用于控制MXCSR的方法及装置与流程
本申请是pct国际申请号为pct/us2011/067957、国际申请日为2011年12月29日、进入中国国家阶段的申请号为201180076121.9,题为“用于控制mxcsr的方法及装置”的发明专利申请的分案申请。
本发明的实施例通常涉及一种用于控制多媒体扩展控制及状态寄存器(mxcsr)的方法及装置。
背景技术:
多媒体扩展控制及状态寄存器(mxcsr)存有ieee浮点控制及状态信息——作为运算标记的状态信息。所述控制位为每个浮点运算的输入,所述运算标记为每个浮点运算的输出。假如浮点运算生成未被对应的控制位“掩码”的运算标记,则必然引发浮点异常。运算标记具有粘性,即一旦由运算设置就不能清除它们。
这使得mxcsr成为用于所有浮点运算的串行化点。现今存在无序处理器,其为所述mxcsr运用某种形式的重命名及重排序机制,以允许不按程序的顺序执行浮点运算。这些机制可以将每个指令生成的运算标记的推测性拷贝附于所述指令的结果,并在该指令退出时,将所述标记并入架构版本并检查异常。不幸的是,这种机制纯粹在硬件中实现,只能知道选择的程序的顺序,不能改变或操纵它。
附图说明
结合下图,根据随后的详细描述能够更好地理解本发明:
图1示出了可以用于本发明实施例的计算机系统架构。
图2示出了可以用于本发明实施例的计算机系统架构。
图3为包含执行浮点运算功能的浮点运算单元(fpu)的处理器核的框图。
图4为示出根据本发明的一个实施例的两个寄存器的框图:架构arch_mxcr和arch_mxsr;以及控制用于fpu运算的mxcsr的优化器。
图5为根据本发明的一个实施例以数字门形式显示合并、旋转(rotate)、清除和mxre指令的示例的图。
具体实施方式
在随后的描述中,出于解释目的,为了全面了解下面描述的本发明实施例,展示了若干具体细节。然而,无需其中的某些具体细节就可以实现本发明,对本领域技术人员来说是显而易见的。在其它实例中,为了避免难以理解本发明实施例的基本原则,以框图形式显示公知结构及设备。
下面是可以用于之后要讨论的本发明实施例、且用于执行本文详述的指令的实例计算机系统。用于膝上计算机、台式机、手持pc、个人数字助手、工程工作站、服务器、网络设备、网络中心、开关、嵌入式存储器、数字信号处理器(dsp)、图形设备、视频游戏设备、机顶盒、微控制器、手机、便携式媒体播放器、手持设备及各种其它电子设备的本领域公知的其它系统设计及配置也合适。总之,如本文公开的能够纳入处理器和/或其它执行逻辑的大量各种系统或电子设备通常是合适的。
现在参考图1,显示了根据本发明的一个实施例的计算机系统100的框图。系统100可以包括一个或多个处理元件110、115,其耦接到图形存储控制中心(gmch)120。在图1中,用虚线指代额外处理元件115的可选性质。各处理元件可以是单核或者可以包括多核。可选地,除了处理核外,所述处理元件还包括其它管芯上元件,例如集成存储控制器和/或集成i/o控制逻辑。而且,对于至少一个实施例,所述处理元件的核可以是多线程的,因为它们可以每核包括一个以上硬件线程上下文。
图1示出gmch120可以耦接到存储器140,其可以例如是动态随机存取存储器(dram)。对于至少一个实施例,所述dram可以与非易失性高速缓存相关联。gmch120可以是芯片组或芯片组的部分。gmch120可以与处理器110、115通信,并控制处理器110、115与存储器140之间的交互。gmch120还可以充当处理器110、115与系统100的其它元件之间的加速总线接口。对于至少一个实施例,gmch120经多点总线(例如前端总线(fsb)195)与处理器110、115通信。而且,gmch120耦接到显示器140(例如,平板显示器)。gmch120可以包括集成图形加速器。gmch120进一步耦接到输入/输出(i/o)控制中枢(ich)150,其可以用于将各种外围设备耦接到系统100。图1的实施例示例性地示出了外部图形设备160,其可以是与另一外围设备170一道耦接到ich150的分立图形设备。
或者,系统100中还可以存在额外或不同的处理元件。例如,额外的处理元件115可以包括与处理器110相同的额外处理器、与处理器110异质或不对称的额外处理器、加速器(例如,图形加速器或数字信号处理(dsp)单元)、现场可编程门阵列或任意其它处理元件。根据包含架构、微架构、热、功耗特性等等的一系列指标规格,物理资源110、115之间可能有各种差异。这些差异可以有效地显现为处理元件110、115间的非对称及异质。对于至少一个实施例,各种处理元件110、115可以驻留在同一管芯封装中。
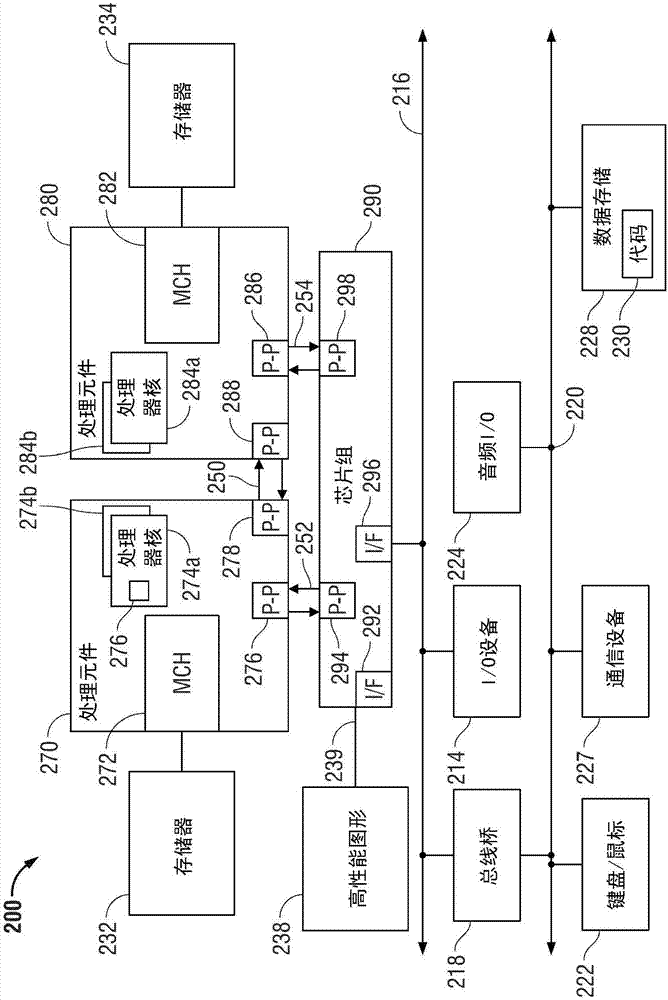
现在参考图2,显示了根据本发明实施例的另一计算机系统200的框图。如图2所示,微处理器系统200为点到点互连系统,并且包括经点到点互连250耦接的第一处理元件270及第二处理元件280。如图2所示,处理元件270及280各自可以是多核处理器,包括第一及第二处理器核(即,处理器核274a及274b,处理器核284a及284b)。或者,一个或多个处理元件270、280可以是除处理器之外的元件,例如加速器或现场可编程门阵列。虽然只显示了两个处理元件270、280,但要理解本发明的范畴不限于此。在其它实施例中,在指定的处理器中可以存在一个或多个额外处理元件。
第一处理元件270可以进一步包括存储器控制器中枢(mch)272和点到点(p-p)接口276及278。类似地,第二处理元件280可以包括mch282、p-p接口286及288。处理器270、280可以利用ptp接口电路278、288、经点到点(ptp)接口250交换数据。如图2所示,mch272及282将所述处理器耦接到相应的存储器,即存储器242和存储器244,其可以是本地附于相应处理器的部分主存储器。
处理器270、280各自可以利用点到点接口电路276、294、286、298、经单独的ptp接口252、254与芯片组290交换数据。芯片组290还可以经高性能图形接口239与高性能图形电路238交换数据。本发明实施例可以位于具有任意数目处理核的任意处理元件内。在一个实施例中,任意处理器核可以包括本地高速缓存存储器(未示出)或以别的方式与其关联。而且,两处理器外部、但经p2p互连仍与所述处理器连接的处理器中可以包括共享高速缓存(未示出),这样假如将处理器置于低功率模式,一个或两个处理器的本地高速缓存信息可以存储在所述共享高速缓存里。第一处理元件270及第二处理元件280可以经p-p互连276、286及284分别耦接到芯片组290。如图2所示,芯片组290包括p-p接口294、298。而且,芯片组290包括接口292,以将芯片组290与高性能图形引擎248耦接。在一个实施例中,总线249可以用于将图形引擎248与芯片组290耦接。或者,点到点互连249可以耦接这些组件。反过来,芯片组290可以经接口296耦接到第一总线216。在一个实施例中,第一总线216可以是外围组件互连(pci)总线、或诸如pci快速总线的总线或另一第三代i/o互连总线,不过本发明的范畴不限于此。
如图2所示,各种i/o设备可以与将第一总线216耦接到第二总线220的总线桥218一道耦接到第一总线216。在一个实施例中,第二总线220可以是低引脚计数(lpc)总线。在一个实施例中,各种设备可以耦接到第二总线220,其包括例如键盘/鼠标222、通信设备226及诸如可以包含代码230的磁盘驱动或其它海量存储设备的数据存储单元228。而且,音频i/o224可以耦接到第二总线220。注意,可能有其它架构。例如,系统可以实现多分支总线或其它此类架构,而不是点到点架构。
如要描述的,本发明实施例涉及优化器,其使得处理器核(例如,274和284)的多媒体扩展控制及状态寄存器(mxcsr)使能重排序、重命名、追踪和异常检查,以允许优化应用程序——包括但不限于诸如动态二进制译码器或即时编译器的动态编译系统——或应用程序编程器的浮点运算。应该懂得术语“应用程序”之后还指的是动态编译系统。
首先,转向图3,将描述mxcsr操作。应该懂得与计算系统的处理器核274通信有两种观点。第一种观点是应用程序或应用程序编程器“看到”了什么,即应用程序或应用程序编程器用来传送指令302并从处理器核274接收输出304的接口。这种接口可以称为处理器逻辑视图。所述逻辑视图中的应用程序状态可以称作架构状态或逻辑状态。
第二种观点是为了以高效方式执行应用程序,处理器核274“在后台”实现了什么或应用程序或应用程序编程器“看不到”什么。所述应用程序状态为可以称作物理状态的核处理器274的实际内部实现。
如图3所示,当在处理器核274中执行浮点运算指令时,处理器核274实现浮点运算单元(fpu)314,其执行相关指令302。为了实现这个,mxcsr310通过控制位312控制fpu314的行为,并从fpu接收状态更新313(运算标记)。在fpu314中执行浮点运算指令,fpu314读取并更新mxcsr310。输出304为fpu314执行的运算操作的结果。应该理解图3显示了处理器的逻辑视图/状态。
许多现代处理器支持标准的逻辑视图,应用程序及应用程序编程器在该标准逻辑视图中仅能看到指令302和输出304。然而,不同处理器间的内部操作可能不同。例如,为了提供高性能,可以以不同于编程器规定的顺序执行指令(这叫作无序执行)。这通过使用无序执行引擎来实现,其为处理器核内部实现的硬件单元。
本发明的实施例涉及优化器,使得处理器核274的多媒体扩展控制及状态寄存器(mxcsr)的硬件使能重排序、重命名、追踪、异常检查,以允许优化应用程序及应用程序编程器的浮点运算。尤其是,支持并保留使用mxcsr的当前逻辑视图,但所述物理实现方式不同于之前现有技术的实现方式。
在一个实施例中,利用硬件组件及优化器组件(即虚拟机优化器)。然而,应该懂得本文公开的组件的实施例可以以硬件、软件、固件或其组合实现。之后,将使用术语优化器。尤其是,参考图4,结合硬件组件的优化器组件410、415可能负责控制处理器核274内部的物理状态,并负责将架构状态或逻辑视图导出给应用程序或应用程序编程器。尤其是,优化器410、415允许所述应用程序或应用程序编程器控制处理器核274内的重排序、重命名、追踪及异常检查,以允许所述应用程序或应用程序编程器优化浮点运算。换言之,优化器组件410、415允许所述应用程序或应用程序编程器优化fpu执行的用于指令302的浮点运算的性能。
作为一个实例,处理器核274可以包括执行运算功能的浮点单元(fpu)406和给所述fpu提供控制位405的多媒体扩展控制寄存器(mxcr)402。进一步地,优化器410、415可以用于从多个推测性多媒体扩展状态寄存器(spec_mxsr)中选择一个spec_mxsr412,以基于指令302更新多媒体控制状态寄存器(mxsr)404。可以从应用程序和/或应用程序编程器接收该指令。该指令可以允许pfu操作的重排序、重命名、追踪及异常检查。
如图4所示,所述实现方式可以包括两个寄存器:架构多媒体扩展控制寄存器(arch_mxcr)404和架构多媒体扩展状态寄存器(arch_mxsr)404。这些寄存器一块提供了mxcsr(例如,“传统”的mxcsr)的架构状态。简言之,arch_mxcr402可以包括以下条目:刷写为零(fz);舍入控制(rc);精度掩码(pm);下溢掩码(um);上溢掩码(om);除零掩码(zm);非正规掩码(dm);无效掩码(im);以及非正规为零(daz)。arch_mxsr404可以包括以下条目:精度误差(pe);下溢误差(ue);上溢误差(oe);除零误差(ze);非正规误差(pe);无效误差(ie);以及多媒体扩展实数异常(mxre)。所述mxre为追踪挂起异常的附加位。
arch_mxcr寄存器402给fpu406提供控制位405。fpu406给优化器410提供状态位407。优化器410决定基于浮点集结字段(fs)更新哪些推测性mxsr(i)(spec_msxr(i))。如图4所示,spec_msxr(i)412的副本可以多达n个。因此,有多个spec_mxsr(i)寄存器412的副本。fpu406生成更新spec_mxsr寄存器的状态位(作为浮点指令执行的结果)。可以用fs字段扩展全部fpu指令。优化器410用fs字段来指定哪些spec_mxsr寄存器将接收所述状态位。
接下来,优化器415可以决定哪些spec_msxr(i)412将基于浮点障碍(fpbarr)指令来更新arch_mxsr404。这个fpbarr指令可以用来管理多个spec_mxsr412副本和arch_mxsr404。通过使用fpbarr指令,优化器415可以根据选择的spec_mxsr寄存器412的物理状态来提供架构mxcsr状态(经arch_mxsr404和arch_mxcr405)。这样,所述应用程序或应用程序编程器可以为fpu操作选择指令和特定的spec_mxsr寄存器412。
因此,通过使用优化器(410,415),本发明的实施例允许在虚拟机环境中高性能地实现浮点程序执行,这允许应用程序或应用程序编程器而不是处理器本身为fpu操作选择指令顺序。尤其是,优化器410、415允许所述应用程序或应用程序编程器控制处理器核274内的重排序、重命名、追踪和异常检查,以允许所述应用程序或应用程序编程器优化浮点操作。换言之,优化器组件410、415允许所述应用程序或应用程序编程器优化fpu执行的用于指令的浮点操作的性能。
之后将更详细地描述本发明实施例的解释。一方面,本发明的实施例可以认为由三部分构成。第一部分可以是存有多个mxcsr状态副本的硬件,第二部分可以包括浮点指令行为的扩展或替代,第三部分可以包括fpbarr指令,其如之前描述的,允许优化器410、415管理多个spec_mxsr寄存器412并检查运算异常。进一步地,本发明实施例允许通过状态更新重命名mxcsr寄存器。
对于部分1,描述了存有多个mxcsr状态副本的硬件。所包含的状态元件可以如下所示:a)mxcsr的控制位的一个架构副本,例如字段—rc、ftz、daz和masks—显示为arch_mxcr402;b)mxcsr的状态位的一个架构副本,例如—追踪挂起异常的flags和mxre位——显示为arch_mxsr404;c)mxsrflags加上mxre位的一组n个推测性副本——称作spec_mxsr(i)412。应该注意在任意指定时刻,能够根据arch_mxcr402和arch_mxsr404重建mxcsr状态(忽略mxre位)。
对于部分2,可以用fs字段扩展浮点指令(如之前描述的)(例如,fs域可以是ceil(log2n)位的标识符)。如之前描述的,所述fs字段可以用来指定或选择spec_msxr(i)412副本。作为一个实例,当浮点指令操作时,它首先从arch_mxcr402读取必需的控制信息(例如,使用舍入模式,如何处理非正规数字等)。操作结束时,fpu406硬件连同所述操作的结果一起生成某些运算标记。通过以“粘性”方式执行逻辑or操作,可以将这些标记合并到spec_mxsr(fs)标记字段。这意味着所述合并操作能够将标记位从“0”变为“1”,反之却不行。假如这一合并期间,第i个spec_mxsr(fs)标记位的值从“0”变为“1”,而第i个arch_mxcr掩码位设为“0”,那么spec_mxsr(fs)mxre位也可以设为“1”(也是以粘性方式)。这意味着这一指令应该引发浮点异常,却没有立即这样做,而是在spec_mxsr(fs)寄存器412中标记这个动作。这种浮点操作的新行为允许推测性地执行浮点操作,而不会改变任何架构状态或引发任何异常。
对于部分3,优化器415实现的fpbarr指令可以允许管理arch_mxcr寄存器404、arch_mxsr寄存器402及spec_mxsr寄存器412,它还允许引发浮点异常。尤其是,利用fpbarr指令的优化器415可以接受规定要执行的特定操作的数个修饰符(即运算数)。例如,可以为同一指令指定不同的修饰符。之后将单独讨论用于fpbarr指令的每个修饰符的各种动作,然后将描述所有修饰符之间的交互。
fpbarr#merge=<v>:#merge修饰符规定了n位宽的位掩码值<v>,称之为合并集。当断言所述合并集中第i个位时,0≤i<n,那么将spec_mxsr(i)寄存器412的值合并入arch_mxsr404。以粘性方式进行所述合并。能够断言任意数目的位,且可以允许多个并发合并。当所述合并集为空(即没有位断言)时,不执行合并操作。所述合并操作还包括标记位以及mxre位。
作为一个实例,参考图5,可以经由fbarr指令将各种spec_mxsr(i)寄存器502、504和506合并在一起。作为说明,图5以数字门的形式显示了fbarr合并、旋转、清除及mxre指令。例如,基于合并指令510和对应的与门512、514、516可以将spec_mxsr(i)寄存器502、504、506合并或不合并在一起。在和或门530合并后,spec_mxsr(i)寄存器502、504、506可以合并为arch_mxsr404。为清楚起见,只示出了一些spec_mxsr(i)寄存器。还可以实施图5的其它指令。例如,可以通过实施选择器535选择的清除命令540来清除spec_mxsr(i)寄存器502、504、506。之后将更详细地讨论该清除命令。另外,还可以通过选择器535、或门544、或门530等来选择之后要讨论的旋转命令。进一步地,假如通过与门560来设置mxre位522,则可以实施多媒体扩展实数异常mxre指令550。假如设置mxre位552且实施mxre指令550,则与门560将发布引发浮点异常562。还将进一步详细描述这一指令。
fpbarr#clear=<v>:#clear指令540规定了n位宽位掩码值<v>,称之为清除集。当断言该清除集中的第i位,0≤i<n-1时,那么清除spec_mxsr(i)寄存器,即将它的值设为零。能够断言任意数目的位,并允许多个并发清除。当该清除集为空(即,没有位断言)时,不执行清除动作。
fpbarr#rotate:#rotate指令542执行合并spec_mxsr(0)、清除spec_mxsr(n-1),以及对于0≤i<n-1寄存器,逻辑重命名全部spec_mxsr(i)寄存器。下面的系列动作能够最佳描述这一特定操作(按先后次序的降序):
arch_mxsr←mergespec_mxsr(0)
spec_mxsr(0)←spec_mxsr(1)
spec_mxsr(1)←spec_mxsr(2)
……
spec_mxsr(n-3)←spec_mxsr(n-2)
spec_mxsr(n-2)←spec_mxsr(n-1)
spec_mxsr(n-1)←clear
fpbarr#mxre:当使用#mxre指令550时,如果arch_mxsr404中的mxre位552被断言,则fpbarr引发浮点异常562。
应该懂得可以将所有三个指令(合并、旋转、mxre)合为单个fpbarr指令。之后为按先后次序的降序的实例步骤:1.执行合并指令510。这些动作更改了arch_mxsr404的值;2.执行第一个旋转指令542,例如将spec_mxsr(0)502合并入arch_mxsr404。这一动作更改了arch_mxsr404的值;3.执行mxre检查指令550。假如新更新的arch_mxsr寄存器404的mxre位为“1”(这可能是因为这个或之前的合并或旋转指令),那么引发浮点运算异常562,且不会执行下面的步骤;4.执行剩余的旋转指令542。这意味着更新所有的spec_mxsr寄存器;5.执行清除指令540。此情况下的清除集指的是重新分配旋转后的spec_mxsr寄存器,而不是初始的spec_mxsr。
之后描述示例用途。清除指令540可以用于程序执行时在特定点重设推测性mxcsr状态。合并指令510可以用于程序执行时在特定点将一个或多个推测性执行流并入架构状态。旋转指令542可以用于循环执行软件流水线优化。
利用这一机制,实施fpbaar指令的优化器401、415能够自由地重排序浮点代码,甚至跨控制流指令(例如,条件分支)。作为示例,实施fpbaar指令的优化器410、415能够遵循着色算法。在一个区域的开始处,可以清除所有的spec_mxsr副本412。接着,给各邻近的代码块分配颜色(spec_mxsr副本)。在需要正确的架构状态的所有点,优化器410、415附上适当的fpbarra指令来执行合并和mxre检测。进一步地,为了计算正确的合并集,优化器410、415应该追踪从最后的fpbarr指令(例如,合并和清除)点到当前的一个点的所有可能的代码路径。通过了解所有的代码路径,优化器410、415明白接触了哪些颜色,并且所述优化器能够计算合并哪些寄存器。
进一步地,优化器410、415可以将旋转指令542用于流水线循环。在此情况下,可以给参与流水线循环内核的各初始循环迭代分配spec_mxsr412,这样给第i次迭代分配specmxsr(0),给迭代i+1分配spec_mxsr(1),……给迭代i+m分配spec_mxsr(m),等等。然后可以基于该指令属于初始循环的哪次迭代,用适当的fs扩充所述内核里的各指令。进一步地,可以在各内核迭代结束时插入优化器410、415用旋转指令实施的fpbarr指令,以为下次内核迭代重新分配specmxsr名称。应该理解这些只是优化器用途的示例。
因此,通过使用优化器(410,415),本发明的实施例允许在虚拟机环境中高性能地实现浮点程序执行,这允许应用程序或应用程序编程器而不是处理器本身选择用于fpu操作的指令的顺序。尤其是,优化器410、415允许应用程序或应用程序编程器控制处理器核274内的重排序、重命名、追踪和异常检查,以允许所述应用程序或应用程序编程器优化浮点操作。换言之,优化器组件410、415允许所述应用程序或应用程序编程器优化fpu执行的用于指令302的浮点操作的性能。
本文公开的不同机制的实施例,例如优化器410、415,以及所有其它机制,可以以硬件、软件、固件或是这些实施方式的组合实现。本发明的实施例可以实现为在包含至少一个处理器、数据存储系统(包括易失性及非易失性存储器和/或存储元件)、至少一个输入设备和至少一个输出设备的可编程系统上执行的计算机程序或程序代码。
可以将程序代码应用于输入数据以执行本文描述的功能,并生成输出信息。所述输出信息可以以公知的方式应用于一个或多个输出设备。出于这种应用的目的,处理系统包括具有例如处理器的任意系统;数字信号处理器(dsp)、微控制器、专用集成电路(asic)或微处理器。
可以用高级过程或面向对象的编程语言实现所述程序代码,以与处理系统通信。如果需要,可以用汇编或机器语言实现所述程序代码。事实上,本文所述的机制范围上不限于任何特定的编程语言。任何情况下,该语言都可以是编译或解释语言。
至少一个实施例的一个或多个方面可以由机器可读介质上存储的表示处理器内各种逻辑的表示性数据实现,机器读取时其使得该机器制作执行本文所述的技术的逻辑。这些称作“ip核”的表示可以存储在有形的机器可读介质上,并提供给各种客户或制造工厂以载入实际制造所述逻辑或处理器的制作机器。这些机器可读存储介质可以包括,而不限于,机器或设备制造或形成的粒子的非瞬态有形布置,包括诸如硬盘、包括软盘、光盘、压缩磁盘只读存储器(cd-rom)、可重写压缩磁盘(cd-rw)、磁光盘的任意类型盘、诸如只读存储器(rom)、例如动态随机存取存储器(dram)、静态随机存取存储器(sram)的随机存取存储器(ram)、可擦除可编程只读存储器(eprom)、闪存、电可擦除可编程只读存储器(eeprom)的半导体设备、磁卡或光卡、或适于存储电子指令的任意其它类型的介质。
因此,本发明的实施例还包括包含用于执行本发明的操作实施例的指令或包含定义本文描述的结构、电路、装置、处理器和/或系统特征的诸如hdl的设计数据的非瞬态的有形机器可读介质。这些实施例也可以称作程序产品。
本文公开的某些指令操作可以由硬件组件执行,并可以由用于促成或至少造成用执行所述操作的指令编程的电路或其它硬件组件的机器可读指令实现。所述电路可以包括不过命名一些实例的通用或专用处理器、或逻辑电路。所述操作还可以选择性地由硬件及软件组合执行。执行逻辑和/或处理器可以包括响应于机器指令或一个或多个由所述机器指令导出的控制信号的具体或特定电路,以存储指令规定的结果操作数。例如,可以在图1、2的一个或多个系统中执行本文公开的指令的实施例,且所述指令的实施例可以存储在所述系统中执行的程序代码内。另外,这些图的处理元件可以利用本文详述的具体流水线和/或架构(例如有序和无序架构)之一。例如,所述有序架构中的解码单元可以解码所述指令,并将解码的指令传递给向量或标量单元等。
纵观之前的描述,出于解释目的,展示了若干具体细节以提供对本发明的全面了解。然而,无需其中的某些细节就可以实现本发明,对于本领域技术人员来说是显而易见的。因此,应该根据随后的权利要求书来判断本发明的范畴及精神。
- 还没有人留言评论。精彩留言会获得点赞!