一种基于Spark与GPU的并行计算系统的制作方法
本发明属于并行计算技术领域,具体涉及一种基于spark与gpu的并行计算框架系统。
背景技术:
当今社会,各行业需要处理的数据规模已经呈现海量趋势,大数据引起了社会各行业的的广泛关注。毋庸置疑,大数据蕴含着丰富的有用信息,如果能够合理地挖掘和使用大数据,将对科学研究和社会经济产生巨大的促进作用。由于大数据中所蕴含的信息能够辅助商业决策与科学研究,所以已经在许多行业内得到了快速的发展与应用。在大数据时代中,一切以数据为中心,从海量的历史数据中能够挖掘分析出许多通过其它方式无法获得的有效信息,从而提高决策的准确性。
分布式计算的发展为充分发掘数据价值提供了有效的手段。分布式计算能够利用廉价的计算机集群,对海量数据进行快速计算分析,有从而有效的节省了数据分析成本。在这样的环境下,一批分布式计算框架技术应运而生,其中spark由于其基于内存计算的特性,能够有效提升数据处理的效率,且在机器学习与交互式分析等领域有着广泛的应用。
与此同时,gpu因其拥有众多核心的特性,使其在很多应用中能够取得比单纯cpu计算更高的计算效率,而这种加速效果往往是以十倍或是百倍来衡量。相比单纯的提升cpu性能,利用gpu进行并行计算往往更加廉价和有效。这使得gpu在高性能计算领域有着重要的地位。
虽然spark能够有效的处理数据密集型作业,但对于计算密集型作业来说不太适合。且集群规模扩展有限,如果单纯使用cpu进行计算,那么对于大批量作业的处理性能提升仍然有待提高。如果能够在spark中引入对gpu设备的支持,使其既能够充分发挥spark本身高效内存计算的特性,又能够利用gpu多核并行计算的优势,这将极大提升对海量数据的处理效率。
原生spark框架中没有引入对gpu设备的支持,现有的在spark中调用gpu加速计算的解决方案是基于在java/scala语言中调用c/c++程序进行处理,这种方式存在很多弊端。由于spark中无法感知gpu计算任务,所以其无法区分cpu任务与gpu任务,在调度任务执行时,将可能会在不含gpu设备的节点中启动gpu任务,造成任务执行失败。且在yarn资源管理器中,只支持对cpu与内存资源的调度,无法感知gpu资源,其无法向上层的spark框架提供对gpu资源的分配与调度。由于yarn与spark框架自身的原因,在spark中执行gpu计算的传统方法无法适应异构集群环境。
技术实现要素:
本发明的目的在于提供一种处理效率高,且能够适应异构集群环境的基于spark与gpu的并行计算系统。
本发明提供的基于spark与gpu的并行计算系统,将spark与gpu进行整合,使其能够有效的处理数据密集型与计算密集型作业,极大提高了作业处理效率。
本发明提供的基于spark与gpu的并行计算框架系统,包括:
组件一,改进的的资源管理平台,其支持对gpu、cpu与内存等多维资源进行调度与管理;
组件二,改进的spark分布式计算框架,其支持对gpu型任务的调度与执行。
(1)所述改进的的资源管理平台,包括:
改进yarn的资源管理器与节点管理器,使其能够有效感知异构集群的gpu资源,从而支持对集群gpu资源的管理与调度。其中,包括资源表示模型、资源调度模型、资源抢占模型、资源隔离机制及gpu设备的动态绑定机制的改进。
(2)所述改进的spark分布式计算框架,包括:
改进spark的资源申请与分配机制、作业调度机制与任务执行机制,使其支持对gpu型任务的调度与执行。通过在资源申请、资源分配、dag生成、stage划分与任务执行等阶段引入对gpu资源的标识,使其执行引擎能够感知gpu任务,并在异构集群中有效执行。
本发明中,所述改进的的资源管理平台,能够支持对包含gpu资源在内的多维资源进行管理与调度。具体来说:
关于资源表示模型,首先可自定义节点中包含的gpu设备数量,并修改资源表示协议,使其增加对gpu资源的表示。待节点启动时,节点管理器初始化资源列表,并与资源管理器通过心跳机制汇报该节点的资源信息。
关于资源调度模型,本发明将gpu与cpu、内存资源一起添加到资源管理平台的层级管理队列中。这样不仅能够保持资源管理的统一性,也能更灵活的针对gpu资源进行权限的设定,更适合在大规模集群中处理多用户作业的场景下应用。本发明依据drf算法对资源调度模块进行修改,使其添加对gpu资源的调度与管理。该算法如下:
(1)初始化变量。其中,r=<totalcpu,totalgpu,totalmem>表示集群cpu、gpu及内存资源的总量。c=<usedcpu,usedgpu,usedmem>表示集群中已被消费的cpu、gpu及内存资源的数量。si表示作业i的主资源占相应总资源的份额。ui=<cpui,gpui,memi>表示已经分配给作业i的资源量。di=<cpui,gpui,memi>表示作业i的每个任务需要的资源量。
在每次选取作业进行资源分配时,依次执行以下步骤:
(2)选取主资源份额si最小的作业执行。
(3)如果c+di≤r,则将资源分配给作业i,更新c=c+di,ui=ui+di,
si=max{ui/r}。否则,集群资源无法满足需求,停止分配。
关于资源抢占模型,通过资源调度器对层级队列中的每个队列设置每种资源的可用上限与下限。资源调度器将负载较轻的队列的资源分配给其他负载较重的队列以提高集群资源利用率。但当有新的应用程序提交到负载较轻的队列时,调度器会资源抢占机制收回其他队列所占用的资源,从而将本属于该队列的资源分配给它。在资源抢占机制发生时,需要释放gpu资源。
这个工作交由节点节点管理器完成,这里新增releasegpu方法用于释放gpu资源。资源管理器将需要释放的资源列表信息通过心跳机制发送给响应的节点管理器,节点管理器检测到待释放的资源实体中含有gpu资源时,会调用releasegpu方法释放gpu资源。然后资源管理器将所释放的资源进一步分配给相关队列。
关于资源隔离模型,由于cgroups具备较好的隔离性能且其支持对gpu资源进行隔离,本发明采用cgroups方案对gpu资源进行隔离。
关于gpu设备的动态绑定机制,当分配给该任务的资源实体中包含gpu资源时,相应的节点管理器需要将节点上的gpu设备与该资源实体进行绑定。如果节点上有多个空闲的gpu资源,那么需要选择一个进行分配。本发明将gpu的运行状态信息表示为<gpu设备号,资源实体号>列表,列表的每条数据标识了gpu设备与相关资源实体的对应关系。节点管理器会在节点刚启动时根据相关配置文件以及该节点上的gpu设备信息初始化该列表。
当有新的任务请求使用gpu资源时,节点管理器通过查找该列表,从而获得处于空闲状态的gpu设备信息,并将其分配给相关任务。如果节点管理器节点上拥有多个gpu资源处于空闲状态,则通过轮转法进行gpu资源的分配。同时,将已经运行的资源实体与gpu资源的对应信息进行保存至数据库中。在节点管理器需要重新启动的情况下,能够从数据库中直接读取gpu设备的分配信息,避免了对节点资源的再分配。
本发明中,所述改进的spark分布式计算框架,是对于spark内核进行改进,使其支持对gpu型任务的调度与执行。具体来说:
在提交作业时,如果spark应用程序的应用程序控制器检测到该应用程序需要gpu资源,则需要在资源申请时,将所需的gpu资源加入到资源请求描述中。
申请的container包括两种:cpu型container与gpu型container。因为对于gpu型任务,也需要cpu完成数据的处理、传输及gpu核函数的启动,所以gpu型container除了需要1个单位的gpu资源外,还需要指定数量的cpu核心。在申请资源时,需要确定所要申请的两种类型的container数目。这里,用executorcores表示每个container所要包含的cpu核数,totalcores表示应用程序申请的cpu核数,gpunum表示应用程序申请的gpu资源数量,则gpu型container的数量为gpunum,非gpu型container的数量为(totalcores-gpunum*executorcores)/executorcores。然后再根据设置的内存资源数量进行判定,检测总的内存数量是否能够满足所有container需要的内存总量,以进一步处理。发出资源请求后,资源调度器并不会立马为它返回满足要求的资源,而需要spark对应的应用程序控制器不断通过心跳机制与资源管理器通信,以探测请求到的资源是否已经分配完成。应用程序控制器在收到所申请的资源后,将其加入程序内部的待分配资源列表中,以分配给具体执行的任务。
在spark接口中,需要对gpu的任务进行标识。本发明提出了mappartitionsgpu算子与mappartitionsgpurdd,用于针对gpu任务进行处理。
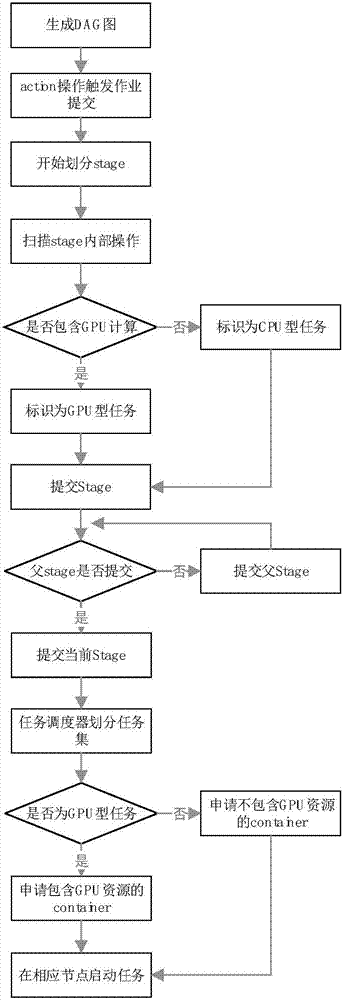
spark的作业调度器dagscheduler在生成dag图后,开始划分stage时,需要增加字段以标识当前stage内是否包含gpu操作。在一个stage内部,根据每个rdd上运行的计算方法是否需要gpu资源,其内部的rdd分为两种:需要gpu资源的rdd与不需要gpu资源的rdd。如果该stage中包含需要gpu资源的rdd时,则在为这个stage中rdd的分区分配资源时,应该为其分配足够的gpu资源,即便可能只有其中一个rdd在计算时需要。否则,任务在计算过程可能会因为没有可使用的gpu资源而导致执行失败。为了标识stage中是否包含需要gpu资源的rdd,需要为stage增加字段flaggpu,当flaggpu为真时,表明该stage中包含需要gpu资源的rdd。通过设置flaggpu字段,在下一步的资源分配中,能够被任务管理器识别并为其分配gpu资源。
本发明中,在spark内部的作业调度器dagscheduler中进行标识stage类型的流程如下:
(1)dag生成后,划分stage。在生成stage时,检测该stage内部所包含的rdd的flaggpu字段是否为真,如果是,则说明该stage在执行过程中需要gpu资源,标记该stage的flaggpu字段为真。作为以后任务管理器进行gpu资源分配的依据。
(2)执行引擎提交stage的算法是一个递归的过程,它会首先提交dag图中的最后一个stage,然后检查该stage的父stage是否都已提交完毕,如果全部提交则开始执行此次stage所对应的任务集。如果其父stage有的没有提交,则递归提交其父stage,并同样作出上述检查。所以最终的结果是按照dag图,从前往后执行stage。这样做是的好处是能够确保当前stage执行时其输入数据已经准备完毕,并且在rdd中的分区数据丢失时,能够沿着dag图从后往前寻找最近的rdd中已生成的分区数据,然后重新执行以获得丢失分区。
(3)提交stage后,任务管理器开始将该stage划分成任务集,并向集群管理器申请执行所需的资源。任务集中所包含的任务数量与rdd的分区数量相同。任务管理器首先检测该stage的flaggpu字段是否为真,如果是则为其分配包含gpu资源的container。在进行该container的分配时,如果有多个container可以选择,则根据本地化策略进行判断。即依次选择本地节点、本机架的其它节点及其他机架节点。然后在资源所在节点中启动任务,并将任务中间结果与最终结果存入存储体系中。这个过程中,如果包含gpu资源的container数量少于gpu型任务的数量,则暂未分配gpu资源的任务需要等待,待其他任务执行完毕,有gpu资源处于空闲状态时则进行分配。
(4)在任务执行完毕后,归还资源。将回收的container加入待分配列表中,以分配给其他任务使用。
本发明基于改进的框架,提出了一种针对gpu型任务的有效的编程模型。
在spark中,rdd中的数据由若干个分区组成,其最终以分区为单位被分配到若干个节点中完成计算。实际上,根据分区数据执行粒度,可以将利用spark进行gpu计算的类型主要分为两种:
(1)以分区为单位完成gpu计算。即将rdd分区中的数据全部放入gpu中以完成并行计算,提高程序执行效率;
(2)以单个记录为单位完成gpu计算。即将rdd分区中的数据逐个放入gpu中完成计算,以单个记录为单位进行加速处理。
在改进的框架中,新增加的mappartitionsgpu算子能够感知gpu型任务,以分区数据作为输入进行处理。该算子的主要执行逻辑如下:
(1)首先在方法中初始化gpu设备;
(2)然后判断对分区数据执行的粒度是以分区为单位还是以单条记录为单位。如果是以分区单位,那么利用cudaapi将分区数据传输到gpu显存中,这个过程可能涉及数据格式的转换,将rdd中分区数据转换成成能够被gpu处理的数据格式。然后调用gpu核函数对数据进行并行计算,在计算完成后,将输出结果传输至内存中。如果分区数据执行的粒度是以单条记录为单位,那么需要对逐个对每个分区记录顺序处理。每次拷贝一个记录数据至gpu显存中,调用gpu核函数对数据进行并行计算,在计算完成后,将输出结果拷贝至内存中。在全部记录处理完毕后,需要将整个记录的输出结果转换成一个分区集合;
(3)释放gpu设备,并且返回分区集合迭代器。
与现有技术相比,本发明的优点和效果有:
1、本发明所提出的改进的资源管理平台能够感知异构集群中的cpu、内存及gpu资源,并且能够有效地对其进行管理和调度;
2、基于spark分布式计算框架进行改进,使其能够有效的判别gpu型任务,在dag生成、stage划分、资源的申请与分配等阶段能够针对性的进行处理,使其能够对gpu型作业进行正确的调度与执行;
3、本发明提出的框架,能够适应集群中部分节点具备gpu设备及单点多卡的异构环境,其将gpu型任务正确的分配到集群中包含gpu资源的节点中执行,解决了传统执行gpu任务时无法在异构集群环境下正常工作的问题。
附图说明
图1为gpu设备分配与释放。
图2为改进的框架执行流程图。
图3为mappartitionsgpu工作原理。
具体实施方式
下面结合附图对本发明所述技术方案进一步说明。
图1是模型训练和图像识别的框图,主要包括:
1、在资源表示上,首先可自定义节点中包含的gpu设备数量,并修改资源表示协议,使其增加对gpu资源的表示。待节点启动时,节点管理器初始化资源列表,并与资源管理器通过心跳机制汇报该节点的资源信息。
2、在资源调度上,本发明将gpu与cpu、内存资源一起添加到资源管理平台的层级管理队列中。
3、资源管理器将需要释放的资源列表信息通过心跳机制发送给响应的节点管理器,节点管理器检测到待释放的资源实体中含有gpu资源时,会调用releasegpu方法释放gpu资源。然后资源管理器将所释放的资源进一步分配给相关队列。
4、在资源隔离上,由于cgroups具备较好的隔离性能且其支持对gpu资源进行隔离,本发明采用cgroups方案对gpu资源进行隔离。
5、在gpu设备的动态绑定上,当分配给任务的资源实体中包含gpu资源时,相应的节点管理器需要将节点上的gpu设备与该资源实体进行绑定。本发明将gpu的运行状态信息表示为<gpu设备号,资源实体号>列表,节点管理器会在节点刚启动时根据相关配置文件以及该节点上的gpu设备信息初始化该列表。当有新的任务请求使用gpu资源时,节点管理器通过查找该列表,从而获得处于空闲状态的gpu设备信息,并将其分配给相关任务。如果节点管理器节点上拥有多个gpu资源处于空闲状态,则通过轮转法进行gpu资源的分配。同时,将已经运行的资源实体与gpu资源的对应信息进行保存至数据库中。
6、本发明提出了mappartitionsgpu算子与mappartitionsgpurdd,用于针对gpu任务进行处理。在生成dag图后,开始划分stage时,需要增加字段以标识当前stage内是否包含gpu操作。
7、任务管理器将该stage划分成任务集时,首先检测该stage是否具备gpu标识,如果是则为其分配包含gpu资源的container。
8、对于具备gpu标识的任务,将其调度到包含gpu设备的节点中执行。
参考文献:
[1]alighodsi,mateizaharia.dominantresourcefairness:fairallocationofmultipleresourcetypes[j].berkeley.
[2]m.zaharia,m.chowdhury,t.das,etal.resilientdistributeddatasets:afaulttolerantabstractionforin-memoryclustercomputing[c]//proceedingsofthe9thusenixconferenceonnetworkedsystemsdesignandimplementation.ca,usa:usenixassociation,2012
[3]jankibhimani,miriamleeser,ningfangmi.acceleratingk-meansclusteringwithparallelimplementationsandgpucomputing[a].2015ieeehighperformanceextremecomputingconference(hpec)[c].2015,1-6.
[4]huangchao-qiang,yangshu-qiang.rddshare:reusingresultsofsparkrdd[a].2016ieeefirstinternationalconferenceondatascienceincyberspace(dsc)[j].2016,290-295.
[5]jiezhu1,juanjuanli.gpu-in-hadoop:enablingmapreduceacrossdistributedheterogeneousplatforms.ieeeicis2014[j].2014,1-6。
- 还没有人留言评论。精彩留言会获得点赞!