基于情绪的文本分类方法与流程
本发明属于数据挖掘、自然语言处理和信息检索领域,涉及短文本情感分析技术,尤其是一种基于情感分析的文本分类方法。
背景技术:
国外研究人员在情感分析领域中贡献了许多具有权威性的数据集,并广泛应用于各个会议和比赛;然而在中文文本情感分析领域中,完全满足研究需要、且具有足够权威性的已标注数据集则相对较少;同时,语料库扩展能够去掉部分噪声,在一定程度上缓解特征稀疏性问题,增加文本内容的语义相关空间,形成语义相近且拥有不同词语的文本,能够有效提高情感分析技术的实验效果。
目前主要的比较精确的文本分类算法为语料库扩展的情感分类算法(dataexpansionsentimentanalysis,desa),该算法虽然可以在一定程度上提高情感分析技术的准确率,但该方法只分析了扩展语料库文本中的事件和观点,并未考虑用户的情绪。
技术实现要素:
为克服现有技术的不足,本发明旨在提出一种基于情绪的文本分类算法(emotiontextclassification,etc),它将情绪因素与语料库扩展的情感分类算法结合,并对原始语料库的分类情感极性值,通过集成模型获得原始语料库的最终分类情感极性值。本发明采用的技术方案是,基于情绪的文本分类方法,步骤如下:
步骤一:获取中文情绪词典:使用英文紧张词和放松词标注词典,通过翻译工具转换成中文,并向中文词典中手动添加部分相关的词语;
步骤二:紧张词和放松词强度检测:根据中文情绪词典,检测原始语料库文本是否包含紧张词和放松词,提取原始语料库文本内容中最大的紧张值stress和最大的放松值relation,使之作为特征集的一部分进行处理;
步骤三:文本情感分类:采用支持向量机算法svm(supportvectormachine)对新的特征向量进行分类,得到原始语料库的情感倾向值;
步骤四:集成分类预测,将紧张词和放松词强度检测的情感分析结果提取出来,并结合语料库扩展的情感分类算法的最终分类情感极性一起输入adaboost算法,构造最终分类器h(x)={h1(x),h2(x),...,ht(x)},其中x为数据集,x为数据实例,hi(x)为弱分类器;使用最终分类器进行集成,获得该语料库文本的最终分类情感极性。
验证步骤:使用准确率precisionrate、召回率recallrate、f值f-measure作为验证研究课题意义的实验评价标准,准确率、召回率、f值的计算方法如下:
其中,ni表示真实类别i包含的文本上,nj表示分类后类别j包含的文本数,ni,j表示分类后类别j中属于真实类别i的文档数,precision(i,j)表示准确率,分类正确的信息条数与所有的信息条数之比,recall(i,j)表示召回率,分类正确的信息条数与样本中正确的信息条数之比,f表示准确率与召回率的调和平均数。
基于情绪的情感分析算法加入紧张词和放松词强度检测部分,使用adaboost算法预测原始文本的情感极值,从而提高情感分析技术的实验效果。
一个具体实施方案包括:
步骤s0101:获取原始语料库,并根据研究目的将原始语料库中的所有信息构造成相应的字符串并按照需求对其进行初步匹配,去除无用数据信息,构造文本和其真实情感极性值truevalue的匹配对集合;
步骤s0201:文本内容通常包含微博平台自身规定的特有的符号,并将剩余部分进行文本分词处理;
步骤s0301:数据预处理之后,需要对语料库文本进行否定词检测,根据不同情感类别对语料库进行扩展,产生新的语料库文本;并根据原始语料库的原始极性值o_senti,赋予新构造的语料库文本以新的极性值n_senti;并将新的扩展语料库加入原始语料库集,形成扩展语料库;
步骤s0302:使用英文紧张词和放松词标注词典,通过翻译工具转换成中文,并向中文词典中手动添加部分相关的词语;
步骤s0401:获取扩展语料库,通过r语言中中文分词软件包rwordseg对文本内容分词处理;
步骤s0501:通过相应的特征选择算法,提取并整理文本内容中的特征;
步骤s0601:根据中文情绪词典,检测原始语料库文本是否包含紧张词和放松词,提取原始语料库文本内容中最大的紧张值stress和最大的放松值relation,使之作为特征集的一部分进行处理;
步骤s0602:将步骤s0501中的特征向量空间作为输入,使用随机森林算法进行文本情感分类,判断扩展语料库的情感倾向;
步骤s0701:采用svm算法对新的特征向量进行分类,得到原始语料库的情感倾向值;
步骤s0702:从步骤s0602中取得原始语料库文本的分类极性o_senti和新构造的语料库文本的分类极性n_senti,使用adaboost算法进行分类,构造多分类器模型,获得原始语料库的最终分类情感极性;
步骤s0801:将紧张词和放松词强度检测的情感分析结果提取出来,并结合语料库扩展的情感分类算法的最终分类情感极性一起输入adaboost算法,构造最终分类器h(x)={h1(x),h2(x),…,ht(x)},其中x为数据集,x为数据实例,hi(x)为弱分类器;使用最终分类器进行集成,获得该语料库文本的最终分类情感极性。
本发明的特点及有益效果是:
将desa算法对扩展语料库和对原始语料库的实验结果与etc算法的结果进行详细的对比,基于情绪的情感分析算法实验效果包括准确率、f值都更为理想。
附图说明:
图1为etc的算法流程图。
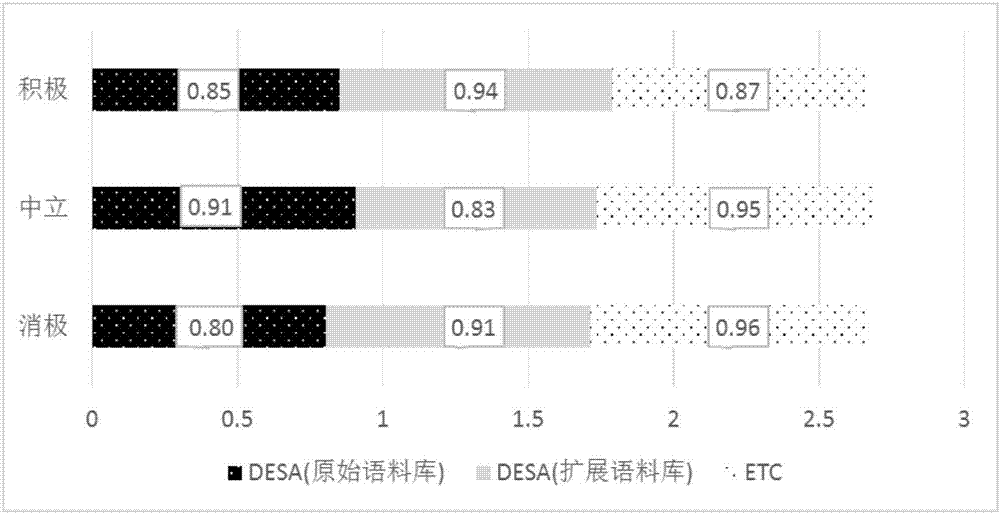
图2为etc与desa准确率对比效果。
通过图2可知,etc对于积极类别准确率效果较差,相比于desa(扩展语料库)低了7%,比desa(原始语料库)高了2%;而etc对于中立类别和消极类别的准确率效果较佳,分别比desa(扩展语料库)提高了8%和4.6%,分别比desa(原始语料库)提高了4%和15%;总体准确率etc比desa(扩展语料库)提高3.2%,比desa(原始语料库)提高6.9%。
具体实施方式
本发明提出一种基于情绪的文本分类算法,包含以下步骤:
步骤一:获取中文情绪词典。使用英文紧张词和放松词标注词典,通过百度翻译等工具转换成中文,并向中文词典中手动添加部分相关的词语。
步骤二:紧张词和放松词强度检测。根据中文情绪词典,检测原始语料库文本是否包含紧张词和放松词,提取原始语料库文本内容中最大的紧张值stress和最大的放松值relation,使之作为特征集的一部分进行处理。
步骤三:文本情感分类。采用支持向量机算法(supportvectormachine,svm)对新的特征向量进行分类,得到原始语料库的情感倾向值。
步骤四:集成分类预测。将紧张词和放松词强度检测的情感分析结果提取出来,并结合语料库扩展的情感分类算法的最终分类情感极性一起输入adaboost算法,构造最终分类器h(x)={h1(x),h2(x),…,ht(x)},其中x为数据集,x为数据实例,hi(x)为弱分类器;使用最终分类器进行集成,获得该语料库文本的最终分类情感极性。
本发明使用准确率(precisionrate)、召回率(recallrate)、f值(f-measure)作为验证研究课题意义的实验评价标准。准确率、召回率、f值的计算方法如下:
几种实验评价标准的具体计算方法如公式(1),公式(2),公式(3)所示。
其中,ni表示真实类别i包含的文本上,nj表示分类后类别j包含的文本数,ni,j表示分类后类别j中属于真实类别i的文档数,precision(i,j)表示准确率,分类正确的信息条数与所有的信息条数之比,recall(i,j)表示召回率,分类正确的信息条数与样本中正确的信息条数之比,f表示准确率与召回率的调和平均数。
基于情绪的情感分析算法加入紧张词和放松词强度检测部分,使用adaboost算法预测原始文本的情感极值,从而提高情感分析技术的实验效果。
通过翻译工具将文献《stressandrelaxationmagnitudedetectionforsocialmediatexts》构造的英文紧张词和放松词词典进行中文翻译,去除其中重复部分,共得到2043个标注词语;然后手动添加74个中文相似语义的词汇,按照出现在已标注词语中的紧张值和放松值对其同义词进行标注,共得到2117个标注词语。
通过调整svm分类算法对不同情感类别的权重值,发现消极、中立和积极三个类别的权重比为40:32:40时,svm分类算法达到较佳的实验效果。
通过svm分类算法得到紧张词和放松词强度检测的情感分析结果,将其与语料库扩展的情感分类算法所预测的原始语料库文本的情感极性o_senti进行匹配,将匹配对作为实验输入,采用adaboost模型进行集成,获得最终结果。经过参数调整,设置分类树个数参数为15。
将desa算法对扩展语料库和对原始语料库的实验结果与etc算法的结果进行详细的对比,准确率效果比较如图1所示,f值效果比较如图2所示。
本发明提供了一种基于情绪的文本分类算法,它的具体实施方案包括:
步骤s0101:获取原始语料库,并根据研究目的将原始语料库中的所有信息构造成相应的字符串并按照需求对其进行初步匹配,去除无用数据信息,构造文本和其真实情感极性值truevalue的匹配对集合。
步骤s0201:文本内容通常包含微博平台自身规定的特有的符号,并将剩余部分进行文本分词处理。
步骤s0301:数据预处理之后,需要对语料库文本进行否定词检测,根据不同情感类别对语料库进行扩展,产生新的语料库文本;并根据原始语料库的原始极性值o_senti,赋予新构造的语料库文本以新的极性值n_senti;并将新的扩展语料库加入原始语料库集,形成扩展语料库。
步骤s0302:使用英文紧张词和放松词标注词典,通过百度翻译等工具转换成中文,并向中文词典中手动添加部分相关的词语。
步骤s0401:获取扩展语料库,通过r语言中中文分词软件包rwordseg对文本内容分词处理。
步骤s0501:通过相应的特征选择算法,提取并整理文本内容中的特征,构造尽可能贴近原始文本内容含义的特征集,形成特征向量空间。
步骤s0601:根据中文情绪词典,检测原始语料库文本是否包含紧张词和放松词,提取原始语料库文本内容中最大的紧张值stress和最大的放松值relation,使之作为特征集的一部分进行处理。
步骤s0602:将步骤s0501中的特征向量空间作为输入,使用随机森林算法进行文本情感分类,判断扩展语料库的情感倾向。
步骤s0701:采用svm算法对新的特征向量进行分类,得到原始语料库的情感倾向值。
步骤s0702:从步骤s0602中取得原始语料库文本的分类极性o_senti和新构造的语料库文本的分类极性n_senti,使用adaboost算法进行分类,构造多分类器模型,获得原始语料库的最终分类情感极性。
步骤s0801:将紧张词和放松词强度检测的情感分析结果提取出来,并结合语料库扩展的情感分类算法的最终分类情感极性一起输入adaboost算法,构造最终分类器h(x)={h1(x),h2(x),…,ht(x)},其中x为数据集,x为数据实例,hi(x)为弱分类器;使用最终分类器进行集成,获得该语料库文本的最终分类情感极性。
本发明所述的一种基于情绪词典进行文本分类的方法,它是在语料库扩展的情感分类算法基础上考虑了情绪的因素的文本分类算法。实验证明,基于情绪的文本分类算法的分类效果更准确。
- 还没有人留言评论。精彩留言会获得点赞!