基于前缀森林的ip索引方法与流程
本发明涉及ip地址段索引领域。具体涉及基于前缀森林的ip索引方法。
背景技术:
术语定义:
ip:internetprotocol.因特网协议是为计算机网络相互连接进行通信而设计的协议。
ipaddress:internetprotocoladdress.因特网协议地址是因特网协议中为因特网上的每台计算机和其它设备都规定的一个唯一的地址。
cidrnotation:classlessinter-domainroutingnotation.无类别域间路由表示法是一种表示ip地址段的方法,由ip地址前缀和掩码两部分组成。掩码内部分等于ip地址前缀的ip地址都属于这一段ip地址段。
trie:又称前缀树或字典树,是一种有序树。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串。
二叉树:每个节点最多有两个子树的树结构。
叶节点:一棵树当中没有子结点的结点。
索引:是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
时间复杂度:定量描述算法运行时间的函数。
现在越来越多的网络服务会根据访客的ip地址查询出对应的信息(如地理位置)后使用相匹配的语言、时区等配置以及提供个性化的服务,甚至根据ip地址赋予差异化的用户权限,从而提升用户体验和保障安全性,通常,ip地址与其索引的信息呈现“多对一”的映射关系,并且有相同信息的ip地址成段出现,因此ip地址的索引问题等价于ip地址的段的索引问题。
现有技术通常以每个ip地址段的起始地址来唯一标识一段ip地址。查询时按顺序遍历起始地址(这里默认顺序是从小到大),当某一起始地址大于要查询的地址时,获取上一个起始地址所索引的数据块并返回。
例如:用4.30.42.207代表4.30.42.207~4.30.42.255这个ip地址段,用4.30.43.0代表下一个ip地址段。当查询ip地址4.30.42.233时,遍历到4.30.43.0时首次发现4.30.43.0大于4.30.42.233,因此认为4.30.42.233位于前一个也就是4.30.42.207~4.30.42.255这个ip地址段。于是返回4.30.42.207所指向的数据块。
通常会在这种线性遍历之前,加入8位或16位的二级索引,以提高性能。仍然以查询4.30.42.233为例:其前16位是4.30(十进制为1054),于是在二级索引中查询第1054个数据块,这个数据块存储了4.30.0.0这个ip地址段的位置,于是直接跳转到4.30.0.0处开始上述的线性遍历。
现有技术的线性遍历方式逻辑简单,易于实现,适合小规模的应用,但随着ip数据库的丰富,ip地址分段必然越来越多,线性遍历的时间复杂度也会随之等比例上升,无法保证将查询控制在一个常数时间内。
技术实现要素:
本发明的目的是针对上述背景技术中的缺陷,提供一种基于前缀森林的ip索引方法,实现降低ip索引的复杂度,压缩索引数据的大小,节省大量的存储空间的效果。
为了达到上述的技术效果,本发明采取以下技术方案:
基于前缀森林的ip索引方法,包括如下步骤:
步骤一:创建索引;
将ip地址段用cidr表示法表示,按前16位分别添加到65536棵二叉trie树中的某一棵,对后面在掩码范围内的每一位添加一个0或1的子节点,最后添加的一个子节点成为叶子节点,存储着到达这一叶子节点的最短路径所代表的ip地址段所索引的数据块的位置;
步骤二:查询ip地址。
由前16位的值直接定位到一棵二叉trie树,根据ip地址后面的每一位沿二叉trie树走到叶子节点,取到叶子节点中索引的位置,按此位置查询到目标数据。
本发明与现有技术相比,具有以下的有益效果:本发明将前缀森林应用到ip索引中,在创建索引时,将ip地址段用cidr表示法表示,同时引入二叉树和节点概念,在查询ip地址时,同样根据这些二叉树和节点查询目标数据。与传统线性遍历方式相比较,该前缀森林索引方式大大降低了ip索引的复杂度,每次查询的时间复杂度由o(n)降低到了o(1),同时该方式不用表示出完整的ip地址,压缩了索引数据的大小。
附图说明
图1是本发明的逻辑示意图;
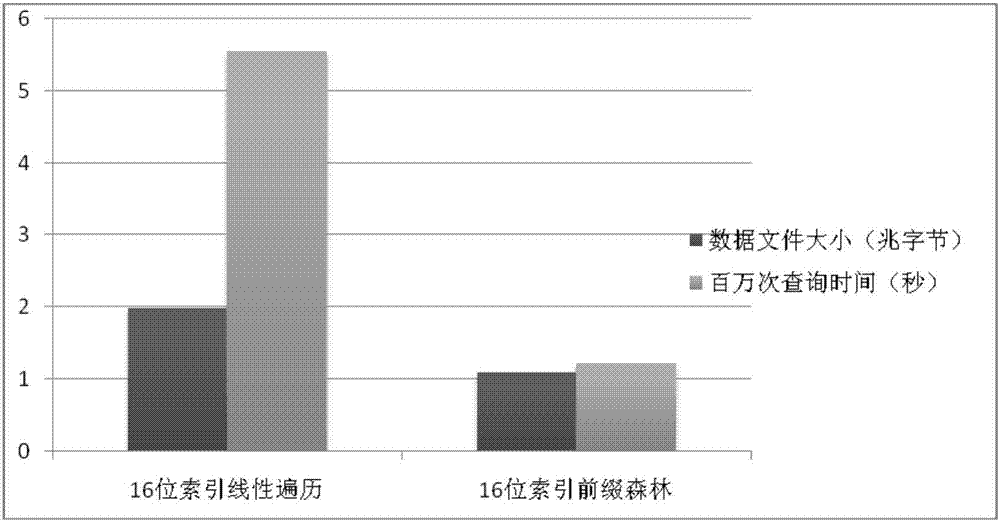
图2是本发明的效果示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
图1是本发明的逻辑示意图,如图所示本发明主要分为创建索引和查询ip:
创建索引时,将ip地址段用cidr表示法表示,按前16位分别添加到65536棵二叉trie树中的某一棵,对后面在掩码范围内的每一位添加一个0或1的子节点,最后添加的一个子节点成为叶子节点,存储着到达这一叶子节点的最短路径所代表的ip地址段所索引的数据块的位置。
查询ip地址时,由前16位的值直接定位到一棵二叉trie树,根据ip地址后面的每一位沿二叉trie树走到叶子节点,取到叶子节点中索引的位置,按此位置查询到目标数据,图中粗箭头指出了在这个数据库中4.30.255.13这个ip地址的查询过程。
下面以4.30.255.13这个ip地址为例具体说明:
创建索引:将ip地址段用cidr表示法表示,按前16位分别添加到65536棵二叉trie树中的某一棵,对后面在掩码范围内的每一位添加一个0或1的子节点,最后添加的一个子节点成为叶子节点,存储着到达这一叶子节点的最短路径所代表的ip地址段所索引的数据块的位置。
查找过程:由前16位4.30先定位到某个二叉trie树,再根据后16位255.13地址后面的每一位沿二叉trie树走到叶子节点,取到叶子节点中索引的位置,按此位置查询到目标数据。
图2是本发明的效果示意图,该图表示了16.8万条地理信息的数据库中线性遍历和前缀森林性能的对比,由图可见,本发明技术方案带来的效果显而易见,以前缀森林索引ip地址段,每次查询的时间复杂度由o(n)降低到了o(1),压缩了索引数据的大小。
trie树又叫前缀树,trie树有两种实现,一种是是二十六叉树方式实现;另一种是二叉树方式实现,就是将一个节点的第一个儿子放在左儿子的位置,下一个儿子,即左儿子的第一个兄弟,放在左儿子的右儿子位置上,再下一个兄弟接着放在右儿子的右儿子的位置。本发明将前缀森林应用到ip索引中,在创建索引时,将ip地址段用cidr表示法表示,同时引入二叉树和节点概念,在查询ip地址时,同样根据这些二叉树和节点查询目标数据。从ip地址段的cidr表示法中暗含的前缀表达思想中,我们可以看到二叉trie树在ip地址段索引中应用的可能:ip地址的位数固定为32,因此查询一个ip地址所需要的读取次数被限制在32次以内,时间复杂度为常数,与数据库的增长无关;二叉trie树的每一层都是ip地址的某一位,用一个位的空间即可表达,不用存下完整的32位ip地址,这会节省大量的存储空间。另外,经过统计,一份16万段的ip地理数据库中,多达94%的ip地址段在用cidr表示法表示时其掩码的位数大于16。在类似场景里,可以使用与现有技术相同的16位二级索引,索引到一个由65536棵二叉trie树构造的前缀森林中。综上所述,与传统线性遍历方式相比较,该前缀森林索引方式大大降低了ip索引的复杂度,每次查询的时间复杂度由o(n)降低到了o(1),同时该方式不用表示出完整的ip地址,压缩了索引数据的大小。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!