分布式文件系统及节省分布式文件系统存储空间的方法与流程
本发明涉及计算机技术领域,具体涉及一种分布式文件系统及节省分布式文件系统存储空间的方法。
背景技术:
计算机通过文件系统来管理和存储数据。随着互联网技术的迅猛发展,人们可以获取的数据逐渐成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量的方式,在容量大小、容量增长速度、数据备份、数据安全等方面的表现都差强人意。而分布式文件系统可以有效解决数据的存储和管理难题:将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点中获取文件的,只需要像使用本地文件系统那样来管理和存储文件系统中的数据。分布式文件系统的这些优点使得它很快就得到了大规模的应用。
而通常的分布式文件系统通常采用了三副本机制来保证数据的可靠性和可用性。也就是说,每一个存储于分布式文件系统的文件,实际上都存储了三份拷贝。三副本机制不仅提高了数据的可靠性,当某一份数据丢失时,可以采用另外两份副本进行数据恢复,而且三副本能起到比较好的负载均衡的功能。然而,这种方法的成本比较高,它消耗的存储空间是实际存储容量的三倍。而且如果当服务器的磁盘阵列采用了类似raid5之类的技术,且在这些服务器节点的基础之上部署了分布式文件系统,那么实际的存储空间消耗会更多。如果进一步考虑存储硬件、机房的消耗、电量消耗等一系列的问题,那么存储成本是比较高的。而且随着数据存储量的不断增大,这个成本问题还会更加突出。
有鉴于此,我们设计并实现了一种节省分布式文件系统存储空间的方法,可以有效地降低存储空间的消耗问题,对于数据中心建设、云计算平台建设等方面可以大大节省成本。
技术实现要素:
本发明克服了现有技术的不足,提供一种分布式文件系统。
为解决上述的技术问题,本发明采用以下技术方案:
一种分布式文件系统,其特征在于,它包括内置在该系统内的客户端、命名节点或存储节点,所述客户端由若干个访问终端构成,所述命名节点和存储节点为单个虚拟机、docker容器或物理服务器。
本发明还可以提供一种节省分布式文件系统存储空间的方法,它包括以下步骤:
步骤1,在分布式文件系统的配置文件中设定冷文件区域和热文件区域区分的热度阀值;
步骤2,将新写入的文件存入分布式文件系统的冷文件区域;
步骤3,在存储节点内对新写入冷文件区域的文件存储采用纠错码的方式存储;
步骤4,在命名节点内的文件元数据信息中,增加单位时间、起始访问时间、访问次数、开始访问时间或热度值;
热度值=访问次数÷(开始访问时间-起始访问时间)÷单位时间;
步骤5,客户端请求一次要访问的文件,就对该文件的文件元数据信息中的访问次数增加一次,并新增加一个开始访问时间,同时计算该文件的热度值;
步骤6,将步骤5中文件的热度值和热度阀值进行比较,如果文件的热度值大于热度阀值,则转向步骤7,否则转向步骤8;
步骤7,将文件移入热文件区域,同时随机选择一个热文件的副本,返回给客户端;
步骤8,在存储节点查找冷文件,将冷文件并通过纠错码计算后返回给客户端。
优选的,分布式文件系统根据不同的业务,所设置的区分冷文件和热文件的热度阀值是不同的。
优选的,所述热文件区域的文件采用三副本的方式存储。
与现有技术相比,本发明的有益效果是:
本发明对于数据中心建设、公有云或私有云建设方面有很强的实用价值,可以有效地降低存储成本,提升存储空间的利用率。在实际检验中我们发现,可以减少采购存储设备的数量30%以上。
附图说明
图1为本发明一种实施例的分布式文件系统的框架示意图。
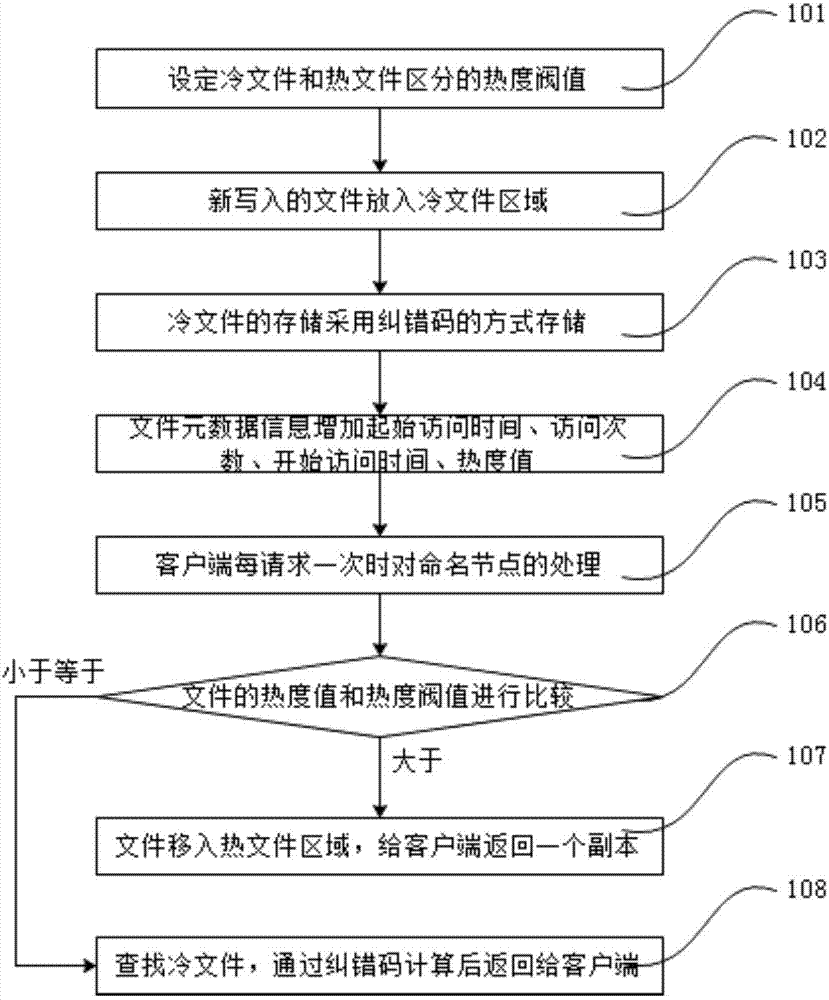
图2为本发明一种实施例的节省分布式文件系统存储空间的方法流程图。
具体实施方式
下面结合附图对本发明作进一步阐述。
如图1所示的一种分布式文件系统,它包括内置在该系统内的客户端、命名节点或存储节点,所述客户端由若干个访问终端构成,所述命名节点和存储节点为单个虚拟机、docker容器或物理服务器,。
如图2所示的一种节省分布式文件系统存储空间的方法,它包括以下步骤:
步骤101:在分布式文件系统的配置文件中设定冷文件区域和热文件区域区分的热度阀值;
分布式文件系统根据不同的业务,所设置的区分冷文件和热文件的热度阀值是不同的,故这个热度阀值是一个可变阀值。
步骤102:将新写入的文件存入分布式文件系统的冷文件区域,假设客户端请求访问文件a;
步骤103:在存储节点对新写入冷文件区域的文件的存储采用纠错码的方式存储,以减少分布式文件系统存储空间的占用,以纠错码方式存储的文件,占用的存储空间大约为原始文件存储空间的1.5倍左右;
步骤104:在命名节点内的文件元数据信息中,增加单位时间、起始访问时间、访问次数、开始访问时间或热度值;
热度值=访问次数÷(开始访问时间-起始访问时间)÷单位时间;
步骤105:客户端每请求一次要访问某个文件(可假设为a文件),就对a文件的元数据信息中的访问次数+1,并新记录一个开始访问时间,同时计算并更新热度值;
步骤106:将a文件的热度值和热度阀值进行比较。如果a文件的热度值大于热度阀值,则转向步骤107,否则转向步骤108。
步骤107:将文件移入热文件区域,同时随机选择一个热文件的副本,返回给客户端。
步骤108:在存储节点查找冷文件,将冷文件并通过纠错码计算后返回给客户端。
热文件区域采用三副本的方式存储,以保证较高的访问效率。存储三副本需要原始文件存储空间三倍以上的存储空间。
本发明充分利用了对冷热文件的不同的存储处理方式,以便尽可能节省分布式文件系统的存储空间;同时还可以根据不同的具体业务细分冷热文件的热度,以便进一步实现更高效率地分布式文件系统存储空间的利用。
统一命名术语,规定为分布式文件系统由命名节点和存储节点构成。命名节点也有叫跟踪节点的,它负责存储文件系统的命名空间,包括文件的元数据等信息,命名节点为多台服务器的集群;而存储节点为文件系统实际存储的服务器,它也是服务器的集群。
以上具体实施方式对本发明的实质进行详细说明,但并不能对本发明的保护范围进行限制,显而易见地,在本发明的启示下,本技术领域普通技术人员还可以进行许多改进和修饰,需要注意的是,这些改进和修饰都落在本发明的权利要求保护范围之内。
技术特征:
技术总结
本发明公开了一种节省分布式文件系统存储空间的方法其步骤依次为:设定冷文件和热文件区分的热度阀值;新写入的文件放入冷文件区域;冷文件的存储采用纠错码的方式存储;文件元数据信息增加起始访问时间、访问次数、开始访问时间、热度值;客户端每请求一次时对命名节点的处理;文件的热度值和热度阀值进行比较。如果大于热度阀值,则转文件移入热文件区域,给客户端返回一个副本,否则转查找冷文件,通过纠错码计算后返回给客户端;同时公开分布式文件系统,该系统它包括内置在该系统内的客户端、命名节点或存储节点;本发明充分利用了对冷热文件的不同的存储处理方式,以便尽可能节省分布式文件系统的存储空间。
技术研发人员:李强;王凤琴
受保护的技术使用者:四川长虹电器股份有限公司
技术研发日:2017.04.27
技术公布日:2017.09.15
- 还没有人留言评论。精彩留言会获得点赞!