一种基于同源余弦损失函数的人物识别方法与流程
本发明涉及人物识别领域,尤其是涉及了一种基于同源余弦损失函数的人物识别方法。
背景技术:
随着智能手机和数码相机的出现,人们通过拍摄更多的照片来记录日常生活和故事,因此人们希望能够识别个人数据,如从社交媒体或互联网的成千上万个图像中的识别不同时间和空间的同一个人。人物识别涵盖了数字图像处理、神经网络、计算机视觉以及人工智能等各个方面的内容,在公安、金融、网络安全、物业管理、考勤制度以及人们日常相册整理等都有广泛的应用。多人物中的人脸识别则可以应用在机场、火车站等人流量密集的场所,可以在密集的人群中识别出目标人物,如可疑人员等,这对提高公共安全有着重要作用。然而,由于受到非正面、光和照明的变化,外观的变化等因素的影响,在无约束环境中的人物识别仍然是一个具有挑战性的问题。
本发明提出了一种基于同源余弦损失函数的人物识别方法,先为头部标记真实数据,并检测脸部和身体区域,接着使用人物姿态估计器进行人物姿态估计,识别人体关键部位,从而找到上身区域,再将每个区域(补丁)对齐到基本位置,减轻内部类别的差异,然后送入深度模型,获得有代表性和鲁棒的特征,最后使用同源余弦损失函数训练深度模型。本发明扩大了类之间的区别,缩小了内部的差异,从而具有更好的分类精度,准确度也有所提高;利用强大的多个深层模型,可以无需对测试集进行第二次训练。
技术实现要素:
针对受到非正面、光和照明的变化,外观变化等影响的问题,本发明的目的在于提供一种基于同源余弦损失函数的人物识别方法,先为头部标记真实数据,并检测脸部和身体区域,接着使用人物姿态估计器进行人物姿态估计,识别人体关键部位,从而找到上身区域,再将每个区域(补丁)对齐到基本位置,减轻内部类别的差异,然后送入深度模型,获得有代表性和鲁棒的特征,最后使用同源余弦损失函数训练深度模型。
为解决上述问题,本发明提供一种基于同源余弦损失函数的人物识别方法,其主要内容包括:
(一)为头部标记真实数据并检测脸部和身体区域;
(二)姿态估计;
(三)补丁对齐并送入深度模型;
(四)使用同源余弦损失函数训练深度模型。
其中,所述的为头部标记真实数据并检测脸部和身体区域,用四个区域的特征r∈{1,…,4},即脸、头、全身和上身来识别一个人;每个区域遵循训练和特征提取程序;在区域建议网络(rpn)中预先训练脸部检测器;使用残差网络模型,删除图层并添加分类和回归两个损失函数;对训练集的脸部模型进行分类;脸部检测器识别脸部(眼睛、眉毛、嘴巴等)的m个关键点,并且通过平移、旋转和缩放让检测到的脸部补丁对准“基本”形状;令
其中,
进一步地,所述的身体区域检测,为了检测身体部分,在rpn框架中预先训练检测器;网络结构是一个初始模型,最终的池层由完全连接的层替代。
其中,所述的通过人体姿态估计识别身体的关键点,确定上半身区域,从而通过这些点定位上身部分。
其中,所述的补丁对齐并送入深度模型,通过将每个区域(补丁)对齐到人体的基本位置,从而减轻内部类别的差异,然后将对齐的补丁送入深度模型,获得有代表性和鲁棒的特征。
其中,所述的使用同源余弦损失函数训练深度模型,使用同源余弦损失函数具有代表性的深层特征,能更好地区分不同类别的样本,并最大程度地减少某一个类别中的差异;首先,定义两个特征f(i)的余弦相似度c(f(i),f(j)),
其中,
令li,lj∈{1,…,k}为样品i,j的标签,其中k是类别的总数,w是网络的权重,则有以下损失函数最大化:
其中,
进一步地,所述的特征平均值,将k类的质心定义为小型
结合公式(3),有以下输出样本i最大化:
分子确保样本i足够接近其本身li,分母限制与其他类别样本的最小距离;指数运算是将余弦相似度转移到范围从0到1的归一化概率输出。
进一步地,所述的同源余弦损失函数,以协作的方式扩大类别之间的差异:
实际上,同源余弦损失可以通过softmax操作以整齐的方式实现。
进一步地,所述的归一化,归一化特征和质心,即
其中,m根据
进一步地,所述的梯度,输入特征f(i)和质心ck的梯度,以元素的方式,如下:
其中,tk是来自标签li的向量化映射;集群质心ck是可学习的参数,只使用公式(4)初始化网络。
附图说明
图1是本发明一种基于同源余弦损失函数的人物识别方法的系统流程图。
图2是本发明一种基于同源余弦损失函数的人物识别方法的算法训练流程图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
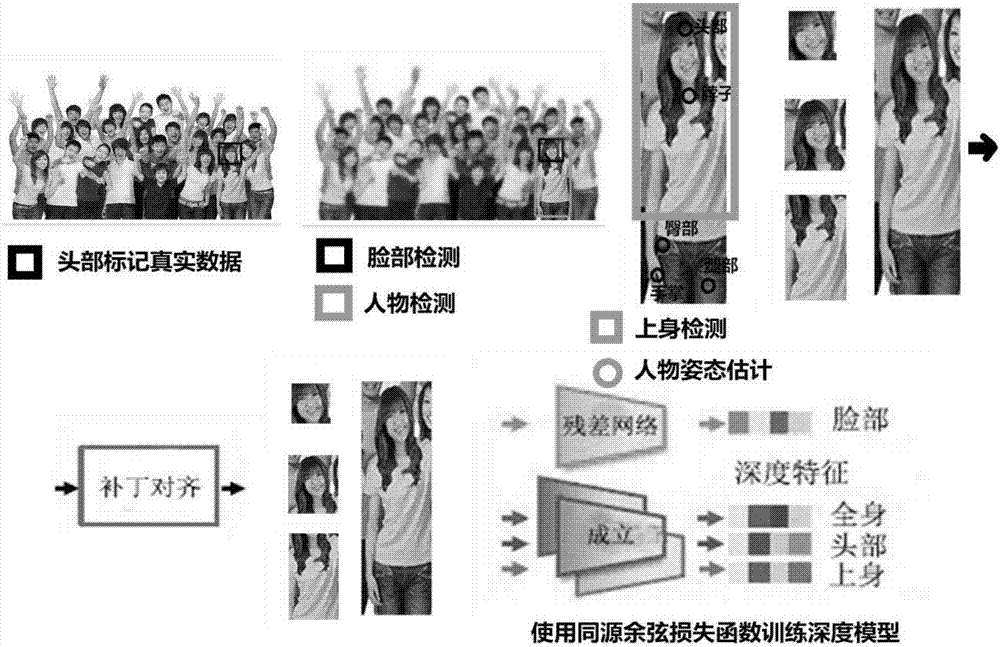
图1是本发明一种基于同源余弦损失函数的人物识别方法的系统流程图。主要包括为头部标记真实数据并检测脸部和身体区域,姿态估计,补丁对齐并送入深度模型,使用同源余弦损失函数训练深度模型。
为头部标记真实数据并检测脸部和身体区域,用四个区域的特征r∈{1,…,4},即脸、头、全身和上身来识别一个人;每个区域遵循训练和特征提取程序;在区域建议网络(rpn)中预先训练脸部检测器;使用残差网络模型,删除图层并添加分类和回归两个损失函数;对训练集的脸部模型进行分类;脸部检测器识别脸部(眼睛、眉毛、嘴巴等)的m个关键点,并且通过平移、旋转和缩放让检测到的脸部补丁对准“基本”形状;令
其中,
为了检测身体部分,在rpn框架中预先训练检测器;网络结构是一个初始模型,最终的池层由完全连接的层替代。
姿态估计,通过人体姿态估计识别身体的关键点,确定上半身区域,从而通过这些点定位上身部分。
补丁对齐并送入深度模型,通过将每个区域(补丁)对齐到人体的基本位置,从而减轻内部类别的差异,然后将对齐的补丁送入深度模型,获得有代表性和鲁棒的特征。
使用同源余弦损失函数训练深度模型,其特征在于,使用同源余弦损失函数具有代表性的深层特征,能更好地区分不同类别的样本,并最大程度地减少某一个类别中的差异;首先,定义两个特征f(i)的余弦相似度c(f(i),f(j)),
其中,
令li,lj∈{1,…,k}为样品i,j的标签,其中k是类别的总数,w是网络的权重,则有以下损失函数最大化:
其中,
将k类的质心定义为小型
结合公式(3),有以下输出样本i最大化:
分子确保样本i足够接近其本身li,分母限制与其他类别样本的最小距离;指数运算是将余弦相似度转移到范围从0到1的归一化概率输出。
同源余弦损失函数,以协作的方式扩大类别之间的差异:
实际上,同源余弦损失可以通过softmax操作以整齐的方式实现。
归一化特征和质心,即
其中,m根据
输入特征f(i)和质心ck的梯度,以元素的方式,如下:
其中,tk是来自标签li的向量化映射;集群质心ck是可学习的参数,只使用公式(4)初始化网络。
图2是本发明一种基于同源余弦损失函数的人物识别方法的算法训练流程图。先为头部标记真实数据,并检测脸部和身体区域,接着使用人物姿态估计器进行人物姿态估计,识别人体关键部位,从而找到上身区域,再将每个区域(补丁)对齐到基本位置,减轻内部类别的差异,然后送入深度模型,获得有代表性和鲁棒的特征,最后使用同源余弦损失函数训练深度模型。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!