一种基于分词的模糊语句搜索方法与流程
本发明涉及一种基于分词的模糊语句搜索方法,属于信息安全技术领域。
背景技术:
在网络日益发达的今天,有益信息与造成不稳定因素的信息也随之日益泛滥,为了网民的思想健康,也为了社会的和谐,在许多对外公共场合下,有些内容是要经过审查才能显示的。在网络审查初期,都是通过人工审核,这种审核方式虽然准确且智能,但是与网络文字产生的速度相比,其效率就显的微不足道了!现阶段虽然通过关键词自动过滤,但是准确性非常低,容易过滤到本身不是不良内容的信息,同时也无法保证将相关的不良内容全部过滤掉。
现阶段,常见的词语搜索算法有两种,一种是基于分词的词语搜索,另一种是基于多模匹配的词语搜索。基于的分词的搜索,即先对原文进行分词,然后对要搜索的关键字进行匹配,但是这种算法只能对词语进行搜索,对语句无法匹配;基于多模匹配的搜索,即使用acbm、wu-manber等算法进行匹配,既可以搜索词语也可以搜索语句,但是无法分析语义。
这两种算法有一种情况均无法匹配,如,以关键字“某地出租车停业”为例,但是原文中内容为“停业某地出租车”或者“某地的出租车停业”,这样子就无法搜索到该关键字,虽然可以通过缩小或更换关键词的方式进行搜索,但是搜索结果的混乱性很大,情况太多,缩小或更换的关键字可能不完整,而且会大大降低搜索的速率。
可见基于分词的词语搜索、基于多模匹配的词语搜索两种搜索算法存在不足,不能对做过混淆、词语顺序跟换过的语句进行搜索。
技术实现要素:
本发明的目的在于提供一种基于分词的模糊语句搜索方法,用以解决现有方法不能对做过混淆、词语顺序跟换过的语句进行搜索的问题。
本发明解决上述技术问题的技术方案如下:一种基于分词的模糊语句搜索方法,所述的搜索方法包括如下步骤:
步骤一:对待检索范围内的原文进行分词,记录每个分词在原文中的起始位置;
步骤二:原文进行分词后,对重复出现的词语进行合并,并记录每个重复出现的词语在原文中的起始位置;
步骤三:对需要检索的关键字进行分词,关键字分词的个数记为i,待检索范围内的原文中至少出现一次的关键字分词的个数记为w;
步骤四:计算关键字分词在检索范围内的原文的出现率p,p=w/i,出现率p大于预设定的数值,对原文的分词结果使用关键字的分词结果进行搜索,得到每个关键字分词在原文中出现的位置,出现率p小于预设定的数值,退出搜索;
步骤五:计算不同关键字分词在原文中出现的位置之间的距离d,比较距离d与相应关键词自身长度之间的差值k是否在容许的数值范围内,差值k在容许的数值范围内,匹配到模糊搜索的结果。
需要说明的是分词可以采用现有的分词算法如基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法,分词方法属于现有技术。
基于分词的模糊语句搜索方法中,所述的起始位置指分词结果第一个文字的初始字符位置,待检索范围内的原文字符编号自0开始。以“停业某地出租车”为例,分词为“停业”“某地”“出租车”三个结果,分词“停业”的位置为0。
基于分词的模糊语句搜索方法中,所述的待检索范围内的原文、需要检索的关键字采用utf-8编码格式。utf-8编码格式是一种针对unicode的可变长度字符编码,又称万国码,utf-8编码格式下,根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。utf-8编码可以通过屏蔽位和移位操作快速读写。字符串比较时strcmp()和wcscmp()的返回结果相同,因此使排序变得更加容易。
基于分词的模糊语句搜索方法中,所述的步骤三中关键字分词在原文中至少出现一次记为1,关键字分词在原文中没有出现记为0,w为至少出现一次的关键字分词个数。需要进一步说明的是w并非关键字分词在原文中出现的次数,而是在原文中有出现情况的关键字分词个数,以“停业某地出租车”为例,分词为“停业”“某地”“出租车”三个结果,在待检索的原文范围内如果“停业”一次没有出现,而“某地”“出租车”两个词均有出现,不管“某地”“出租车”在待检索的原文范围内出现几次,此时的w则为2。
基于分词的模糊语句搜索方法中,所述的步骤四中出现率p大于等于0小于等于1,出现率指的是关键字分词在待检索范围内的原文出现过的个数占关键字分词个数的比例,关键字分词在原文中出现多次表示该关键字分词在原文中出现,关键字分词在待检索范围内的原文出现过的个数记录增加1个;所述的预设定的数值为大于等于0小于等于1的值,预设定的数值越接近于1表示关键字分词在原文中的出现率越大,p大于预设定的数值存在对原文的分词结果使用关键字的分词结果进行搜索的必要性。以“停业某地出租车”为例,分词为“停业”“某地”“出租车”三个结果,在待检索的原文范围内如果“停业”一次没有出现,而“某地”“出租车”两个词均有出现,此时的w则为2,关键字“停业某地出租车”分词个数为3,此时,出现率p则为2/3,由于w的值不可能超过分词个数3,因此出现率p大于等于0小于等于1,设预设定的数值为3/4,出现率p为2/3大于3/4,因此存在对原文的分词结果使用关键字的分词结果进行搜索的必要性。在待检索的原文范围内如果“停业”“某地”一次没有出现,而只有“出租车”一个词有出现,此时出现率p则为1/3,出现率p为1/3小于预设定的数值3/4,因此没必要对原文的分词结果使用关键字的分词结果进行搜索。可见预设定的数值根据检索的准确性确定,预设定的数值越大检索的准确性越高。
基于分词的模糊语句搜索方法中,所述的步骤五中距离d与相应关键词自身长度之间的差值k超出容许的数值范围,退出该检索结果的显示;所述的容许的数值范围根据差值k与相应关键词自身长度确定,差值k与相应关键词自身长度相等说明原文中不存在混淆、词语顺序现象,差值k与相应关键词自身长度存在数值差表示关键词在原文中存在混淆、词语顺序现象,差值k与相应关键词自身长度存在数值差越大表示原文中存在混淆、词语顺序现象可能性越小。距离d与相应关键词自身长度之间的差值k超出容许的数值范围,表明待检索范围内的原文内容不存在与检索关键字相同或类似的内容,也就不存在检索结果的展示,距离d与相应关键词自身长度之间的差值k在容许的数值范围内,表明待检索范围内的原文内容存在与检索关键字相同或类似的内容,将检索结果及做过混淆、词语顺序跟换过的结果也一一检索出来,更详细的说明将在下文具体实施方式中做进一步交代。
基于分词的模糊语句搜索方法中,所述的步骤五中不同关键字分词指的是对关键字进行分词后的不同分词结果,不同分词结果在原文中出现的位置之间的距离d。以“停业某地出租车”为例,分词为“停业”“某地”“出租车”三个结果,在待检索的原文中可能做过混淆、词语顺序跟换,因此需要计算“停业”“某地”“出租车”三者之中两两之间的在原文中出现的位置之间的距离d。
基于分词的模糊语句搜索方法中,所述的分词是指对语句的拆分,将语句拆分为字、词组。对关键字的拆分并不限于词组,可以是单个文字或多个文字。
本发明方法具有如下优点:通过对待检索范围内的原文进行分词,记录每个分词在原文中的起始位置;原文进行分词后,对重复出现的词语进行合并,并记录每个重复出现的词语在原文中的起始位置;对需要检索的关键字进行分词,关键字分词的个数记为i,待检索范围内的原文中至少出现一次的关键字分词的个数记为w;计算关键字分词在检索范围内的原文的出现率p,p=w/i,出现率p大于预设定的数值,对原文的分词结果使用关键字的分词结果进行搜索,得到每个关键字分词在原文中出现的位置,出现率p小于预设定的数值,退出搜索;计算不同关键字分词在原文中出现的位置之间的距离d,比较距离d与相应关键词自身长度之间的差值k是否在容许的数值范围内,差值k在容许的数值范围内,匹配到模糊搜索的结果。可以实现对做过混淆、词语顺序跟换过的语句进行检索,检索结果更加准确,提高了检索效率,有效地保护了国家信息的安全,促进社会的和谐与稳定。
附图说明
图1基于分词的模糊语句搜索方法流程示意图;
图2基于分词的模糊语句搜索方法的算法简图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1所示,一种基于分词的模糊语句搜索方法,搜索方法包括如下步骤:
s1:对待检索范围内的原文进行分词,记录每个分词在原文中的起始位置;
s2:原文进行分词后,对重复出现的词语进行合并,并记录每个重复出现的词语在原文中的起始位置;
s3:对需要检索的关键字进行分词,关键字分词的个数记为i,待检索范围内的原文中至少出现一次的关键字分词的个数记为w;
s4:计算关键字分词在检索范围内的原文的出现率p,p=w/i,出现率p大于预设定的数值,对原文的分词结果使用关键字的分词结果进行搜索,得到每个关键字分词在原文中出现的位置,出现率p小于预设定的数值,退出搜索;
s5:计算不同关键字分词在原文中出现的位置之间的距离d,比较距离d与相应关键词自身长度之间的差值k是否在容许的数值范围内,差值k在容许的数值范围内,匹配到模糊搜索的结果。
下面以原文为“停业某地出租车,我爱某地观景点,观景点上太阳升,某地的出租车停业”,搜索关键字为“某地出租车停业”为例对本发明方法做更详细的阐述。
第一步:对原文分词,分词结果为“[{"word":"停业","offset":0},{"word":"某地","offset":6},{"word":"出租","offset":12},{"word":"租车","offset":15},{"word":"出租车","offset":12},{"word":",","offset":21},{"word":"我","offset":24},{"word":"爱","offset":27},{"word":"某地","offset":30},{"word":"观景","offset":36},{"word":"观景点","offset":36},{"word":",","offset":45},{"word":"观景","offset":48},{"word":"观景点","offset":48},{"word":"上","offset":57},{"word":"太阳","offset":60},{"word":"太阳升","offset":60},{"word":",","offset":69},{"word":"某地","offset":72},{"word":"的","offset":78},{"word":"出租","offset":81},{"word":"租车","offset":84},{"word":"出租车","offset":81},{"word":"停业","offset":90}]”,其中word为分词的结果,offset表示该词在原文中的位置。
第二步:由于对原文分词后,有些词语会出现多次,如某地在offset=6、offset=72等多个位置都有出现,所以对分词的结果做个处理,将重复的词语合并。合并后结果如下:
{出租:[12,81],
停业:[0,90],
爱:[27],
上:[57],
某地:[6,30,72],
出租车:[12,81],
租车:[15,84],
我:[24],
,:[21,45,69],
观景:[36,48],
观景点:[36,48],
太阳:[60],
太阳升:[60],
的:[78]
}
“:”左边为词语,右边为offset数组。
第三步:对关键字也进行分词处理,分词结果如下:
["停业","某地","出租车"]
关键字不需要记录offset。
第四步:对原文的分词结果使用关键字的分词结果进行搜索,得到如下结果:
[
停业:[0,90],
某地:[6,30,72],
出租车:[12,81]
]
可得出关键字分词结果在原文中出现的位置。此处可设置一个出现率:
出现率=关键字分词结果在原文中出现的次数/关键字分词结果个数,可见出现率是大等于0小等于1的数,只有真正的出现率大于设置的出现率,才进入下一步。如果将出现率设置为0.75,此事例中出现率为3/3=1,显然1>0.75,可进入下一步计算。
如果提供的关键字为“出售香烟”,分词结果为["出售","香烟"],则此处["出售","香烟"]在所给待检索原文中的出现率为0/2=0,退出查找。
第五步:对第四步结果中offset比较,计算最短距离。
由于使用了utf8编码,第四步结果中几个词语的长度分别是:
[
停业:6,
某地:6,
出租车:9
]。
比较可得
[
停业:0
某地:6
出租车:12
],这三组offset最短距离为6,符合。所以位置为0处匹配到关键字。
[
停业:90
某地:72
出租车:81
],这三组中“出租车”与“停业”最小距离为9符合,但是“某地”与“出租车”最短距离却为9,实际相差应该是6才对,这里我们可以设置一个允许两个词相差的最大值来规避这个问题。如果该值设置为5,那么9-6=3<5,所以符合。位置为72处同样匹配到关键字。
所以匹配到的结果为“停业某地出租车”和“某地的出租车停业”。达到模糊匹配的效果。从而有效地解决了传统算法无法检索出做过混淆、词语顺序跟换过的搜索问题。
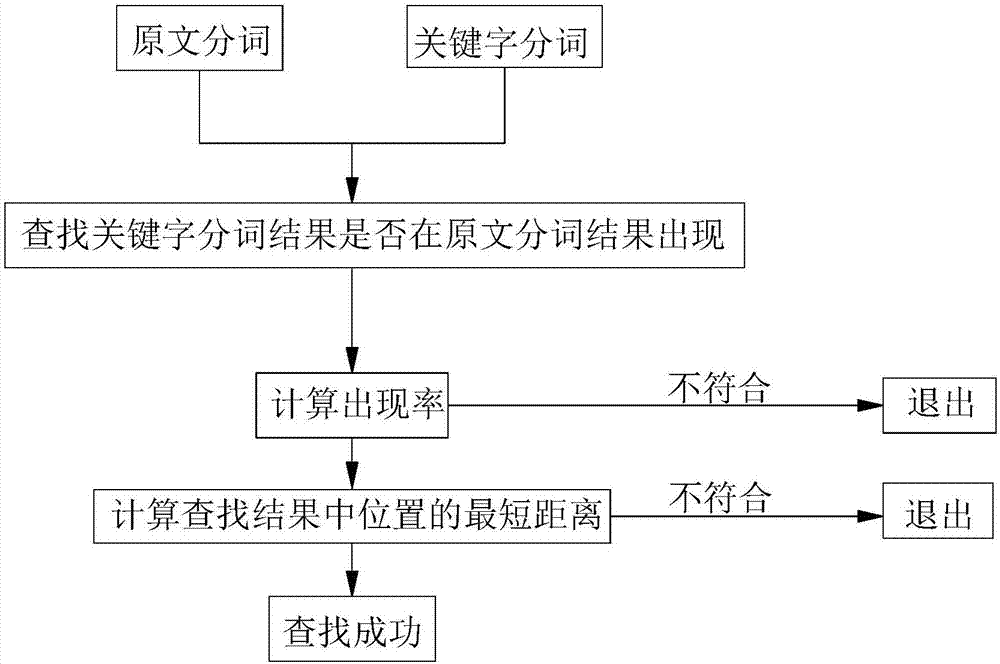
进一步参见图2,可以更方便的理解本发明方法的思想。首先是原文分词、关键字分词,然后查找关键字分词结构是否在原文分词结果中出现,即通过计算出现率来与预设的数值比较,决定是否进入下一步搜索,进入下一步后通过比较不同关键字分词在原文中出现的位置之间的距离d与相应关键词自身长度之间的差值k是否在容许的数值范围内,来决定是否显示查找的结果。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!