一种岩石圈密度的快速提取方法与流程
本发明涉及地球物理数据应用、并行计算技术领域,尤其涉及一种并行岩石圈密度的快速提取方法。
背景技术:
全球地壳模型crust是目前地球物理学界广泛应用的地球模型。目前公布了1°×1°分辨率的crust1.0模型。其主要使用高精度的数据内插方法由2°×2°的crust2.0模型内插得到。因此,目前使用最广泛的版本是crust2.0模型(bassinet.al,2000)。crust2.0(http://igppweb.ucsd.edu/~gabi/crust2.html)模型是在crust5.1模型的基础上加入了更多的观测资料并使用改进的数据处理方法得到(mooneyet.al,1998)。
crust2.0模型的空间分辨率为2°×2°;且融合了最近发布的全球1°×1°分辨率的沉积物厚度、冰盖厚度数据。该模型编绘的数据覆盖了大部分的欧亚大陆、北美地区、澳大利亚、非洲和南美的以及部分海洋区域。模型的海底地形和陆地地形数据来源于etopo5.模型。crust2.0模型在每个格网点上是1维(1d)的7层模型,依次为冰盖、海深、软沉积物、硬沉积物、上层地壳、中层地壳、下层地壳。模型的每一层都给出了p波速度(vp)、s波速度(vs)和密度(rho)参数,并给出了莫霍面以下的上地幔密度信息,能够很好得反映岩石圈的密度特征。crust2.0模型与以往发布的模型不同之处在于:沉积物结构的厚度、密度、地震波数据更加丰富,覆盖更加完善;沉积物速度结构的估计基于了大量的地壳结构数据;且采用最新的野外和实验数据对横波、纵波以及密度结构进行了约束;在数据处理过程中,采用数学随机统计方法对没有进行野外测量的区域进行了估计。
crust2.0模型可应用于地球物理等相关学科,需要岩石圈密度、或某一区域岩石圈块体质量等信息。在具体数据处理时涉及多计算点、多深度层的密度信息提取和区块质量的高精度积分计算。全球岩石圈密度数据的提取速度和区块质量的计算速度是相关地球物理应用的瓶颈之一。随着计算机硬件技术的发展,无论是超级计算机(supercomputer),还是较小的计算机集群(cluster),或是基于多cpu和多核的计算工作站,用户都可以容易的获取基于多核,多处理器计算平台支持;另外,基于多cpu和多核的mpi(messagepassinginterface)标准和软件平台也日益成熟并广泛使用于数值运算领域。这为采用提高全球岩石圈密度模型数据的提取和区块质量的计算速度提供了很好的硬件和系统软件平台的支持。但是,实现全球岩石圈密度模型数据快速提取的方案尚未出现,目前的密度提取,包括区块质量计算仍然基于逐一站点的顺序提取和计算,十分耗时;制约了crust模型在地球物理学等相关领域的高精度深层次应用。
文献1:bassin,c.,laske,g.andmasters,g.,thecurrentlimitsofresolutionforsurfacewavetomographyinnorthamerica,eostransagu,81,f897,2000.
文献2:mooneyet.al.adescriptionofcrust5.1canbefoundin:mooney,laskeandmasters,crust5.1:aglobalcrustalmodelat5x5degrees,jgr,103,727-747,1998.
技术实现要素:
本发明的目的是提供一种适用于岩石圈密度提取和区块质量计算的快速数据处理方法,该方法基于并行处理技术和区块六边形划分方法实现密度的快速提取和高精度区块质量快速计算方法。以解决相关应用数值处理时,大量站点多深度层密度信息提取和区块高精度质量计算速度较慢的问题。
本发明提供一种岩石圈密度的快速提取方法,包括对每个站点的区块,采用正六边形划分进行填充,每一个六边形单元均对应一个深度为h的六棱台,h为计算深度;根据深度分层值h和计算深度h计算深度层数m=h/h;深度为h的六棱台分为m个高度为h的六棱台;
进行所有站点的各层密度值快速提取时,计算资源分配方式为,根据计算核心数nk和待计算点数n1,将计算任务分配给每个计算核心;其中n1根据站点总数n和计算深度层数m按公式n1=n×m计算;对于第k个计算核心,分配n1/nk个计算点,k取1~nk,余下的mod(n1,nk)个计算点从第1个计算核心开始依次分配;
当需要计算某个站点的区块质量时,根据区块中心的位置,按照填充的正六边形单元边长和区块半径推算各正六边形的中心位置,相应得到每深度层所有六棱台中心位置;根据深度范围和深度分层值h计算每深度层中六棱台的体积;对每一深度层,提取该层所有六棱台中心位置处的密度值,并累加,最后乘以该层单个六棱台的体积得到该层的质量;所有深度层的质量累加得到该区块深度范围的区块质量;
所述对每一深度层,提取该层所有六棱台中心位置处的密度值,计算资源分配方式为,根据计算核心数nk和当前区块的待计算点数n2,将计算任务分配给每个计算核心;其中n2根据正六边形总数p和计算深度层数m按公式n2=p×m计算;对于第k个计算核心,分配n2/nk个计算点,k取1~nk,余下的mod(n2,nk)个计算点从第1个计算核心开始依次分配。
而且,对所有站点逐个计算站点的区块质量。
而且,进行所有站点的各层密度值快速提取时,任一个站点每层的密度值均由crust模型内插得到。
而且,所述对每一深度层,提取该层所有六棱台中心位置处的密度值,均由crust模型内插得到。
而且,通过调整六边形半径r控制计算时间和计算精度。
本发明具有以下优点和积极效果:
1、采用正六棱台作为区块质量计算的质量元,相对于传统圆台作为质量元进行质量计算的精度有显著提高;且可以容易地通过调整六边形半径r来平衡计算时间和计算精度的矛盾;
2、针对待计算密度点之间的无关性,采用细粒度并行方式进行密度信息提取,具有效率高、能充分发挥计算硬件能力的特点;
3、快速算法的实现原理简单、执行效率高(并行颗粒度较细),适用于多核心和多处理器计算机系统、可有效提高地球物理相关应用提取全球岩石圈密度信息和区块质量计算的效率;
4、构建成本低,适用于目前主流的操作系统,且可实现自动化批处理。
附图说明
图1是本发明实施例提出的并行岩石圈密度提取方法的流程图。
图2是本发明实施例中区块划分和质量计算原理图。
图3是本发明实施例中正六边形区块划分和经典圆形区块划分的对比图。
图4是本发明实施例中经典方法与本发明提出的方法完成1000-10000个站点的运行计算时间对比图。
具体实施方式
本发明考虑到相关地球物理应用在提取岩石圈密度和区块质量计算时,不同站点密度信息以及不同区块的质量之间是无关的,在提取和计算上也没有逻辑上的先有依赖关系。因此每一计算点的密度信息提取和每一区块质量的计算是独立的。基于上述基础,可以实现高效的细颗粒度并行计算。
本发明中,将站点文件给出的每一有明确经度纬度位置的点称为站点,其分布可能是规则格网或者散布的离散点;对于每一个需要提取密度进而累加计算体积的点称为计算点。区块指以站点为中心半径为a的需要计算质量的区域,本发明首创提出,对于某一站点对应的区块,按正六边形分区和深度分层得到若干计算点。
以下结合附图和实施例详细说明本发明技术方案。本发明所提供技术方案可采用计算机软件技术实现自动运行流程。参见图1,实施例的流程包括以下步骤:
步骤1,设定crust模型数据文件名称,站点文件名称,输出文件名称,是否进行区块质量计算的布尔值,区块计算的半径(a),区块划分正六边形单元的边长(r),区块密度积分计算深度分层值(h)等。并且,读取crust模型数据。
具体实施时,本领域技术人员可预先设置程序运行的方案文件,运行流程时读取预设的方案文件,并通过方案文件中的信息设定运行控制项,即可实现本步骤。
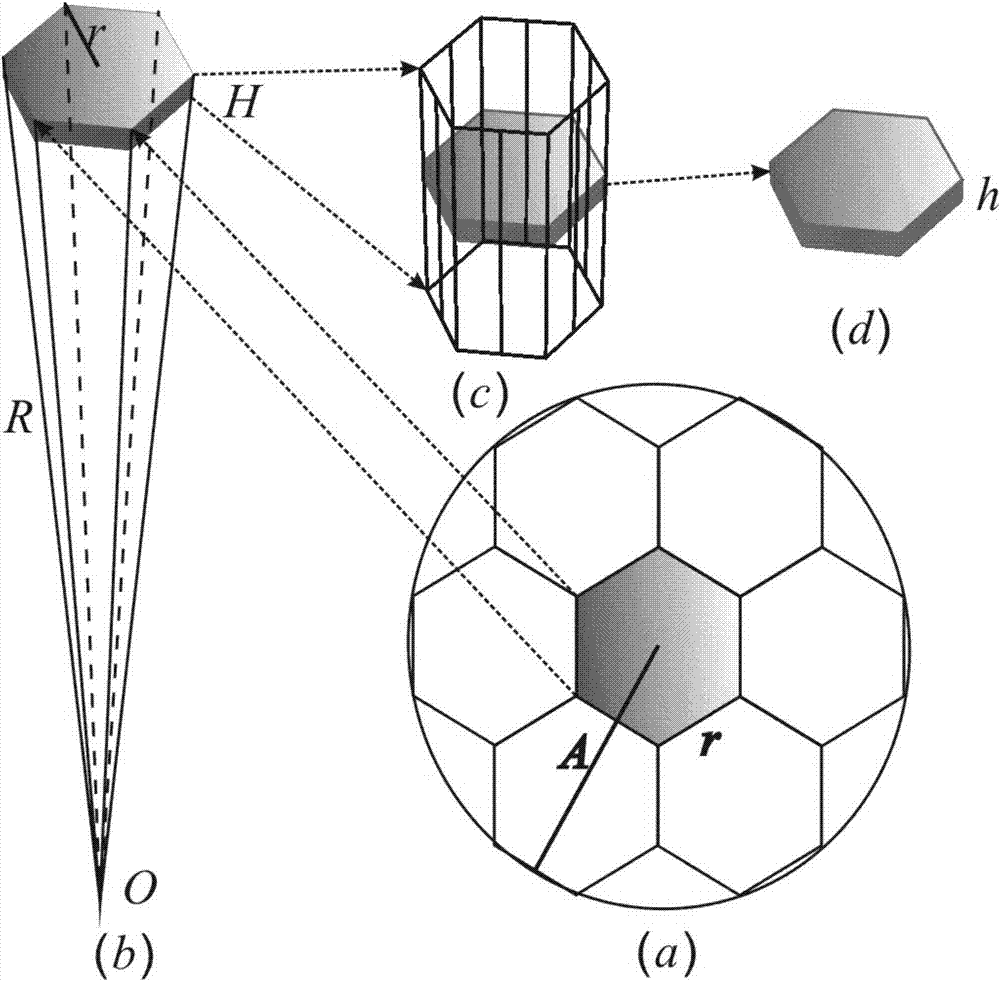
如图2(a)所示,区块半径(a)和正六边形单元的边长(r)的取值满足下列关系。
a=(2q+1)×(sqrt(3)/2×r)其中q为划分正六边形的系数(圆划分的圆形半径),q=0,1,2,3,…,q取值越大计算精度越高,耗时越长,sqrt(.)为求平方根的函数。
另外图3可以看出,如果采用圆形填充,相当于使用六边形的内切圆进行填充,在相同计算量的情况下,现有技术中圆形划分的精度明显低于本发明提出的正六边形划分。在图3中,圆形划分之间会有空隙,因此在计算量相同的情况下,正六边形划分的精度相对于圆形划分的区块质量计算的精度可以提高10%。理论分析如下:
圆单元面积=π×g2
正六边形单元面积=3×r×g
精度提高(正六边形单元面积-圆单元面积)/圆单元面积≈10%
具体实施时,可以方便地通过调整六边形半径r控制计算时间和计算精度,满足实际需求。
步骤2,读取站点文件;站点文件每条纪录存储一个待计算站点的信息,具体包括:站点经度、纬度、地心距(r)、计算深度(h)等信息,并由积分计算深度分层值(h)和h计算深度层数m=h/h;整个文件读取完毕后得到站点总数(n)。
步骤3,站点的各层密度值快速提取;该过程包含以下子步骤:
步骤3.1,计算资源分配i,以待计算点数n1分配计算资源并进行快速密度提取存储:根据可用的计算核心数nk,待计算点数n1,将计算任务分配给每个计算核心;其中n1根据站点总数(n)和计算深度层数(m)按公式n1=n×m计算;对于第k(k取1~nk)个计算核心,分配n1/nk个计算点,余下的mod(n1,nk)个计算点可从第1个计算核心开始依次分配,即第1个到第mod(n1,nk)个计算核心分配一个。按照可用的计算核心数nk进行计算资源分配,nk的能够取的最大值取决于硬件系统平台;目前实际工作中需提取的岩石圈密度信息的站点数不超过168,480,000个(相当于全球1′×1′格网点数),例如站点数取168,480,000个,计算深度取100km,计算深度分层值取10km,则m=10层,此时n1=168,480,000×10=1,684,800,000。
任一个站点每层的密度值均由crust模型内插得到,内插/提取处理分配到各计算核心依次完成。比如对于某一站点,需要该站点的密度,密度分层为10层,则按照crust给出的密度模型按深度线性内插出10个深度层的密度值。
步骤3.2,资源分配完毕后,各计算核心启动并行岩石圈模型密度信息提取,即对任一个站点每层的密度值根据crust模型进行内插计算,形成站点经度、纬度、深度、密度的信息列表并存入设定的输出文件。如图1中,实现对第1个计算点进行crust模型密度提取,…,对第i个计算点进行crust模型密度提取,…,对第n1个计算点进行crust模型密度提取,并对各计算点的提取结果自动按照经度、纬度、深度层为索引进行密度信息存储。
步骤3.3,根据设定的布尔值判断是否进行区块质量计算,若不进行则提取处理结束,否则进入步骤4。
步骤4,对所有站点逐个计算站点的区块质量,可以采用循环执行流程的方式快速计算每个区块的质量,其中区块以站点经度和纬度为中心,a为半径定义;包括依次取各区块,分别执行以下子步骤:
步骤4.1,根据当前区块的区块半径(a)和划分区块的正六边形单元边长(r)得到划分的正六边形总数(p),同时由站点位置(经度和纬度)推算区块内所有正六边形的中心位置(经度和纬度)。
如图2(a)所示,知道了圆形区域中心(站点的区块中心)的位置,可以按照填充的正六边形单元边长(r)和区块半径(a)推算各正六边形的中心位置,根据深度相应即可得到每深度层所有六棱台中心位置。
步骤4.2,根据深度范围(r~r-h)和深度分层值(h)计算每深度层六棱台的体积(v)(同一深度层所有六棱台的体积相等);
如图2(b)所示,o为地球质心,r为站点到地心距离,h为需要计算质量的深度;这样既可确定一个深度为h的六棱台,该六棱台的顶部六边形边长为(r),底部六边形边长小于(r),设为(r’),可由(r),(h)和(r)确定。每一个六边形单元均对应一个六棱台。如图2(c)和(d)所示,深度为(h)的六棱台可分为h/h(即m)个高度为(h)的“薄”六棱台,根据顶部六边形边长(r)和底部六边形边长(r’),得到h/h个六棱台分别的体积,提取密度和计算时认为“薄”六棱台的密度是均匀的。因此若要提高计算精度(h)必须足够小,优选地,在一般区域h可取10km,对于密度变化较大的区域可以取1~5km。
当(r)确定后,每一深度层虽然有多个六棱台,但它们的体积相等,所以后续步骤4.4计算时只需将步骤4.3所得该层所有六棱台中心位置处的crust密度值累加,最后乘以该层单个六棱台的体积即得到该层的质量。
每个六边形中心的密度值代表该六边形的密度。因六边形划分时是以中心开始划分六边形的,该区块(站点)的位置就是划分的中间的六边形的中心,因此该六边形的密度可以就取这个站点的密度值。该站点的其它六边形密度则需按照对应的位置(六边形的中心)读取crust模型,按位置和深度重新由crust模型数据内插得到。每一层六棱台的体积相等,因此该层的质量=(六边形1密度+六边形2密度+...)×体积。
步骤4.3,计算资源分配ii,以当前区块(站点)的待计算点数n2分配计算资源并进行快速密度提取存储,提取区块同深度层的各六棱台中心位置处密度:对当前的区块,根据该区块划分的正六边形总数(p)和计算深度层数(m)得到计算点总数(n2=p×m)以及可获得计算核心的数量(nk)进行计算资源分配;方法同步骤3.1,只是将站点总数(n)替换为区块的正六边形总数(p);即根据可用的计算核心数nk,计算点数n2(替换步骤3.1中的n1),将计算任务分配给每个计算核心;其中n2根据正六边形总数(p)和计算深度层数(m)按公式n2=p×m计算;对于第k(k取1~nk)个计算核心,分配n2/nk个计算点,余下的mod(n2,nk)个计算点可从第1个计算核心开始依次分配,即第1个到第mod(n2,nk)个计算核心各分配一个计算点。
执行步骤4.3后,对当前区块完成所有深度层的各六棱台中心位置处密度提取,后续步骤可以直接利用各深度层的提取结果。
步骤4.4,在步骤4.3针对当前区块完成密度提取后,根据所得区块同深度层的各六棱台中心位置处密度,对同深度层的密度值进行累加,然后乘以该层六棱台的体积得到该层的质量;所有深度层的质量累加得到该区块深度范围(r~r-h)的区块质量,形成区块中心经度和纬度、深度范围、区块质量的信息列表,并存入设定的输出文件。参见图1,分别对区块第1个计算点进行crust模型密度提取,…,对区块第i个计算点进行crust模型密度提取,…,对区块第n2个计算点进行crust模型密度提取,提取完成后进行区块所有六棱台体积和质量计算。具体实施时,可采用索引方式,自动按照经度、维度为索引对区块质量信息进行存储。
对当前区块执行完以上子步骤后,取下一区块继续同样处理。在所有区块的密度提取完成后,结束循环。
本实施例的实施环境如下:
超级计算机、普通计算集群或个人计算工作站等多核或多处理器计算机硬件平台。操作系统选用centoslinux,并行软件平台选用mpich-2;准备好指定格式的方案文件,作为控制程序运行主参数的设定。
图4给出了提取1000-10000个站点单密度层采用单cpu进程(single)和本快速方法(parallel)提取岩石圈密度的计算耗时比较图例(legend),横轴为站点数pointnumber,纵轴为时间time/s。可以看出,对于单cpu计算而言,随着站点数的增加,计算耗时呈线性增加,而采用本发明的快速提取方法计算耗时明显少于单cpu进程的耗时。测试的系统有8个计算核心,本发明的方法提取密度信息的耗时约为单cpu进程方法的1/7-1/8。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,例如各阈值(如六边形边长值等)可由本领域技术人员自行根据具体情况设定,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!