一种基于三维空间表层的背景建模方法与流程
本发明属于视频图像处理技术领域,尤其涉及一种基于三维空间表层的背景建模方法。
背景技术:
从一段视频序列中检测运动目标是视频监控的首要而基本的任务之一,也是计算机视觉领域的一个重要研究内容。它通过图像处理的方法对图像序列中的运动目标信息进行解析,具有一定的智能性。运动目标检测的最好结果是每一个运动目标能够被完整单独的检测出来,有效的检测结果对后期视频处理中运动目标的分类、跟踪、识别是非常重要的。背景建模对于固定背景下的运动目标检测通常是不可缺少的步骤,首先需要“学习”背景模型,然后将背景模型和当前图像进行比较,从而得到监控场景中前景运动目标。背景建模方法通过构建不同的背景模型,且随着背景模型更新不断适应场景中的变化,最终能够实现场景中运动目标的实时检测,因此基于背景建模的目标检测算法成为该领域的重要研究方向之一。经典的背景建模方法如混合高斯模型是一种直观的概率密度模型,能够适应光照变化以及多模态场景,但这种方法在场景中运动目标体积大且运动缓慢的时候,检测效果会显著下降;近年来应用较多的vibe背景建模算法可以处理背景突然变化的情况,但是由于采用了运动物体的像素初始化样本集,很容易引入拖影(ghost)区域。背景建模会遇到很多困难,常见的有光照变化如室外阳光被云层遮挡、动态背景如晃动的树叶、密集人流、处理速度等。以上经典的背景建模算法一般都是二维空间下的背景建模,对于拥挤场景下运动目标前后遮挡的问题难以解决,在前景检测时很可能将不同的运动目标检测成为一个目标,使得运动目标的检测效果并不理想。
综上所述,现有技术存在的问题是:对于环境光照、动态背景的变化,前景检测时容易出现虚景;前景与背景图像像素值很相近时,导致前景与背景不能够分清;拥挤场景下运动目标存在前后遮挡时,导致前景检测时前后目标连在一块。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于三维空间表层的背景建模方法。
本发明是这样实现的,一种基于三维空间表层的背景建模方法,所述基于三维空间表层的背景建模方法包括以下步骤:
步骤一,利用双目相机获取场景中的深度图,得到相机视场范围内的三维空间点,通过关注三维空间中最高点组成的表层,构建出场景三维空间表层模型;三维空间表层模型表示为:
zmax(w,h)=g′=max(g|p′(w,h,g));
w∈(0,w-1),h∈(0,h-1),g∈(0,255);
其中三维空间坐标x,y,z的单位是mm,min(z)与max(z)表示范围内所有点的最低点高度值与最高点高度值;m*n为选择的监控范围大小,单位为mm,w*h*255为量化的三维空间的大小,(w,h,g)为像素点三维空间坐标(x,y,z)在量化的三维空间内的坐标值,g’则表示在量化的三维空间内(w,h)处最高点的高度,zmax(w,h)即为三维空间的表层模型。
步骤二,然后对其进行背景模型的初始化,背景模型的更新,以及对每一帧图像进行前景运动目标的提取;图像像素点(u,v)对应的三维空间表层模型处的zmax(w,h),则:
其中sr(zmax(w,h))表示以像素点(w,h)为中心r为半径的区域,r取20,min为设定的阈值,取2,m(w,h)={v1,v2,…,vn}为(w,h)处的背景样本集(样本集大小为n),n一般取20,v1,v2,…,vn表示(w,h)处随机选择n个邻居点的灰度值。bk(u,v)等于1时,表示(u,v)像素点为背景点,为0时表示(u,v)像素点为前景点。
进一步,所述步骤一中:利用双目相机中获取到的左右原图计算出视差图:首先对双目立体相机进行内参标定,然后对原图矫正得到透视变换矩阵q,选择bm算法进行立体匹配计算视差值。
进一步,所述步骤一中:将图像上所有像素点坐标(u,v)映射到三维空间(x,y,z)中:利用相机视差值与透视矩阵q将图像像素点坐标(u,v)转化到相机坐标系下坐标(x,y,z),然后寻找合适的绕三个坐标轴的旋转角度α,β,θ,通过旋转相机坐标系将这些点坐标转化到大地坐标系下坐标(x,y,z),使得运动目标在三维空间中到地面的投影尽可能小的聚在一起:
disparity(u,v)为(u,v)像素点处的视差值,θ为绕z轴旋转的角度,β为绕x轴旋转的角度,α为绕y轴旋转的角度,d为一个常数值。
进一步,所述步骤一中三维空间表层模型的构建方法包括:根据相机监控范围选择将一定大小m*n的三维空间量化到大小为w*h*255的三维空间内;将三维空间中范围内所有有效点p(x,y,z)的x归一化为0~w-1之间的整数w,y归一化为0~h-1之间的整数h,将高度z归一化为0~255之间的整数g,即一个三维点p(x,y,z)对应一个三维点p’(w,h,g),得到一张w*h的灰度图zmax,其像素点p’(w,h)处的灰度值为所有归一化到(w,h)处最高点的归一化高度g′,即构建出三维空间表层模型。
进一步,所述步骤二中对三维空间表层模型进行背景模型的初始化包括:对于zmax图像上每一个像素点,随机的选择它的邻居点的像素值作为模型样本值:
m0(w,h)={v0(y|y∈ng(w,h))}
其中m0(w,h)表示t=0的初始时刻(w,h)处的背景样本集,ng(w,h)为(w,h)处的邻居点。v0(y)表示t=0的初始时刻y像素点处的灰度值。
进一步,所述步骤二中对视频新的一帧图像进行背景模型的更新包括:图像像素点(u,v)对应的三维空间表层模型处的zmax(w,h),n值可以自己设定改变更新速率,则:
本发明的另一目的在于提供一种应用所述基于三维空间表层的背景建模方法的计算机。
本发明的另一目的在于提供一种应用所述基于三维空间表层的背景建模方法的服务器。
本发明的另一目的在于提供一种应用所述基于三维空间表层的背景建模方法的视频监控系统。
本发明的优点及积极效果为:通过双目立体相机获得场景三维空间信息,然后进行背景建模,实现拥挤场景实时监控下运动目标检测。本发明既克服了拥挤环境中目标检测的部分遮挡问题,也在一定程度上减少了检测结果中鬼影的出现。同时,通过对三维空间的表层进行背景建模,相比于直接进行三维空间背景建模,此算法计算复杂度大大减少,在测试本发明的实验中,硬件装备为具有inteli7-6700cpu和8gbram的笔记本电脑,在此硬件上无gpu加速时本算法可以实现一秒20帧的计算速度,能够满足实时监控系统中运动目标检测需求。
本发明对三维空间的表层进行的背景建模,计算复杂度大大减少,能够使用在实时监控系统中。经典的背景建模方法由于只使用图像信息在二维空间进行建模,在拥挤场景中,前后两个运动目标由于遮挡在平面图像上会有重叠的部分,这样的两个目标一般很难被分割开来。而本发明利用双目立体相机获取到了场景中三维空间点云信息,实现了在三维空间中的简化背景建模,由于前后两个发生遮挡的运动目标在三维空间中相隔距离不会很小,因此可以较为容易的将两个目标分割开,这给后期前景运动目标的进一步研究带来了很大的便利,比如场景中运动目标的跟踪、识别等研究。只有把运动目标准确的检测并分割出来,才可以准确的获得每一个运动目标的位置信息与图像信息,这些信息对跟踪与识别研究有很大的帮助。
本发明实现了复杂背景下的背景建模,具有良好的鲁棒性,突破了单相机背景建模中的常见的遮挡和鬼影问题,在稠密场景中对运动目标进行有效分割。在测试本发明的实验中,还将本发明与目前比较受欢迎的vibe算法进行了比较,总共选择了4个存在遮挡的场景,每个场景230帧图像,有597个前景运动目标,通过两种算法的前景检测结果发现,本发明准确率为96.39%,查全率是89.45%,vibe准确率为22.2%,查全率是80.40%,因此无论从准确率还是查全率上本发明都更加有效鲁棒。
附图说明
图1是本发明实施例提供的基于三维空间表层的背景建模方法流程图。
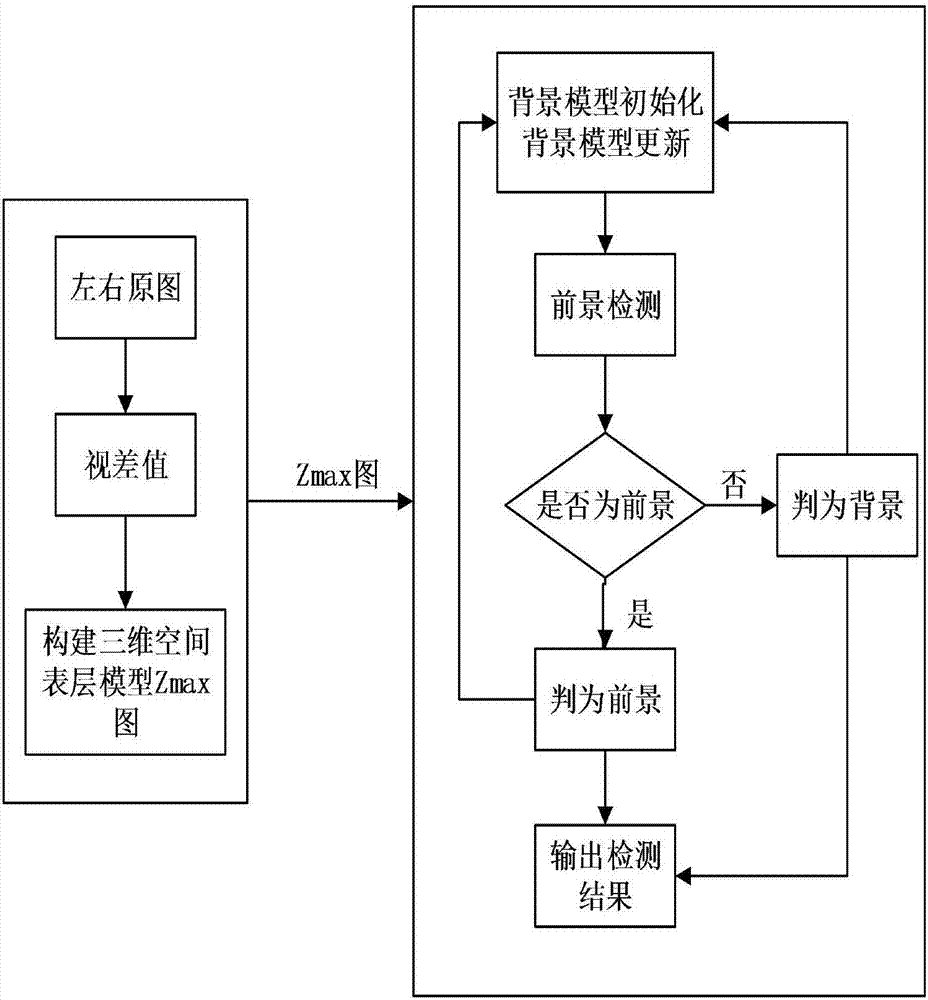
图2是本发明实施例提供的基于三维空间表层的背景建模方法实现流程图。
图3是本发明实施例提供的三维空间表层模型示意图及前景目标检测结果图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的基于三维空间表层的背景建模方法包括以下步骤:
s101:利用双目相机获取场景中的深度图,得到相机视场范围内的三维空间点,通过关注三维空间中最高点组成的表层,进而构建出场景三维空间表层模型;
s102:然后对其进行背景模型的初始化,背景模型的更新,以及对每一帧图像进行前景运动目标的提取。
下面结合附图对本发明的应用原理作进一步的描述。
如图2所示,本发明实施例提供的基于三维空间表层的背景建模方法具体包括如下步骤:
步骤1,利用双目相机中获取到的左右原图计算出视差图:首先对双目立体相机进行内参标定,然后对原图矫正得到透视变换矩阵q,进而选择bm算法进行立体匹配计算视差值。
步骤2,将图像上所有像素点坐标(u,v)映射到三维空间(x,y,z)中:利用相机视差值与透视矩阵q将图像像素点坐标(u,v)转化到相机坐标系下坐标(x,y,z),然后寻找合适的绕三个坐标轴的旋转角度α,β,θ,通过旋转相机坐标系将这些点坐标转化到大地坐标系下坐标(x,y,z),使得运动目标在三维空间中到地面的投影尽可能小的聚在一起:
disparity(u,v)为(u,v)像素点处的视差值,θ为绕z轴旋转的角度,β为绕x轴旋转的角度,α为绕y轴旋转的角度,d为一个常数值。
步骤3,构建三维空间表层模型:根据相机监控范围选择将一定大小m*n(单位:mm)的三维空间量化到大小为w*h*255的三维空间内,w与h的值越大,计算量就越大,计算速度就会越慢,而m/w,n/h的值一般不超过30,值越小表示投影精度越大。这样的量化过程是将三维空间中范围内所有有效点p(x,y,z)的x归一化为0~w-1之间的整数w,y归一化为0~h-1之间的整数h,将高度z归一化为0~255之间的整数g,即一个三维点p(x,y,z)对应一个三维点p’(w,h,g)。由此可以得到一张w*h的灰度图zmax,其像素点p’(w,h)处的灰度值为所有归一化到(w,h)处最高点的归一化高度g′,即构建出了三维空间表层模型:
zmax(w,h)=g′=max(g|p′(w,h,g)),;
w∈(0,w-1),h∈(0,h-1),g∈(0,255);
其中三维空间坐标x,y,z的单位是mm,min(z)与max(z)表示范围内所有点的最低点高度值与最高点高度值。m*n为选择的监控范围大小,单位为mm,w*h*255为量化的三维空间的大小,(w,h,g)为像素点三维空间坐标(x,y,z)在量化的三维空间内的坐标值,g’则表示在量化的三维空间内(w,h)处最高点的高度,zmax(w,h)即为三维空间的表层模型。
步骤4,对三维空间表层模型进行背景模型的初始化:由于现在已经将模型简化为一张灰度图,所以初始化的方法可以选择很多种,这里选取vibe的单帧初始化方法。背景模型为每个背景点存储了一个样本集,对于zmax图像上每一个像素点(w,h),随机的选择它的邻居点的像素值作为它的模型样本值:
m0(w,h)={v0(y|y∈ng(w,h))}
其中m0(w,h)表示t=0的初始时刻(w,h)处的背景样本集,ng(w,h)为(w,h)处的邻居点。v0(y)表示t=0的初始时刻y像素点处的灰度值。
步骤5,对视频新的一帧图像进行运动前景提取:前景分割时选择与vibe一样的方法,所以这种三维空间表层背景建模方法的前景分割策略为vibe的前景分割策略加上在三维空间中一种特殊的分割策略:设图像像素点(u,v)对应的三维空间表层模型处的zmax(w,h),则:
其中sr(zmax(w,h))表示以像素点(w,h)为中心r为半径的区域,r一般取20,min为设定的阈值,一般取2,m(w,h)={v1,v2,…,vn}为(w,h)处的背景样本集(样本集大小为n),n一般取20,v1,v2,…,vn表示(w,h)处随机选择n个邻居点的灰度值。bk(u,v)等于1时,表示(u,v)像素点为背景点,为0时表示(u,v)像素点为前景点。
步骤6,对视频新的一帧图像进行背景模型的更新:背景模型更新方法选择vibe的背景更新方法再加上在三维空间由于阴影存在提出的特殊的更新策略。设图像像素点(u,v)对应的三维空间表层模型处的zmax(w,h),n值可以自己设定改变更新速率,则:
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!