多变量时间序列预测方法和系统与流程
本公开涉及一种多变量时间序列预测方法和一种多变量时间序列预测系统。
背景技术:
时间序列模型可以拟合并学习数据随时间变化的规律,例如周期性规律、趋势性规律或者随机性变化等,时间序列模型能够很好地考虑季节性因素、内部因素和外部因素对数据变化的影响。然而,随着工业、销售服务以及物流等各行各业的快速发展,越来越多的数据不断累积,并且随着科技的进步,获取数据的能力也在不断增强,面对对大数据的分析预测,需要可以适应大数据预测的时间序列预测方法。
技术实现要素:
本公开的一个方面提供了一种多变量时间序列预测方法,用于预测产品数量统计信息,该方法包括:采集至少一组与目标数据相关联的数据,其中,目标数据包括数量统计信息。对至少一组采集的数据进行处理,得到至少一组特征数据。使用多个模型对特征数据进行训练,其中,多个模型采用各自不同的方式对特征数据进行训练以得到针对目标数据的预测结果。以及将训练好的多个模型得到的预测结果进行组合,得到目标数据的预测结果。
可选地,与目标数据相关联的数据包括:外部数据,该外部数据表示影响多变量时间序列预测的系统外部数据信息,和/或内部数据,该内部数据表示影响多变量时间序列预测的系统内部数据信息。
可选地,使用多个模型对特征数据进行训练是并行进行的。
可选地,将训练好的多个模型得到的预测结果进行组合,包括:平均组合,对各模型的预测结果取平均值,作为目标数据的预测结果,或者加权组合,对各模型的预测结果取加权平均值,作为目标数据的预测结果。
可选地,对至少一组采集数据进行处理,得到至少一组特征数据,包括,将至少一组采集的数据逐一与目标数据进行相关性和/或相似度计算,选择相关性超过阈值或者相似度超过阈值的数据作为特征数据。
可选地,对至少一组采集数据进行处理,得到特征数据,还包括:对特征数据的所有非空子集进行模型预训练,得到训练结果,以及选择训练结果最优的模型对应的子集中的特征数据作为最优特征数据。相应地,使用多个模型对特征数据进行训练包括,使用多个模型对最优特征数据进行训练。
可选地,对至少一组采集数据进行处理,得到特征数据,还包括:对特征数据进行不同降维比例的降维处理,得到多个降维特征数据,对多个降维特征数据进行模型预训练,得到训练结果,以及选择训练结果最优的模型对应的降维特征数据作为最优降维特征数据。相应地,使用多个模型对特征数据进行训练包括,使用多个模型对最优降维特征数据进行训练。
可选地,对至少一组采集数据进行处理,得到特征数据,还包括:为特征数据中的每一组特征数据配置至少一个前置参数,在各组特征数据的不同前置参数组合下,对特征数据进行模型预训练,以及选择训练结果最优的模型对应的前置参数组合作为各组特征数据对应的最优前置参数。相应地,使用多个模型对特征数据进行训练包括,使用多个模型根据最优前置参数对特征数据进行训练。
本公开的另一个方面提供了一种多变量时间序列预测系统,包括一个或多个存储器,存储有可执行指令,以及一个或多个处理器,运行可执行指令以执行如上所述的方法。
本公开的另一方面提供了一种非易失性存储介质,存储有计算机可执行指令,所述指令在被执行时用于实现如上所述的方法。
本公开的另一方面提供了一种计算机程序,所述计算机程序包括计算机可执行指令,所述指令在被执行时用于实现如上所述的方法。
附图说明
为了更完整地理解本公开及其优势,现在将参考结合附图的以下描述,其中:
图1示意性示出了根据本公开实施例的多变量时间序列预测方法的流程图;
图2示意性示出了根据本公开实施例的数据处理方法的流程图;
图3a-图3b示意性示出了根据本公开实施例的相关性计算的示意图;以及
图4示意性示出了根据本公开实施例的多变量时间序列预测系统的框图。
具体实施方式
以下,将参照附图来描述本公开的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本公开的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本公开的概念。
在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本公开。这里使用的词语“一”、“一个(种)”和“该”等也应包括“多个”、“多种”的意思,除非上下文另外明确指出。此外,在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
附图中示出了一些方框图和/或流程图。应理解,方框图和/或流程图中的一些方框或其组合可以由计算机程序指令来实现。这些计算机程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,从而这些指令在由该处理器执行时可以创建用于实现这些方框图和/或流程图中所说明的功能/操作的装置。
因此,本公开的技术可以硬件和/或软件(包括固件、微代码等)的形式来实现。另外,本公开的技术可以采取存储有指令的计算机可读介质上的计算机程序产品的形式,该计算机程序产品可供指令执行系统使用或者结合指令执行系统使用。在本公开的上下文中,计算机可读介质可以是能够包含、存储、传送、传播或传输指令的任意介质。例如,计算机可读介质可以包括但不限于电、磁、光、电磁、红外或半导体系统、装置、器件或传播介质。计算机可读介质的具体示例包括:磁存储装置,如磁带或硬盘(hdd);光存储装置,如光盘(cd-rom);存储器,如随机存取存储器(ram)或闪存;和/或有线/无线通信链路。
本公开的实施例提供了一种多变量时间序列预测方法,用于预测产品数量统计信息(例如,预测某产品的下个月销量、或者预测某产品下几个月的库存数量等等),该方法包括:采集至少一组与目标数据相关联的数据,其中,目标数据包括数量统计信息。对至少一组采集的数据进行处理,得到至少一组特征数据。使用多个模型对特征数据进行训练,其中,多个模型采用各自不同的方式对特征数据进行训练以得到针对目标数据的预测结果。以及将训练好的多个模型得到的预测结果进行组合,得到目标数据的预测结果。
图1示意性示出了根据本公开的实施例的多变量时间序列预测方法的流程图。
如图1所示,该方法包括在操作s110,采集至少一组与目标数据相关联的数据。其中,目标数据包括数量统计信息,例如,目标数据可以是某款手机的销售量,则该多变量时间序列预测方法用于预测该款手机下个时间点(例如,下周、下个月、下个季度或者下半年等)或者下几个时间点(例如,下两周、下三个月等等)的销售量。
根据本公开实施例,采集至少一组与目标相关联的数据可以在不同时机采集。
例如,采集与目标数据相关联的数据可以是实时采集,这样,采集得到的数据具有良好的时效性,可以为多变量时间序列预测系统提供最新的相关数据,以提高预测精度。
或者例如,采集与目标数据相关联的数据可以是按照预设周期采集。例如,每隔1个小时采集一次或者每隔1天采集一次,预设周期可以根据目标数据的性质设定(例如,若目标数据的时间单位为天,则可以设置2个小时为采集周期,若目标数据的时间单位为季度,则可以设置1个月为采集周期。这样,目的性较强,效率也比较高。
又例如,采集与目标数据相关联的数据可以是发生特定条件时采集,例如,政府出台相关政策,或者本公司的制度调整,又或者相关产品的发布等影响目标数据走向的事件,当特定的条件发生时,及时采集相关数据。这样,可以及时获取与目标数据相关的数据,可以减少采集次数,又不会错过重要数据。
当然,采集与目标数据相关联的数据还可以在其他可能时机采集,例如随机采集等,本公开各实施例不做限制。
根据本公开实施例,与目标数据相关联的数据包括:外部数据和/或内部数据。
其中,外部数据表示影响多变量时间预测的系统外部数据信息。例如,目标数据为a公司的手机销量,则与目标数据相关的外部数据可以是b公司的手机销量、宏观经济信息、微观经济信息等等。采集外部数据可以通过爬虫、官方网站下载等方式从网络渠道抓取。
根据本公开实施例,引入外部数据可以增强预测能力,通过将与目标数据相关联的外部数据引入多变量时间序列预测模型,外部数据可以与内部数据相互影响,多因素相互作用,更加接近真实应用场景,提高预测精度。
内部数据表示影响多变量时间序列预测的系统内部数据信息。例如,目标数据为a公司的手机销量,则与目标数据相关的内部数据可以是a公司的该手机库存信息、a公司的该手机的销售价格信息、a公司的另一款手机的销量、或者a公司的政策变化等等。采集内部数据可以通过在企业内部的信息系统中收集。
在操作s120,对至少一组采集的数据进行处理,得到至少一组特征数据。根据本公开实施例,对至少一组采集的数据进行处理得到至少一组特征数据包括将至少一组采集的数据逐一与目标数据进行相关性和/或相似度计算,选择相关性超过阈值或者相似度超过阈值的数据作为特征数据。
根据本公开实施例,对至少一组采集的数据进行处理还可以包括以下一种或者几种的任意组合:
对特征数据的所有非空子集进行模型预训练,得到训练结果,以及选择训练结果最优的模型对应的子集中的特征数据作为最优特征数据;或者
对特征数据进行不同降维比例的降维处理,得到多个降维特征数据,对多个降维特征数据进行模型预训练,得到训练结果,以及选择训练结果最优的模型对应的降维特征数据作为最优降维特征数据;或者
为特征数据中的每一组特征数据配置至少一个前置参数,在各组特征数据的不同前置参数组合下,对特征数据进行模型预训练,以及选择训练结果最优的模型对应的前置参数组合作为各组特征数据对应的最优前置参数。
例如,对采集的数据进行处理可以包括对采集的数据进行相关性和/或相似度的计算,得到特征数据,对该特征数据的所有非空子集进行模型训练,选择训练结果最优的模型对应的非空子集作为最优特征数据集。然后,以最优特征数据集作为后续多模型训练的输入数据。
又例如,对采集的数据进行处理还可以包括对采集的数据进行相关性和/或相似度的计算,得到至少一组特征数据,对至少一组特征数据进行降维计算后进行模型训练,选择训练结果最优的模型对应的降维后的特征数据作为最优降维特征数据。然后,以最优降维特征数据作为后续多模型训练的输入数据。
再例如,对采集的数据进行处理还可以包括对采集的数据进行相关性和/或相似度的计算,得到至少一组特征数据,为每一组特征数据配置至少一个前置参数,在不同前置参数下对至少一组特征数据进行模型训练,选择训练结果最优的模型对应的每组特征数据的前置参数作为该组特征数据的最优前置参数。然后,以最优前置参数作为后续多模型训练的输入参数数据。
本领域技术人员应当理解,对采集的数据进行处理不限于上述举例的几种组合方法,也不限于上述方法的各种可能的组合,还可以包括缺失值处理、数据归一化或者变量组合等数据处理。
根据本公开实施例,通过对采集的数据进行筛选,可以避免大量的噪声数据,提高多变量时间序列预测的准确度。
下面参考图2,结合具体实施例对图1所示的操作s120做进一步说明。
图2示意性示出了根据本公开实施例的其中一种数据处理方法的流程图。
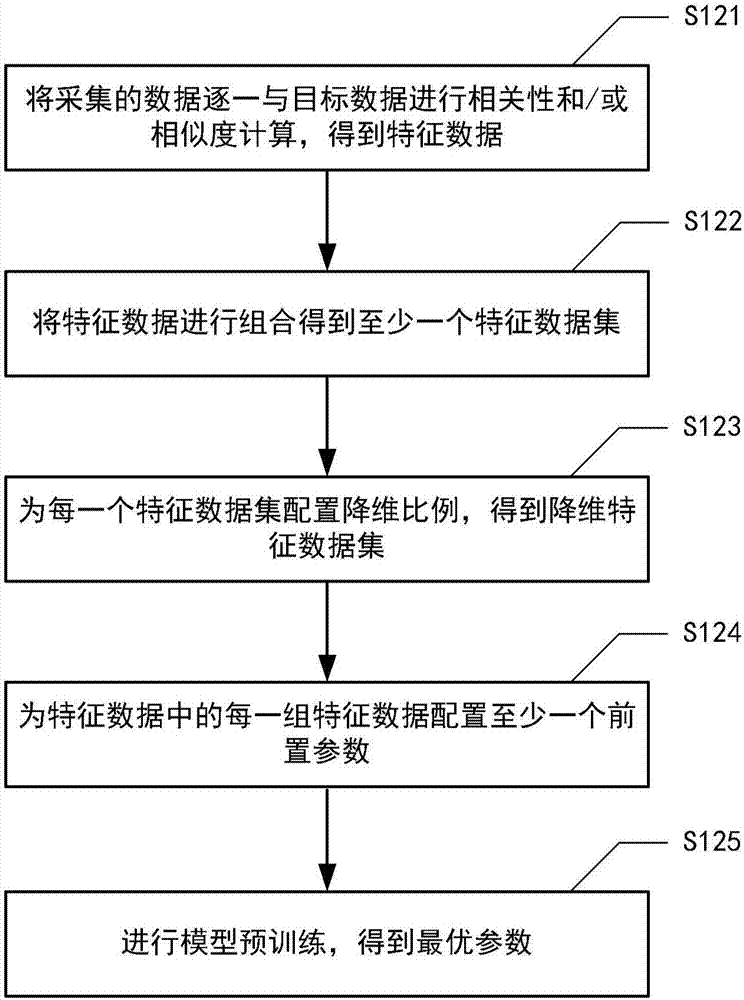
如图2所示,操作s120包括操作s121-s125。本实施例表示操作s120中的一种可能的对采集的数据的处理方法。
在操作s121,将至少一组采集的数据逐一与目标数据进行相关性和/或相似度计算,选择相关性超过阈值或者相似度超过阈值的数据作为特征数据。
根据本公开实施例,将采集到的n组数据逐一与目标数据进行相关性计算。例如可以使用spearman相关系数进行相关性计算。
图3a-图3b示意性示出了根据本公开实施例的相关性计算的示意图。其中,图3a表示采集的数据,图3b表示相关性计算后得到的数据。
如图3a所示,目标数据y表示有2015年1月到2016年12月的原始销量数据,现在要预测目标数据y在2017年1月的销量。x1-x8表示采集的与目标数据y相关的数据。时间区域为五个月。
目标数据y与x1进行相关性计算包括,将近5个月的目标数据y(2016-08~2016-12)与x1(2015-01~2015-05)计算spearman相关系数,再与x1(2015-02~2015-06)计算spearman相关系数,依次类推,最后与x1(2016-07~2016-11)计算spearman相关系数(这里x1预留了一个月,本领域技术人员应当理解,若要预测目标数据y的后两个月的数据则x1应预留两个月)。取相关性系数最高的对应的x1中的5个月的数据作为x1的特征数据。
同理,对所有采集的数据x2-x8以及目标数据y本身的历史数据也做同样的相关性计算(即,特征数据可以包括采集的数据以及目标数据本身的历史数据),最后按照相关性最高的月份对齐,得到如图3b所示的,计算相关性后得到的数据。
根据本公开实施例,采集到的n组数据同样要逐一与目标数据进行相似度计算,例如可以使用余弦相似度进行相似度计算。
例如,继续沿用上述计算相关性的示例,目标数据y与x1进行相似度计算包括,将近5个月的目标数据y(2016-08~2016-12)与x1(2015-01~2015-05)计算余弦相似度,再与x1(2015-02~2015-06)计算余弦相似度,依次类推,最后与x1(2016-07~2016-11)计算余弦相似度(这里x1预留了一个月,本领域技术人员应当理解,若要预测目标数据y的后两个月的数据则x1应预留两个月)。取相似度系数最高的对应的x1中的5个月作为x1的特征数据。
同理,对所有采集的数据x2-x8以及目标数据y本身的历史数据也做同样的相似度计算(即,特征数据可以包括采集的数据以及目标数据本身的历史数据),最后按照相似度系数最高的月份对齐,得到计算相似度后的数据。
根据本公开实施例,选择相关性超过阈值或者相似度超过阈值的数据作为特征数据。即,淘汰既不满足相关性要求又不满足相似度要求的采集的数据,剩余的至少一组采集的数据可以作为特征数据。其中,阈值可以是表征相关性或者相似度的某一预设数值,也可以是按照相关性或者相似度由高到低排列后的数据的百分比。例如,可以是选择相关性超过0.5以及相似度超过0.6的数据作为特征数据。又例如,还可以是选择相关性前50%以及相似度前60%的数据作为特征数据。
根据本公开实施例,通过上述方法,对大量的采集的数据进行筛选,可以减少噪声数据,提高多变量时间序列预测的准确度。
在操作s122,将多组特征数据进行至少一种组合,得到至少一个特征数据集。特征数据集中包含至少一组特征数据。
根据本公开实施例,将相关性最高的kc组特征数据与相似度最高的ks组特征数据进行至少一种组合得到至少一个特征数据集。例如,将相关性最高的1组(kc=1)特征数据与相似度最高的1组(ks=1)数据组成特征数据集a,将相关性最高的2组(kc=2)特征数据与相似度最高的3组(ks=3)数据组成特征数据集b,将相关性最高的2组(kc=2)特征数据与相似度最高的2组(ks=2)数据组成特征数据集c等等。
根据本公开实施例,可以将所有有可能的kc与ks的组合方式都组合成特征数据集,也可以是按照某种规则(例如,kc=ks,kc>ks,或者kc<ks)进行组合,得到多个特征数据集。
在操作s123,为每一个特征数据集配置至少一个降维比例,得到至少一个降维特征数据集。降维特征数据集中包含至少一组特征数据。
根据本公开实施例,对每一个操作s122中得到的特征数据集按照配置的至少一个降维比例分别进行降维压缩。例如,可以使用主成分分析pca降维、也可以使用奇异值分解svd降维,还可以使用laplacianeigenmap降维等降维计算方法。降维比例可以包括1.0、0.9、0.8等比例,根据特征数据集中特征数据的组数而定。例如特征数据集m中包括5组特征数据,则降维比例可以是1.0(即降维后的特征数据集m中还包括5组特征数据),降维比例也可以是0.8(即降维后的特征数据集m中生成新的4组特征数据)。
在操作s124,为每一组特征数据配置至少一个前置参数。根据本公开实施例,为每一组特征数据配置至少一个前置参数,还包括为降维后新生成的每一组特征数据配置至少一个前置参数。
前置参数的取值与时间序列预测选取的时间区域有关,例如,选择5个月作为时间区域,则前置参数可以包括0个月、1个月、2个月、3个月、4个月、5个月。在配置前置参数时,可以将全部可取的前置参数都分别配置给相应的特征数据,这样可以考虑到全部的前置参数,避免错过某一最优前置参数。在配置前置参数时,也可以选取配置,例如,选择100天作为时间区域,则可以选择0天、5天、10天等作为前置参数,在这种选择数量大的情况,可以根据情况或者用户设定进行前置参数的配置。
在操作s125,将至少一个降维特征数据集以及该降维特征数据集中每组特征数据对应的前置参数输入到模型中,进行训练。
根据本公开实施例,将操作s121中得到的至少一组特征数据、s122中得到的至少一个特征数据集、s123中得到的至少一个降维特征数据集、以及s124中得到的至少一个前置参数进行所有可能的多种组合。并对每一种组合进行模型训练,选取模型训练最优结果对应的上述数据作为最优数据,以用于作为后续多模型训练的输入数据。
根据本公开实施例,该模型可以是一次指数平滑模型,也可以是二次指数平滑模型,还可以是自回归滑动平均模型等可以用于时间序列预测的数据模型。
根据本公开实施例,选择模型训练结果最好的对应的数据作为最优特征数据。例如准确率最高的模型对应的最优特征数据集(例如包括:选取相关性最高的5组、选取相似度最高的4组、以及目标数据本身的历史数据一组),最优降维特征数据集(将最优特征数据以降维比例0.8降维后得到的数据集),以及最优前置参数(最优降维特征数据集中的8组特征数据对应的前置期数k1、k2……k8)。则,经过模型训练得到的最优特征数据集、最优降维特征数据集以及最优前置参数,可以作为后续的多模型训练的输入数据。
根据本公开实施例,通过将各种可能形成的组合方式进行模型训练后选择最优的训练结果对应的各组数据,可以自动地在大量数据中选择最优的特征数据,提高多变量时间序列预测的准确度。
在操作s130,使用多个模型对特征数据进行训练,其中,多个模型采用各自不同的方式对特征数据进行训练以得到针对目标数据的预测结果。
根据本公开实施例,使用多个模型对特征数据进行训练是并行进行的。
根据本公开实施例,多个模型分布训练可以包括使用多个模型对特征数据进行训练,还可以包括以下一种或者几种的任一组合:使用多个模型对最优特征数据进行训练,或者使用多个模型对最优降维特征数据进行训练,或者使用多个模型根据最优前置参数对特征数据进行训练。
根据本公开实施例,使用多个模型对特征数据进行训练可以是将操作s125中得到最优降维特征数据集以及最优前置参数一起输入到多个模型中进行训练。
根据本公开实施例,使用多个模型对特征数据进行训练还可以是对操作s125得到的最优降维特征数据集中的多组特征数据进行随机采集,将采集得到的特征数据以及每组特征数据对应的最优前置参数输入到多个模型中进行训练。
随机采集可以是降维特征数据集中的每一组特征数据按照可能被采集的概率进行采集(例如,每一组特征数据被采集的概率为80%),也可以是按照采集的数量随机采集(例如,采集5组特征数据,则在10组特征数据中随机采集5组)。
根据本公开实施例,多个模型可以包括:自回归滑动平均模型、自回归模型、滑动模型、指数平滑模型等等可以用于时间序列预测的数学模型。使用多个模型对同样的输入的特征数据进行并行的模型训练。
根据本公开实施例,通过多模型并行训练,优化了计算效率,并且相同的输入数据同时进行模型训练提高了资源使用率,相较于现有的串行算法,可以提高工作效率。
在操作s140,将训练好的多个模型得到的预测结果进行组合,得到目标数据的预测结果。
根据本公开实施例,将训练好的多个模型得到的预测结果进行组合可以是平均组合,对各模型的预测结果取平均值,作为目标数据的预测结果。
例如,使用了3个模型对目标数据进行预测,得到训练结果y1、y2、以及y3,则目标数据的预测结果为(y1+y2+y3)/3。
根据本公开实施例,将训练好的多个模型得到的预测结果进行组合还可以是加权组合,对各模型的预测结果取加权平均值,作为目标数据的预测结果。
例如,使用了3个模型对目标数据进行预测,得到训练结果y1、y2、以及y3,y1对应的模型的拟合度最好,y2其次,y3最不好,则目标数据的预测结果可以是(0.5y1+0.3y2+0.2y1)。
根据本公开实施例,通过对内部数据以及外部数据同时采集,增强了预测能力,更加逼近真实应用场景。并且对采集的数据进行处理,通过预训练自动选择最优的特征数据,减少人工参与,并且保证了特征数据的选择正确性。最后,通过多个模型并行计算,更加适应大数据的预测分析,并且多模型并行计算可以提高工作效率。
图4示意性示出了根据本公开实施例的多变量时间序列预测系统400的框图。
如图4所示,多变量时间预测系统400包括处理器410、以及计算机可读存储介质420。多变量时间预测系统400可以执行上面参考图1~图3b描述的方法,以多变量时间序列的预测。
具体地,处理器410例如可以包括通用微处理器、指令集处理器和/或相关芯片组和/或专用微处理器(例如,专用集成电路(asic)),等等。处理器410还可以包括用于缓存用途的板载存储器。处理器410可以是用于执行参考图1~图3b描述的根据本公开实施例的方法流程的不同动作的单一处理单元或者是多个处理单元。
计算机可读存储介质420,例如可以是能够包含、存储、传送、传播或传输指令的任意介质。例如,可读存储介质可以包括但不限于电、磁、光、电磁、红外或半导体系统、装置、器件或传播介质。可读存储介质的具体示例包括:磁存储装置,如磁带或硬盘(hdd);光存储装置,如光盘(cd-rom);存储器,如随机存取存储器(ram)或闪存;和/或有线/无线通信链路。
计算机可读存储介质420可以包括计算机程序421,该计算机程序421可以包括代码/计算机可执行指令,其在由处理器410执行时使得处理器510执行例如上面结合图1~图3b所描述的方法流程及其任何变形。
计算机程序421可被配置为具有例如包括计算机程序模块的计算机程序代码。例如,在示例实施例中,计算机程序421中的代码可以包括一个或多个程序模块,例如包括421a、模块421b、……。应当注意,模块的划分方式和个数并不是固定的,本领域技术人员可以根据实际情况使用合适的程序模块或程序模块组合,当这些程序模块组合被处理器410执行时,使得处理器410可以执行例如上面结合图1~图3b所描述的方法流程及其任何变形。
尽管已经参照本公开的特定示例性实施例示出并描述了本公开,但是本领域技术人员应该理解,在不背离所附权利要求及其等同物限定的本公开的精神和范围的情况下,可以对本公开进行形式和细节上的多种改变。因此,本公开的范围不应该限于上述实施例,而是应该不仅由所附权利要求来进行确定,还由所附权利要求的等同物来进行限定。
- 还没有人留言评论。精彩留言会获得点赞!