一种基于社交信息的用户属性预测方法与系统与流程
本发明属于数据挖掘技术领域,特别涉及一种基于社交信息的用户属性预测方法与系统。
背景技术:
随着互联网技术的不断发展,“数据及资源”的大数据时代已经来临。而在近几年,用户信息泄露事件层出不穷,2011年,csdn网站的数据被拖库,紧接着,2012年天涯论坛4000万信息泄露,2013年,社交网站facebook上600万用户的个人信息,如电话、住址、电子邮箱等也被泄露出去,同年,美国著名软件公司adobe的数据也大批泄露,其中包含了用户姓名信用卡以及信用卡的过期时间,2014年,我国铁路订票网站12306也出现用户数据的泄露,同年,携程网也被报出存在漏洞,而就在最近,京东12g用户数据也疑似泄露。
当今,生活在互联网时代,网络成为人们传递消息的高速载体。而很多网站出于安全考虑,设置需要用户登录访问,这样频繁的注册登录势必降低了用户体验。所以许多网站和手机app都支持oauth协议,允许用户通过如腾讯qq、微博等第三方社交网络账号进行登录,使得用户不向第三方暴露自己的登录信息的同时,也能访问站点资源。因此,这样在多个站点的用户访问信息因社交账号的关系而进行关联。
基于上面提到的泄露数据,通过对大量用户数据进行综合分析、建模、预测可形成完整的用户画像。利用这部分数据,对企业也来说,能够指导产品研发以及优化用户体验;对广告商来说,可以实现精准化营销,实现巨额收益。另外,这些信息也可能会被恶意利用,,一些不法分子或诈骗集团,利用得到的用户真实数据,赢取用户信任,从而进行诈骗,造成用户巨大损失。
这里主要通过关联多个泄露站点的数据,分析用户个人属性以及社交关系,预测用户真实属性(因网络的虚拟性,用户更倾向于使用一些虚假信息隐藏自己),揭露用户的隐私泄露现状。综上,融合多站点的多类型数据,挖掘用户真实属性,告知用户画像预测的真实姓名、年龄、班级等隐私信息,便于用户了解自身隐私泄露现状,加强用户的隐私保护意识,具有极为重要的理论和现实意义。
目前已经有一些方法通过分析用户好友信息来推断用户属性,但是这些方法主要是基于用户在社交网站上的好友关系,构建社交关系图,通过基于图的属性传播方法来推测用户属性。为了推测用户的属性,传统方法需要知道用户的所有好友,然后根据好友信息推测用户属性,然而,用户好友关系亲疏有别,提供的信息价值也不尽相同。所以仅凭好友来推断用户属性必然存在瓶颈,要加入新的特征来突破。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于社交信息的用户属性预测方法与系统,本发明考虑用户在不同社交群组中的关系,有区分、加权性地计算用户加入的不同社交群组提供的信息,给可信度更高的社交群组更高的权值,使得最终的预测结果更准确;另外,本发明考虑专业简称来对社交群组进行分类,并对缺失专业简称的专业利用分类模型生成对应的专业简称,完善了先验知识库,使得给社交群组分类结果更精确。
为了实现上述目的,本发明采用的技术方案是:
一种基于社交信息的用户属性预测方法,包括:
数据获取:获取全国各学校名称及专业名称,构建先验知识库;
文本分析:对得到的全国各学校名称及专业名称进行处理,输出高校简称和专业简称,完善先验知识库;
社交群组分析:分析各社交群组,计算其对用户属性预测所能提供的有价值信息;
用户属性预测:利用用户在多个群组的社交关系,考虑每个社交群组提供的信息,加权分析预测出用户的真实属性,所述用户的真实属性主要包括用户教育背景和年龄。
所述数据获取过程中,从网上获取全国所有学校名称,同时得到各高校开设专业名称;
所述文本分析过程中,通过提取专业/学校简称的特征,利用这些特征训练分类器,对已知专业简称/学校的样本进行训练,给出生成的未知专业/学校简称的可信度,进一步完善先验知识库;
所述社交群组分析过程中,首先根据经验值和3σ原则剔除社交群组中的噪音点,如果待预测的用户仍在社交群组中,则剔除该用户信息,然后用社交群组中剩余所有用户的平均值作为该社交群组对该用户的属性估计值;
所述用户属性预测过程中,通过分析用户的社交关系模式,对社交群组名称和简介利用关键字,按优先级进行匹配,识别出用户加入的具体班级类型,刻画出相应的教育背景,并且根据“%班%/%届%”关键字,识别出用户就读该校的年份。
所述文本分析过程中,对专业名称的处理,流程如下:
1)计算专业名称全称的长度为n,计算得到专业名称全称字符串可能的所有子串,即字符串组合问题,从n个字符中,任取m个字符组合成一个新的字符串,m~[min,max],其中,min是要生成的专业简称的最小长度,max为最大长度,1<min<max<n;
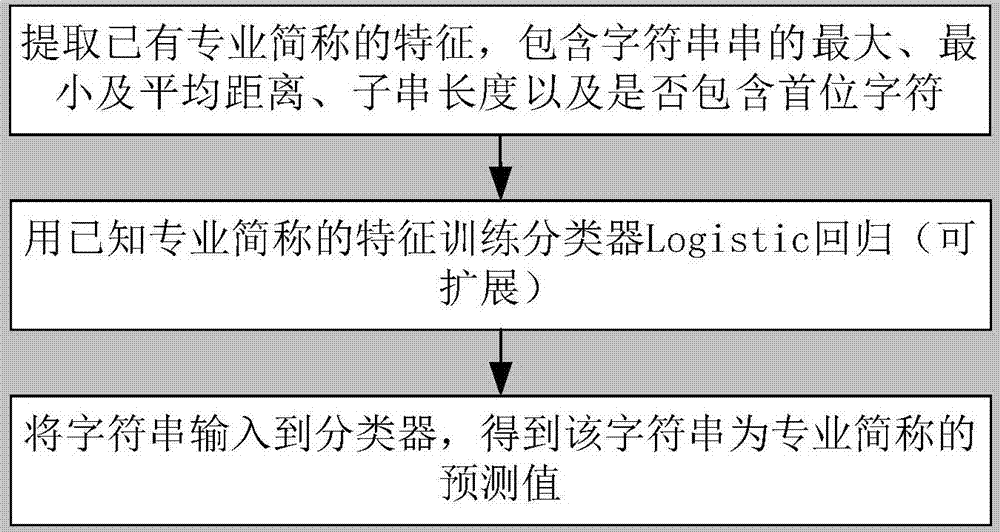
2)提取专业简称的特征,利用这些特征训练分类器,利用已知的部分专业简称作为训练集,预测生成的未知专业简称的可信度;具体包括如下步骤:
2.1)在特征提取部分,考虑生成的子串的最大距离、最小距离、平均距离、子串的长度、以及是否包含首尾字符,其中,距离为任意两个字符的距离,为在专业名称全称中的位置相差的绝对值;
2.2)分类器采用logistic回归(sklearn.linear_model-logisticregression),使用基于python的机器学习库scikit-learn,使用已知的专业简称样本作为训练集,对分类器进行训练,再使用该分类器对其余专业生成的专业简称进行预测,分类器输出值作为生成的该专业简称的可信度。
3)对这多个专业简称进行可信度排名,选择可信度高的前k个作为该专业的简称。
所述社交群组分析过程中:
假设社交群组中用户年龄值为[amin,amax],设定amin=4,amax=100,首先识别出社交群组gj中的异常用户
接着,根据3σ原则剔除噪音点,在正态分布中σ代表标准差,μ代表均值,x=μ即为图像的对称轴,3σ原则为数值分布在(μ-3σ,μ+3σ)中的概率为0.9974,过滤掉不在±3σ范围的噪音点;
对每个社交群组gj,μj和σj为社交群组gj中用户年龄的平均值和方差,计算如下:
社交群组gj中有异常年龄的用户为:
用
当nu,j>0时,让μu,j代表社交群组
估计用户属性的时候,参考其加入的社团群体中其他用户的特征信息,对用户加入的群组,估计其加入的群组j的平均年龄为μu,j,并将该值作为当前社交群组对用户u的年龄估计值,其中j∈nu,nu为用户u加入的所有社交群组。
所述用户属性预测过程中,教育背景刻画是通过分析用户的社交关系模式,结合文本分析模块生成的先验知识库,基于关键字匹配刻画用户的教育背景,可能匹配上的关键字模式如下:
匹配过程按上述列表先后进行匹配,以上信息均未匹配,则认为社交群组为非班级群。
所述用户属性预测过程中,考虑用户加入的多个社交群组,最终对用户u的估计年龄是au,定义参数wu,j去评估社交群组
其中,σu,j代表社交群组
令
本发明还提供了一种基于社交信息的用户属性预测系统,包括:
数据获取模块:获取全国各学校名称及专业名称,构建先验知识库;
具体地,数据获取模块即从网上获取全国所有学校名称,同时得到各高校开设专业名称,构建先验知识库。
文本分析模块:对得到的全国各学校名称及专业名称进行处理,输出高校简称和专业简称,完善先验知识库;
具体地,在实际生活使用中,为了方便,大家常用简称代替全名称进行沟通交流,在社交群组更是如此,所以对未知简称的学校和专业名称,我们需要生成对应的简称。
社交群组分析模块:分析各社交群组,计算其对用户属性预测所能提供的有价值信息;
具体地,对各社交群组,使用经验和3σ原则剔除社交群组的噪音点,考虑各社交群组提供信息的权重大小,计算其提供的价值信息。
用户属性预测模块:利用用户在多个群组的社交关系,考虑每个社交群组提供的信息,加权分析预测出用户的真实属性,所述用户的真实属性主要包括用户教育背景和年龄。
具体地,通过分析用户的社交关系模式,结合文本分析模块生成的先验知识库,基于关键字匹配刻画用户的教育背景。评估每个社交群组提供的信息,筛选出部分社交群组,给提供信息更准确的社交群组分配更高权值,然后对多个群组加权求值,从而预测出用户的年龄属性。
与现有技术相比,本发明的有益效果是:
1、通过引入外部数据,对社交群组分析和用户教育背景刻画提供先验知识库,提升了结果的可信度。
本发明将全国高校及专业名称信息作为先验知识库,考虑社交群组的名称及简介,基于关键字匹配对社交群组进行分类,刻画出用户教育背景的同时,大大提升了结果的说服力。
2、结合高校专业缩写信息,完善了先验知识库。
本发明将根据专业全称,生成专业缩写,完善了先验知识库,对社交群组分析提供了更多信息。
3、通过对社交群组信息加权来推测用户的属性信息,考虑各群组提供信息的差异性,提升最终结果的评估准确度。
本发明通过分析用户加入社交群组的动机,评估每个社交群组提供的信息价值,筛选出可信的社交群组,并根据各社交群组提供的信息不同,加权预测计算得到最终用户属性。因考虑到各社交群组提供信息的差异性,给提供信息高的社交群组更高的权值,使得最终预测得到的用户属性更可信。
附图说明
图1为本发明方法整体结构图。
图2为本发明文本处理模块专业简称可信度预测流程图。
图3为本发明文本处理模块生成专业简称流程图。
图4为本发明社交群组分析模块流程图。
图5为本发明用户属性预测模块用户教育背景刻画流程图。
图6为本发明用户属性预测模块用户年龄属性预测流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面结合附图和实施例详细说明本发明的实施方式。
如图1所示,本系统由四个模块组成,分别是数据获取模块,文本分析模块,社交群组分析模块和用户属性预测模块。
首先,从网上爬虫获取全国各学校名称及高校开设所有专业名称,包括全国各学校名称,包括小学,初中,高中,大学,以及高校开设所有专业名称,构建先验知识库。
接着,对数据获取模块得到的全国学校名称及各高校开设所有专业名称进行处理。输出高校简称和专业简称。
值得说明的是,所获取学校名称和高校开设专业名称是全称,而在实际生活或社交网络中,大家大多采取专业或学校缩写来表示所学专业或就读学校,因此需要根据专业或学校全称来生成可信的专业或学校缩写。
然后,考虑各社交群组提供信息的差异性,剔除群组中噪音点,计算每个群组对用户预测所提供的价值信息。
最后,通过分析用户的社交关系模式,结合文本分析模块生成的先验知识库,基于关键字匹配刻画用户的教育背景。评估每个社交群组提供的信息,筛选出部分有价值的社交群组,给提供信息相对更准确的社交群组分配更高权值,然后对多个群组加权求值,从而预测出用户年龄属性。
本发明中各个模块的详细介绍如下:
1、数据获取模块
主要实现先验知识库的构建,获取全国学校名称以及各高校开设的所有专业。
具体地,数据获取模块对学校名称的处理过程如下:
作为中国领先的实名制社交网络平台,人人网提供了一个全方位的互动交流平台,同时在个人页面,允许用户编辑个人信息,填写包括小学,初中,中专技校、高中以及大学等信息,人人网鼓励大家实名注册并对填写学校可进行验证,保证了信息来源的可靠性及全面性。本发明使用scrapy框架,模拟用户登录人人网,当用户在个人主页编辑资料信息时,选择添加学校,页面弹出全国各地所有学校,按省市递归爬取所有页面列表,解析出全国高校名称信息。
数据获取模块对高校专业处理的过程如下:
在用户选定大学和相应的入学年份后,下方弹出该高校开设的专业院系,模拟用户选定学校这一行为,依次选定各高校,使用scrapy框架爬取高校开设所有的专业名称。经过汇总去重,得到全国高校开设所有专业。
另外,在全国高校本科专业目录网站上,使用scrapy框架爬虫获取所列所有专业。作为上述通过人人网爬取到专业名称的一个补充。部分高校和专业的简称在网上有给出,作为后续文本处理的训练集。
2、文本分析模块
主要功能是对数据获取模块得到的全国学校名称及各高校开设所有专业名称进行处理。输出高校简称和专业简称。
具体地,在实际生活使用中,为了方便,大家常用简称代替全名称进行沟通交流,在社交群组更是如此,所以对未知简称的高校和专业名称,需要生成对应的简称。
对专业名称的处理,如图2和图3所示,流程如下:
1)计算专业名字全称的长度为n,计算得到该字符串可能的所有子串,即字符串组合问题,从n个字符中,任取m个字符组合成一个新的字符串,m~[min,max],其中,min是要生成的专业简称的最小长度,max为最大长度,一般而言,1<min<max<n。
2)提取专业简称的特征,利用这些特征训练分类器,利用已知的部分专业简称作为训练集,预测生成的未知专业简称的可信度。具体来说:
2.1)在特征提取部分,考虑了生成的子串的最大距离、最小距离、平均距离、子串的长度、以及是否包含首尾字符(1为包含首字符,2为包含尾字符,3为都包含,0为都不包含)。其中提到的距离为任意两个字符的距离为在原专业全称中的位置相差的绝对值,举例来说,专业“软件工程”,有一子串“软工”,这两个字符的距离为2.
2.2)分类器采用logistic回归(sklearn.linear_model-logisticregression),使用了基于python的机器学习库scikit-learn。对于专业来说,部分专业的简称是已知的,使用这部分样本作为训练集,对分类器进行训练,再使用该分类器对其余专业生成的专业简称进行预测,分类器输出值作为生成的该专业简称的可信度。
3)步骤2)输出生成的专业简称的可信度,对一个专业来说,有多个专业简称,对这多个专业简称,进行可信度排名,选择可信度高的前k个作为该专业的简称。
经过上面三个步骤,对每个专业,选取k个专业简称作为其对应的候选集。
同理,学校名称对应的简称生成过程如上。
3、社交群组分析模块
主要功能是分析各社交群组,计算其对用户属性预测所能提供的有价值信息。
具体地,如图4所示,对各社交群组,因社交群组是由每个独立个体组成,因个体的差异提供的信息价值也不相同,也就是说,有的用户提供的信息明显是“噪音”,所以,假设社交群组中用户年龄值为[amin,amax],根据经验,设定amin=4,amax=100,使用这个简单规则,首先识别出社交群组的gj中的异常用户
接着根据3σ原则剔除噪音点,在正态分布中σ代表标准差,μ代表均值,x=μ即为图像的对称轴,3σ原则为数值分布在(μ—3σ,μ+3σ)中的概率为0.9974,过滤掉不在±3σ范围的噪音点。
对每个社交群体gj,μj和σj为社交群组gj中用户年龄的平均值和方差,如下计算:
社交群组gj中有异常年龄的用户为:
用
当nu,j>0时,让μu,j代表社交群组
“物以类聚,人以群分”,互联网中社交群体是将用户因某一兴趣或者班级原因,而聚集在一起,因此一个社交群体中的用户属性相似。利用这一特性,估计用户属性的时候,可参考其加入的社团群体中其他用户的特征信息。对用户加入的群组,估计其加入的群组j(j∈nu,nu为用户u加入的所有社交群体)的平均年龄为μu,j,并将该值作为当前社交群组对用户u的年龄估计值。
4、用户属性预测模块
利用用户在多个群组的社交关系,考虑每个社交群组提供的信息,加权计算预测出用户属性。主要包括用户教育背景刻画和年龄预测。
1)教育背景刻画
如图5所示,通过分析用户的社交关系模式,结合文本分析模块生成的先验知识库,基于关键字匹配刻画用户的教育背景。
为了描述方便,表1给出可能匹配上的关键字模式:
表1待匹配的关键字
注:匹配过程按上述列表先后进行匹配,以上信息均未匹配,则认为社交群组为非班级群。
通过对社交群组名称和简介利用上述关键字,按优先级进行匹配,识别出用户加入的具体班级类型(大学,初中,高中,小学,硕士,博士),刻画出相应的教育背景。并且根据“%班%/%届%”关键字,识别出用户就读该校的年份。对于没打上标签的社交群组,则认为是非班级群。
2)年龄预测
如图6所示,具体地,一般来说,用户加入不止一个社交群组,也就是说,|nu|>1。接着,考虑多个社交群组,最终对用户u的估计年龄是au。定义参数wu,j去评估社交群组
其中,σu,j代表社交群组
一般来说,同班同学之间年龄更为相似。所以,介绍一种基于班级群的用户年龄估计方法。
综上,本发明提供的一种基于社交信息的用户属性预测模块,通过对用户加入的社交群体关系进行分析,预测用户的真实身份属性。本发明可用于用户属性真实性检测,也可用于用户画像。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于生成和显示通过社交网络的用户内容的视觉流的技术的制作方法
- 媒体流的转移方法和用户设备的制作方法
- 用于向社交网络中的用户提醒好友位置变化的方法和设备的制作方法
- Network element for enabling a user of an IPTV system to obtain media stream ...的制作方法
- 用于模拟社交网络中离线用户的推荐的方法和系统的制作方法
- 一种用户设备的媒体信息获知方法和用户设备的制作方法
- 用于同步社交网络中的用户内容的方法和系统的制作方法
- 利用媒体提示来识别和关联用户设备的系统、方法和介质的制作方法
- 基于用户的媒体内容分节系统和方法
- 对公司社交网络的用户接收的消息进行分类的方法