人工智能客服机器人的问题解答方法及系统与流程
本发明涉及人工智能领域,特别涉及一种人工智能客服机器人的问题解答方法及系统。
背景技术:
目前,最广泛的客服聊天机器人,使用了传统nlp(naturelanguageprocessing,自然语言处理)技术,对问题进行关键字提取,然后进行聚类,并在答案集合中进行匹配。在匹配的结果中,进行短文本相似度计算,针对每个候选答案给出一个分值,排序后取前n个返回给用户。
由于语言表达的多样性、语义理解的困惑度,特别是中文的歧义等现象非常常见,导致了nlp技术的解答准确率比较低,而且由于自然语言处理中的上下文复杂性,这种技术的解答准确率是受到严重限制的。同时这种技术的语料库的维护成本相当高,需要人工给出很多的标注,对词的聚类也需要投入大量的人工,因此在企业实际应用中,在企业和用户两方面都没有得到很好的反馈。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中客服聊天机器人使用的nlp技术解答准确率低,语料库的维护成本高,导致用户体验度低的缺陷,提供一种人工智能客服机器人的问题解答方法及系统。
本发明是通过下述技术方案来解决上述技术问题:
一种人工智能客服机器人的问题解答方法,其特点在于,所述问题解答方法包括以下步骤:
s1、接收整段问题信息,对所述整段问题信息进行多卷积,并且提取若干个主要特征信息;
s2、对若干个主要特征信息进行下采样处理,并且从若干个主要特征信息提取若干个目标特征信息;
s3、根据若干个目标特征信息并基于人工智能分类算法输出问题类型信息;
s4、根据所述问题类型信息查询对应类型的语料库;
s5、从所述整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息,将所述问题序列文本信息分别与若干个解答序列文本信息进行匹配,并且生成相似度列表,所述相似度列表用于表征所述问题序列文本信息分别与若干个解答序列文本信息之间的相似度;
s6、输出所述相似度列表中相似度最高的解答序列文本信息所对应的解答信息。
较佳地,在步骤s1中,基于cnn(convolutionalneuralnetwork,卷积神经网络)模型对所述整段文本信息进行多卷积,并且提取若干个主要特征信息;
在步骤s3中,所述人工智能分类算法为softmax算法(机器学习算法)。
较佳地,在步骤s5中,基于bi-lstm模型(双向长短时记忆模型)及cnn模型,从所述整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息。
较佳地,在步骤s5中,采用cosine(余弦)算法将所述问题序列文本信息分别与若干个解答序列文本信息进行匹配。
较佳地,在步骤s5中,生成所述相似度列表之后,对所述相似度列表中的若干个解答序列文本信息以相似度从高到低的顺序进行排列,并且选取前五个解答序列文本信息;
在步骤s6中,输出前五个解答序列文本信息中相似度最高的解答序列文本信息所对应的解答信息,还分别输出其余四个解答序列文本信息所对应的解答信息对应的问题信息。
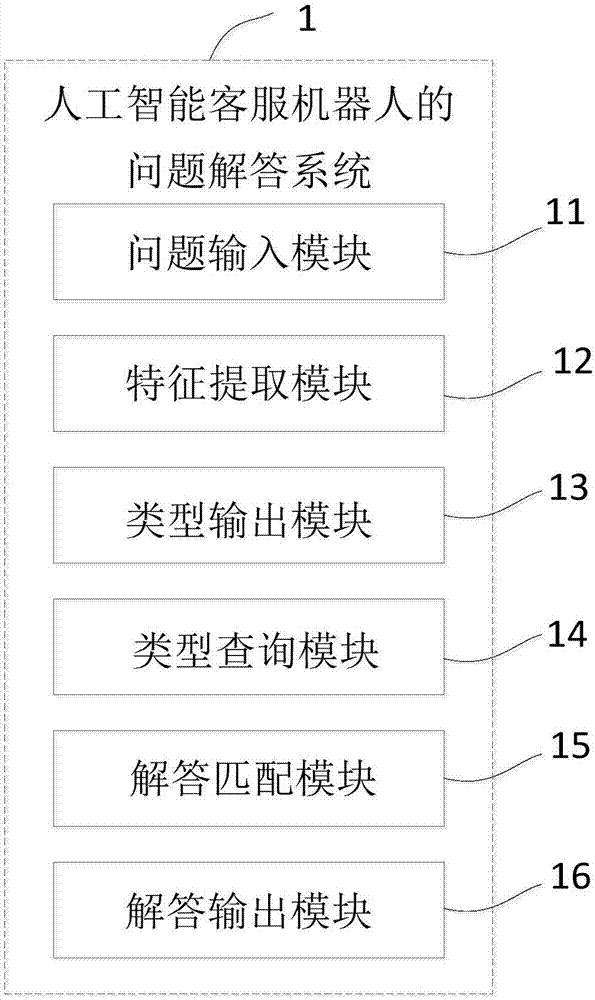
一种人工智能客服机器人的问题解答系统,其特点在于,所述问题解答系统包括问题输入模块、特征提取模块、类型输出模块、类型查询模块、解答匹配模块及解答输出模块;
所述问题输入模块用于接收整段问题信息,并且将所述整段问题信息发送至所述特征提取模块;
所述特征提取模块用于对所述整段问题信息进行多卷积,并且提取若干个主要特征信息,所述特征提取模块还用于对若干个主要特征信息进行下采样处理,并且从若干个主要特征信息提取若干个目标特征信息,所述特征提取模块还用于将若干个目标特征信息发送至所述类型输出模块;
所述类型输出模块用于根据若干个目标特征信息并基于人工智能分类算法输出问题类型信息;
所述类型查询模块用于根据所述问题类型信息查询对应类型的语料库;
所述解答匹配模块用于从所述整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息,将所述问题序列文本信息分别与若干个解答序列文本信息进行匹配,并且生成相似度列表,所述相似度列表用于表征所述问题序列文本信息分别与若干个解答序列文本信息之间的相似度;
所述解答输出模块用于输出所述相似度列表中相似度最高的解答序列文本信息所对应的解答信息。
较佳地,所述特征提取模块用于基于cnn模型对所述整段文本信息进行多卷积,并且提取若干个主要特征信息;
所述人工智能分类算法为softmax算法。
较佳地,所述解答匹配模块用于基于bi-lstm模型及cnn模型,从所述整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息。
较佳地,所述解答匹配模块用于采用cosine算法将所述问题序列文本信息分别与若干个解答序列文本信息进行匹配。
较佳地,所述解答匹配模块用于生成所述相似度列表之后,对所述相似度列表中的若干个解答序列文本信息以相似度从高到低的顺序进行排列,并且选取前五个解答序列文本信息;
所述解答输出模块用于输出前五个解答序列文本信息中相似度最高的解答序列文本信息所对应的解答信息,还分别输出其余四个解答序列文本信息所对应的解答信息对应的问题信息。
在符合本领域常识的基础上,上述各优选条件,可任意组合,即得本发明各较佳实例。
本发明的积极进步效果在于:
本发明提供的人工智能客服机器人的问题解答方法及系统使用深度学习模型,极大地提高了人工智能客服机器人的解答准确率,降低了语料库的维护成本,从而较好地满足在企业实际应用中的各项要求,提高了用户体验度。
附图说明
图1为本发明较佳实施例的人工智能客服机器人的问题解答方法的流程图。
图2为本发明较佳实施例的人工智能客服机器人的问题解答系统的结构示意图。
图3为本发明较佳实施例中的分布式容器化部署的示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
如图1所示,本实施例提供的人工智能客服机器人的问题解答方法包括以下步骤:
步骤101、接收整段问题信息,对整段问题信息进行多卷积,并且提取若干个主要特征信息。
在本实施例中,所述问题解答方法采用两级的深度学习模型,第一级trigger模型(深度学习的常用模型)负责对输入问题进行分类,从而为第二级的模型选择提供依据。第二级的qa模型(深度学习的常用模型)负责对该分类下的问题进行答案匹配并输出结果。
在本步骤中,人工智能客服机器人接收用户输入的问题后,即整段问题信息,并且准备进行问题的分类工作。
在本步骤中,基于cnn模型对所述整段文本信息进行多卷积,并且提取若干个主要特征信息。
步骤102、对若干个主要特征信息进行下采样处理,并且从若干个主要特征信息提取若干个目标特征信息。
在本步骤中,对若干个主要特征信息进行下采样处理,从而进一步提取若干个目标特征信息。在本实施例中,并不具体限定主要特征信息及目标特征信息的提取数量,均可根据实际情况及实际算法来提取。
步骤103、根据若干个目标特征信息并基于softmax算法输出问题类型信息。
步骤104、根据所述问题类型信息查询对应类型的语料库。
在本步骤中,根据输出的问题类型信息来查询对应类型的语料库,例如,当用户输入旅游相关问题,问题类型信息可以为“签证类”、“自由行类”、“团队游类”等,接下来查询并匹配相应类型的签证语料库、自由行语料库、团队游语料库等,当然本实施例中并不具体限定语料库的类型,均可根据实际情况来自行设定。
步骤105、从整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息,将问题序列文本信息分别与若干个解答序列文本信息进行匹配,并且生成相似度列表。
在本步骤中,基于bi-lstm模型及cnn模型,从所述整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息。
在本步骤中,采用cosine算法将所述问题序列文本信息分别与若干个解答序列文本信息进行匹配。
在本步骤中,所述相似度列表用于表征所述问题序列文本信息分别与若干个解答序列文本信息之间的相似度。
在本实施例中,采用了qa模型的混合模型,即bi-lstm模型和cnn模型的混合模型,充分利用了bi-lstm模型对序列文本的解析能力,同时通过双向计算,大大提高了模型的稳定性和多特征综合提取。在级联cnn模型的基础上,摒弃了softmax层,选择了cosine算法对向量进行比较,从而输出相似度。
步骤106、对相似度列表中的若干个解答序列文本信息以相似度从高到低的顺序进行排列,并且选取前五个解答序列文本信息。
在本步骤中,虽然仅示出选取前五个解答序列文本信息的方案,但是并不具体所选取的解答序列文本信息的数量,也可根据实际情况进行或多或少的调整。
步骤107、输出前五个解答序列文本信息中相似度最高的解答序列文本信息所对应的解答信息,还分别输出其余四个解答序列文本信息所对应的解答信息对应的问题信息。
在本实施例中,在人工智能客服机器人训练阶段中,首先需要对语料库进行技术整理,整理出相应的问答分类,并归入各分类的对应语料库。送入模型进行训练。切出其中的10%作为测试数据集,并在训练完成后进行测试验证。验证通过后,即可进行实际提问,并得到相应的回答分类。
如图3所示,在人工智能客服机器人实施阶段中,由于深度模型依赖的实施环境和运行环境都较复杂,本实施例中采用了分布式容器化部署,结果证明其对于系统监控、loadbalance(负载均衡)及稳定性都提供了很好的保障,mesos为开源分布式资源管理框架,是分布式系统的内核,docker为虚拟机容器。
在本实施例中,所述问题解答方法应用人工智能的深度学习模型,可以在以下几个方面获得显著的效果:
1、由于深度学习模型的模型层数较深,对于语言的解析更加全面且多层次;
2、多深度模型混合,可以从更多方面根据各自特性综合对同一问答对进行分析,大幅度提升了准确率;
3、由于深度学习模型的本质属于机器学习,所以伴随着语料库样本的不断增加,模型准确率和召回率可以不断提升,并达到和保持在一个高可用的基准上;
4、由于深度学习模型的特性是端到端的学习,因此不需要对语料进行关键字提取、聚类、关键字匹配等步骤,大大减少了该环节的人工成本和技术成本;
5、应用深度学习模型后,对于多国语言的训练和模型输出也会变得更通用和低成本,而这一点在传统nlp技术上是无法实现或者代价很大。
如图2所示,本实施例还提供一种人工智能客服机器人的问题解答系统1,包括问题输入模块11、特征提取模块12、类型输出模块13、类型查询模块14、解答匹配模块15及解答输出模块16。
在本实施例中,人工智能客服机器人的问题解答系统1采用两级的深度学习模型,第一级trigger模型(深度学习的常用模型)负责对输入问题进行分类,从而为第二级的模型选择提供依据。第二级的qa模型(深度学习的常用模型)负责对该分类下的问题进行答案匹配并输出结果。
问题输入模块11用于接收整段问题信息,并且将所述整段问题信息发送至特征提取模块12。在本实施例中,人工智能客服机器人接收用户输入的问题后,即整段问题信息,并且准备进行问题的分类工作。
特征提取模块12用于基于cnn模型对所述整段文本信息进行多卷积,并且提取若干个主要特征信息,特征提取模块12还用于对若干个主要特征信息进行下采样处理,并且从若干个主要特征信息提取若干个目标特征信息,特征提取模块12还用于将若干个目标特征信息发送至类型输出模块13。在本实施例中,并不具体限定主要特征信息及目标特征信息的提取数量,均可根据实际情况及实际算法来提取。
类型输出模块13用于根据若干个目标特征信息并基于softmax算法输出问题类型信息。
类型查询模块14用于根据所述问题类型信息查询对应类型的语料库。在本实施例中,根据输出的问题类型信息来查询对应类型的语料库,例如,当用户输入旅游相关问题,问题类型信息可以为“签证类”、“自由行类”、“团队游类”等,接下来查询并匹配相应类型的签证语料库、自由行语料库、团队游语料库等,当然本实施例中并不具体限定语料库的类型,均可根据实际情况来自行设定。
解答匹配模块15用于基于bi-lstm模型及cnn模型,从所述整段问题信息中提取问题序列文本信息,从对应类型的语料库中的若干个解答信息中分别提取若干个解答序列文本信息,采用cosine算法将所述问题序列文本信息分别与若干个解答序列文本信息进行匹配,并且生成相似度列表,所述相似度列表用于表征所述问题序列文本信息分别与若干个解答序列文本信息之间的相似度。
在本实施例中,采用了qa模型的混合模型,即bi-lstm模型和cnn模型的混合模型,充分利用了bi-lstm模型对序列文本的解析能力,同时通过双向计算,大大提高了模型的稳定性和多特征综合提取。在级联cnn模型的基础上,摒弃了softmax层,选择了cosine算法对向量进行比较,从而输出相似度。
解答匹配模块15还用于生成所述相似度列表之后,对所述相似度列表中的若干个解答序列文本信息以相似度从高到低的顺序进行排列,并且选取前五个解答序列文本信息。在本实施例中,虽然仅示出选取前五个解答序列文本信息的方案,但是并不具体所选取的解答序列文本信息的数量,也可根据实际情况进行或多或少的调整。
解答输出模块16用于输出前五个解答序列文本信息中相似度最高的解答序列文本信息所对应的解答信息,还分别输出其余四个解答序列文本信息所对应的解答信息对应的问题信息。
在本实施例中,在人工智能客服机器人训练阶段中,首先需要对语料库进行技术整理,整理出相应的问答分类,并归入各分类的对应语料库。送入模型进行训练。切出其中的10%作为测试数据集,并在训练完成后进行测试验证。验证通过后,即可进行实际提问,并得到相应的回答分类。
如图3所示,在人工智能客服机器人实施阶段中,由于深度模型依赖的实施环境和运行环境都较复杂,本实施例中采用了分布式容器化部署,结果证明其对于系统监控、loadbalance(负载均衡)及稳定性都提供了很好的保障,mesos为开源分布式资源管理框架,是分布式系统的内核,docker为虚拟机容器。
在本实施例中,人工智能客服机器人的问题解答系统1应用人工智能的深度学习模型,可以在以下几个方面获得显著的效果:
1、由于深度学习模型的模型层数较深,对于语言的解析更加全面且多层次;
2、多深度模型混合,可以从更多方面根据各自特性综合对同一问答对进行分析,大幅度提升了准确率;
3、由于深度学习模型的本质属于机器学习,所以伴随着语料库样本的不断增加,模型准确率和召回率可以不断提升,并达到和保持在一个高可用的基准上;
4、由于深度学习模型的特性是端到端的学习,因此不需要对语料进行关键字提取、聚类、关键字匹配等步骤,大大减少了该环节的人工成本和技术成本;
5、应用深度学习模型后,对于多国语言的训练和模型输出也会变得更通用和低成本,而这一点在传统nlp技术上是无法实现或者代价很大。
本实施例提供的人工智能客服机器人的问题解答方法及系统使用深度学习模型,极大地提高了人工智能客服机器人的解答准确率,降低了语料库的维护成本,从而较好地满足在企业实际应用中的各项要求,提高了用户体验度。
在现有nlp技术下,已有问答的解答准确率仅为72%,而理想情况下的深度模型的解答准确率为100%;现有nlp技术在开放问题句式下的解答准确率为43%,而理想情况下的深度模型在语料库仅数千条的情况下,开放问题句式的解答准确率可达到70%以上,并且伴随语料库的增加还可以获得较大的提升。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!