一种面向初等数学领域的分词方法与流程
本发明涉及自然语言处理
技术领域:
,具体涉及一种面向初等数学领域的分词方法。
背景技术:
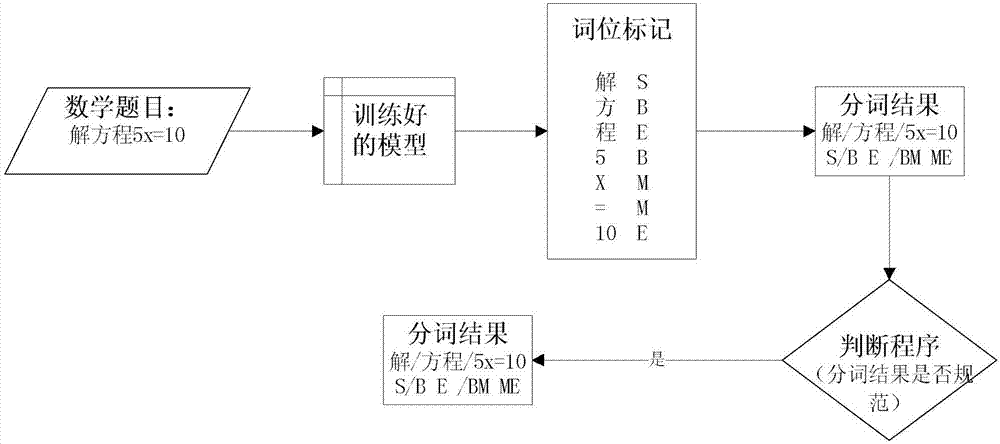
:随着信息技术的发展及人工智能技术的不断成熟,自然语言处理(nlp)得到了广泛的应用,同时有关的理论、技术也得到了很大的发展。然而目前绝大多数的自然语言处理和图像语义识别等方面的研究都集中于新闻、论坛、博客等领域,专业领域的研究较少,涉及到符号、数学公式等处理的就更少。然而,数学领域的文本不仅仅包含自然语言,还包含符号、数学公式等内容,而且其中所包含的自然语言也与平时用于日常交流的语言有一定差别。目前现有的自然语言处理算法不能直接应用于数学领域,如果想要使计算机实现初等数学问题自动求解,并生成类人的答题过程就需要对包含符号、数学公式、图形等元素的自然语言进行处理,需要融合和扩展自然语言处理和图像语义理解的研究。技术实现要素:基于此,针对上述问题,有必要提出一种面向初等数学领域的分词方法,其针对于数学领域,可以很好的对包含符号、数学公式、图形等元素的自然语言进行处理,可以有效地推动自然语言处理、图像语义理解、机器学习等人工智能领域中的关键技术针对数学领域的研究和应用。本发明的技术方案是:一种面向初等数学领域的分词方法,包括如下步骤:s1:根据初等数学中文分词所需的分词模型,按照中文分词规范进行定义,同时将公式、变量和符号定义为词语,并根据词性类别分别进行规定;s2:利用分词和词性标记后的数学标注语料库,并对通过训练后的模型进行切换,得到领域分词和词性标注模型;s3:判断分词结果是否符合初等数学领域的规范,如果是,则分词成功;如果否,则利用分词后处理程序进行重新分词。在基础框架方面,本发明采用大规模数据处理框架和基于深度学习的特征学习方法,利用大规模未标注语料构建特征集合,并利用特征集合结合结构化机器学习方法来完成处理任务。针对具体任务,本发明根据数学领域的文本特点,并结合通用自然语言处理基础问题的研究成果,研究发明了面向数学领域的分析方法。针对初等数学中文分词所需要的分词模型,本发明在常规的中文分词规范的基础上,将公式、变量、符号等也定义为词语,词性根据类别分别进行规定;然后使用自己研究的模型领域自适应方法,利用少量经过分词和词性标记的数学标注语料库,对通过新闻语料进行训练过的模型进行切换;此方法可以充分利用已有训练语料的信息,结合少量标注语料得到领域分词和词性标注模型;再把分词当作字的词位分类问题,用b代表词首,e代表词尾,m代表词中,s代表单字词,将b和e之间的字以及s单字构成分词;当分词结果不符合初等数学领域的规范时,使用分词后处理程序进行重新分词,综合利用了统计和规则的方法。作为上述方案的进一步优化,所述步骤s1具体包括以下步骤:在进行中文分词之前,将数学领域中数据稀疏的元素根据其所属类别变换为相应的中文词语。在常规的中文分词规范的基础上,将公式、变量、符号等也定义为词语,词性根据类别分别进行规定,在这种标注规范的情况下,数学领域的特有元素可能会存在数据稀疏性问题,如大多数公式在语料库中出现次数会非常低;因此,在进行中文分词之前,我们首先将这些数学领域特有内容根据其所属类别变换为相应的中文词语,有利于进行之后的中文分词,使分词的准确性提高。作为上述方案的进一步优化,所述步骤s2具体包括以下步骤:s21:根据基于深度学习的特征学习方法所需的未标注语料,收集相应的初等数学问题以及对应的答案文本,并利用训练初始的单词向量表示其形式;s22:利用4-tags标记,对训练语料做预处理,分别用字母“b”表示词首,字母“e”表示词尾,字母“m”表示词中,字母“s”表示单字词;并将数学表达式或特殊符号识别为一个词;s23:利用语言模型最大化的方法进行训练,并加入句子所在篇章的相关信息。本方案中所述的深度学习(deeplearning)是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。本发明首先针对基于深度学习的特征学习方法所需的海量未标注语料问题,通过网络题库收集一万多道初等数学问题以及对应的答案文本,利用其训练初始的单词向量表示形式;然后采用传统的4-tags标记法,对训练语料做预处理,分别用b代表词首,e代表词尾,m代表词中,s代表单字词;再利用语言模型最大化的方法进行训练,同时加入句子所在篇章的信息来提高单词向量学习的准确度,由于单词向量学习的计算复杂度极大,所以采用大规模数据处理框架进行并行学习。当分词后的结果不符合初等数学规范时则会进行相应的分词后处理,对于分词错误的句子则会根据上下文语境和数学知识重新进行分词,使得分词结果可以很好的使用于数学领域。作为上述方案的更进一步优化,所述步骤s3具体包括以下步骤:s31、根据上下文语境和数学规范,对分词错误的句子进行重新分词,依次把分词错误的前一个词段的字词进行入栈操作;s32、一边出栈一边和分词错误的后一个词段的字词进行匹配;s33、当发现数学中的特殊符号配对成功时,则证明原句的处理错误,需要把分词错误的前一个词段和后一个词段合并到一起,成为一个词。在本方案中,对于分词错误的句子则会根据上下文语境和数学知识重新进行分词,依次把分词错误的前一个词段的字词进行入栈操作,然后一边出栈一边和分词错误的后一个词段的字词进行匹配,当发现数学中的特殊符号(“()”,“{}”,“[]”)配对成功,说明原句的处理有错误,则需要把分词错误的前一个词段和后一个词段合并到一起,使之成为一个词。作为上述方案的更进一步优化,所述的分词方法采用条件随机场开源工具crf进行分词操作。本方案的条件随机场(crf)是一种常用于模式识别和机器学习的统计建模方法,主要用于结构化预测;crf是一种有区别的无向概率图形模型,它通常用于标记或解析顺序数据,如自然语言文本或生物序列和计算机视觉,在计算机视觉中,crf经常用于对象识别和图像分割;使用普通分类器预测单个样本的标签时一般不考虑“相邻”样本,但是crf可以考虑上下文,例如,线性链crf(其在自然语言处理中流行)预测输入样本的序列的标签序列。本发明的有益效果是:1、本发明利用语言模型最大化的方法进行训练,同时加入句子所在篇章的信息来提高单词向量学习的准确度,进而能被计算机所识别,便于资源的共享利用。2、本发明在常规的中文分词规范的基础上,将公式、变量、符号等也定义为词语,词性根据类别分别进行规定,研究出了模型的领域自适应方法,利用少量经过分词和词性标记的数学标注语料库,对通过新闻语料进行训练过的模型进行切换;可以充分利用已有训练语料的信息,结合少量标注语料得到领域分词和词性标注模型。3、本发明采用传统的4-tags标记法,对训练语料做预处理,分别用b代表词首,e代表词尾,m代表词中,s代表单字词,当分词后的结果不符合初等数学规范时则会进行相应的分词后处理,对于分词错误的句子则会根据上下文语境和数学知识重新进行分词,使得分词结果可以很好的使用于数学领域。附图说明图1是本发明实施例所述面向初等数学领域的分词方法的流程图;图2是本发明实施例对应表2在未进行后处理程序的中文分词流程图;图3是本发明实施例对应表3在进行了后处理程序的中文分词流程图。具体实施方式下面结合附图对本发明的实施例进行详细说明。实施例如图1所示,一种面向初等数学领域的分词方法,包括如下步骤:s1:根据初等数学中文分词所需的分词模型,按照中文分词规范进行定义,同时将公式、变量和符号定义为词语,并根据词性类别分别进行规定;s2:利用分词和词性标记后的数学标注语料库,并对通过训练后的模型进行切换,得到领域分词和词性标注模型;s3:判断分词结果是否符合初等数学领域的规范,如果是,则分词成功;如果否,则利用分词后处理程序进行重新分词。在基础框架方面,本发明采用大规模数据处理框架和基于深度学习的特征学习方法,利用大规模未标注语料构建特征集合,并利用特征集合结合结构化机器学习方法来完成处理任务。针对具体任务,本发明根据数学领域的文本特点,并结合通用自然语言处理基础问题的研究成果,研究发明了面向数学领域的分析方法。针对初等数学中文分词所需要的分词模型,本发明在常规的中文分词规范的基础上,将公式、变量、符号等也定义为词语,词性根据类别分别进行规定;然后使用自己研究的模型领域自适应方法,利用少量经过分词和词性标记的数学标注语料库,对通过新闻语料进行训练过的模型进行切换;此方法可以充分利用已有训练语料的信息,结合少量标注语料得到领域分词和词性标注模型;再把分词当作字的词位分类问题,用b代表词首,e代表词尾,m代表词中,s代表单字词,将b和e之间的字以及s单字构成分词;当分词结果不符合初等数学领域的规范时,使用分词后处理程序进行重新分词,综合利用了统计和规则的方法。在其中一个实施例中,所述步骤s1具体包括以下步骤:在进行中文分词之前,将数学领域中数据稀疏的元素根据其所属类别变换为相应的中文词语。将公式、变量、符号等也定义为词语,词性根据类别分别进行规定,在这种标注规范的情况下,数学领域的特有元素可能会存在数据稀疏性问题,如大多数公式在语料库中出现次数会非常低;因此,在进行中文分词之前,我们首先将这些数学领域特有内容根据其所属类别变换为相应的中文词语,有利于进行之后的中文分词,使分词的准确性提高。在另一个实施例中,所述步骤s2具体包括以下步骤:s21:根据基于深度学习的特征学习方法所需的未标注语料,收集相应的初等数学问题以及对应的答案文本,并利用训练初始的单词向量表示其形式;s22:利用4-tags标记,对训练语料做预处理,分别用字母“b”表示词首,字母“e”表示词尾,字母“m”表示词中,字母“s”表示单字词;并将数学表达式或特殊符号识别为一个词;s23:利用语言模型最大化的方法进行训练,并加入句子所在篇章的相关信息。本方案中所述的深度学习(deeplearning)是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。本发明首先针对基于深度学习的特征学习方法所需的海量未标注语料问题,通过网络题库收集一万多道初等数学问题以及对应的答案文本,利用其训练初始的单词向量表示形式;然后采用传统的4-tags标记法,对训练语料做预处理,分别用b代表词首,e代表词尾,m代表词中,s代表单字词;再利用语言模型最大化的方法进行训练,同时加入句子所在篇章的信息来提高单词向量学习的准确度,由于单词向量学习的计算复杂度极大,所以采用大规模数据处理框架进行并行学习。当分词后的结果不符合初等数学规范时则会进行相应的分词后处理,对于分词错误的句子则会根据上下文语境和数学知识重新进行分词,使得分词结果可以很好的使用于数学领域。在另一个实施例中,所述步骤s3具体包括以下步骤:s31、根据上下文语境和数学规范,对分词错误的句子进行重新分词,依次把分词错误的前一个词段的字词进行入栈操作;s32、一边出栈一边和分词错误的后一个词段的字词进行匹配;s33、当发现数学中的特殊符号配对成功时,则证明原句的处理错误,需要把分词错误的前一个词段和后一个词段合并到一起,成为一个词。在本方案中,对于分词错误的句子则会根据上下文语境和数学知识重新进行分词,依次把分词错误的前一个词段的字词进行入栈操作,然后一边出栈一边和分词错误的后一个词段的字词进行匹配,当发现数学中的特殊符号(“()”,“{}”,“[]”)配对成功,说明原句的处理有错误,则需要把分词错误的前一个词段和后一个词段合并到一起,使之成为一个词。在另一个实施例中,所述的分词方法采用条件随机场开源工具crf进行分词操作。本方案的条件随机场(crf)是一种常用于模式识别和机器学习的统计建模方法,主要用于结构化预测;crf是一种有区别的无向概率图形模型,它通常用于标记或解析顺序数据,如自然语言文本或生物序列和计算机视觉,在计算机视觉中,crf经常用于对象识别和图像分割;使用普通分类器预测单个样本的标签时一般不考虑“相邻”样本,但是crf可以考虑上下文,例如,线性链crf(其在自然语言处理中流行)预测输入样本的序列的标签序列。如图2和图3所述本发明的中文分词流程图,把分词当作了字的词位分类问题,通常用b代表词首,e代表词尾,m代表词中,s代表单字词,将b和e之间的字,以及s单字构成分词,综合了统计和规则的方法经进行分词,具体步骤如下:a、输入一道初等数学题目;b、利用训练好的模型对题目进行词位标记(b代表词首,e代表词尾,m代表词中,s代表单字词);c、将分词(将b和e之间的字以及s单字构成分词)后的结果保存到设置好的数据结构中方便使用;d、在使用分词后的数学题目提取关系和数据时发现分词结果不符合初等数学规范(分词时进行了错误的处理),则进行步骤e的分词后处理;e、对于分词不符合初等数学规范的句子(数学表达式、括号之类的)重新进行分词,利用栈来实现括号的匹配,从而避免将一对括号(“()”,“{}”,“[]”)拆分开来。下面以实例详细说明一种面向初等数学领域的分词方法的流程:这里选择一道题进行输入,题目信息为:求方程y=3x2+2x在区间[1,2]上的最大值。1、使用训练好的crf模型进行词位标注(其中第一列是序号,第二列是题干,第三列是词位标记的信息),结果如表1所示:表12、将b和e之间的字,以及s单字构成一个词语,分词的结果如表2所示(其中第一列为序号,第二列是词位标记,第三列是分词结果):表23、因为训练的模型是多样化的,所以进行词位标注的时候也是多样化的,不能够保证分词的结果一定符合现实需要,所以上述题目还可能会有如表3所示的分法:1s求2be方程3bmmmmmey=3x2+2x4s在5be区间6bme[1,7be2]8s上9s的10bme最大值11s。表3明显上文中的分词结果(具体见序号6、7)不符合数学领域的规范(因为把一个区间拆分开了),所以需要对分词结果进行重新分词,依次把序号6所代表的字词进行入栈操作,然后一边出栈一边和序号7所代表的字词进行字词匹配,可以发现序号6所代表的字词中的“[”和序号7所代表的字词中的“]”号配对,说明原句的处理有错误,需要把序号6、7所代表的字词合并为一个长的分词结果(正确的分词结果如表2所示)。以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1