一种基于隐状态模型的fMRI自然图像解码方法与流程
本发明属于fmri数据分析领域,涉及一种基于隐状态模型的fmri自然图像解码方法。
背景技术:
fmri(functionalmagneticresonanceimaging,功能核磁共振成像)是一种通过血氧水平变化探测大脑神经活动的检测技术。基于fmri信号的编解码模型成为近两年的研究热点,模型精度越高,说明该模型对大脑信息处理的解释越合理,对于研究大脑处理信息的模式有非常重要的参考意义。目前研究最为关注的是基于视觉fmri信号的编解码模型。
视觉fmri信号编码模型的特点在于,通过视觉刺激预测大脑响应。例如,对每一个体素的时间序列估计一个一般线性模型(glm,generallinearmodel)就可以算作是一种编码模型。在这模型中,假设每个体素最终测得的时间序列是由该体素对每一个实验条件的血液动力学响应所叠加起来的序列再混叠一些噪声构成。对所有体素拟合该模型,就能得到每个体素对每个实验条件的响应强度。一般线性模型的操作过程是用实验刺激序列和测得的信号预测大脑响应。在编码模型中,认为响应强度是图像各个特征的加权和。首先要提取和刺激图像相关的特征矩阵,对这些特征矩阵训练出一个权重,每一个体素对每一幅图都能够得到一个权向量,而对于一副新图,只要对该图像的特征矩阵进行加权求和就能够得到最终的预测强度。
视觉fmri信号解码模型的特点在于,用大脑响应去预测视觉刺激。解码模型按目的主要有分类、识别、重构三类。分类模型是要分出被试者所看的图像种类,例如,刺激图像的内容有动物和植物,解码模型需要根据测得的信号预测被试者所看到的到底是动物还是植物。识别模型的目的是要根据测得的信号预测出被试者看的是哪一副图。重构模型中,要把被试者所看到的刺激图像恢复出来。分类解码模型是最简单的,主要应用一些机器学习的方法就能够达到比较理想的结果。而识别解码模型相对较复杂,其中有一种思路是先编码再解码。例如,先训练一个一般的编码模型,简单来说就是先得到图像特征矩阵再用该矩阵训练出一个权向量。该模型能够预测出刺激图像对应的相关体素的响应强度,这些体素的响应强度组成一幅脑活动图(activitypattern),其实就是由响应强度组成的一个向量。当得到一个测得的脑活动图时,将这个脑活动图与和编码模型预测出的脑活动图进行对比,哪一幅图的预测图和测得的活动图更接近,则认为此图就是被试者所看的图。
重构解码模型可以拆分为简单的分类问题。在二值图像实验中,刺激图像是网格状的,每一格中要么有闪烁的黑白棋盘格纹理,要么是全灰背景,即,每一格中要么是有刺激的要么是无刺激的。这时,用测得的响应强度向量去分类每一格中到底是有刺激还是无刺激,分类完成后,再把所有格子的分类结果拼凑在一起,就能够得到最终重构的刺激图像。在分类是有刺激还是无刺激时,可应用简单的支持向量机或者神经网络等机器学习方法。
传统的图像解码方法存在模型精度不高的问题,造成了识别的准确率较低。
技术实现要素:
本发明的目的在于针对上述现有技术中的问题,提供一种基于隐状态模型的fmri自然图像解码方法,该方法能够大幅度缩小预测响应强度的误差,并且大幅度提高图像识别的准确率,进而为探究人类视觉皮层处理信息的数学模式提供了支持和依据。
为了实现上述目的,本发明采用的技术方案包括以下步骤:
1)求出刺激图像的特征矩阵,大脑体素的响应强度为特征矩阵的加权和;
2)求出特征矩阵的权向量以及估计的误差向量;
3)求出每个体素的误差向量与其他体素的误差向量之间的相关系数,根据相关系数越大对体素响应影响越大的关系,找出对目标体素响应影响明显的体素;
4)通过主成分分析法求取体素误差向量的主成分,作为引入的隐状态特征;
5)按照响应强度为特征矩阵和隐状态的加权和,重新估计模型,求出新的权向量,得到训练出的隐状态编码模型,通过训练出的隐状态编码模型进行图像识别。
所述的步骤1)首先将刺激图像划分为网格状,在每个格点上设计五个不同空间频率、八个不同方向、两个正交相位共80个gbaor滤波器,对图像进行滤波,得到特征矩阵x;
单个体素对应每个特征矩阵x有一个响应强度,则有向量y=[y1,y2,…,yi,…yn]∈rn×1,其中,不同的元素表示该体素对不同刺激图像的响应强度,共有n幅图,x=[x1,x2,…,xi,…,xn]t∈r(n×(m+1)),其中,不同的元素表示不同刺激图像的特征矩阵。
所述的步骤2)通过编码模型y=xα+r进行预估计,通过感受野模型计算出每一个体素的感受野之后,筛选出感受野有效的体素,最后求解出每个体素对应的误差向量r=y-xα。
所述的相关系数为皮尔逊相关系数,并且由大至小按序选择出多个对目标体素响应影响明显的体素。所述的隐状态编码模型为y=xα+hβ+n,通过pca求取选出体素对应相关误差向量的主成分,作为式中的隐状态h。
所述的步骤5)首先通过新的权向量求解出每个体素对每个刺激图像的响应强度,得到由多个体素响应强度组成的脑活动图,所得脑活动图与测试集中预测的每一个刺激图像相对应;再求出测得的脑活动图与预测脑活动图之间的误差,经过步骤4)求解出每一个刺激图像对应的隐状态。图像识别的具体过程为:
1、向量v=[v1,v2,…,vi,…,vp]t∈r(p×1)表示对某一幅刺激图像测得的脑活动图,式中的不同元素分别表示不同体素对该图像的响应强度,向量v′=[v1′,v2′,…,vi′,…,vp′]t∈r(p×1)表示通过一般编码模型预测的活动图;2、求v与v′二者之间的误差向量,e=v-ν′,e=[e1,e2,…,ei,…,ep]t∈r(p×1),式中的不同元素分别表示不同体素的预测强度与真实强度之间的误差;3、假定第j,k,l个体素对第i个体素的影响最大,则选出第j,k,l个体素的误差值;4、求解hi=f(ej,ek,el),式中的函数f(·)是步骤5)中用pca学习出的线性变换;5、用隐状态编码模型预测脑活动图,计算
与现有技术相比,本发明具有如下的有益效果:假设体素的响应强度是特征矩阵和隐状态的加权和,因此首先计算出刺激图像的特征矩阵,训练出一个权向量,然后再求出训练模型的误差,这样每一个体素都对应了一个误差向量。通过主成分分析法,求出对某个体素响应强度有影响的几个体素的误差向量的主成分,将主成分作为该体素的隐状态,将隐状态加入特征矩阵再重新训练一个权向量,这样即得到了隐状态编码模型。在解码过程中,首先用隐状态编码模型预测出每一幅图对应的响应强度序列,将测得的响应强度序列与预测的序列进行相关运算,相关性最大的一幅图即为被试者所看的刺激图像。本发明引入隐状态作为新的变量,结合图像的纹理信息建立隐状态编码模型进行图像识别,通过fmri信号能够预测被试者所看到的刺激图像,图像识别模型稳定,大幅缩小了预测响应强度的误差,有效地提高了图像识别的准确率以及预测精度,在通过脑信号解码视觉信息领域易于推广和应用。
附图说明
图1本发明隐状态编码模型的原理图;
图2本发明训练隐状态编码模型的流程图;
图3本发明进行图像识别的流程图;
图4隐状态编码模型与一般编码模型预测误差的对比统计图;
图5隐状态解码模型与一般解码模型识别准确率的对比统计图;
具体实施方式
下面结合附图对本发明做进一步的详细说明。
参见图1,隐状态编码模型的工作原理为:将由一般编码模型预测得到的脑活动图与真实测得的脑活动图之间的误差进行一个线性变换,首先估算出隐状态,求出新的权向量,得到训练出的隐状态编码模型,再由隐状态模型预测出新的脑活动图。
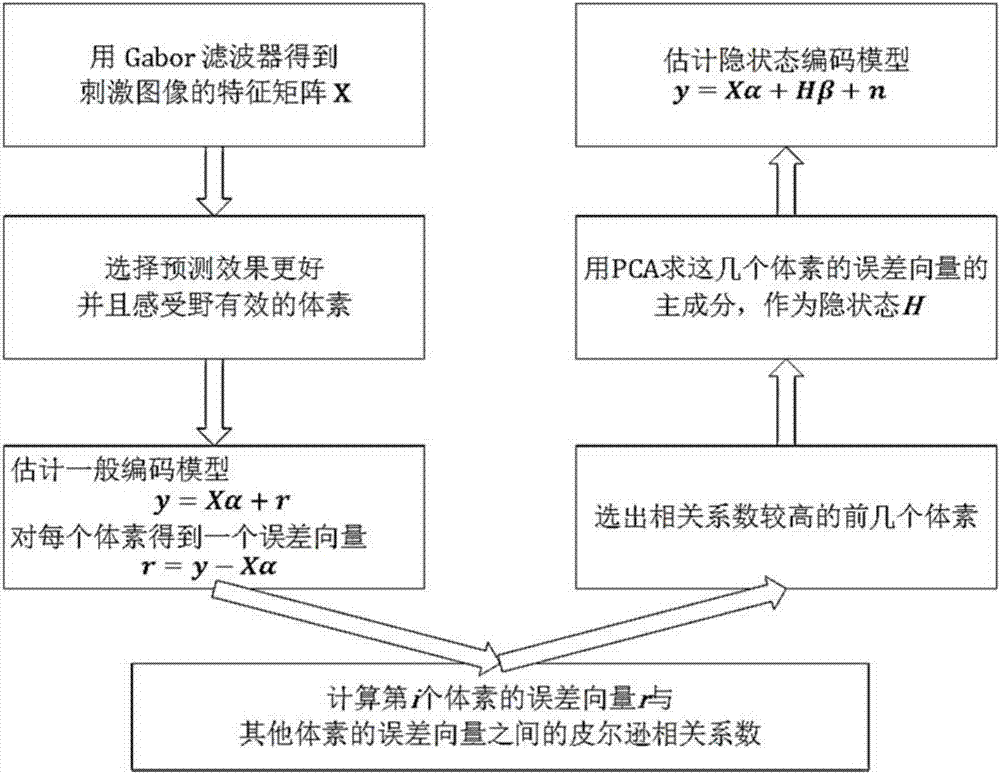
参见图2,隐状态解码模型的第一部分是隐状态编码模型,实施过程如下:
1、把刺激图像划分为网格状,在每个格点上,设计五个不同空间频率、八个不同方向、两个正交相位共80个gbaor滤波器,对图像进行滤波,得到特征矩阵x。单个体素对应每个特征矩阵x有一个响应强度,则有向量y=[y1,y2,…,yi,…yn]∈rn×1,其中,不同的元素表示该体素对不同的刺激图像的响应强度,一共有n幅图,x=[x1,x2,…,xi,…,xn]t∈r(n×(m+1)),其中,不同的元素表示不同刺激图像的特征矩阵。
2、用一般编码模型进行预估计,并通过对每一个体素估算使其感受野模型,挑选出预估计中预测效果较好且体素感受野有效的体素,进行下一步。
3、用最小二乘法估计一般编码模型y=xα+r,求出每个体素对应的误差向量r=y-xα。
4、对第i个体素,计算其误差向量与其他体素的误差向量之间的皮尔逊相关系数。
5、选择相关系数最高的几个体素,认为这几个体素对第i个体素的响应强度影响最大。
6、用pca求取这几个体素对应的误差向量的主成分,作为隐状态h。
7、估计隐状态编码模型y=xα+hβ+n。
参见图3,隐状态编码模型的第二部分是图像识别,具体过程如下:
1、向量v=[v1,v2,…,vi,…,vp]t∈r(p×1)表示对某一幅刺激图像测得的脑活动图,式中的不同元素表示不同体素对该图像的响应强度;向量v′=[v1′,v2′,…,vi′,…,vp′]t∈r(p×1)表示通过一般编码模型预测得出的脑活动图。
2、求二者之间的误差向量,e=v-ν′,e=[e1,e2,…,ei,…,ep]t∈r(p×1),式中不同元素表示不同体素的预测强度与真实强度之间的误差。
3、根据得到的第j,k,l个体素对第i个体素的影响最大,则选出第j,k,l个体素的误差值。
4、求hi=f(ej,ek,e1),其中函数f(·)是用pca学习出的线性变换。
5、用隐状态编码模型预测脑活动图,计算
6、对p个体素和n幅刺激图像重复这个过程,最终得到n个隐状态编码模型预测的脑活动图,每个活动图由n个预测的体素响应强度组成
7、将预测所得的n个脑活动图与测出的脑活动图一一做相关性分析,认为相关系数最大的那一个预测图所对应的刺激图像即为仪器检测时被试者所观看的图像。
图4为隐状态编码模型的单个体素响应强度预测误差对比统计,图中横线条纹柱形表示用一般编码模型预测的体素响应强度与真值之间的均方误差,竖线条纹柱形表示隐状态解码模型的预测误差。其中对被试者一的数据,前者是0.3453,后者是0.2522,对于被试者二的数据,前者是0.2269,后者是0.3115。综合表现来看,隐状态编码模型将预测误差减小了27%。
图5为模型识别准确率的对比统计,图中横线条纹柱形表示一般解码模型的识别准确率,竖线条纹柱形表示隐状态解码模型的识别准确率。对于被试者一的数据,前者的识别准确率是73%,后者的识别准确率是89%,对于被试者二的数据,前者的识别准确率是70%,后者的识别准确率是75%。对比可见,隐状态解码模型的识别准确率最大提升了25%。
- 还没有人留言评论。精彩留言会获得点赞!