一种基于集成支持向量机的P300拼写器的训练集扩展方法与流程
本发明涉及一种集成支持向量机的训练集扩展方法,具体为一种基于集成支持向量机的p300拼写器的训练集扩展方法。
背景技术:
脑机接口(braincomputerinterface,bci)是在人脑和计算机或其他电子设备之间建立不依赖与常规的大脑信息输出通路(外周神经和肌肉组织)的全新对外信息交流和控制的通信系统。脑机接口是一种新颖的人机接口系统,其研究具有重要意义:第一,可以为大脑功能健全但身体其他部分运动功能有障碍的人(如肌萎缩侧索硬化症患者)提供一种新的与外界交流的方式,随着脑机接口技术的发展,将会促进康复医学领域向更高的层次发展。第二,随着当前世界各国老龄化趋势的加剧,脑机接口技术将为老年人提供生活上的便利。第三,脑机接口技术的产生,为在高危环境下(如外太空等)工作的人们提供了一种新的控制设备的方式,提高了安全保障。另外,脑机接口技术的发展将会推动大脑认知模式以及大脑传递信息时脑区的活跃程度的研究,对进一步研究人类大脑提供了新的方法。
基于p300的拼写器脑机接口系统是目前应用最广泛的脑机接口系统之一。由于其对硬件的要求比较低,诱发的范式比较简单,电位的时域特征明显,并且被试在使用前无需进行大量的训练等优势获得了良好的效果,具有广阔的应用前景。由于脑电信号非常微弱,且非常容易受到外界环境的干扰,通常我们要将靶刺激叠加平均多次才能得到稳定的p300电位。经实验验证,在传统的p300拼写器脑机接口系统中,叠加15轮之后,字符识别的正确率仅有75%左右。字符传输率和字符识别率过低成为该脑机接口系统广泛应用于日常生活中的障碍。
kaufman等人在2011年发现人在观察一个熟悉人脸时在f3、f4电极位置记录到了一个明显的特征波形,被称为n400;金晶等人将这个发现运用到了基于p300的脑机接口刺激诱发范式上,将传统的p300脑机接口系统改为了基于名人熟悉人脸的p300拼写器脑机接口系统,即将字符的高亮变为了转换成熟悉人脸。经实验验证,该p300拼写器脑机接口系统的分类识别正确率在某些被试中高达91%,取得了较好的效果。
支持向量机作为脑机接口系统的分类算法已经被研究者广泛使用,它在解决非线性和高维模式识别问题中表现出许多特有的优势,并在很大程度上克服了“维数灾难”和“过学习”等问题。作为一种监督式学习算法,支持向量机需要大量样本进行训练才能保证系统的分类效果,这需要使用者在使用前花费很长时间来获取训练集样本。然而,长时间的脑电数据样本的获取将使使用者的情绪和身体状况等诸多因素发生变化,降低了脑电数据质量,影响了数据的可靠性,从而导致系统的分类性能下降。因此,通过扩展在较短时间内获得的训练集样本,满足支持向量机训练的要求是提高系统分类性能的有效手段之一。
技术实现要素:
本发明的目的在于提供一种基于集成支持向量机的p300拼写器脑机接口系统的训练集扩展方法,是针对集成支持向量机需要使用大量的训练集样本进行训练以确保分类性能的缺陷,提出了通过叠加平均不同两组脑电信号的方法扩展训练集的样本数量的方法。
本发明的目的可以通过以下技术方案实现:一种基于集成支持向量机的p300拼写器脑机接口系统训练集扩展方法,其特征在于具体包括以下步骤:
步骤一:使用基于名人熟悉人脸的p300拼写器脑机接口系统进行eeg脑电数据采集获取训练集样本;
步骤二:对训练集样本进行预处理,包括眼电伪迹去除、波形分段、基线校正、带通滤波;
步骤三:通过叠加平均不同两组eeg脑电数据的方法进行训练集样本数量的扩展;
1)假设p300拼写器脑机接口系统界面由m×n的字符矩阵构成(m列n行),设每列或行的一次闪烁为一个trial,所有列和行闪烁一次为一个sequence,即一个sequence包含m+n个trial;对应一个目标字符的输入,进行了q(q≥2)轮的sequence,被称为一个run;
2)假设
同理,假设
3)从q个sequence中选取两组,依次对m个列trial对应的
4)继续从q个sequence中选取两组,保证至少一组与之前选取的组合不重复。依次对m个列trial对应的
5)重复步骤4)直到完成
步骤四:对叠加平均后的eeg脑电数据进行降采样,将降采样后所有电极的eeg脑电数据按照固定的电极顺序进行排列形成特征向量;
步骤五:采用集成支持向量机算法对特征向量进行分类,得到系统正确输入字符的结果。
本发明的积极效果是
1.减小使用者的训练时间,从而保证数据的可靠性;
2.经过处理的波形特征更明显,有利于接下来的特征提取及分类识别;
3.增强脑机接口系统的实用性。
附图说明
图1基于名人熟悉人脸的p300拼写器脑机接口系统的数据处理流程图。
图2基于名人熟悉人脸的p300拼写器脑机接口系统的提示界面。
图3系统的电极使用配置图。
图4系统界面刺激提示的详细设计。
图5训练集扩展前后的系统识别正确率的对比图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细说明。
本发明针对集成支持向量机需要使用大量的训练集样本进行训练以确保分类性能的缺陷,提出了通过叠加平均不同两组脑电信号的方法扩展了训练集的样本数量的方法,并对该方法做了详细的数据验证分析。结果表明,一种基于集成支持向量机的p300拼写器的训练集扩展方法提高了分类正确率,其性能优于未扩展训练集的p300拼写器脑机接口系统。本发明缩短了训练集样本数据的获取时间,提高了脑电信号数据可靠性,增强了脑机接口系统的实用性。
如图1所示,本发明的基于集成支持向量机的p300拼写器的训练集扩展方法,具体包含以下步骤:
步骤1.本实施例使用基于名人熟悉人脸的p300拼写器脑机接口系统获取17名被试的脑电数据作为样本集。
如图2所示,该p300拼写器脑机接口系统的提示界面由36个字符(a-z,0-9)组成6×6的字符矩阵构成(6列6行)。
采用neuroscan公司生产的64通道synamps2脑电系统采集脑电数据,采样频率设置为256赫兹。记录了14个电极通道(fz、f3、f4、fc1、fc2、cz、c3、c4、pz、p3、p4、o1、o2和oz)的脑电数据,参考电极(ref)放置在左侧乳突的位置,接地电极(gnd)放置在右耳乳突的位置。脑电数据记录过程中,采用两对电极分别记录被试的水平眼电(veog)和垂直眼电(heog)。系统的电极使用配置如图3所示。
该p300拼写器脑机接口系统在运行过程中,字符矩阵以行(列)为单位随机的闪烁,闪烁的时间间隔为250毫秒,其中变亮的时间为200毫秒,后又转为灰色的时间为50毫秒。变亮的同时,在字符上面覆盖一张半透明的著名球星大卫·贝克汉姆的人脸(由于版权限制,文中展示出的是一名被试的人脸图片)。
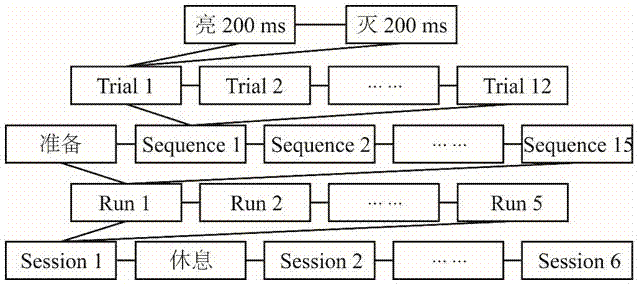
假设每列或行的一次闪烁为一个trial,所有列和行闪烁一次为一个sequence,即一个sequence包含12个trial(6列+6行)。为方便数据处理,6列依次被标记为1-6,6行依次被标记为7-12。对应一个目标字符的输入,进行了q=15轮的sequence,被称为一个run。数据采集过程中,标记每个trial的闪烁开始时刻。在本实施例中,要求被试输入6个单词:“clgdx”、“brain”、“short”、“float”、“break”、“while”。每个单词均由5个字符组成,故输入一个单词共需5个run,称为一个session。每个session之间允许被试休息2-5分钟。系统界面刺激提示的详细设计如图4所示。
步骤2.对样本集中的数据进行预处理,包括去除眼电、波形分段、基线校正、带通滤波。
采用回归分析算法进行眼电伪迹去除;以每个trial的闪烁开始时刻为零点,以-100毫秒—500毫秒为时间窗对脑电波形进行分段,记为eegp(p=1,2,…,m+n);对应一个目标字符,将获得(6+6)×15=180个eeg脑电数据。整个实施例中,共采集180个eeg脑电数据×5字符×6单词=5400个eeg脑电数据;以-100毫秒—0毫秒为基准对每个eeg脑电数据进行基线校正。然后以0.01-30赫兹进行带通滤波。
步骤3.通过叠加平均不同两组eeg脑电数据的方法进行样本集的数量扩展。
1)假设
同理,假设
2)从15个sequence中选取两组,依次对6个列trial对应的
3)继续从15个sequence中选取两组,保证至少一组与之前选取的组合不重复。依次对6个列trial对应的
4)重复步骤3)直到完成
本实施例中,取1个session作为训练集,其他5个session作为测试集。因此,训练集经过扩展之后,eeg脑电数据将从180×5=900扩展至1260×5=6300。
步骤4.对叠加平均后的eeg脑电数据进行降采样,将降采样后所有电极的eeg脑电数据按照固定的电极顺序进行排列形成特征向量。
针对每个电极通道,将每个eeg脑电数据的采样率从256赫兹降至64赫兹,即每隔4个点取一个点作为特征值,因此每个电极通道由采样点构成的特征向量长度由原来的128降到了32。然后将14个通道的特征向量按照f3、fz、f4、fc1、fc2、c3、cz、c4、p3、pz、p4、o1、oz、o2的顺序首尾相接,作为这个eeg脑电数据的特征向量,长度为32×14=448。
步骤五:采用集成支持向量机算法对特征向量进行分类,得到系统正确输入字符的结果。
在构建集成支持向量机时,为保证子支持向量机间的差异性,我们使用不同的训练集构建不同的子支持向量机,这些不同的子训练集均取自相同的样本集,本实施例中样本集即为扩展后的训练集。1个session的脑电数据用于训练,经过上述扩展方法进行扩展后,共有(6+6)×105×5=6300个eeg脑电数据。
采用bagging算法构建子训练集。该算法基于bootstrap,即随机且有放回的从扩展训练集中取出900个eeg脑电数据构成一组子训练集,这个过程重复k=7次,最后使用这些子训练集训练出k=7个子支持向量机,并对其进行集成。
5个session的脑电数据用于测试。假设eegim(i=1,2,…,15;m=1,2,…,6)是第i个sequence中第m列的eeg脑电数据,eegin(i=1,2,…,15;n=1,2,…,6)是第i个sequence中第n行的eeg脑电数据。vecim表示第i个sequence中eegim的特征向量,vecin表示第i个sequence中eegin的特征向量。将vecim和vecin放入第k(k=1,2,…,7)个子支持向量机中得到分类标签labimk和labink。如果第k个子支持向量机识别出eegim包含p300电位,则labimk=1;如果不包含p300电位,则labimk=-1,labink同理。
每个eeg数据将得到k=7个结果,采用加权投票算法整合k=7个分类结果。为每个子支持向量机计算一个权重系数,精度越高权重越高,使分类结果与权重相乘,得到该eeg数据的分数值。假设第k个子支持向量机的权重系数是wk,q(q=1,2,…,15)指用于分类的sequence数量,则第m列eeg数据的分数值为:
同理,第n行eeg数据的分数值为:
包含目标字符的列和行应该是分数值最高的列和行,所以最有可能的列为:
同样地,最有可能的行为:
根据columnq和rowq,即可确定目标字符。
为了消除时间相关性,提升实验结果的客观性,采用6折交叉验证计算分类正确率。假设gt(t=1,2,…,6)指该组的训练集是样本集中第t个session,a(gt)是第t组的分类准确率,那么p(p=17)个被试的平均准确率是
为了验证扩展训练集对分类的促进作用,分别计算了17名被试训练集扩展前后的系统识别正确率,如图5所示。
由分类结果可知,扩展训练集对p300拼写器脑机接口系统的性能有显著提升。经过训练集扩展后,叠加4个sequence即可达到85.5%的识别正确率,叠加11个sequence可达到100%的识别正确率。而未使用未扩展的训练集,叠加4个sequence才达到65.2%的识别正确率,叠加了全部的15个sequence才达到95.4%的识别正确率。这个结果证明了使用相同规模的样本集时,使用扩展训练集的系统性能比使用未扩展训练集的系统性能更显著,本发明对小训练集具有极大的优势。
- 还没有人留言评论。精彩留言会获得点赞!