一种多元时序数据的模式预测方法与流程
本发明属于计算机领域,特别涉及计算机中的数据挖掘领域,具体涉及一种多元时序数据的模式预测方法。
背景技术:
时序预测在天气预报,股票等领域是一个非常重要的研究方向。在时序预测中一个最重要的方法就是能够根据一些变量的趋势去预测其他变量的行为,这就叫做多元时序预测。例如,如果我们认为两个变量相关,那我们可能想知道例如在天气预报中温度增加了10%是否影响了湿度的趋势。
在多元预测中,我们可以将主要的一些方法分成数学和人工的方法。数学方法中如arima(autoregressiveintegratedmovingaveragemodel,将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型)或者指数平滑算法在处理真实世界中的非线性无规律数据时均不可靠。人工神经网络、支持向量机和k近邻都是一些应用于时间序列预测的机器学习方法。然而由于很多的时间变量会随着时间平移和伸缩,这些传统的方法就会失效。为了解决这个问题,一个解决方案就是考虑一个序列的行为而不是考虑一个变量值。例如一些方法在时间序列分析中进行模式预测。这些方法都假定一种对数据表示然后尽力去寻找最频繁的模式。然而,这些解决方案存在的主要问题是:这些方法中数据表示并没有降低数据维数尤其是高维数据,而且他们还必须去用例如聚类的方法处理数据导致时间复杂度提高;另外一个问题是他们的研究没有能力解释输出规则和关系,因此时间复杂度的减小和解释输出规则和关系需要得要有效的解决。
技术实现要素:
针对现有技术的缺陷和不足,本发明的目的是提供一种多元时序数据的模式预测方法,解决现有的数据处理方法时间复杂度高的问题。
为了实现上述目的,本发明采用如下技术方案予以实现:
一种多元时序数据的模式预测方法,包括以下步骤:
阶段一:对每一个条件变量及决策变量所形成的时间序列寻找候选兴趣模式集,分别对每个候选兴趣模式集进行聚类;
步骤1:寻找候选兴趣模式集;
步骤1.1:寻找可用初始子序列
对于时间序列s={s1,…,sl},从s1开始依次寻找斜率m1≠0的两个相邻时间序列值,将首次寻找到的两个相邻时间序列值作为初始子序列si={si,si+1},其中,i=1,2,…,l-1,l为时间序列的长度,斜率m1的计算公式为:
步骤1.2:计算相邻时间序列值的斜率
给可用初始子序列增加下一个si+2,计算si+2和si+1的斜率m2;
步骤1.3:获取兴趣模式
如果m2不等于m1,得到兴趣模式pα={si,si+1,si+2};
如果m2等于m1,继续步骤1.2,直到mk不等于m1为止,得到兴趣模式pα={si,si+1,…,si+k},其中,mk为si+k和si+k-1的斜率,k=1,2,…,l-2;
步骤1.4获取候选兴趣模式集
对于时间序列s={s1,…,sl},从兴趣模式pα的最后一个时间序列值开始,重复步骤1.1至步骤1.3,直到找到整个时间序列s={s1,…,sl}中所有的兴趣模式,形成候选兴趣模式集pc={p1,p2,…,pα,…,pβ,…,pn};
步骤2:候选兴趣模式集聚类;
步骤2.1:利用以下剪枝规则①和剪枝规则②给满足规则条件的模式距离值赋为无穷大;
剪枝规则①:如果候选兴趣模式集pc中的任意两个兴趣模式pα,pβ没有同时出现在区域宽度为ws的同一区域中,将距离矩阵d中的dαβ赋为无穷大;其中,ws是用户指定的参数,d为兴趣模式的距离矩阵,
dαβ=dαβ(pα,pβ),dαβ为pα和pβ的欧几里德距离;
剪枝规则②:如果兴趣模式pα的斜率为负,且兴趣模式pβ的斜率为正,将距离矩阵d中的dαβ赋为无穷大;
步骤2.2:计算距离矩阵中dαβ为非无穷大的元素的距离,并赋值到距离矩阵中相应的位置;
步骤2.3:比较dαβ(pα,pβ)和用户指定的dmin之间的大小,若dαβ≤dmin,从pc中删除pα和pβ两个兴趣模式中时间序列值的个数较小的兴趣模式,最终得到新的兴趣模式集p;
其中,dmin取相邻两个时间序列值之间的欧几里德距离最小值和最大值之间的某个值,具体由用户指定;
阶段二:产生预测规则
步骤3:用apriori算法计算关联规则
合并每个时间变量的兴趣模式集p得到pall,利用apriori算法对pall中的兴趣模式进行关联规则挖掘,获取不同时间变量间的多个关联规则;
步骤4:生成预测规则
①把m(pvm)=m(p′)=1的多个关联规则合并形成如下的预测规则:
a1≤v(pv1)≤b1,且a2≤v(pv2)≤b2,…,且aj≤v(pv)j≤bj,…,且aλ≤v(pvλ)≤b,则c1≤v(p′)≤c2,并且延迟δt1个单位时间;
其中,pvj是条件变量形成的兴趣模式,j=1,2,…,λ,λ≥1,λ为条件变量的个数,p′是决策变量形成的兴趣模式;
m(pvm)是sl和s1之间的斜率,m(pvm)=sgn(sl-s1),pvm是条件变量中对决策变量影响最大的兴趣模式,sl是pvm中最后一个时间序列值,s1是pvm中第一个时间序列值;m(p′)是s′l和s1′之间的斜率,s′l代表p′中最后一个时间序列值,s1′代表p′中第一个时间序列值;
aj和bj分别是m(pvm)=m(p′)=1的兴趣模式关联规则中v(pvj)的最小值和最大值,c1和c2分别是m(pvm)=m(p′)=1的兴趣模式关联规则中v(p′)的最小值和最大值,aj、bj、c1和c2均是正数;
v(pvj)是条件变量中兴趣模式pvj的变化量,v(p′)是决策变量中兴趣模式p′的变化量,
v(pvj)=(max(pvj)-min(pvj))×m(pvj)
v(p′)=(max(p′)-min(p′))×m(p′)
max(pvj)和min(pvj)分别表示兴趣模式pvj的最大时间序列值和最小时间序列值;
时延δt1=max(δ(rg)),δ(rg)=ipvm-ip′,ipvm是pvm的起始时间值,ip′是p′的起始时间值;
②把m(pvm)=m(p′)=-1的多个关联规则合并形成如下的预测规则:
e1≤v(pv1)≤f1,且e2≤v(pv2)≤f2,…,且ej≤v(pv)j≤f,j…,且eη≤v(pvη)≤fη,则g1≤v(p′)≤g2,并且延迟δt2个单位时间;
其中,ej和fj分别是m(pvm)=m(p′)=-1的兴趣模式关联规则中v(pj)的最小值和最大值,g1和g2分别是m(pvm)=m(p′)=-1的兴趣模式关联规则中v(p′)的最小值和最大值,j=1,2,…,η,η≥1,η为条件变量的个数;ej、fj、g1和g2均是负数,j为自然数;δt2=max(δ(rg));
阶段三:将待测数据的条件变量执行阶段一获得的兴趣模式去匹配阶段二的预测规则,若满足预测规则的前件,则输出决策变量的预测结果。
进一步的,所述的步骤2中候选兴趣模式集聚类方法可以用如下方法替换:
步骤2.1:利用r-tree构建候选模式集中的每个模式的mbr,形成模式的数据结构,得到模式的索引;
步骤2.2:对r-tree数据结构中的每个孩子节点i和j,利用以下剪枝规则1和规则2给满足规则条件的模式距离值赋为无穷大。
剪枝规则①:如果两个兴趣模式pα,pβ没有同时出现在区域宽度为ws的同一区域中,将距离矩阵中的dαβ赋为无穷大;其中,ws是用户指定的参数,d为兴趣模式的距离矩阵,
dαβ=dαβ(pα,pβ),dαβ为pα和pβ的欧几里德距离;
剪枝规则②:如果兴趣模式pα的斜率为负,且兴趣模式pβ的斜率为正,将距离矩阵d中的dαβ赋为无穷大;
步骤2.3:距离矩阵d中dαβ为非无穷大的元素按照欧几里德距离进行计算,并赋值到距离矩阵中相应的位置;
步骤2.4:比较dαβ(pα,pβ)和用户指定的dmin之间的大小,若dαβ≤dmin,从pc中删除pα和pβ两个兴趣模式中时间序列的个数较小的兴趣模式,最终得到新的兴趣模式集p;其中,dmin取相邻两个时间序列之间的欧几里德距离最小值和最大值之间的某个值,具体由用户指定。
与现有技术相比,本发明的有益效果是:本发明的多元时序数据的模式预测方法计算量小,有效的减小模式预测中的时间复杂度,解决了传统方法中时间复杂度过高的问题。
附图说明
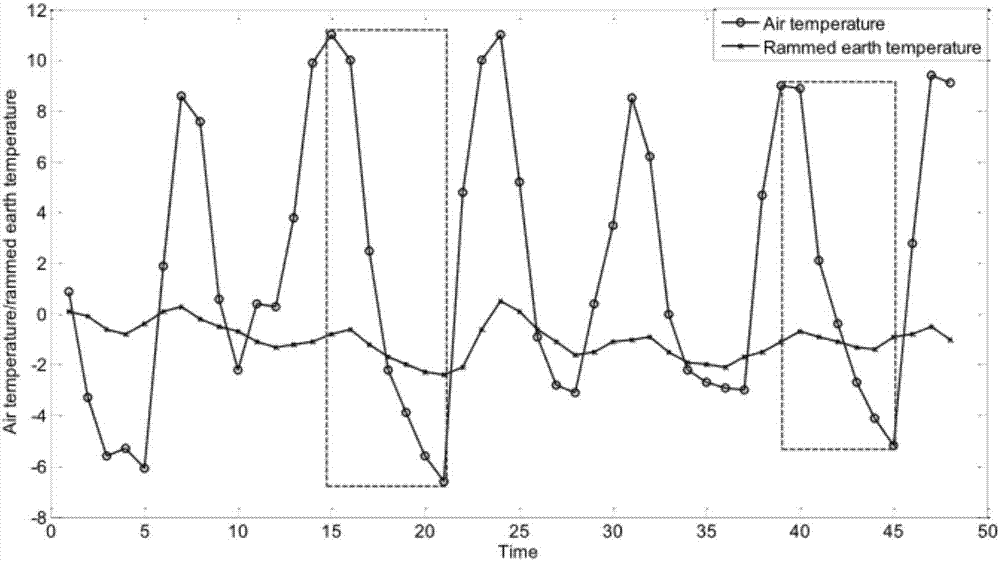
图1是空气温度和夯土温度的时序图。
图2是空气温度和夯土温度的变量关系图。
图3是模式间的mbr。
图4是本发明所提出的用于检索候选模式的基于r-tree的数据结构图。
图5是欧几里得距离测量的使用剪枝与未使用剪枝策略进行距离矩阵计算的性能与序列号图。
图6是使用剪枝规则的欧氏距离计算所用的时间和使用剪枝和r-tree进行距离矩阵计算的时间性能比较图。
图7是实施例中生成的六个规则的性能评价。
以下结合实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
本发明中的条件变量是能够用来预测其他变量的变量,决策变量就是可以被其他变量预测的变量。
本发明的方法过程分为三个阶段:
阶段一:对每一个条件变量及决策变量所形成的时间序列寻找候选兴趣模式集,分别对每个候选兴趣模式集进行聚类;阶段二:产生预测规则;阶段三:根据阶段二生成的预测规则对待测数据进行预测。
其中阶段一和阶段二是训练阶段,将已有的数据执行阶段一和阶段二后得到预测规则,阶段三是针对待测量的数据,将待测量数据经历阶段一后获得的兴趣模式去匹配阶段二中的预测规则,若满足预测规则的前件,则输出决策变量的预测结果。
在阶段一中:寻找兴趣模式,并总结数据的行为,对于数据的变化,寻找斜率为正和斜率为负的模式。由于序列数据可能包含重复的模式,该算法对这些模式进行聚类和分组,具体为:
步骤1:寻找候选兴趣模式集
步骤1.1:寻找可用初始子序列
对于时间序列s={s1,…,sl},从s1开始依次寻找斜率m1不为0的两个相邻时间序列值,将首次寻找到的两个相邻时间序列值作为初始子序列si={si,si+1},其中,i=1,2,…,l-1,l为时间序列的长度,
步骤1.2:计算相邻时间序列值的斜率
给可用初始子序列增加下一个si+2,计算si+2和si+1的斜率m2;
步骤1.3:获取兴趣模式
如果m2不等于m1,得到兴趣模式pα={si,si+1,si+2};
如果m2等于m1,继续步骤1.2,直到mk不等于m1为止,得到兴趣模式pα={si,si+1,…,si+k},其中,mk为si+k和si+k-1的斜率,k=1,2,…,l-2;
步骤1.4获取候选兴趣模式集
对于时间序列s={s1,…,sl},从兴趣模式pα的最后一个时间序列值(即si+k)开始,重复步骤1.1至步骤1.3,直到找到整个时间序列s={s1,…,sl}的n个兴趣模式,形成候选兴趣模式集pc={p1,p2,…,pα,…,pβ,…,pn};
步骤2:候选兴趣模式集聚类;
在候选模式集中将相似模式分组,寻找相似模式的第一步是在模式之间生成一个距离矩阵。对于每一对模式,一个距离矩阵的元素显示了两个模式的距离。然而传统的算法的时间消耗太大,为了解决这个问题,本发明中提出了两种方法:一种为剪枝规则,另一种为r-tree结合剪枝规则。
对于剪枝规则,具体如下:
步骤2.1:利用以下剪枝规则①和剪枝规则②给满足规则条件的模式距离值赋为无穷大;
剪枝规则①:如果候选兴趣模式集pc中的任意两个兴趣模式pα,pβ没有同时出现在区域宽度为ws的同一区域中,那么这两个模式的距离为无穷大,将距离矩阵d中的dαβ赋为无穷大;其中,ws是用户指定的参数,d为兴趣模式的距离矩阵,
dαβ=dαβ(pα,pβ),dαβ为pα和pβ的欧几里德距离;
剪枝规则②:使用模式的斜率来进行剪枝,如果兴趣模式pα的斜率为负,且兴趣模式pβ的斜率为正,则它们不能被认为是相似的,将距离矩阵d中的dαβ填充为无穷大;
步骤2.2:计算距离矩阵中dαβ为非无穷大的元素之间的欧几里德距离,并赋值到距离矩阵中相应的位置。
步骤2.3:比较dαβ(pα,pβ)和用户指定的dmin之间的大小,若dαβ≤dmin,从pc中删除pα和pβ两个兴趣模式中时间序列值的个数较小的兴趣模式,最终得到新的兴趣模式集p;其中,dmin取相邻两个时间序列值之间的欧几里德距离最小值和最大值之间的某个值,时间序列值具体由用户指定。
对于r-tree结合剪枝规则,r-tree用来索引候选模式集pc,如图4所示,p1-p9为候选模式,r树结构中每一个树的叶结点为一个候选模式的mbr。具体如下:
步骤2.1:利用r-tree构建候选模式集中的每个模式的mbr,形成模式的数据结构,得到模式的索引;其中每一个叶子节点是一个模式的mbr,r-tree的中间项用附近的mbr来索引模式。这个数据结构通过减少处理的模式的数量将被用来减少算法的时间复杂度。图3说明了模式p1和模式p2间的mbr。
步骤2.2:对r-tree数据结构中的每个孩子节点i和j,利用以下剪枝规则1和规则2给满足规则条件的模式距离值赋为无穷大。
剪枝规则①:如果候选兴趣模式集pc中的任意两个兴趣模式pα,pβ没有同时出现在区域宽度为ws的同一区域中,那么这两个模式的距离为无穷大,将距离矩阵d中的dαβ赋为无穷大;其中,ws是用户指定的参数,d为兴趣模式的距离矩阵,
dαβ=dαβ(pα,pβ),dαβ为pα和pβ的欧几里德距离;
剪枝规则②:使用模式的斜率来进行剪枝,如果兴趣模式pα的斜率为负,且兴趣模式pβ的斜率为正,则它们不能被认为是相似的,将距离矩阵d中的dαβ填充为无穷大;
步骤2.3:计算距离矩阵中dαβ为非无穷大的元素之间的欧几里德距离,并赋值到距离矩阵中相应的位置。
步骤2.4:比较dαβ(pα,pβ)和用户指定的dmin之间的大小,若dαβ≤dmin,从pc中删除pα和pβ两个兴趣模式中时间序列值的个数较小的兴趣模式,最终得到新的兴趣模式集p;其中,dmin取相邻两个时间序列值之间的欧几里德距离最小值和最大值之间的某个值,具体由用户指定。
阶段二:产生预测规则
步骤3:用apriori算法计算关联规则
合并每个时间变量的兴趣模式集p成pall,利用apriori算法对pall中的兴趣模式进行关联规则挖掘,获取不同时间变量间兴趣模式的关联规则:
其中,g=1,2,…,r,pvj是条件变量形成的兴趣模式,p′是决策变量形成的兴趣模式;
按照如下的公式计算关联规则rg的方向、时延和变化量:
关联规则的方向计算公式:
其中,m(pvm)是sl和s1之间的斜率,m(pvm)=sgn(sl-s1),pvm是条件变量中对决策变量影响最大的兴趣模式,sl代表pvm中最后一个时间序列值,s1代表pvm中第一个时间序列值;m(p′)是s′l和s′之间的斜率,s′l代表p′中最后一个时间序列值,s′代表p′中第一个时间序列值;
时延的计算公式:
δt1=max(δ(rg)),δ(rg)=ipvm-ip′(4)
其中,ipvm是pvm的起始时间值,ip′是p′的起始时间值;
规则的变化量:
v(pvj)=(max(pvj)-min(pvj))×m(pvj)
v(p′)=(max(p′)-min(p′))×m(p′)(5)
其中,v(pvj)是条件变量中兴趣模式pvj的变化量,v(p′)是决策变量中兴趣模式p′的变化量,max(pvj)和min(pvj)分别表示兴趣模式pvj的最大时间序列值和最小时间序列值。
步骤4:生成预测规则
①把m(pvm)=m(p′)=1的多个关联规则合并形成如下的预测规则:
a1≤v(pv1)≤b1,且a2≤v(pv2)≤b2,…,且aj≤v(pv)j≤bj,…,且aλ≤v(pvλ)≤b,则c1≤v(p′)≤c2,并且延迟δt1个单位时间;
其中,aj和bj分别是m(pvm)=m(p′)=1的兴趣模式关联规则rg中v(pvj)的最小值和最大值,c1和c2分别是m(pvm)=m(p′)=1的兴趣模式关联规则rg中v(p′)的最小值和最大值,j=1,2,…,λ,λ≥1,λ为条件变量的个数,aj、bj、c1和c2均是正数。
②把m(pvm)=m(p′)=-1的多个关联规则合并形成如下的预测规则:
e1≤v(pv1)≤f1,且e2≤v(pv2)≤f2,…,且ej≤v(pv)j≤f,j…,且eη≤v(pvη)≤fη,则g1≤v(p′)≤g2,并且延迟δt2个单位时间;
其中,ej和fj分别是m(pvm)=m(p′)=-1的兴趣模式关联规则中v(pj)的最小值和最大值,g1和g2分别是m(pvm)=m(p′)=-1的兴趣模式关联规则中v(p′)的最小值和最大值,ej、fj、g1和g2均是负数,j=1,2,…,η,η≥1,η为条件变量的个数;δt2=max(δ(rg)),δ(rg)=ipvm-ip′,ipvm是pvm的起始时间值,ip′是p′的起始时间值;
本发明使用命中率h用于说明本发明算法的性能,h定义为:
其中,n为条件变量中准确匹配预测规则的兴趣模式的数目,m为条件变量中兴趣模式的总数目。
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
实施例1
本实施例给出将本发明算法用于预测明长城遗址的土体温度,其中,图1和图2分别为明长城遗址空气温度和夯土温度的时序图及其变量关系图,将该时序数据通过上述三个阶段的处理,其中,本实施例在阶段一中只使用了剪枝规则候选兴趣模式集聚类,其结果如图5,其中,naive曲线表示的是既不使用剪枝规则也不使用r-tree数据结构的聚类结果,pruning-based曲线表示使用剪枝规则的聚类结果,从图中可以看出,随着时间序列数量的增加,未使用剪枝规则的欧氏距离计算所用的时间程指数增长,而使用了剪枝规则进行距离计算的时间增长缓慢。
实施例2
本实施例与实施例1的区别点在于:本实施例在阶段一中使用了r-tree的数据结构结合剪枝规则候选兴趣模式集聚类,这个数据结构通过减少处理的模式的数量将被用来减少算法的时间复杂度,如图6所示。横轴是时间序列的数量,可以看到随着时间序列数量的增加,使用剪枝规则结合r-tree进行距离矩阵计算的时间比仅使用剪枝规则进行距离矩阵计算的时间增长缓慢。在空气温度的时序图中,p1和p2为本发明算法识别的候选模式集,可以构建两个模式间的mbr,图3所示为模式p1和模式p2之间的mbr。
表1为本实施例生成的六个具体的预测规则,
表1预测规则
图7是本实施例根据上述六个预测规则的预测结果,图中横轴为监测区域,纵轴为命中率。图7中展示了生成的六个预测规则在区域1,2,3,4,5中进行预测的命中率h的对比结果,其中规则3的平均命中率最高。
- 还没有人留言评论。精彩留言会获得点赞!