一种设定水泥烧成系统最佳运行点的方法与流程
本发明属于水泥生产过程中的能耗控制领域,具体的说是一种利用多元自适应回归样条法建立能耗模型,然后基于目标规划法求解能耗最低工作点的设定水泥烧成系统最佳运行点的方法。
背景技术:
水泥熟料烧成属于高耗能,高排放,高污染行业,对该过程中的能耗控制无论从经济角度还是环保角度都至关重要。水泥熟料烧成系统是很庞大的生产线,各个运行点的参数都有可调空间,传统的调节方法是根据工人的经验来调节,即只要在工艺允许范围内即可,所以导致相同的产量煤耗有高有低,废气排放量也不相同。
技术实现要素:
本发明提供了一种设定水泥烧成系统最佳运行点的方法,该方法求解的稳态运行点可以使系统运行在煤耗最小的工况下,具有较高的经济价值,克服了传统调节方法的上述不足。
本发明技术方案结合附图说明如下:
一种设定水泥烧成系统最佳运行点的方法,该方法包括以下步骤:
步骤一、确定模型输入变量和输出变量;
步骤二、采集数据;
步骤三、使用多元自适应回归样条算法进行建模;
步骤四、对模型做光滑处理;
步骤五、构建目标函数;
步骤六、求解目标函数。
步骤一中所述的输入变量为生料流量,预热器出口废气量,预热器出口温度,冷却机出口废气量,冷却机出口气体温度,冷却机出口熟料温度,平均温差;输出变量为煤耗。
所述的步骤二的具体方法为:
从水泥厂dcs系统中获取步骤一中输入输出变量的稳态数据,即30分钟内,最大变化不超过平均值的2%的数据,取240组数据,200组数据作为建模,40组数据作为测试用模型的预测能力。
所述的步骤三的具体方法为:
多元自适应回归样条即mars是由friedman引入的一种回归分析形式,它是一种非参数回归技术,可以看作模拟变量之间的非线性和相互作用的线性模型的扩展,mars模型的一般形式:
式中:
mars的目的是寻找基函数集
mars不会在每个样本点出放置基函数,为了避免节点过于靠近,引入最小步长
n为样本个数,它的建模过程分为前向逐步和后向剪枝,前向过程是一个迭代过程,模型首先生成初始基函数迭代次数i=0,即
b0(x)=1
每次迭代(i>1),mars遍历所有节点,成对地添加新的来减小训练误差最多的镜像基函数,直到基函数个数达到最大个数或者模型精度满足要求
b2i-1(x)=bl(x)b(xv,t)
b2i(x)=bl(x)b(-xv,t)
其中bl(x)是在之前的迭代中生成的基函数,称作父基函数,这种迭代过程会产生大量的基函数,造成模型的过拟合,后向剪枝过程每次循环删除一个对训练误差减小量为最小的基函数,得到对应子模型,直到模型只剩下截距项,引入一般交叉验证gcv准则
c(m)=trace(b(btb)-1bt)+1+dm
式中,m是基函数个数,n为输入变量个数,(k-1)/2为扭结点的个数,trace(b(btb)-1bt)+1为模型有效系数个数,b是m×n的矩阵,d为惩罚因子,一般设为2到4之间,最终选取gcv值最小的子模型作为最优模型,可以看出过多的基函数与扭结点会受到惩罚,从而减小模型的体积,避免过拟合。
所述的步骤四的具体方法为:
由于基函数一般为铰链函数,最终模型是铰链函数的集合,模型在转折点处没有导函数,进一步的求解算法要求模型处处可导,所以要对模型做光滑处理,即在不影响模型精确度的情况下,是模型在变量空间内处处可导,
处理方法:将铰链函数替换成其立方截断形式,
对于铰链函数b(x|s,t)=s(x-t),s=±1,其截断立方形式为:
其中
t-,t,t+,分别表示该节点与其左侧节点的中点位置,节点位置,该节点与其右侧节点的中点位置。
所述的步骤五的具体方法为:
由步骤四求得能耗模型:
y=f(x1,x2,x3,x4,x5,x6,x7)(1)
y指煤耗,x1—x7分别指生料流量,预热器出口废气量,预热器出口温度,冷却机出口废气量,冷却机出口气体温度,冷却机出口熟料温度,平均温差;
其工艺参数:
生料流量根据生产计划而定x1min≤x1≤x1max(2)
预热器出口废气量会影响o2,co含量,x2min≤x2≤x2max(3)
预热器出口温x3min≤x3≤x3max(4)
冷却机出口废气量设为获取数据的最大值与最小值之间x4min≤x4≤x4max(5)
冷却机出口气体温度也设为获取数据的最大值与最小值之间x5min≤x5≤x5max(6)
出冷却机熟料温度x6min≤x6≤x6max(7)
筒体表面平均温差为表面温度减去环境温度x7min≤x7≤x7max(8)
式(1)-式(8)共同构成水泥数量烧成过程约束条件,认为满足这些条件的x=[x1,x2,x3,x4,x5,x6,x7]t即是满足工艺要求,又可以稳定运行的工作点;
经过步骤三,四得出的稳态模型,结合约束条件共同构成如下方程组:
目标函数:
即
即最小单位生料耗煤量。
所述的步骤六的具体方法为:
求解目标函数问题转化为求多元函数求最小值的问题,
目标函数的最小值只能出现在边界或者极值点上,所以将待求点分为两类,一类是内部极值点,另一类是边界点;
1.内部极值点
对于xt=[x1t,x2t,x3t,x4t,x5t,x6t,x7t]t为l(x1,x2,x3,x4,x5,x6,x7)极值点的必要条件:
lx1'(xt)=0,lx2'(xt)=0,lx3'(xt)=0,lx4'(xt)=0,lx5'(xt)=0,lx6'(xt)=0,lx7'(xt)=0;即求出满足上式的点,极值点必然存在其中。
2.边界值
对于7个输入变量,只要存在一个变量处于边界即归为边界点,每一个变量都有上下两个边界,所以共有
3.综合
目标函数解:[x1,x2,x3,x4,x5,x6,x7]t=xf,l(xf)=min(l(x1),l(x2)...l(xf)..l(xn));经过上述步骤,目标函数的解即可作为系统能耗最小的运行点。
本发明的有益效果为:
1、本发明从生产线运行数据入手建立模型,符合实际情况。
2、本发明采用数据挖掘的方式,避免了费时费力的热工标定过程。
3、本发明系统运行在经过本发明设定的工况,能在一定程度上减少煤炭的消耗量,和废气排放量,很大的经济和环保有效益。
附图说明
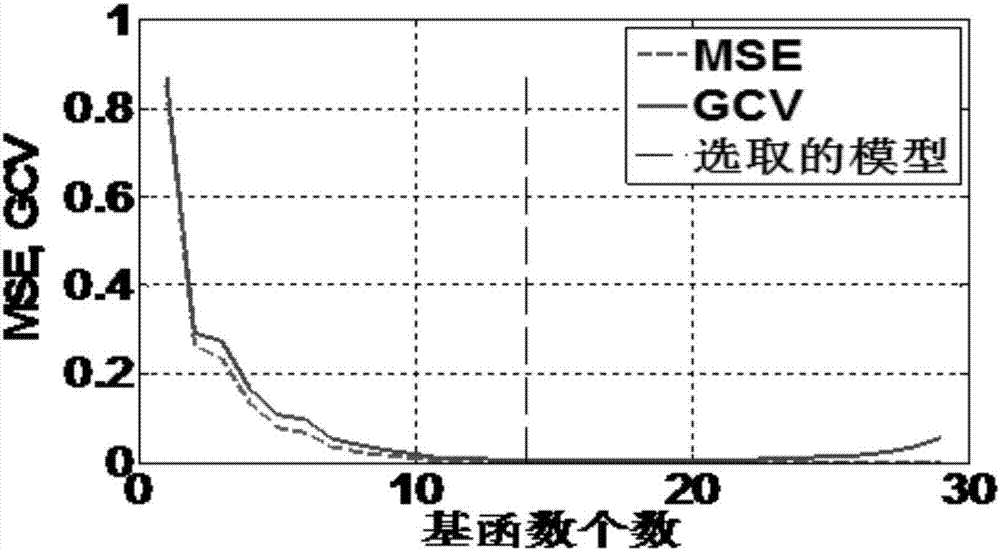
图1为多元自适应回归样条建模示意图;
图2为建模过程误差和模型复杂度变化示意图;
图3为铰链函数示意图;
图4a为光滑处理后效果示意图;
图4b为光滑处理前效果示意图;
图5为本发明流程图;
图6a为本发明中200个训练样本的拟合效果图
图6b为本发明中40个样本的预测效果图。
具体实施方式
参阅图5,一种多元自适应回归样条和目标规划方法设定水泥熟料烧成过程最佳运行点的方法,该方法包括如下步骤:
步骤一、确定模型输入变量和输出变量;
根据热平衡确定能耗的影响因素,通过分解炉内部燃烧机理,结合现场工作人员的经验总结,可以得出影响煤炭消耗的主要因素有生料流量,预热器出口废气量,预热器出口温度,冷却机出口废气量,冷却机出口气体温度,冷却机出口熟料温度,平均温差;
(1)生料流量的影响
水泥生料在烧成系统中会发生复杂的物理化学反应,有吸热和放热过程,是煤耗的主要因素。
(2)预热器出口废气量
新型干法水泥采用悬浮预热技术,预热器出口指五级旋风筒的出口,出口气体过少会使得悬浮不均匀,消耗热量增加,出口气体过量,会导致热量流失增加。
(3)预热器出口温度
预热器出口温度衡量热量损失程度。
(4)冷却机出口废气量
冷却机出口废气也是系统热量散失的一大来源。
(5)冷却机出口气体温度
冷却机出口温度衡量冷却机的热量回收效果。
(6)冷却机出口熟料温度
冷却机出口熟料温度衡量冷却机的热量回收效果。
(7)平均温差
平均温差是指回转窑表面多个温度测试点测试的温度,水泥熟料烧成系统中回转窑长度较长,是一个不能忽略的热量损失点。
步骤二、采集数据;
从水泥厂dcs系统中获取上述输入输出变量的稳态数据,取100组数据,80组数据作为建模。实际的生产线是一个稳态-过度-稳态的过程,因为本发明是设定稳态运行点,所以要采集稳态数据建模,实际生产中绝对的稳态是不存在的,所以认为10分钟内,最大变化不超过平均值的2%的数据即为稳态数据。
步骤三、使用多元自适应回归样条算法进行建模;
将采集的数据处理成,算法接口规定的数据格式,设定算法参数,主要是变量交互程度,对模型复杂度的惩罚度,输入算法程序,建模。
多元自适应回归样条即mars是由friedman引入的一种回归分析形式,它是一种非参数回归技术,可以看作模拟变量之间的非线性和相互作用的线性模型的扩展,mars模型的一般形式:
式中:
mars的目的是寻找基函数集
mars不会在每个样本点出放置基函数,为了避免节点过于靠近,引入最小步长
n为样本个数,它的建模过程分为前向逐步和后向剪枝,前向过程是一个迭代过程,模型首先生成初始基函数迭代次数i=0,即
b0(x)=1
每次迭代(i>1),mars遍历所有节点,成对地添加新的来减小训练误差最多的镜像基函数,直到基函数个数达到最大个数或者模型精度满足要求
b2i-1(x)=bl(x)b(xv,t)
b2i(x)=bl(x)b(-xv,t)
其中bl(x)是在之前的迭代中生成的基函数,称作父基函数,这种迭代过程会产生大量的基函数,造成模型的过拟合,后向剪枝过程每次循环删除一个对训练误差减小量为最小的基函数,得到对应子模型,直到模型只剩下截距项,引入一般交叉验证gcv准则
c(m)=trace(b(btb)-1bt)+1+dm
式中,m是基函数个数,n为输入变量个数,(k-1)/2为扭结点的个数,trace(b(btb)-1bt)+1为模型有效系数个数,b是m×n的矩阵,d为惩罚因子,一般设为2到4之间,最终选取gcv值最小的子模型作为最优模型,可以看出过多的基函数与扭结点会受到惩罚,从而减小模型的体积,避免过拟合。将mars算法应用与步骤和步骤二选取的变量,得到以输入计算输出的模型,如图1所示。图2为模型建立过程随着基函数的添加,模型误差越来越小。
步骤四、对模型做光滑处理;
因为步骤三建立的模型在节点处不可导,不能直接步骤三建立模型不能直接用于计算最佳运行点,所以要进行光滑处理,即在不影响模型精度的情况下,是模型处处可偏导。采用的方法是用立方截断形式代替基函数。
由于基函数一般为铰链函数,参阅图3,最终模型是铰链函数的集合,模型在转折点处没有导函数,进一步的求解算法要求模型处处可导,所以要对模型做光滑处理,即在不影响模型精确度的情况下,是模型在变量空间内处处可导,
处理方法:将铰链函数替换成其立方截断形式,
对于铰链函数b(x|s,t)=s(x-t),s=±1,其截断立方形式为:
其中
t-,t,t+,分别表示该节点与其左侧节点的中点位置,节点位置,该节点与其右侧节点的中点位置。图4a、4b可以看出此光滑处理的效果。处理过的模型在变量空间内具有一阶连续偏导数,最高含有变量的三次方项。
步骤五、构建目标函数;
由步骤四求得能耗模型:
y=f(x1,x2,x3,x4,x5,x6,x7)(1)
y指煤耗,x1—x7分别指生料流量,预热器出口废气量,预热器出口温度,冷却机出口废气量,冷却机出口气体温度,冷却机出口熟料温度,平均温差;
以2000t/d水泥熟料生产线为例,其工艺参数:
生料流量根据生产计划而定x1min≤x1≤x1max(2)
预热器出口废气量会影响o2:co含量,co含量,o2:2%-3%,co<0.2%
x2min≤x2≤x2max(3)
预热器出口温:310℃-350℃,x3min≤x3≤x3max(4)
冷却机出口废气量设为获取数据的最大值与最小值之间x4min≤x4≤x4max(5)
冷却机出口气体温度也设为获取数据的最大值与最小值之间x5min≤x5≤x5max(6)
出冷却机熟料温度80℃-105℃x6min≤x6≤x6max(7)
筒体表面平均温度300℃-350℃,温差为其减去环境温度x7min≤x7≤x7max(8)
式(1)-式(8)共同构成水泥数量烧成过程约束条件,认为满足这些条件的x=[x1,x2,x3,x4,x5,x6,x7]t即是满足工艺要求,又可以稳定运行的工作点;
经过步骤三,四得出的稳态模型,结合约束条件共同构成如下方程组:
目标函数:
即
即最小单位生料耗煤量。
步骤六、求解目标函数。
求解目标函数问题转化为求多元函数求最小值的问题,
目标函数的最小值只能出现在边界或者极值点上,所以将待求点分为两类,一类是内部极值点,另一类是边界点;
4.内部极值点
对于xt=[x1t,x2t,x3t,x4t,x5t,x6t,x7t]t为l(x1,x2,x3,x4,x5,x6,x7)极值点的必要条件:
lx1'(xt)=0,lx2'(xt)=0,lx3'(xt)=0,lx4'(xt)=0,lx5'(xt)=0,lx6'(xt)=0,lx7'(xt)=0;即求出满足上式的点,极值点必然存在其中。
5.边界值
对于7个输入变量,只要存在一个变量处于边界即归为边界点,每一个变量都有上下两个边界,所以共有
6.综合
目标函数解:[x1,x2,x3,x4,x5,x6,x7]t=xf,l(xf)=min(l(x1),l(x2)...l(xf)..l(xn));经过上述步骤,目标函数的解即可作为系统能耗最小的运行点。
实施例
1.经由步骤一和步骤二选取了240组稳态数据,200组用于建模,40组用于测试
2.经由步骤三,步骤四建立了mars煤耗模型,并对模型做光滑处理。
模型公式:
y=17.18719+0.3163841*bf1+0.2725098*bf2+0.02066081*bf3
-0.09776752*bf4+0.05692726*bf5-0.09460275*bf6
+0.05146817*bf7+0.3095877*bf8+0.03062948*bf9
+0.2200285*bf10-0.1723237*bf11+0.4182119*bf12
-0.8993806*bf13
其中:bf1=c(x2|+1,1.427231,2.749509,3.133633);bf2=c(x5|+1,1.435401,2.870499,3.37111);
bf3=c(x3|+1,1.716174,3.309962,4.780396);bf4=c(x3|-1,1.716174,3.309962,4.780396);
bf5=c(x6|+1,0.8723287,1.722137,3.862424);bf6=c(x6|-1,0.8723287,1.722137,3.862424);
bf7=c(x7|+1,0.6459411,1.092902,3.660228);bf8=c(x2|-1,3.133633,3.517757,4.854848);
bf9=c(x4|+1,0.7307734,1.461101,3.864771);bf10=c(x5|-1,3.37111,3.87172,5.032277);
bf11=c(x1|+1,2.544589,4.197969,5.239564);bf12=c(x1|+1,0.452856,0.8912096,2.54458);
bf13=c(x1|-1,0.452856,0.8912096,2.54458).
模型拟合曲线见附图6a、6b。
3.经由步骤五步骤,构建了约束方程组和目标函数:
目标函数:
即
7.经由步骤六求解目标函数:
所求解内部极值点xt,
对比样本数据
系统运行在所求极值点煤耗比采集到的最小能耗点还要低2.3%。每吨生料至少节省煤炭1.7kg。按孰料生料比1.5计算,2000t的生产线每天至少节煤2.27t,有很可观的经济效益。
综上所述,本发明提出基于生产数据建立数学模型,进而求解水泥熟料烧成系统最佳工作点的方法,此方法避免了费时费力的热工标定过程,并且从实际数据出发,比从机理建模更加符合实际情况,较之依靠经验定性的调节方式,多了定量的准确性。本发明可以用于设定水泥熟料烧成系统运行点,能减小煤炭消耗,带来经济效益,也能减少废气排放,带来环保效益。
- 还没有人留言评论。精彩留言会获得点赞!