一种基于虚拟角色的数据处理方法及系统与流程
本发明涉及图像识别领域和计算机动画领域,特别是涉及一种基于虚拟角色的数据处理方法及系统。
背景技术:
如今,在视听通信设备上进行视频播放已经十分普遍,视频中的交流对象往往是用户的真实形象,随着人脸采集技术和建模技术的不断发展,人脸采集技术和建模技术常常应用在动画、影视、游戏等许多重要的领域,尤其是需要人机互动的娱乐游戏领域、虚拟直播领域、3d动画领域。虚拟角色的动画包括肢体动画和表情动画两部分,为了实现虚拟角色的逼真效果,单纯的肢体动画已经无法满足用户的需求,逼真的表情动画是提升用户使用体验的重要因素。例如将真人直播可以替换为卡通人物、动物、名人进行直播,两个陌生人之间也可以各自选择不同的虚拟形象进行视频聊天等等。
要实现上述目标,我们需要现实世界中的真人的面部表情和动作,来控制虚拟世界中虚拟角色的面部表情和动作,现有技术中虽然能够将采集的真实人脸的面部动作转移到虚拟角色上进行演示,但是并不能在根据用户需要的特殊虚拟角色上演示,例如像长颈鹿这样与人脸特征相差较大的虚拟角色。而且,现有技术中不能解决由于光线干扰、网络状况较差等环境因素造成的造成识别不准、识别错误或识别失败的问题,从而引起不能正常获取表情包,造成虚拟角色控制不稳定的问题。
技术实现要素:
本发明提供了一种基于虚拟角色的数据处理方法及系统,其目的是一方面实现将实时人脸的面部动作转移到用户选择的任何虚拟角色上进行流畅演示;另一方面能够当识别出现故障时,把角色的动作稳定控制在一个区间内,使得虚拟角色演示更加生动自然。
本发明提供的技术方案如下:
本发明提供一种基于虚拟角色的数据处理方法,包括步骤:s100获取表演者的面部表情图像信息;s200转换所述面部表情图像信息为角色表情数据;s300根据数据插值算法,处理所述角色表情数据,得到虚拟角色的虚拟表情数据。
本发明中,可以将人脸的面部动作,转移到用户选择的任何虚拟角色上进行演示,能够实时地通过该虚拟角色反应出表演者当前的面部表情变化,虚拟角色创建更加生动形象,增加趣味性,提升用户的使用体验,并且能够在识别出现故障时,把角色的动作稳定控制在一个区间内,使得虚拟角色演示更加生动自然。
进一步的,所述步骤s300之后还包括步骤:s310判断所述表演者的虚拟角色是否完成初始化;若是,执行步骤s330,否则,执行步骤s320;s320根据初始化数据对所述虚拟角色进行初始化;s330判断当前时刻是否在预设接收时长内接收到角色表情数据;若是,执行步骤s340,否则,执行步骤s350;s340将当前时刻的角色表情数据与上一时刻的角色表情数据进行插值运算,得到所述虚拟角色的第一虚拟表情数据;s350将所述上一时刻的角色表情数据与所述初始化数据进行插值运算,得到所述虚拟角色的第二虚拟表情数据。
本发明中,能够在识别丢失、识别错误时,平滑过渡处理使得角色的动作稳定控制在一个区间内,使得后期虚拟角色的演示更加自然生动,避免因为录制设备自身的精度等原因出现抖动等不自然的现象,提升用户的使用体验。
进一步的,所述步骤s200包括步骤:s210根据所述表演者的面部表情图像信息,识别当前时刻的面部表情信息,得到面部特征点和面部特征点的当前空间坐标值;s220将所述面部特征点的当前空间坐标值和与相应的初始空间坐标进行运算,得到位移差值;s230将所述位移差值与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;s240将所述当前时刻的表情参数按照预设转换方式进行转换,得到所述角色表情数据;其中,所述面部特征点包括眼睛、眼球、眉毛、鼻子、嘴巴、耳朵和颈骨。
本发明中,可以将人脸的面部动作,转移到用户选择的任何虚拟角色上进行演示,能够实时地通过该虚拟角色反应出表演者当前的面部表情变化,虚拟角色创建更加生动形象,增加趣味性,提升用户的使用体验。
进一步的,所述步骤s300之后还包括步骤:
s400控制所述虚拟角色根据所述虚拟表情数据进行演示。
进一步的,所述步骤s400之后还包括步骤:
s500获取控制参数信息,并控制所述虚拟角色进行演示;
其中,所述控制参数信息包括动作参数信息、道具参数信息、毛发参数信息、背景参数信息中的任意一种或多种。
本发明中,动作参数信息包括但是不限于位移、缩放程度、旋转角度和进出场动作。与预先设置的卡通角色相比,本发明有大量的实时动作可以供用户使用,通过控制窗口的按钮来激活动作,使得虚拟角色的形象看起来更加生动。而且,还可以根据用户喜好来选择虚拟角色的发型,得到更加漂亮个性化的虚拟角色。当然,还可以根据用户的喜好,来选择等道具,增加趣味性。
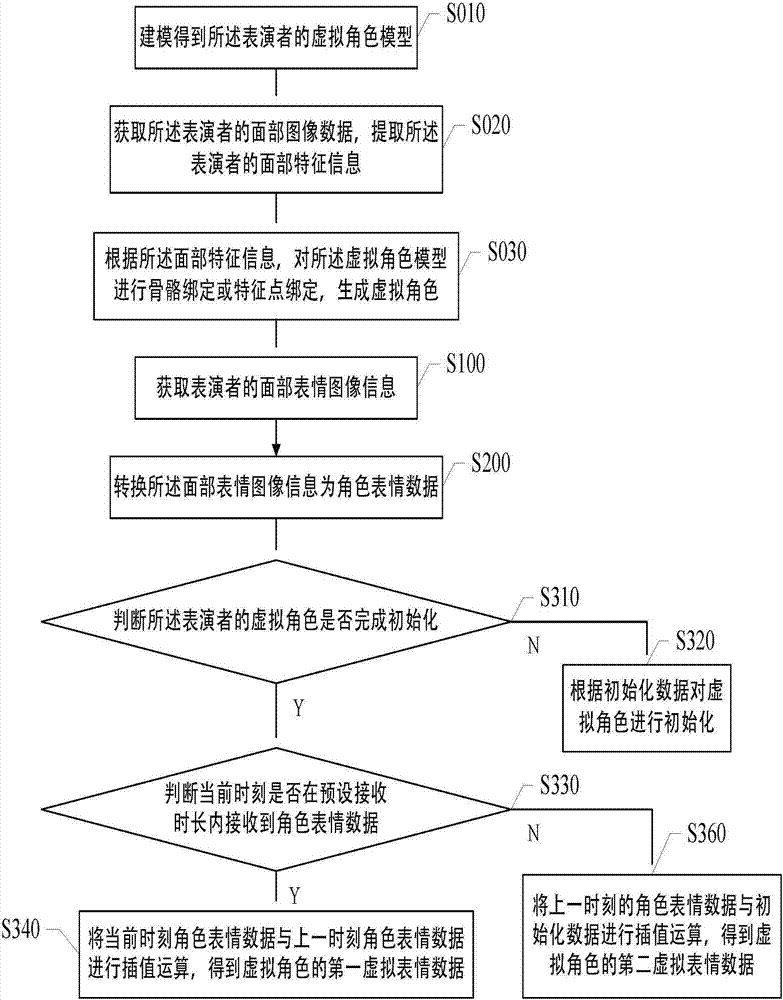
进一步的,所述步骤s100之前包括步骤:s010建模得到所述表演者的虚拟角色模型;s020获取所述表演者的面部图像数据,提取所述表演者的面部特征信息;s030根据所述面部特征信息,对所述虚拟角色模型进行骨骼绑定或特征点绑定,生成所述虚拟角色。
在本发明中,用户可以自己进行创建喜欢的虚拟角色,可以将用户的骨骼(或特征点)与想要创建的虚拟角色的骨骼(或特征点)按照用户需求进行绑定,这样后期即使是用户创建的是与人脸面部特征差距较大的虚拟角色也能够生动形象地演示出来。
本发明还提供一种基于虚拟角色的数据处理系统,包括:第一获取模块,获取表演者的面部表情图像信息;转换模块,与所述获取模块通信连接;将所述获取模块获取的所述面部表情图像信息,转换为角色表情数据;处理模块,与所述转换模块通信连接;根据数据插值算法,处理所述转换模块转换得到的所述角色表情数据,得到虚拟角色的虚拟表情数据。
本发明中,可以将人脸的面部动作,转移到用户选择的任何虚拟角色上进行演示,能够实时地通过该虚拟角色反应出表演者当前的面部表情变化,虚拟角色创建更加生动形象,增加趣味性,提升用户的使用体验,并且能够在识别出现故障时,把角色的动作稳定控制在一个区间内,使得虚拟角色演示更加生动自然。
进一步的,所述处理模块包括:储存子模块,按照时间先后顺序,储存初始化数据和每一时刻的角色表情数据;接收子模块,接收角色表情数据;第一判断子模块,判断所述表演者的虚拟角色是否完成初始化;初始化子模块,与所述第一判断子模块通信连接;当所述第一判断子模块判断所述表演者的虚拟角色未完成初始化时,根据初始化数据对所述虚拟角色进行初始化;第二判断子模块,分别与所述接收子模块和所述第一判断子模块通信连接;当所述第一判断子模块判断所述虚拟角色完成初始化时,判断在预设接收时长内所述接收子模块是否接收到当前时刻的角色表情数据;第一处理子模块,与所述第二判断子模块、所述储存子模块通信连接;当所述第二判断子模块判断所述接收子模块在预设接收时长内接收到当前时刻的角色表情数据时;将所述储存子模块储存的当前时刻的角色表情数据与所述储存子模块储存的上一时刻的角色表情数据进行插值运算,得到所述虚拟角色的第一虚拟表情数据;第二处理子模块,与所述第二判断子模块、所述储存子模块通信连接;当所述第二判断子模块判断所述接收子模块在预设接收时长内未接收到当前时刻的角色表情数据时;将所述储存子模块储存的上一时刻的角色表情数据与所述储存子模块储存的初始化数据进行插值运算,得到所述虚拟角色的第二虚拟表情数据。
本发明中,能够在识别出现故障时,例如识别失败或者识别错误时,将数据进行插值运算,平滑处理从而把角色的表情动作稳定控制在一个区间内,使得虚拟角色演示更加生动自然。
进一步的,所述转换模块还包括:识别子模块,根据所述第一获取模块获取的表演者的面部表情图像信息,识别当前时刻的面部表情信息,得到面部特征点和面部特征点的当前空间坐标值;运算子模块,与所述识别子模块通信连接;将所述识别子模块识别得到的所述所述面部特征点的当前空间坐标值,与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;并将所述位移差值与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;转换子模块,与所述运算子模块通信连接;将所述运算子模块运算得到的所述当前时刻的表情参数按照预设转换方式进行转换,得到所述角色表情数据;其中,所述面部特征点包括眼睛、眼球、眉毛、鼻子、嘴巴、耳朵和颈骨。
本发明中,不仅仅能够将表演者的实时面部表情变化映射在虚拟角色上面进行演示,还能够根据用户需求将用户的表情参数按照用户预先设置的转换方式进行转换,获得更加夸张搞怪的角色表情数据,提升用户的使用体验和趣味性。
进一步的,基于虚拟角色的数据处理系统还包括建模模块,建模得到所述表演者的虚拟角色模型;采集模块,获取所述表演者的面部图像数据;提取模块,与所述采集模块通信连接;根据所述采集模块获取的所述表演者的面部图像数据,提取所述表演者的面部特征信息;生成模块,分别与所述建模模块和所述提取模块通信连接;根据所述提取模块提取的所述面部特征信息,对所述建模模块建模得到的所述虚拟角色模型进行骨骼绑定或特征点绑定,生成所述虚拟角色;控制模块,与所述处理模块通信连接;控制所述表演者的虚拟角色根据所述处理模块处理后得到的所述虚拟表情数据进行演示;第二获取模块,获取控制参数信息;所述控制模块,还与所述第二获取模块通信连接;根据所述第二获取模块获取的所述控制参数信息,控制所述虚拟角色进行演示;其中,所述控制参数信息包括动作参数信息、道具参数信息、毛发参数信息、背景参数信息中的任意一种或多种。
本发明中,除了将表演者的面部表情变化,实时的在虚拟角色进行同步演示,还增加了通过预设的控制键与场景参数的关系,选择控制键控制虚拟角色增加一些身体动作,为虚拟角色选择用户自己喜欢的道具等,这样使得虚拟角色的表演不呆板,个性化十足。
与现有技术相比,本发明提供一种基于虚拟角色的数据处理方法及系统,至少带来以下一种技术效果:
1、本发明能够将实时人脸的面部动作转移到用户选择的任何虚拟角色上生动形象地演示出来。能够实时地通过该虚拟角色反应出表演者当前的面部表情变化,虚拟角色创建更加生动形象,增加趣味性,提升用户的使用体验。
2、本发明能够在视频聊天、网络直播等互动性较强的应用领域中,避免用户隐私泄露,提升安全性。
3、本发明能够在识别丢失、识别错误时,将捕捉数据进行插值处理,平滑过渡把角色的动作稳定控制在一个区间内,使得角色的演示更加自然生动,避免因为录制设备自身的精度等原因出现抖动等不自然的现象,提升用户的使用体验。
4、本发明能够获取丰富的表情信息和眼动信息,将情感与面部动画结合演示,提高表演者的使用体验和观众的观看体验。
5、本发明能够将虚拟角色的面部动作与预设身体动画、脸部动画、道具、毛发、位移、缩放程度、旋转角度和进出场动画中的至少一种进行融合渲染,趣味性更高。
附图说明
下面将以明确易懂的方式,结合附图说明优选实施方式,对一种基于虚拟角色的数据处理方法及系统的特性、技术特征、优点及其实现方式予以进一步说明。
图1是本发明一种基于虚拟角色的数据处理方法一个实施例的流程图;
图2是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图3是本发明一种基于虚拟角色的数据处理方法实施例的数据插补效果图;
图4是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图5是本发明一种基于虚拟角色的数据处理方法实施例网格探针的效果图;
图6是本发明一种基于虚拟角色的数据处理方法实施例网格探针的效果图;
图7是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图8是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图9是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图10是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图11是本发明一种基于虚拟角色的数据处理方法另一个实施例的流程图;
图12是本发明一种基于虚拟角色的数据处理方法实施例的毛发控制界面图;
图13是本发明一种基于虚拟角色的数据处理方法实施例的毛发探针效果图;
图14是本发明一种基于虚拟角色的数据处理方法实施例的动作、道具控制界面图;
图15是本发明一种基于虚拟角色的数据处理系统一个实施例的结构图;
图16是本发明一种基于虚拟角色的数据处理系统一个实施例的虚拟男神猫咪形象图;
图17是本发明一种基于虚拟角色的数据处理系统另一个实施例的结构图;
图18是本发明一种基于虚拟角色的数据处理系统另一个实施例的结构图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
参照图1所示,本发明提供一种基于虚拟角色的数据处理方法的一个实施例,包括:
s100获取表演者的面部表情图像信息;
s200转换所述面部表情图像信息为角色表情数据;
s300根据数据插值算法,处理所述角色表情数据,得到虚拟角色的虚拟表情数据。
具体的,本发明实施例中,通过摄像头等运动采集设备来采集获取表演者的面部表情图像信息,通过计算机等处理器来处理数据。摄像头可以是计算机自带的摄像头,也可以是通过usb等物理连接方式进行连接,也可以是通过wifi、蓝牙等通讯连接方式进行连接。本发明中,可以将人脸的面部动作,转移到用户选择的任何虚拟角色上进行演示,能够实时地通过该虚拟角色反应出表演者当前的面部表情变化,虚拟角色创建更加生动形象,增加趣味性,提升用户的使用体验,并且能够在识别出现故障时,把角色的动作稳定控制在一个区间内,使得虚拟角色演示更加生动自然。
参照图2所示,本发明提供一种基于虚拟角色的数据处理方法的另一个实施例,包括:
s010建模得到所述表演者的虚拟角色模型;
s020获取所述表演者的面部图像数据,提取所述表演者的面部特征信息;
s030根据所述面部特征信息,对所述虚拟角色模型进行骨骼绑定或特征点绑定,生成所述虚拟角色;
s100获取表演者的面部表情图像信息;
s200转换所述面部表情图像信息为角色表情数据;
s310判断所述表演者的虚拟角色是否完成初始化;若是,执行步骤s330,否则,执行步骤s320;
s320根据初始化数据对所述虚拟角色进行初始化;
s330判断当前时刻是否在预设接收时长内接收到角色表情数据;若是,执行步骤s340,否则,执行步骤s350;
s340将当前时刻的角色表情数据与上一时刻的角色表情数据进行插值运算,得到所述虚拟角色的第一虚拟表情数据;
s350将所述上一时刻的角色表情数据与所述初始化数据进行插值运算,得到所述虚拟角色的第二虚拟表情数据。
具体的,本发明实施例中,faceshift捕捉技术最大的好处在于可以将捕捉数据以网络包的形式发送给计算机等处理器,但往往因为一些特殊原因(诸如光线干扰)造成识别不准、识别错误或识别失败。因此需要在unity里解析网络包,可以实现在解析的过程中对错误的包做处理来弥补识别丢失和识别错误造成的不良后果,这样能够使得即使识别丢失、或者当部分识别数据出现偏差过大或识别失败时,unity将平滑过渡处理,可以把角色的动作稳定控制在一个区间内,使得角色的演示更加自然生动,避免因为录制设备自身的精度等原因出现抖动等不自然的现象,其中faceshift传送的数据包格式如下:协议号+包正文。协议号为33633,33433这2项中的一项。
具体的,当协议号为33633时,包正文为动画和骨骼的初始化数据(初始化包)。当协议号为33433时,包正文为动画和骨骼的驱动数据。(驱动数据包,这里驱动数据是指虚拟角色完成初始化后的根据表演者面部表情图像信息得到的虚拟角色的角色表情数据)
如果未初始化时识别错误,将无法接受到33633包。此时,客户端将使用上一次正确识别的初始化数据。直到识别正确,才使用本次的初始化数据替代。如果未曾获取过初始化数据,则挂起线程,忽略所有33433包,一直等待到正确的初始化数据再驱动。
如果识别错误,通常可以通过解析33433的数据包来发现。
33433包正文的格式为:
包id+包大小+包起始位+驱动数据+包id+包大小+包起始位+驱动数据。
当包id等于101时,驱动数据为布尔值,表明该帧识别是否正常。如果识别错误,则跳过本条数据,不驱动,只是平滑过渡到初始状态。对于unity3d来说,此时将角色上一帧的朝向、位移、蒙皮变形数据做平滑插补(damperlerp)。在2秒内,平滑的将角色朝向和位移过度到初始值,将角色的蒙皮变形数据过度到初始状态。
代码如下:
translation=vector3.lerp
(_prevvalidtranslation,m_prev_track.translation(),_lefpt);
rotation=quaternion.slerp
(_prevvalidrotation,m_prev_track.drotation(),_lefpt);
float_lefpt在2秒内从0累加1。
此过程简称为“丢失还原”。
如果在丢失还原的过程中收到了识别失败的包,则一律略过。
如果在丢失还原的过程中收到了识别正确的包,则将此时的动作平滑过度到新包的数据。
translation=vector3.lerp
(_prevvalidtranslation,m_current_track.translation(),_lefpt);
rotation=quaternion.slerp
(_prevvalidrotation,m_current_track.drotation(),_lefpt);
float_lefpt重设为0,并在2秒内从0累加1。
有一种特殊情况,faceshift采集数据时将非脸部的图像识别为脸部。如衣服上有人面图案,或者如果光线过暗,会将头发识别成眉毛。此时的faceshift会认为自己的数据采集正确,并将33433包的101字段标为true。此时,必须在unity3d中做处理。当每次获得到采集数据后不适用收到的数据去驱动角色的骨骼动画和蒙皮变形,而是将本次数据与上一次的数据做插补:
data=math.lerp(prevdata,currentdata,0.5)
将插补的值作为本次获取的数据,并赋值给prevdata,留给下一次获取到数据包时做处理。这样做的好处是,当识别不稳定时,几乎可以把角色的动作稳定控制在一个区间内。采集数据插补处理后的效果如图3所示。使得角色的演示更加自然生动,避免因为录制设备自身的精度等原因出现抖动等不自然的现象。本发明能够在识别丢失或识别错误时,平滑过渡处理使得角色的动作稳定控制在一个区间内,角色的演示更加自然生动,避免因为录制设备自身的精度等原因出现抖动等不自然的现象,提升用户的使用体验。
参照图4所示,本发明提供一种基于虚拟角色的数据处理方法的另一个实施例,包括:
s010建模得到所述表演者的虚拟角色模型;
s020获取所述表演者的面部图像数据,提取所述表演者的面部特征信息;
s030根据所述面部特征信息,对所述虚拟角色模型进行骨骼绑定或特征点绑定,生成所述虚拟角色;
s100获取表演者的面部表情图像信息;
s210根据所述表演者的面部表情图像信息,识别当前时刻的面部表情信息,得到面部特征点和面部特征点的当前空间坐标值;
s220将所述面部特征点的当前空间坐标值和与相应的初始空间坐标进行运算,得到位移差值;
s230将所述位移差值与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;
s240将所述当前时刻的表情参数按照预设转换方式进行转换,得到所述角色表情数据;
s400控制所述虚拟角色根据所述虚拟表情数据进行演示;
其中,所述面部特征点包括眼睛、眼球、眉毛、鼻子、嘴巴、耳朵和颈骨。
具体的,本发明实施例中,用户可以自己进行创建喜欢的虚拟角色,建立虚拟角色模型后,需要建立虚拟角色的基础表情库,通过预设方式绑定骨骼,得到虚拟角色的初始表情,然后根据训练调整或者预先存储的表情比值得到虚拟角色的n种基础表情,其中训练调整是获取用户的真实表情的所有面部特征关键点的空间坐标,然后分别根据各个基础表情的空间坐标,训练调整虚拟角色得到虚拟角色的n中基础表情数量,在此,虚拟角色的基础表情的数量真实人脸的基础表情的数量要相同,如图5所示,根据预设的预定数量的真人面部关键特征点,在采集的人脸上建立网格和网格探针,从而进行上述处理得到人脸表情比值,并且通过后期摄像头采集的人脸面部表情变化得到表演者当前的面部表情比值,实时的将面部表情变化映射到虚拟角色上,生动形象地演示出来。利用摄像头等运动捕捉设备来捕捉镜头前表演者的面部表情图像信息,面部表情图像信息包括表情变化、眼球变化、颈部运动变化等等一系列变化信息,然后将捕捉的面部表情图像信息进行分析处理,能够得到面部特征点和面部特征点的当前空间坐标值,从而得到位移差值,进而得到表演者的当前时刻的表情参数,将当前表情参数转换得到角色表情数据,并映射到用户选择的虚拟角色模型上,能够实时地通过该虚拟角色反应出表演者当前的面部表情变化。本实施例由于获取面部表情变化基本上只获取五官的轮廓位置信息,并不能更生动的获取真人面部变化,因此获取眼球的运动以及脖子的运动,将眼球运动的空间坐标信息进行分类,并根据分好类别的空间坐标信息与预先建立的情感信息数据库中的眼球情感信息坐标作比对,得到眼球当前空间坐标表示的感情含义,这样能够获取丰富的眼动信息,从而分析表演者的情感状态,根据情感状态与预先绑定的表示相应情感的表情符和身体动作结合映射到虚拟角色进行演示,能够增加趣味性,提高表演者的使用体验和观众的观看体验。
具体的,首先需要通过捕捉镜头前表演者的初始表情(即表演者面部没有任何变化的表情)的面部关键特征点,得到初始表情的初始空间坐标,然后实时捕捉镜头前表演者的当前表情变化,对采集的当前表情的面部关键特征点进行分析,得到当前表情的当前空间坐标值,然后计算两者之间的差值,并计算出比值。例如,假设摄像头实时采集的人脸表情为喜悦,将初始表情的眉毛、眼睛、鼻子、嘴巴、耳朵等的空间坐标值设为原点值so,基础表情(即为表演者喜悦、悲伤、生气等常见表情的最大情绪表达程度)“喜悦”的眉毛、眼睛、鼻子、嘴巴、耳朵等最大程度表示时的空间坐标值设为smax,当前表情的眉毛、眼睛、鼻子、嘴巴、耳朵等的空间坐标值设为st,那么计算出当前喜悦表情的比值q=|st-so|÷|smax|。例如,表演者当前的面部表情为悲喜交加,即形容悲伤和喜悦的心情交织在一起,对“悲喜交加”这个复杂表情进行拆分得到“喜悦”和“悲伤”的基础表情,假设“悲喜交加”的“喜悦”和“悲伤”的比值均为喜悦比值s1=0.5,且悲伤比值s2=0.5,那么虚拟角色就根据事先建立好的虚拟角色相应的“喜悦”表情和“悲伤”表情,得到虚拟角色的比值p,即喜悦比值p1=0.5,且悲伤比值p2=0.5,按照0.5的比值控制虚拟角色相应的面部特征点的位移变化,合成为与表演者“悲喜交加”对应的虚拟角色的“悲喜交加”,当然,现实中“悲喜交加”的“喜悦”和“悲伤”的比值不一定均为0.5,可以通过相应的计算得到比值。另外,假设表演者的当前面部表情为咧嘴,咧嘴的比值为s3=0.2,那么表演者可以根据预设的p=ns的方式进行计算得到虚拟角色的咧嘴比值,例如n=2时,p3=0.2×2=0.4,那么虚拟角色的咧嘴程度要大于表演者的咧嘴程度,这样不仅仅能够实现将实时人脸的面部动作转移到用户选择的动画人物、企业吉祥物、已故偶像等一切虚拟形象上演示的功能,还能够提供表演者方便的根据需求来进行夸张有趣的表演,提升表演者的使用体验和观看者的观看体验。由于直播很多动作是通过faceshift采集真人的,并且所有动作都能自由控制,因此往往会有需求用程序实时计算网格变形来取代美术人员实现制作动画。使用类似探针的做法:设定几个关键探针位置及半径,实时控制以探针为球心的球中的顶点坐标来模拟各种蒙皮效果。例如,如图6所示,如果表演者创建的虚拟角色为狗模型,由于狗的天性喜欢嗅鼻子,因此在狗模型的鼻子出增加一个独立的探针。探针球覆盖整个鼻子。每隔一个随机的时间(一般在1到3秒),把探针球内的顶点x坐标往中心偏移并恢复,形成挤压的效果。把顶点的y坐标往y轴正方向偏移并恢复,形成鼻子上抬的效果,这样不仅仅能够更加生动形象根据用户的鼻子变化来控制虚拟角色的鼻子变化,还能提升趣味性。而由于互联网直播即时互动的特性,可以迅速为直播形象与观众建立联系,并取得反馈,大大提高了直播的娱乐性、趣味性。本发明虚拟技术的应用领域可以包括各种商业化运营,如品牌授权、广告植入、周边产品开发、影视作品制作、艺人和网红经纪等。也包括自媒体、pgc视频、影视、演唱会、游戏和动漫元素有关的完整产业链构建。除此之外,虚拟直播还可以应用在教育、博物馆、旅游景点等。仅仅采集表演者的面部五官运动变化进行演示的话,生动性不够因此如果将眼球变化与情感信息绑定,采集到眼球变化后,映射到虚拟角色进行演示能使直播演示更加生动有趣,提升观众的观看体验。本发明还能够在视频聊天、网络直播等互动性较强的应用领域中,避免用户隐私泄露,提升安全性。
参照图7所示,本发明提供一种基于虚拟角色的数据处理方法的另一个实施例,包括:
s010建模得到所述表演者的虚拟角色模型;
s020获取所述表演者的面部图像数据,提取所述表演者的面部特征信息;
s030根据所述面部特征信息,对所述虚拟角色模型进行骨骼绑定或特征点绑定,生成所述虚拟角色;
s100获取表演者的面部表情图像信息;
s210根据所述表演者的面部表情图像信息,识别当前时刻的面部表情信息,得到面部特征点和面部特征点的当前空间坐标值;
s220将所述面部特征点的当前空间坐标值和与相应的初始空间坐标进行运算,得到位移差值;
s230将所述位移差值与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;
s240将所述当前时刻的表情参数按照预设转换方式进行转换,得到所述角色表情数据;
s400控制所述虚拟角色根据所述虚拟表情数据进行演示;
s500获取控制参数信息,并控制所述虚拟角色进行演示;
其中,所述面部特征点包括眼睛、眼球、眉毛、鼻子、嘴巴、耳朵和颈骨;所述控制参数信息包括动作参数信息、道具参数信息、毛发参数信息、背景参数信息中的任意一种或多种。
具体的,本发明实施例中s400虚拟角色演示过程中,如果获取了控制参数信息,那么需要将虚拟角色的面部动画与表演者选择的控制参数信息对应的动画进行融合演示,具体的,如图8所示。
s10根据用户输入的预设躯干动作指令,将所述虚拟角色面部动画与用户选择的躯干动作参数信息进行融合动画演示;其中,所述躯干动作信息包括位移、旋转、缩放;和/或,
s30根据用户输入的预设脸部动作指令,将所述虚拟角色面部动画与用户选择的脸部动作进行融合动画演示;和/或,
s40根据用户输入的预设道具指令,将所述虚拟角色面部动画与用户选择的道具参数信息进行融合动画演示;和/或,
s50根据用户输入的预设毛发指令,将所述虚拟角色面部动画与用户选择的毛发参数信息进行融合动画演示;和/或,
s60根据用户输入的预设背景指令,将所述虚拟角色面部动画与用户选择的背景参数信息进行融合动画演示;
本发明中,与预先设置的卡通角色相比,本发明技术特征有大量的实时动作可以供用户使用,通过控制窗口的按钮来激活动作,使得虚拟角色的形象看起来更加生动。而且,还可以根据用户喜好来选择虚拟角色的发型,得到更加漂亮个性化的虚拟角色。当然,还可以根据用户的喜好,来选择眼镜、腮红等道具,增加趣味性。
进一步的,所述步骤s10包括步骤:
s11判断在预设待机时长内,所述虚拟角色是否接收到所述预设动作指令,若是执行步骤s12;否则,执行步骤s17;
s12输出所述虚拟角色当前状态为待机状态,根据预设的待机动作,控制所述虚拟角色进行演示;
s17输出所述虚拟角色当前状态为活跃状态,根据当前预设动作指令,调用与所述当前预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示。
进一步的,所述步骤s12之后,s17之前还包括步骤:
s13判断所述待机状态下,所述虚拟角色是否接收到所述预设动作指令,若是执行步骤s14;否则,执行步骤s12;
s14判断当前预设动作指令是否是第一预设动作指令,若是执行步骤s15;否则,执行步骤s16;
s15停止进行所述待机动作,并根据所述第一预设动作指令,调用与所述第一预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示;
s16继续进行所述待机动作,并根据第二预设动作指令,调用与所述第二预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示。
进一步的,所述步骤s17之后还包括步骤:
s18判断所述活跃状态下,在所述当前预设动作指令对应的完成时长内,所述虚拟角色是否接收到下一预设动作指令,若是执行步骤s19;否则,执行步骤s20;
s19所述虚拟角色停止当前动作,根据所述下一预设动作指令,调用与所述下一预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示;
s20继续根据所述当前预设动作指令,控制所述虚拟角色进行演示。
上述步骤的整体流程图如图9所示。其中,所述预设动作指令包括第一预设动作指令和第二预设动作指令;所述第一预设动作指令是指打断待机身体动作,通过所述第一预设动作指令的相关身体动作进行演示的预设动作指令;所述第二动作是指不打断待机身体动作,通过所述第二预设动作指令的相关身体动作与所述待机身体动作进行融合演示的预设动作指令。本实施例只具体讲述了躯干动作指令对应的躯干动作参数信息,脸部动作指令与躯干动作指令的过程是一致的,在此不再细细讲述说明。
本发明实施例中,在制作模型的时候将头部与身体拆分开,再在unity内部把头装到身体上,faceshift只控制颈部骨骼、眼球转动和脸部蒙皮变形动画,身体动作包括待机动作和非待机动作,非待机动作包括3dmax预制动画和unity3d程序动画,预制动画是只控制身体的动画,与面部表情两者互相叠加,比如一边可以倒立,一边可以抛媚眼。unity3d程序动画是当处理完头部动画和预制动画后,再在其上重载新的骨骼动画。以点击“弹出眼球”按钮为例:每一帧update先执行把眼球的坐标归回初始坐标,再把眼球朝向根据faceshift数据转向,最后将眼球的“骨骼”往前平移。另外,因为长时间的等待会使得角色看起来呆板,所以每隔n个t秒会播放一次特殊的“小动作”,例如经常摸摸脑袋或肚子,使得虚拟角色看起来更加生动。
本发明中,与预先设置的卡通角色相比,本发明技术特征有大量的实时动作可以供用户使用,动作控制分为3部分:faceshift捕捉的脸部动作,3dmax预制的动画,以及unity3d中由程序控制的动画。
faceshift捕捉的动画:脸部表情,眼球运动,颈部转动
3dmax预制动画:鼓掌,捂嘴偷笑,双手比爱心,数落,跳舞,倒立,磕头,鞠躬,抖腿,劈叉,打哈欠,怒骂等
unity3d程序动画:头高速回旋,头掉落,头部拉扯,弹出眼球等。
其中3dmax预制动画和unity3d程序动画通过控制窗口的按钮来激活。
通过3dmax预制动画,以及unity3d中由程序控制动画。
在制作模型的时候将头部与身体拆分开。再在unity内部把头装到身体上,头部的父级为颈部骨骼。faceshift只控制颈部骨骼、眼球转动和脸部蒙皮变形,而预制动画只控制身体的动画,两者互相叠加。比如一边倒立,一边可以抛媚眼。对于unity3d的程序动画来说,当处理完faceshift动画和程序动画后,再在其上重载新的骨骼动画。以点击“弹出眼球”按钮为例:每一帧update先执行把眼球的坐标归回初始坐标,再把眼球朝向根据faceshift数据转向,最后将眼球的“骨骼”往前平移。
待机动作分为5个动作。分别为主待机动作,长度为0.5秒,作用为使角色骨骼还原。特殊待机动作分别为:原地喘气,摸头,摸肚子,来回摆动身体。因为长时间的待机会使得角色看起来呆板,所以每隔n个0.5秒会播放一次特殊的“小动作”(n为1到10之间的随机数)。经常摸摸脑袋或肚子,使得卡通形象看起来更加生动。在角色在任何状态收到预制动画的播放信号后,就立刻开始播放预制动画。动画播放完成后,自动进入主待机动画,再随机播放特殊待机动画。跑步动作是一个特殊的预制动画。在收到跑步的信号后,如果此时角色状态为待机,则跑步动画将打断待机,立刻播放跑步动画。否则,角色将只执行位移,而不执行跑步动画。比如,角色此时正在表演骑马舞,而控制角色往画面左侧移动,那么,角色将以骑马舞的姿势跳跃到画面左侧,而不是打断骑马舞的动作。
如图10所示,进一步的,所述步骤s30包括步骤:
s31判断所述虚拟角色是否接收到所述预设道具指令,若是执行步骤s32;
s32判断所述虚拟角色是否接收到所述预设动作指令,若是执行步骤s33;否则,执行步骤s37;
s33判断所述预设道具指令对应的道具是否是第一预设道具,若是执行步骤s34;否则,执行步骤s36;
s34在预设隐藏时长内隐藏所述第一预设道具;
s35根据所述预设动作指令,调用与所述预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示;
s36保留第二预设道具,并根据所述预设动作指令,调用与所述预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示;
s37根据所述预设道具指令,调用与所述预设道具指令对应的道具参数信息,控制所述虚拟角色进行演示;
其中,所述道具类型包括所述第一预设道具和第二预设道具;所述第一预设道具指当接收到所述预设动作指令时,在预设隐藏时长内隐藏的道具;所述第二预设道具是指当接收到所述预设动作指令时,保留的道具。虽然道具可以直接通过按钮来控制开关,但部分道具需要与事件结合来调用。
第一预设道具包括但是不限于:爱心、黄瓜、骨头等。例如当做出一个比爱心的动作时被一个跳舞的动作打断,那么爱心将立刻被隐藏。
第二预设道具包括但是不限于:腮红、眼镜、墨镜、裂屏特效、黄瓜渍特效等。例如,比一个爱心的动作时希望双手合拢的同时显示一个红色爱心,这个显示的触发条件是动作,再比如,把一根骨头砸向屏幕的时候希望骨头到达屏幕前显示一个裂屏的画面,这个裂屏特效的触发条件是骨头的位置。当把骨头砸向显示屏时,立刻切换成倒立动画,碎屏特效和眼镜都依然存在。眼镜只能通过控制面板的按钮关闭,而碎屏特效有自己的生命周期,逐渐透明并在若干秒后自动隐藏。
把3dmax动画导入到unity3d后,在unity3d里编辑各个关键帧,例如,比爱心时,在动画轴到达双手合拢的同时抛出一个事件。扔骨头时,在动画轴到达骨头飞到屏幕前时抛出一个事件。所有的事件和点击按钮的事件一样,可以驱动某个道具显示或隐藏,因此可以方便的编辑控制,能够方便快捷地统一管理多种触发条件。
如图11所示,进一步的,所述步骤s40包括步骤:
s41判断所述虚拟角色是否接收到所述预设毛发指令,若是执行步骤s42;
s42判断所述虚拟角色是否接收到所述预设动作指令,若是执行步骤s43;否则,执行步骤s47;
s43根据所述预设动作指令,调用与所述预设动作指令对应的动作参数信息,控制所述虚拟角色进行演示;
s44根据预设查找方式,查找所述虚拟角色毛发变化部位;
s45判断所述毛发变化部位的空间坐标变化值是否超过预设变化范围,若是执行步骤s46;
s46根据预设调整方式,将所述毛发变化部位的毛发进行调整;
s47根据所述预设毛发指令,调用与所述预设毛发指令对应的毛发参数信息,控制所述虚拟角色进行演示。
其中,所述毛发选择信息包括毛发颜色、毛发长度、毛发透明度和毛发着色中的一种或任意多种。
本发明中,unity3d的所有渲染工作都离不开shader(着色器),shader实际上就是一小段程序,它负责将输入的mesh(网格)以指定的方式和输入的贴图或者颜色等组合作用,然后输出依据这个输出来将图像绘制到屏幕上。输入的贴图或者颜色等,加上对应的shader,以及对shader的特定的参数设置,将shader及输入参数打包存储在一起,得到的就是一个material(材质)。之后,我们便可以将材质赋予合适的renderer(渲染器)来进行渲染输出了。与动画片里,消耗大量时间预先渲染的毛发不同,本发明的虚拟角色毛发都是实时渲染的,由于需要平衡渲染效果以及渲染效率,因此,使用了毛发探针技术选择虚拟角色的毛发长度、颜色、透明度等。另外,角色的动作往往会带来毛发的加速度变化,从而使局部地区的毛发扭曲。如果像动画片里一样对每一根毛发做调整,计算机的开销会非常巨大。为此,使用毛发探针系统对虚拟角色的毛发进行扭曲查找并处理,如此一来,便可以在整个角色只是用一个shader的情况下,控制局部的毛发摆动,大大的提高了渲染效率。
本发明中,与动画片里,消耗大量时间预先渲染的毛发不同,本发明的虚拟角色毛发都是实时渲染的,由于需要平衡渲染效果以及渲染效率,因此,使用了毛发探针技术选择虚拟角色的毛发长度、颜色、透明度等。另外,角色的动作往往会带来毛发的加速度变化,从而使局部地区的毛发扭曲。如果像动画片里一样对每一根毛发做调整,计算机的开销会非常巨大。为此,使用毛发探针系统对虚拟角色的毛发进行扭曲查找并处理,如此一来,便可以在整个角色只是用一个shader的情况下,控制局部的毛发摆动,大大的提高了渲染效率。毛发是由使用unity3d的vertex&fragment函数的shader编写。毛发的构成至少需要2张贴图:base贴图,length贴图。如图12所示,base贴图表示的是毛发的颜色,采用3d美术人员在建模软件里制作的毛发贴图。再在此基础上,通过ps软件增加杂色和点状化滤镜,使得贴图中有不规则杂色。length贴图表示的是毛发的长短,采用3d美术人员在建模软件中制作的毛发贴图,去色并增加对比度,略微做调整。其中,白色表示毛发最长,黑色表示毛发最短。noise贴图是所有卡通角色公用的一张贴图,用来表示毛发的透明度,一般来说,将其平铺15到20次。平铺越少,毛块颗粒越大。平铺越多,毛块颗粒越细。把base贴图乘上basecolor作为角色的“底色”,即没有毛发的地方的颜色(如嘴唇、口腔、眼睛周围)。再将base贴图乘上furcolor,乘以平铺后的noise贴图的透明度,生成一张“半透明颗粒状”的贴图,这张贴图沿着模型法线方向,偏移furlength*length贴图的灰度。即可得到毛发最外的轮廓。重复此过程共20次,每次偏移量为i/20。形成20层“半透明状”的毛发外壳。其中,公式如下:
每一层的透明度alpha=1-pow(multiplier,_furtickness)。
当然,如果希望毛发看起来更卡通一些,可以使用明暗过渡更锐利的照明方法。其中有两种着色方法:
a静态光源卡通着色
将一张cubemap,以模型法线方向投射到视口,将此结果与已有的毛发颜色做乘法。代码如下:
float3cubenormal=mul(unity_matrix_mv,float4(v.normal,0));
float4cube=texcube(_toonshade,i.cubenormal);
returncol*cube;//col为上一步计算出的毛发颜色//
b动态光源卡通着色
先将模型法线与主平行光源的朝向做点乘,获得到一个-1到1之间的值称为d,通过d=d*0.5+0.5将d范围变成0到1之间。将一张高度为1个像素的ramp贴图,以d为横坐标取uv获取到照明颜色(查表法)。将结果与已有的毛发颜色做乘法。代码如下:
#ifndefusing_directional_light
lightdir=normalize(lightdir);
#endif
halfd=dot(normal,lightdir)*0.5+0.5;
half4ramp=tex2d(_ramp,float2(d,d));
return_lightcolor0*ramp*(atten*2);
另外,角色的动作往往会带来毛发的加速度变化,从而使局部地区的毛发扭曲。如果像动画片里一样对每一根毛发做调整,计算机的开销会非常巨大。为此,使用毛发探针系统进行查找处理。如图13所示,球状标志为毛发探针。探针绑定在角色的骨骼上。当骨骼有移动或旋转时,造成加速度。探针捕捉对应骨骼的加速度,反馈到毛发上。离探针越近,受加速度影响越大。离探针越远,则受到加速度影响越小。在探针以外的位置,加速度为多个探针的插值。cpu计算加速度后,通过探针将多个vector3传给gpu。毛发shader最初对毛发做的偏移值为normal*i/20。此时修改为normal*i/20+accelerate*pow2(i/20)。用pow2的理由是毛发越接近根部,受到的加速度越小。在制作女性角色时,头发往往比较长。而由于头发是随着头部摆动,头部又是实时计算朝向的,所以无法通过预先录制动画来制作头发的飘动。此时我们的网格探针又派上用场了。对于较短的头发(如前额的头发),在头发根部放置探针,父级为角色的头部。探针实时捕获头部的平移加速度和转加速度。离探针原点越近的网格顶点受到的加速度影响越小,离原点越远的网格顶点受到的加速度越大。代码如下:
vector3offset=distance*distance*accelerate;
其中,distance为顶点到探针原点的距离。对于较长的头发(如马尾辫),我们使用两个探针。a探针放置于头发的根部,b探针放置于头发的末梢。末梢的探针b将随着头发摆动,并且受到物理重力的影响自然下垂。在两个探针之间插入一条空间的贝塞尔曲线:
vector3evaluate(vector3v0,vector3v1,vector3v2,vector3v3,floatt){
floatmf=1-t;
returnv0*mf*mf*mf+3*v1*t*mf*mf+3*v2*t*t*mf+v3*t*t*t;}
其中v0=m_start;//头发根部的探针位置;
v1=m_start+(m_end-m_start).normalized*m_startpriority;//头发根部的位置加上指向头发末梢的单位向量乘以起始权重(权重越大,头发刚性越强,权重越小,头发越下垂)
v2=m_accelerate*m_endpriority;//头发运动的加速度乘以终点权重(权重越大,头发越硬,权重越小,头发越柔软)
v3=m_end;//头发末梢的探针位置
t为头发的模型上各个顶点到探针a的距离除以ab探针的总长度。其物理意义为ab探针的权重百分比。
如此一来,便可以在整个角色只是用一个shader的情况下,控制局部的毛发摆动,大大的提高了渲染效率。
把3dmax动画导入到unity3d后,在unity3d里编辑各个关键帧,例如,比爱心时,在动画轴到达双手合拢的同时抛出一个事件。扔骨头时,在动画轴到达骨头飞到屏幕前时抛出一个事件。如图14所示,通过动作、道具等控制窗口的按钮来激活3dmax预制动画和unity3d程序动画,使得虚拟角色的形象看起来更加生动。而且,还可以根据用户喜好来选择虚拟角色的发型,得到更加漂亮个性化的虚拟角色。当然,还可以根据用户的喜好,来选择眼镜、腮红、骨头、爱心、黄瓜等道具,将选择的道具在不影响虚拟角色做身体动作的时候使用,增加趣味性。总之,我们可以根据需求来选择身体动作、道具、毛发中的任意一种或者多种相互之间于面部变化进行融合渲染,也可以不选择任何的输入控制身体动画指令,在达到预设的待机时长后,我们后台就会根据预置好的待机动作来进行播放,或者也可以事先将播放待机动画的功能关闭,只要根据用户的需求,可以任意的播放虚拟角色的动画。所有的事件和点击按钮的事件一样,可以驱动某个道具显示或隐藏,因此可以方便的编辑,能够统一管理多种触发条件。
参照图15所示,本发明提供一种基于虚拟角色的数据处理系统的一个实施例,包括:
第一获取模块,获取表演者的面部表情图像信息;
转换模块,与所述获取模块通信连接;将所述获取模块获取的所述面部表情图像信息,转换为角色表情数据;
处理模块,与所述转换模块通信连接;根据数据插值算法,处理所述转换模块转换得到的所述角色表情数据,得到虚拟角色的虚拟表情数据。
具体的,本发明实施例中,利用第一获取模块来捕捉镜头前表演者的面部表情图像信息,转换模块处理得到当前人脸面部特征的空间坐标,从而得到角色表情数据,处理模块进一步进行插值运算等运算过程,得到虚拟角色的虚拟表情数据,例如由知名情感主播主持的《深夜喵语》,以全新概念的虚拟男神猫咪形象,如图16,讲述情感文艺故事,分享每个人情感中的酸甜苦乐,为观众在线解答疑惑、为爱疗伤。本发明实施例可以将人脸的面部动作,转移到用户选择的任何虚拟角色上进行演示,能够实时地通过该虚拟角色反应出表演者当前的面部表情变化,虚拟角色创建更加生动形象,增加趣味性,提升用户的使用体验,并且能够在识别出现故障时,把角色的动作稳定控制在一个区间内,使得虚拟角色演示更加生动自然。
参照图17所示,本发明提供一种基于虚拟角色的数据处理系统的另一个实施例,所述处理模块包括:
储存子模块,按照时间先后顺序,储存初始化数据和每一时刻的角色表情数据;
接收子模块,接收角色表情数据;
第一判断子模块,判断所述表演者的虚拟角色是否完成初始化;
初始化子模块,与所述第一判断子模块通信连接;当所述第一判断子模块判断所述表演者的虚拟角色未完成初始化时,根据初始化数据对所述虚拟角色进行初始化;
第二判断子模块,分别与所述接收子模块和所述第一判断子模块通信连接;当所述第一判断子模块判断所述虚拟角色完成初始化时,判断在预设接收时长内所述接收子模块是否接收到当前时刻的角色表情数据;
第一处理子模块,与所述第二判断子模块、所述储存子模块通信连接;当所述第二判断子模块判断所述接收子模块在预设接收时长内接收到当前时刻的角色表情数据时;将所述储存子模块储存的当前时刻的角色表情数据与所述储存子模块储存的上一时刻的角色表情数据进行插值运算,得到所述虚拟角色的第一虚拟表情数据;
第二处理子模块,与所述第二判断子模块、所述储存子模块通信连接;当所述第二判断子模块判断所述接收子模块在预设接收时长内未接收到当前时刻的角色表情数据时;将所述储存子模块储存的上一时刻的角色表情数据与所述储存子模块储存的初始化数据进行插值运算,得到所述虚拟角色的第二虚拟表情数据。
所述转换模块还包括:
识别子模块,根据所述第一获取模块获取的表演者的面部表情图像信息,识别当前时刻的面部表情信息,得到面部特征点和面部特征点的当前空间坐标值;
运算子模块,与所述识别子模块通信连接;将所述识别子模块识别得到的所述所述面部特征点的当前空间坐标值,与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;并将所述位移差值与预设位移值进行运算,得到所述表演者在所述当前时刻的表情参数;
转换子模块,与所述运算子模块通信连接;将所述运算子模块运算得到的所述当前时刻的表情参数按照预设转换方式进行转换,得到所述角色表情数据;
其中,所述面部特征点包括眼睛、眼球、眉毛、鼻子、嘴巴、耳朵和颈骨。
具体的,本发明实施例中,首先需要通过捕捉镜头前表演者的初始表情的面部关键特征点,得到初始表情的初始空间坐标,然后实时捕捉镜头前表演者的当前表情变化,对采集的当前表情的面部关键特征点进行分析,得到当前表情的当前空间坐标值,然后计算两者之间的差值,并计算出比值。本发明能够实时地将人脸的面部动作转移到用户选择的任何虚拟角色上演示。本发明中,仅仅采集表演者的面部五官运动变化进行演示的话,生动性不够,因此如果将眼球变化与情感信息绑定,例如眼球飞速转动表明你做出的决定很冲动,眼神呆滞表明你神志恍惚,眼球转动缓慢道出了你疲劳的程度等等。采集到眼球变化后,映射到虚拟角色进行演示能使直播演示更加生动有趣,提升观众的观看体验。本发明中,捕捉技术最大的好处在于可以将捕捉数据以网络包的形式发送给别的客户端,但往往因为一些特殊原因(诸如光线干扰)造成识别不准、识别错误或识别失败。因此需要在unity里解析网络包,可以实现在解析的过程中对错误的包做处理来弥补识别丢失和识别错误造成的后果,这样能够使得即使识别丢失、或者当部分识别数据出现偏差过大或识别失败时,unity将平滑过渡处理,可以把角色的动作稳定控制在一个区间内,使得角色的演示更加自然生动,将实时采集的人脸面部动作流畅迅速地转移到虚拟角色上。
参照图18所示,本发明提供一种基于虚拟角色的数据处理系统的另一个实施例,基于虚拟角色的数据处理系统还包括建模模块,建模得到所述表演者的虚拟角色模型;采集模块,获取所述表演者的面部图像数据;提取模块,与所述采集模块通信连接;根据所述采集模块获取的所述表演者的面部图像数据,提取所述表演者的面部特征信息;生成模块,分别与所述建模模块和所述提取模块通信连接;根据所述提取模块提取的所述面部特征信息,对所述建模模块建模得到的所述虚拟角色模型进行骨骼绑定或特征点绑定,生成所述虚拟角色;控制模块,与所述处理模块通信连接;控制所述表演者的虚拟角色根据所述处理模块处理后得到的所述虚拟表情数据进行演示;第二获取模块,获取控制参数信息;所述控制模块,还与所述第二获取模块通信连接;根据所述第二获取模块获取的所述控制参数信息,控制所述虚拟角色进行演示;其中,所述控制参数信息包括动作参数信息、道具参数信息、毛发参数信息、背景参数信息中的任意一种或多种。
具体的,本发明实施例中,用户可以自己进行创建喜欢的虚拟角色,建立虚拟角色模型后,需要建立虚拟角色的基础表情库,通过预设方式绑定骨骼,得到虚拟角色的初始表情,然后根据训练调整或者预先存储的表情比值得到虚拟角色的n种基础表情,其中训练调整是获取用户的真实表情的所有面部特征关键点的空间坐标,然后分别根据各个基础表情的空间坐标,训练调整虚拟角色得到虚拟角色的n中基础表情数量,在此,虚拟角色的基础表情的数量真实人脸的基础表情的数量要相同,这样通过后期摄像头采集的人脸面部表情变化,实时的将面部表情变化映射到虚拟角色上,生动形象地演示出来。与预先设置的卡通角色相比,本发明技术特征有大量的实时动作可以供用户使用,通过3dmax预制动画,以及unity3d中由程序控制动画,这样通过控制窗口的按钮来激活3dmax预制动画和unity3d程序动画,使得虚拟角色的形象看起来更加生动。而且,还可以根据用户喜好来选择虚拟角色的发型,得到更加漂亮个性化的虚拟角色。当然,还可以根据用户的喜好,将选择的道具在不影响虚拟角色做身体动作的时候使用,增加趣味性。这样将虚拟角色的面部动作与预设身体动作、道具、毛发中的至少一种进行融合渲染,趣味性更高,用户使用体验更佳。把3dmax动画导入到unity3d后,在unity3d里编辑各个关键帧,例如,比爱心时,在动画轴到达双手合拢的同时抛出一个事件。扔骨头时,在动画轴到达骨头飞到屏幕前时抛出一个事件。所有的事件和点击按钮的事件一样,可以驱动某个道具显示或隐藏,因此可以方便的编辑控制,能够方便快捷地统一管理多种触发条件。
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!