一种数据库水平分库分表方法及系统、服务器与流程
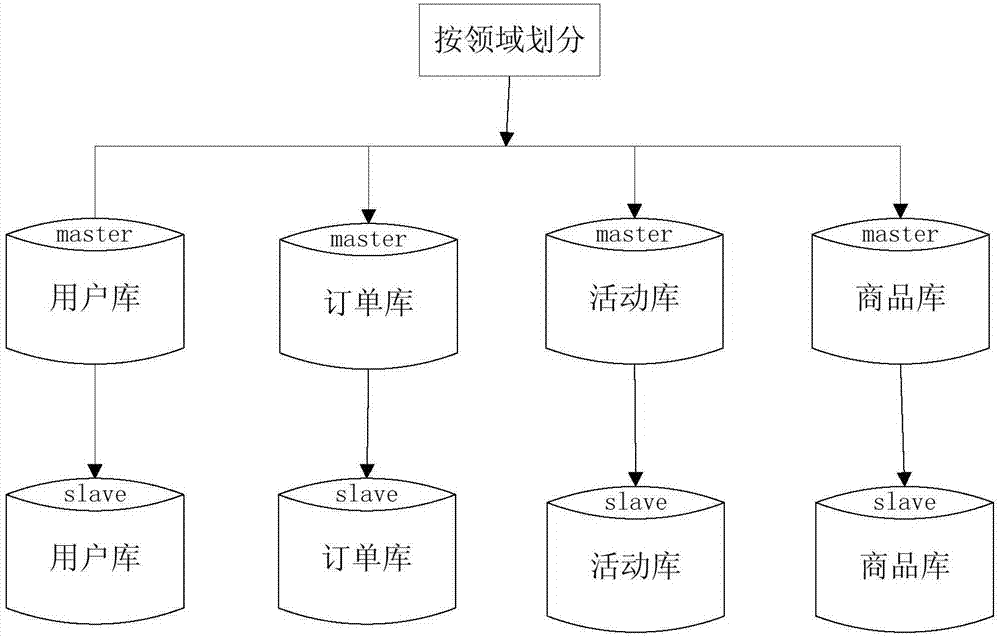
本发明涉及数据库的
技术领域:
,特别是涉及一种数据库水平分库分表方法及系统、服务器。
背景技术:
:数据库(database)是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库。通常,数据库是一个单位或是一个应用领域的通用数据处理系统,它存储的是属于企业和事业部门、团体和个人的有关数据的集合。数据库中的数据是从全局观点出发建立的,按一定的数据模型进行组织、描述和存储;其结构基于数据间的自然联系,从而可提供一切必要的存取路径,且数据不再针对某一应用,而是面向全组织,具有整体的结构化特征。随着业务不断发展,应用系统的业务数据也随着日积月累。相应的性能指标不断提升,日渐精细,例如信用审核自动化,用户全维度画像信息的掘取。这些业务需求上的升级,对响应时间的要求是越来越快,导致对系统性能的要求越来越高。垂直分库按照业务领域将原数据库划分为若干分数据库,从而解决业务系统之间的耦合,也能一定程度提升性能,有利于系统维护。垂直分表即通常所说的大表拆小表,拆分是基于关系型数据库中的列进行的。当某个表中的字段比较多,可以新建立一张扩展表,将不经常使用或者长度较大的字段拆分出去放到扩展表。因此,在字段特别多的情况下,垂直分表确实便于开发和维护,某种意义上可能表面“跨页”访问的问题。如图1所示,现有技术中的垂直分库分表后的数据库架构通常采用master-slave模式,只能对数据库的读操作进行扩展,而对数据库写入操作还是集中在master上,单个master上挂载slave的数量,也受到master性能的限制。垂直分库分表的方式缓解了原来单集群的压力,但不能解决秒杀等在线查询场景。例如需要判断一个用户,在某个活动期间内,只允许下一单。这样的场景对订单表的查询,响应时间的要求就非常苛刻。对订单这样的高表来说,性能就会成为查询瓶颈。关系型数据库在大于一定数据量的情况下检索性能会急剧下降。在面对互联网海量数据情况时,所有数据都存于一张表,显然会轻易超过数据库表可承受的数据量阀值。对于互联网应用来说,数据库单表的记录行数,可能达到千万级别,甚至是以亿级别,故会对实时业务查询造成严重影响。因此,对数据库进行分库分表是必须进行的。对于访问极为频繁、数据量巨大的单表来说,首要就是减少单表的记录条数,以减少查询所需要的响应时间,提高数据吞吐。而现有的数据库垂直分库分表方法无法解决这一问题。技术实现要素:鉴于以上所述现有技术的缺点,本发明的目的在于提供一种数据库水平分库分表方法及系统、服务器,基于单表的行数,将数据库水平分割为若干分库,每个分库再分割为若干分表,从而减少单表的记录数量,提高查询所需要的响应时间,且易于扩展。为实现上述目的及其他相关目的,本发明提供一种数据库水平分库分表方法,包括以下步骤:设定集群的个数、一个集群所包含的数据库个数以及一个数据库所包含的表格的个数;基于预设数据库拆分路由规则,将数据记录分配至各个集群所包含的各个数据库中;基于预设表格拆分路由规则,将各个数据库中的数据记录分配至该数据库所包含的各个表格中。于本发明一实施例中,所述集群所包含的数据库个数与所述数据库所包含的表格的个数的取值相同。于本发明一实施例中,基于预设数据库拆分路由规则,将数据记录分配至各个集群所包含的各个数据库中包括以下步骤:计算数据库线性扩展倍增因子factor=round(userid/scope),其中,round表示向下取整运算,useid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的用户编号,scope表示一个集群的数据记录容量数;计算hash切分因子remainder=useridmodscope,其中,mod表示取余数操作;计算remaindermodn+factorxn,得到数据记录所处数据库在其所处集群中的编号,以将该数据记录分配至该编号对应的数据库中,其中,n为一个集群所包含的数据库个数。于本发明一实施例中,基于预设表格拆分路由规则,将各个数据库中的数据记录分配至该数据库所包含的各个表格中包括以下步骤:获取数据库中的数据记录遵循某一规则的编号值;将该编号值对数据库所包含的表格的个数进行取余操作,得到数据记录所处表格在其所处数据库中的编号,以将该数据记录分配至该编号对应的表格中。于本发明一实施例中,所述该编号值采用数据记录的useid值或orderid值;其中,useid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的用户编号,orderid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的订单编号。同时,本发明还提供一种数据库水平分库分表系统,包括设置模块、数据库拆分模块和表格拆分模块;所述设置模块用于设定集群的个数、一个集群所包含的数据库个数以及一个数据库所包含的表格的个数;所述数据库拆分模块用于基于预设数据库拆分路由规则,将数据记录分配至各个集群所包含的各个数据库中;所述表格拆分模块用于基于预设表格拆分路由规则,将各个数据库中的数据记录分配至该数据库所包含的各个表格中。于本发明一实施例中,所述设置模块设定所述集群所包含的数据库个数与所述数据库所包含的表格的个数的取值相同。于本发明一实施例中,所述数据库拆分模块执行以下操作::计算数据库线性扩展倍增因子factor=round(userid/scope),其中,round表示向下取整运算,useid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的用户编号,scope表示一个集群的数据记录容量数;计算hash切分因子remainder=useridmodscope,其中,mod表示取余数操作;计算remaindermodn+factorxn,得到数据记录所处数据库在其所处集群中的编号,以将该数据记录分配至该编号对应的数据库中,其中,n为一个集群所包含的数据库个数。于本发明一实施例中,所述表格拆分模块执行以下操作:获取数据库中的数据记录遵循某一规则的编号值;将该编号值对数据库所包含的表格的个数进行取余操作,得到数据记录所处表格在其所处数据库中的编号,以将该数据记录分配至该编号对应的表格中。另外,本发明还提供一种服务器,包括上述任一所述的数据库水平分库分表系统。如上所述,本发明的数据库水平分库分表方法及系统、服务器,具有以下有益效果:(1)基于单表的行数,将数据库水平分割为若干分库,每个分库再分割为若干分表,从而减少单表的记录数量,提高查询所需要的响应时间;(2)部署方便、开发集成等成本低、无代码侵入性;(3)支持数据库线性扩展,无数据迁移痛苦,扩容成本低;(4)能够根据设定的存储量的大小主动扩容,而不是在数据库出现瓶颈时才实施,保证了数据库的安全可靠性;(5)只需迁移一次数据,即可实现原数据库到水平分库分表后的数据库的更新。附图说明图1显示为现有技术中数据库垂直分库的示意图;图2显示为本发明的数据库水平分库分表方法的流程图;图3显示为本发明的数据库水平分库分表系统的结构示意图;图4显示为本发明的服务器的结构示意图。元件标号说明1设置模块2数据库拆分模块3表格拆分模块具体实施方式以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。本发明的数据库水平分库分表方法及系统、服务器基于单表的行数,将数据库水平分割为若干分库,每个分库再分割为若干分表,从而减少单表的记录数量,提高查询所需要的响应时间,且支持数据库线性扩展,无数据迁移痛苦,扩容成本低。参照图2,本发明的数据库水平分库分表方法包括以下步骤:步骤s1、设定集群的个数、一个集群所包含的数据库个数以及一个数据库所包含的表格的个数。具体地,根据实际产生的数据记录的条数,确定集群的个数、一个集群所包含的数据库个数以及一个数据库所包含的表格的个数。在实际使用中,可根据实际的数据记录的条数进行数据库的线性扩展。需要说明的是,线性扩展的原则是保障单表响应性能的前提下,同时兼顾效益。以订单数据记录为例,假定目前订单表包括700万条记录。如表1所示,采用4x4拆分的集群时,单表存放记录为625万。表1、不同库维度和不同表维度下对应的单表存放容量总容量(亿)库维度表维度集群内表数量单表存放记录数(万)100,000,00044166,250,0001,000,000,000886415,625,00010,000,000,000161625639,062,500100,000,000,0003232102497,656,250按每月200万订单计算(目前月平均70万),十年订单可达到2.47亿条记录。散列到8x8个表存放,每张表存放的记录数为386万条记录不到,则单表的性能应该处在年轻状态,可满足实际查询等应用的需求。对于十年后的2.47亿条记录,如表2所示,十年中间扩容二次即可,即从4x4扩容至8x8,再扩容至16x16。表2、不同库维度和不同表维度下对应的单表存放容量总容量(亿)库维度表维度集群内表数量单表存放记录数(万)500,000,000441631,250,000500,000,00088647,812,500500,000,00016162561,953,125500,000,00032321024488,281优选地,集群所包含的数据库个数与数据库所包含的表格的个数的取值相同。步骤s2、基于预设数据库拆分路由规则,将数据记录分配至各个集群所包含的各个数据库中。具体地,基于预设数据库拆分路由规则,将数据记录分配至各个集群所包含的各个数据库中包括以下步骤:21)计算数据库线性扩展倍增因子factor=round(userid/scope),其中,round表示向下取整运算,useid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的用户编号,scope表示一个集群的数据记录容量数。其中,数据库线性扩展倍增因子factor也就是数据记录所处集群的编号。集群的编号从0开始,依次递增1。22)计算hash切分因子remainder=useridmodscope,其中,mod表示取余数操作。其中,remainder作为useid的hash值,用于后续的hash切分。23)计算remaindermodn+factorxn,得到数据记录所处数据库在其所处集群中的编号以将该数据记录分配至该编号对应的数据库中,其中,n为一个集群所包含的数据库个数。例如,需要将一个集群切分成4个数据库时,就用4这个数字对useid的hash值remainder进行取余数运算,也就是remaindermod4。这样的话每次运算就有四种可能:结果为0的时候,对应db1;结果为1的时候对应db2;结果为2的时候对应db3;结果为3的时候对应db4。这样一来就非常均匀的将数据分配到4个数据库中,有利于后续的数据检索。需要说明的是,数据库编号在各个集群中线性扩展,具有连续性。因此,通过上述步骤,实现了数据库的线性扩展,集群的线性扩容。同时,由于在集群内采用hash切分算法,使得分配至各个数据库的记录非常均匀。步骤s3、基于预设表格拆分路由规则,将各个数据库中的数据记录分配至该数据库所包含的各个表格中。具体地,基于预设表格拆分路由规则,将各个数据库中的数据记录分配至该数据库所包含的各个表格中包括以下步骤:31)获取数据库中的数据记录遵循某一规则的编号值。具体地,该编号值可以为上述的useid值,也可以是数据记录的orderid值。其中,orderid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的订单编号。需要说明的是,表格拆分路由规则和数据库拆分路由规则并不相关,故表格拆分路由可以采用orderid等参数。这是因为,在实际应用中,订单查询是常见的场景。按orderid查询的场景频率也很高。当然,也可以继续用userid值做hash切分。32)将该编号值对数据库所包含的表格的个数进行取余操作,得到数据记录所处表格在其所处数据库中的编号,以将该数据记录分配至该编号对应的表格中。在表格拆分路由规则中,仍然采用hash切分,从而保证了与数据库拆分路由规则的一致性。这使得数据记录水平切分后,易于进行水平扩展,同时还能兼顾按照orderid查询的性能,故极大地提升了用户体验。下面通过具体实施例来进一步阐述本发明的数据库水平分库分表方法。设定包括两个集群,每个集群包括四个数据库,每个数据库包括四个表格。每个集群所包含的数据记录的容量为10000。在该实施例中,具体的数据库水平分库分表方法如表3所示。表3、数据库水平分库分表方法的特定实施例当useid分别为9900、9901、19900和19901时,对应的数据记录分配结果如表4所示。表4、数据记录分配结果因此,通过本发明的数据库水平分库分表方法能够将各个数据记录对应地分配至各个具体的表格,实现了对原始数据库的数据记录的水平分库分表,且数据库线性扩展,无数据迁移痛苦,扩容成本低。另外,对于现有的数据库,需要通过数据迁移的方式将数据记录存储至水平分库分表后的数据库。该数据迁移只需进行一次,具体包括以下步骤:阶段一确定订单号等编码规则,在新老数据库插入时,判断新老数据库的订单号生成规则是否一致,若不一致就不能作为数据迁移截点,可以以时间为截点。在原有业务代码中,添加新分片的数据源写入,实现数据双落地。查询读取保持走老数据库源。事务成功判断以老数据库为准。确定迁移数据截点,原则上使得双落地和迁移这个时间窗口造成的数据差异性越小越好。比如拿双落功能上线时间点2016.12.3123.59.59,作为迁移历史数据的截点,这个时间点之前的数据,需要迁移。阶段二数据迁移结束,补偿时间窗口内新订单(还有出错补偿),插入前需要检查是否存在。运行一段时间,定时检查新老数据源中的数据一致性,及时发现原因,进行处理,以及补偿。历时一段时间,确定无差异性后切换读数据源变更,变更到分片数据源。事务成功以新数据库为准。阶段三切换对老数据源依赖的应用,关闭老数据源写,变成单落,只落分片的新数据库。老数据库可以作废。需要说明的是,进行数据迁移的工作需要满足以下要求:(1)需要对接老数据库和分片的新数据库;(2)能支持按输入sql语句迁移,即支持按时间或者id分段迁移;(3)导入出错时,记录orderid,以便补偿;(4)补偿迁移,需要在插入前做exists检查。刚开始大批量迁移,不需要做exists检查,否则会很影响效率。通过增加配置参数判断是否要判断。参照图3,本发明的数据库水平分库分表系统包括依次相连的设置模块1、数据库拆分模块2和表格拆分模块3。设置模块1用于设定集群的个数、一个集群所包含的数据库个数以及一个数据库所包含的表格的个数。具体地,根据实际产生的数据记录的条数,确定集群的个数、一个集群所包含的数据库个数以及一个数据库所包含的表格的个数。在实际使用中,可根据实际的数据记录的条数进行数据库的线性扩展。需要说明的是,线性扩展的原则是保障单表响应性能的前提下,同时兼顾效益。以订单数据记录为例,假定目前订单表包括700万条记录。如表1所示,采用4x4拆分的集群时,单表存放记录为625万。表1、不同库维度和不同表维度下对应的单表存放容量总容量(亿)库维度表维度集群内表数量单表存放记录数(万)100,000,00044166,250,0001,000,000,000886415,625,00010,000,000,000161625639,062,500100,000,000,0003232102497,656,250按每月200万订单计算(目前月平均70万),十年订单可达到2.47亿条记录。散列到8x8个表存放,每张表存放的记录数为386万条记录不到,则单表的性能应该处在年轻状态,可满足实际查询等应用的需求。对于十年后的2.47亿条记录,如表2所示,十年中间扩容二次即可,即从4x4扩容至8x8,再扩容至16x16。表2、不同库维度和不同表维度下对应的单表存放容量总容量(亿)库维度表维度集群内表数量单表存放记录数(万)500,000,000441631,250,000500,000,00088647,812,500500,000,00016162561,953,125500,000,00032321024488,281优选地,集群所包含的数据库个数与数据库所包含的表格的个数的取值相同。数据库拆分模块2用于基于预设数据库拆分路由规则,将数据记录分配至各个集群所包含的各个数据库中。具体地,数据库拆分模块2执行以下操作:21)计算数据库线性扩展倍增因子factor=round(userid/scope),其中,round表示向下取整运算,useid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的用户编号,scope表示一个集群的数据记录容量数。其中,数据库线性扩展倍增因子factor也就是数据记录所处集群的编号。集群的编号从0开始,依次递增1。22)计算hash切分因子remainder=useridmodscope,其中,mod表示取余数操作。其中,remainder作为useid的hash值,用于后续的hash切分。23)计算remaindermodn+factorxn,得到数据记录所处数据库在其所处集群中的编号以将该数据记录分配至该编号对应的数据库中,其中,n为一个集群所包含的数据库个数。例如,需要将一个集群切分成4个数据库时,就用4这个数字对useid的hash值remainder进行取余数运算,也就是remaindermod4。这样的话每次运算就有四种可能:结果为0的时候,对应db1;结果为1的时候对应db2;结果为2的时候对应db3;结果为3的时候对应db4。这样一来就非常均匀的将数据分配到4个数据库中,有利于后续的数据检索。需要说明的是,数据库编号在各个集群中线性扩展,具有连续性。因此,通过上述步骤,实现了数据库的线性扩展,集群的线性扩容。同时,由于在集群内采用hash切分算法,使得分配至各个数据库的记录非常均匀。表格拆分模块3用于基于预设表格拆分路由规则,将各个数据库中的数据记录分配至该数据库所包含的各个表格中。具体地,表格拆分模块执行以下操作:31)获取数据库中的数据记录遵循某一规则的编号值。具体地,该编号值可以为上述的useid值,也可以是数据记录的orderid值。其中,orderid表示与数据记录唯一对应且随数字记录逐个递增的数字记录的订单编号。需要说明的是,表格拆分路由规则和数据库拆分路由规则并不相关,故表格拆分路由可以采用orderid等参数。这是因为,在实际应用中,订单查询是常见的场景。按orderid查询的场景频率也很高。当然,也可以继续用userid值做hash切分。32)将该编号值对数据库所包含的表格的个数进行取余操作,得到数据记录所处表格在其所处数据库中的编号,以将该数据记录分配至该编号对应的表格中。在表格拆分路由规则中,仍然采用hash切分,从而保证了与数据库拆分路由规则的一致性。这使得数据记录水平切分后,易于进行水平扩展,同时还能兼顾按照orderid查询的性能,故极大地提升了用户体验。如图4所示,本发明还提供一种服务器,包括上述的数据库水平分库分表系统。综上所述,本发明的数据库水平分库分表方法及系统、服务器基于单表的行数,将数据库水平分割为若干分库,每个分库再分割为若干分表,从而减少单表的记录数量,提高查询所需要的响应时间;部署方便、开发集成等成本低、无代码侵入性;支持数据库线性扩展,无数据迁移痛苦,扩容成本低;能够根据设定的存储量的大小主动扩容,而不是在数据库出现瓶颈时才实施,保证了数据库的安全可靠性;只需迁移一次数据,即可实现原数据库到水平分库分表后的数据库的更新。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属
技术领域:
中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1