基于局部影响力计算的影响力阻断最大化方法与流程
本发明涉及社交网络技术领域,具体地,涉及一种基于局部影响力计算的影响力阻断最大化方法,可用于社交网络信息传播控制。
背景技术:
社交网络中的影响力传播分析对社交网络信息传播控制有重要作用。社交网络上谣言等恶意信息传播可能会对经济发展、社会稳定和国家安全等造成重大危害。为了使社交网络成为更可靠的信息传播平台,需要采取有效的策略来减少恶意信息传播的危害。当用户接受针对某个坏信息的好信息后,用户将不再接受该坏信息,因此可以在社交网络上发布好信息来遏制相应的坏信息的传播。传播坏信息的信源称为负面种子群,而传播好信息的信源称为正面种子群。
经对现有技术的文献检索发现,影响力阻断最大化问题在很多传播模型下是np-hard的,但是其目标函数在有些传播模型下具有子模性,因此贪心算法可以获得1-1/e的近似比。但是计算影响力的阻断范围是很困难的,通常采用蒙特卡洛模拟来估计影响力的阻断范围。然而,为了保证估计精度,需要进行大量蒙特卡洛模拟,因此需要耗费大量时间,不利于在大规模社交网络上即时采取应对恶意信息传播的策略。在影响力最大化相关研究中,有研究者提出在局部结构中近似快速计算影响力范围,影响力最大化和影响力阻断最大化问题有很多相似之处,影响力范围的快速计算方法为影响力阻断范围的快速计算提供了新思路。
给定一个负面种子群,影响力阻断最大化问题旨在发现一个正面种子群来发布正面信息,正面信息和负面信息竞争传播,使负面信息的传播范围的阻断最大。he等人于2012年在国际会议《sdm》上发表题为“influenceblockingmaximizationinsocialnetworksunderthecompetitivelinearthresholdmodel”的文章,文中研究竞争线性阈值模型下的影响力阻断最大化问题。他们证明该问题在竞争线性阈值模型下是np-hard,其目标函数在该模型下具有子模性,因此贪心算法能够获得1-1/e的近似保证比。贪心算法速度太慢,他们基于dag结构提出了速度更快的算法cldag,该算法利用了在dag结构中能够快速近似计算传播影响的性质。budak等人于2011年在国际会议《www》上发表题为“limitingthespreadofmisinformationinsocialnetworks”的文章,文中在竞争无意识独立级联模型(coicm)下研究传播阻断最大化问题。他们证明该问题在这两个模型下是np-hard,并且该问题的目标函数在两个模型下具有子模性,因此贪心算法能够获得1-1/e的近似保证比。但是贪心算法速度太慢,无法适用于大规模社交网络。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于局部影响力计算的影响力阻断最大化方法,速度更快,性能更好。
为达到上述目的,本发明所采用的技术方案如下:
一种基于局部影响力计算的影响力阻断最大化方法,包括如下步骤:
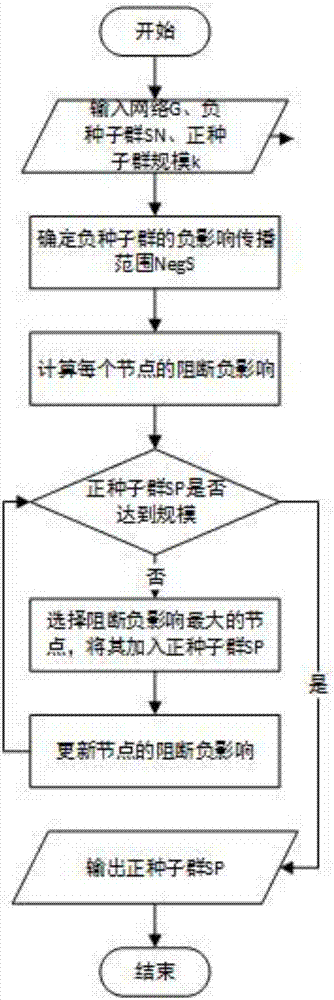
步骤1:输入网络g、负种子群sn、正种子群规模k,网络每条边赋予一个传播概率;
步骤2:确定负影响传播范围negs;
步骤3:计算所有节点的初始阻断负影响decinf(v);
步骤4:选择阻断负影响最大的节点u;
步骤5:将u加入正种子群sp,更新所有相关节点的阻断负影响decinf(v);
步骤6:判断正种子群是否达到规模,若达到规模,则执行步骤7;若没有达到规模,则执行步骤4;
步骤7:输出正种子群。
优选地,所述步骤2包括:
步骤2.1:对负种子群中每个节点u构造该节点的最大影响出树mioa(u,θ),最大影响出树由从该节点出发的所有传播概率大于一个阈值θ的最大影响路径的并集组成;
步骤2.2:负种子群中所有节点的最大影响出树的并集组成负影响传播范围。
优选地,所述步骤3包括:
步骤3.1:对负影响传播范围内的每个节点u,循环执行步骤3.2到3.6;
步骤3.2:构造该节点的最大影响入树miia(u,θ),最大影响入树由到该节点的所有传播概率大于一个阈值θ的最大影响路径的并集组成;
步骤3.3:计算u在miia(u,θ)中的负激活概率apn(u,sn,sp,miia(u,θ));
步骤3.4:对miia(u,θ)中的每个节点v,循环执行步骤3.5到3.6;
步骤3.5:计算u在正种子群为sp∪{v}时的负激活概率apn(u,sn,sp∪{v},miia(u,θ));
步骤3.6:按以下公式累加计算v的阻断负影响decinf(v):
decinf(v)+=apn(u,sn,sp,miia(u,θ))-apn(u,sn,sp∪{v},miia(u,θ))。
优选地,所述步骤5包括:
步骤5.1:构造选择的阻断负影响最大的节点u的最大影响出树mioa(u,θ);
步骤5.2:对mioa(u,θ)中的每个节点v,循环执行步骤5.3到5.5;
步骤5.3:构造v的最大影响入树miia(v,θ);
步骤5.4:对miia(v,θ)中的每个节点w,循环执行步骤5.5
步骤5.5:按以下公式更新w阻断负影响decinf(w):
decinf(w)-=apn(v,sn,sp,miia(v,θ))-apn(v,sn,sp∪{w},miia(v,θ));
步骤5.6:将节点u加入到正种子群sp;
步骤5.7:对mioa(u,θ)\{u}中的每个节点v,循环执行步骤5.8到5.12;
步骤5.8:构造v的最大影响入树miia(v,θ);
步骤5.9:计算v的负激活概率apn(v,sn,sp,miia(v,θ));
步骤5.10:对miia(v,θ)中的每个节点w,循环执行步骤5.11到5.12;
步骤5.11:计算v在正种子群为sp∪{w}时的负激活概率apn(v,sn,sp∪{w},miia(v,θ));
步骤5.12:按以下公式更新w阻断负影响decinf(w):
decinf(w)+=apn(v,sn,sp,miia(v,θ))-apn(v,sn,sp∪{w},miia(v,θ))。
与现有技术相比,本发明具有如下的有益效果:
1、根据本发明提供的基于局部影响力计算的影响力阻断最大化方法,具有和贪心算法相近的负影响阻断性能,但是比贪心算法快超过三个数量级。
2、根据本发明提供的基于局部影响力计算的影响力阻断最大化方法,在大部分网络上比其他基础的启发式算法的负影响阻断性能好。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明提供的基于局部影响力计算的影响力阻断最大化方法的流程图;
图2为本发明和多个已有方法之间在小规模网络email网络上的影响力阻断有效性性能对比图,其中:
图(a)为trivalency模型下负激活节点数随正种子数变化图;
图(b)为wc模型下负激活节点数随正种子数变化图;
图(c)各算法的运行时间;
图3为本发明和多个已有方法之间在三个大规模网络上的影响力阻断有效性性能对比图,其中:
图(a)为nethept网络上trivalency模型下负激活节点数随正种子数变化图;
图(b)为nethept网络上wc模型下负激活节点数随正种子数变化图;
图(c)为netphy网络上trivalency模型下负激活节点数随正种子数变化图;
图(d)为netphy网络上wc模型下负激活节点数随正种子数变化图;
图(e)为dblp网络上trivalency模型下负激活节点数随正种子数变化图;
图(f)为dblp网络上wc模型下负激活节点数随正种子数变化图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本邻域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
为了更清楚地说明本发明中的技术方案,列举如下的具体的实施例进一步说明:
根据本发明提供的基于局部影响力计算的影响力阻断最大化方法,包括如下步骤:
步骤s1、输入网络g、负种子群sn、正种子群规模k,为网络每条边赋予一个传播概率,传播概率表示当前时刻激活的节点在下一时刻激活其未被激活的邻居的概率;
步骤s2、根据负种子群中每个节点的最大影响出树mioa(u,θ)确定负影响传播范围negs;
所述的步骤s2,具体为:
步骤s21、对负种子群中每个节点u构造该节点的最大影响出树mioa(u,θ),最大影响出树由从该节点出发的所有传播概率大于一个阈值θ的最大影响路径的并集组成;
步骤s22、负种子群中所有节点的最大影响出树的并集组成负影响传播范围;
步骤s3、根据节点加入正种子群前后相关节点负激活概率的变化计算所有节点的初始阻断负影响decinf(v);
所述的步骤s3,具体为:
步骤s31、对负影响传播范围内的每个节点u,循环执行步骤32到36;
步骤s32、构造该节点的最大影响入树miia(u,θ),最大影响入树由到该节点的所有传播概率大于一个阈值θ的最大影响路径的并集组成;
步骤s33、计算u在miia(u,θ)中的负激活概率apn(u,sn,sp,miia(u,θ));
步骤s34、对miia(u,θ)中的每个节点v,循环执行步骤35到36;
步骤s35、计算u在正种子群为sp∪{v}时的负激活概率apn(u,sn,sp∪{v},miia(u,θ));
步骤s36、按以下公式累加计算v的阻断负影响decinf(v):
decinf(v)+=apn(u,sn,sp,miia(u,θ))-apn(u,sn,sp∪{v},miia(u,θ));
步骤s4、选择阻断负影响最大的节点u;
步骤s5、将u加入正种子群sp,更新所有相关节点的阻断负影响decinf(v);
所述的步骤s5,具体为:
步骤s51、构造选择的阻断负影响最大的节点u的最大影响出树mioa(u,θ);
步骤s52、对mioa(u,θ)中的每个节点v,循环执行步骤s53到s55;
步骤s53、构造v的最大影响入树miia(v,θ);
步骤s54、对miia(v,θ)中的每个节点w,循环执行步骤s55
步骤s55、按以下公式更新w阻断负影响decinf(w):
decinf(w)-=apn(v,sn,sp,miia(v,θ))-apn(v,sn,sp∪{w},miia(v,θ));
步骤s56、将节点u加入到正种子群sp;
步骤s57、对mioa(u,θ)\{u}中的每个节点v,循环执行步骤s58到s512;
步骤s58、构造v的最大影响入树miia(v,θ);
步骤s59、计算v的负激活概率apn(v,sn,sp,miia(v,θ));
步骤s510、对miia(v,θ)中的每个节点w,循环执行步骤s511到s512;
步骤s511、计算v在正种子群为sp∪{w}时的负激活概率apn(v,sn,sp∪{w},miia(v,θ));
步骤s512、按以下公式更新w阻断负影响decinf(w):
decinf(w)+=apn(v,sn,sp,miia(v,θ))-apn(v,sn,sp∪{w},miia(v,θ));
步骤s6、判断正种子群是否达到规模,若达到规模,则执行步骤s7;若没有达到规模,则执行步骤s4;
步骤s7、输出正种子群。
为使本实施例要解决的技术问题、技术方案和优点更加清楚,下面将结合附图对本实施例进行详细描述。
如图1所示,本实施例提供的基于局部影响力计算的影响力阻断最大化方法,包括如下步骤:
步骤s1、输入网络g、负种子群sn、正种子群规模k,为网络每条边赋予一个传播概率,传播概率表示当前时刻激活的节点在下一时刻激活其未被激活的邻居的概率;
步骤s2、根据负种子群中每个节点的最大影响出树mioa(u,θ)确定负影响传播范围negs,对负种子群中每个节点u构造该节点的最大影响出树mioa(u,θ),最大影响出树由从该节点出发的所有传播概率大于一个阈值θ的最大影响路径的并集组成,负种子群中所有节点的最大影响出树的并集组成负影响传播范围;
步骤s3、根据节点加入正种子群前后相关节点负激活概率的变化计算所有节点的初始阻断负影响decinf(v),对负影响传播范围内的每个节点u,构造该节点的最大影响入树miia(u,θ),最大影响入树由到该节点的所有传播概率大于一个阈值θ的最大影响路径的并集组成,计算u在miia(u,θ)中的负激活概率apn(u,sn,sp,miia(u,θ));对miia(u,θ)中的每个节点v,计算u在正种子群为sp∪{v}时的负激活概率apn(u,sn,sp∪{v},miia(u,θ)),按以下公式累加计算v的阻断负影响decinf(v):
decinf(v)+=apn(u,sn,sp,miia(u,θ))-apn(u,sn,sp∪{v},miia(u,θ));
步骤s4、选择阻断负影响最大的节点u;
步骤s5、将u加入正种子群sp,更新所有相关节点的阻断负影响,构造选择的阻断负影响最大的节点u的最大影响出树mioa(u,θ),对mioa(u,θ)中的每个节点v,构造v的最大影响入树miia(v,θ);对miia(v,θ)中的每个节点w,按以下公式更新w阻断负影响decinf(w):
decinf(w)-=apn(v,sn,sp,miia(v,θ))-apn(v,sn,sp∪{w},miia(v,θ));
将节点u加入到正种子群sp;对mioa(u,θ)\{u}中的每个节点v,构造v的最大影响入树miia(v,θ),计算v的负激活概率apn(v,sn,sp,miia(v,θ));对miia(v,θ)中的每个节点w,计算v在正种子群为sp∪{w}时的负激活概率apn(v,sn,sp∪{w},miia(v,θ)),按以下公式更新w阻断负影响decinf(w):
decinf(w)+=apn(v,sn,sp,miia(v,θ))-apn(v,sn,sp∪{w},miia(v,θ));
步骤s6、判断正种子群是否达到规模,若达到规模,则执行步骤s7;若没有达到规模,则执行步骤s4;
步骤s7、输出正种子群。
本实施例的有效性可以通过下面的仿真实验来进一步说明。需要说明的是,实验中应用的参数不影响本发明的一般性。
1)仿真条件:
cpuintel
2)仿真内容:
在四个真实网络上进行实验来评估算法的效率和效果。四个真实网络为email、nethept、netphy和dblp。roviraivirili大学的email网络将每个email地址当作一个节点,如果两个节点之间存在通信,则将它们连接起来。nethept、netphy和dblp是三个学术合作网络,节点表示作者,两个节点之间的边表示两个作者至少合作一篇论文。采用trivalency模型和wc模型来设置mcicm中的负面传播概率和coicm中的传播概率。在trivalency模型中,为每条边从集合{0.2,0.05,0.01}中随机选择一个传播概率,分别对应于高、中、低的传播概率。在wc模型中,边(u,v)的传播概率设置为1/dv,其中dv为节点v的入度。
本实施例在仿真实验中用cima-o表示。
将本实施例与4个其他的影响力阻断最大化方法进行仿真对比。这4个方法如下,budak等人于2011年在国际会议《www》上发表文章“limitingthespreadofmisinformationinsocialnetworks”中提出的greedy-h方法,该方法每次估计影响力时进行10000次蒙特卡洛模拟;budak等人于2011年在国际会议《www》上发表文章“limitingthespreadofmisinformationinsocialnetworks”中提出的proximity方法,该方法从负面种子的直接出邻居中选择正面种子,所有直接出邻居按负面激活概率排序,前k个负面激活概率最大的节点被选为正面种子;degree方法,该方法选择前k个度最大的节点作为正面种子;random方法,该方法随机选择节点作为正面种子。
仿真实验在小规模网络email网络上的影响力阻断有效性性能如图2的(a)~(c)所示,在trivalency模型下,cmia-o比random、degree、proximity和greedy-o分别好32.8%、4.8%、8.4%和3.0%;在wc模型下,cmia-o比random、degree、proximity和greedy-o分别好57.6%、7.5%、4.0%和6.3%;greedy-o花费超过6小时,而cmia-o只需要几秒钟,因此cmia-o方法比贪心算法快超过三个数量级。在三个大规模网络上的影响力阻断有效性性能如图3的(a)~(f)所示,在trivalency模型下,cmia-o平均比random、degree和proximity分别好105%、5.5%和13.5%;在wc模型下,cmia-o平均比random、degree和proximity分别好1000%、86.7%和17.7%。
本实施例提供的基于局部影响力计算的影响力阻断最大化方法,可用于社交网络信息传播控制。本实施例基于节点的局部结构近似计算节点的负激活概率;基于负激活概率计算节点的负阻断影响;迭代选择负阻断影响最大的节点作为正种子;更新节点的负阻断影响。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本邻域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!