一种基于深度学习的图片生成方法及生成对抗网络与流程
本发明涉及深度学习技术领域,特别是涉及一种基于深度学习的图片生成方法及生成对抗网络。
背景技术:
面部表情是人类情绪状态的最直观反映,是传递人类身体状态以及情感状态的重要媒介,是除语言交流之外主要交流方式。在人机交互过程中,表情的生成无疑能够为人们提供更便捷的沟通和服务。
深度学习作为目前机器学习的重要领域,在图像识别、语音分析等方向都有着重要应用。深度学习由神经网络演化而来,到目前为止,人们已经针对分类、检测、识别等各类不同的问题设计了多种行之有效的网络结构。其中在很多领域如人脸识别等已经超过了人眼识别的准确率。通俗地讲,深度学习通过在大量的样本中学习有价值的信息,从而得到了对目标分析判断的能力。
生成对抗网络(generativeadversarialnetwork)是深度学习的一个分支。其目的是生成与真实数据非常相似的数据。通过生成对抗网络,可以生成与训练样本具有同一性质但训练样本中没有的数据。生成对抗网络由生成网络和判别网络组成,生成网络的输入是随机的噪声信号,输出是图片。判别网络的输入是真实的图片和生成网络生成的图片,输出是图片属于真实图片的概率。即生成网络的作用是生成符合真实图片分布的图片,来欺骗判别网络,而判别网络的作用是分辨图片是由生成网络生成的还是真实图片,最终的目的是使得生成网络产生以假乱真的图片。然而,生成对抗网络尽管能够产生近似真实的图片,却无法根据类别产生需要的图片,这限制了生成对抗网络的应用。
技术实现要素:
为了弥补现有技术的不足,本发明提供一种基于深度学习的图片生成方法及生成对抗网络,其不仅可以生成图片,而且可以指定要生成的图片类别。
本发明的技术方案如下:
一种基于深度学习的图片生成方法,包括如下步骤:
(1)建立图片数据库:收集若干真实图片并对其进行分类和标注,每张图片具有唯一与之对应的类别标签k;
(2)构建生成网络g:在所述生成网络g中输入随机的噪声信号z和类别标签k组合而成的向量,将所述生成网络g生成的数据作为判别网络d的输入;
(3)构建判别网络d:所述判别网络d的损失函数由用于判断图片真假的第一损失函数和用于判断图片类别的第二损失函数组成;
所述第一损失函数如下:
其中,
所述第二损失函数如下:
其中,
(4)训练网络:
(41)训练所述判别网络d来最大化其输出属于真实图片或属于生成网络g生成的数据的概率;训练所述判别网络d来最大化
(42)训练所述生成网络g来最小化log(1-dt(g(z)));训练所述生成网络g来最大化
(5)生成需要的图片:将随机的的噪声信号z和类别标签k输入到经过步骤(4)训练好的生成网络g中,得到指定类别的图片。
优选地,所述步骤(41)具体包括如下步骤:
a、将真实图片集x输入到判别网络d,根据所述第一损失函数中的判别损失函数logdt(x)来更新判别网络d的参数;并输入图片对应的类别标签k,根据所述第二损失函数中的分类损失函数log(dc(xk)k)来更新判别网络d的参数;
b、将随机的噪声信号z和类别标签k作为生成网络g的输入,再将生成网络g生成的数据作为判别网络d的输入,根据所述第一损失函数中的判别损失函数log(1-dt(g(z)))来更新判别网络d的参数;并以对应的类别标签k,根据所述第二损失函数中的分类损失函数log(dc(g(z,c)c=k)k)来更新判别网络d的参数。
优选地,所述步骤(42)具体包括如下步骤:
将随机的噪声信号z和类别标签k作为生成网络g的输入,再将生成网络g生成的数据作为判别网络d的输入,根据所述第一损失函数中的判别损失函数log(1-dt(g(z)))来更新生成网络g的参数;并以对应的类别标签k,根据所述第二损失函数中的分类损失函数log(dc(g(z,c)c=k)k)来更新生成网络g的参数。
优选地,所述图片为人的面部表情图片。
一种用于所述的图片生成方法的基于深度学习的图片生成对抗网络,所述生成对抗网络包括生成网络和判别网络,其中:
所述生成网络包括第一输入层、第一全连接层、第一反卷积层、第一批归一化层和第一激活层,以随机的噪声信号和类别标签组合而成的向量作为所述第一输入层的输入,所述输入经过所述第一全连接层、所述第一反卷积层、所述第一批归一化层和所述第一激活层后生成数据;
所述判别网络包括第二输入层、第二反卷积层、第二批归一化层、第二激活层和第二全连接层,分别以所述生成网络生成的数据和真实图片作为所述第二输入层的输入,所述第二全连接层由用于判断图片真假的全连接层和用于判断图片类别的全连接层组成,所述第二输入层的输入经过所述第二反卷积层、第二批归一化层、第二激活层和第二全连接层后,得到指定类别的图片。
优选地,所述图片为人的面部表情图片。
与现有技术相比,本发明的有益效果包括:
现有的生成网络的输入是随机的噪声信号,类别信息隐藏在噪声中,使得无法得知噪声的哪一部分产生了类别信息,而通过本发明的方案,对生成网络的输入进行改进,将输入的信号分成两部分,一部分是类别信息,一部分是其他噪声信息;同时对判别网络进行改进,现有的判别网络只有一个判别图片真假的损失函数,本发明增加一个判断图片类别的损失函数,通过以上改进后,使得生成网络可用来生成指定类别的图片。因此,本发明不仅可以生成图片,而且能够通过输入生成网络的指定类别标签来生成对应类别的图片。
附图说明
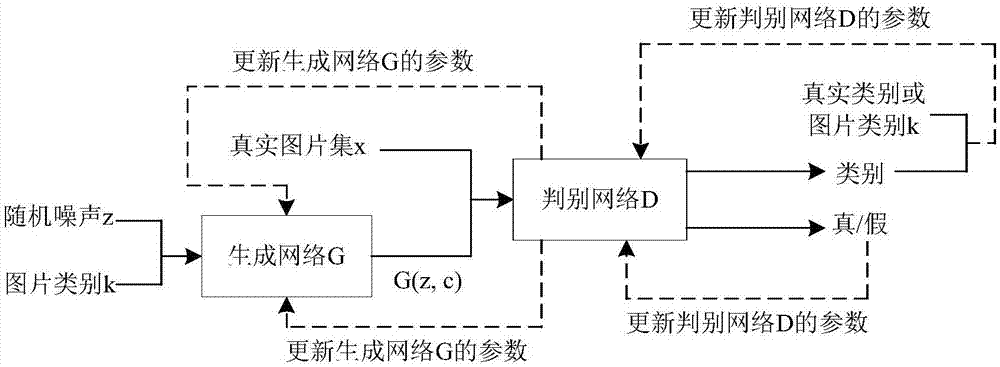
图1是本发明具体实施方式中基于深度学习的图片生成对抗网络的架构图;
图2是本发明具体实施方式中的生成对抗网络中的生成网络结构图;
图3是本发明具体实施方式中的生成对抗网络中的判别网络结构图;
图4是本发明具体实施方式生成的表情示例。
具体实施方法
下面对照附图并结合优选的实施方式对本发明作进一步说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
图1是本发明具体实施方式中基于深度学习的图片生成对抗网络的架构图,以生成人的面部表情图片为例,图片生成方法包括如下步骤:
(1)建立人脸表情数据库
收集大量人脸图片,按照不同的表情分类并标注,设表情种类为表情1、···表情n,则每张图片具有唯一与之对应的表情类别k。
(2)构建生成网络g
设输入的噪声信号为z和类别标签k,则生成网络g的输入是z和k组合而成的向量,生成网络g生成的数据将作为下方判别网络d的输入。生成网络包括第一输入层,第一全连接层(ip),第一反卷积层(fc),第一批归一化层(bn),第一激活层(relu),本例中的具体结构如图2所示,在本例中,生成网络g的输入(z+k组成的向量)经过第一全连接层后产生1024通道4*4分辨率的特征图,再分别经过第一反卷积层、第一批归一化层和第一激活层(本例中,可以经过四次反卷积处理)后,生成3通道64*64分辨率的特征图,并将其作为判别网络d的输入。
(3)构建判别网络d
判别网络d的损失函数由两部分组成,一是判断图片真假的第一损失函数,一是判断图片类别的第二损失函数。判别网络d包括第二反卷积层(fc),第二批归一化层(bn),第二激活层(relu),第二全连接层(ip),其中判别网络d中的第二全连接层由用于判断图片真假的全连接层1和用于判断图片类别的全连接层2组成,本例中的具体结构如图3所示,在本例中,以上由生成网络生成的3通道64*64分辨率的特征图经过第二反卷积层、第二批归一化层、第二激活层后输出1024通道4*4分辨率的特征图,再分别经过全连接1输出图片的类别、经过全连接2输出图片的真/假。
(4)训练网络
学习生成网络在真实图片集x的分布pg,首先定义了随机的噪声信号z的噪声变量pz(z),用g(z;θg)将其映射到数据空间。生成网络g是由参数θg构成的,判别网络d有两个输出,一个为判断图片来源的输出,即输出真/假,设为dt,另一个为判断图片类别的输出,即输出图片属于类别标签k的概率,设为dc。第一损失函数如下:
学习判别网络来判别生成的数据以及真实图片的类别标签k,c表示类别标签k的集合,用dc(xk)k来表示属于表情类别标签k的xk(xk表示真实表情图片集中的第k类表情的一个图片)被判别网络d分为k的概率,用dc(g(z,c)c=k)k来表示由生成网络产生的表情类别标签为k的生成图片由判别网络d分为k的概率。第二损失函数如下:
(41)训练判别网络d来最大化其输出属于真实图片或属于生成网络g生成的数据的概率;训练判别网络d来最大化
(42)训练生成网络g来最小化log(1-dt(g(z)));训练生成网络g来最大化
训练步骤具体如下:
1.更新判别网络d的参数
a、将真实图片集x输入到判别网络d,根据第一损失函数中的判别损失函数logdt(x)来更新判别网络d的参数;并输入图片对应的类别标签k,根据第二损失函数中的分类损失函数log(dc(xk)k)来更新判别网络d的参数。
b、将随机噪声信号z和类别标签k作为生成网络g的输入,再将生成网络g生成的数据作为判别网络d的输入,根据第一损失函数中的判别损失函数log(1-dt(g(z)))来更新判别网络d的参数;并以对应的类别标签k,根据第二损失函数中的分类损失函数log(dc(g(z,c)c=k)k)来更新判别网络d的参数。
2.更新生成网络g的参数
将随机的噪声信号z和类别标签k作为生成网络g的输入,再将生成网络g生成的数据作为判别网络d的输入,根据第一损失函数中的判别损失函数log(1-dt(g(z)))来更新生成网络g的参数;并以对应的类别标签k,根据第二损失函数中的分类损失函数log(dc(g(z,c)c=k)k)来更新生成网络g的参数。
(5)使用生成网络d生成需要的表情图片
将随机噪声信号z和需要的类别标签k,输入到以上训练好的生成网络g中,得到指定类别的表情图片。网络生成的表情图片如图4所示,其中从上往下数的第一排的表情表示惊讶,第二排的表情表示生气,第三排的表情表示微笑。
以上实施例是以人的面部表情图片为例进行的说明,但本领域技术人员应当理解,本发明不仅可以用来生成表情,也可以用来训练生成其他种类图片。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!