一种基于口令编码规则的分析方法及系统与流程
本发明涉及安全认证技术领域,尤其涉及一种基于口令编码规则的分析方法及系统。
背景技术:
由于现在犯罪分子,危险分子的犯罪通信手段数字化在加深,在交互使用的文字信息大多都进行了口令加密处理,即使安全机关捕获了犯罪罪证文件信息,但无法解密,不能获得有效的证据信息。因此需要能否分析出加密口令的编码规则的优先级来,以便极大提高破解加密文件密码的速度,尽快掌握犯罪分子的犯罪罪证,为进一步破案提高强有力的保障。
目前的加密文件破解大多采用常用密码进行穷举破解或者应用已有的密码库进行撞库破解。这种方式受限于拥有的常用口令和密码的数量,很难大范围内覆盖大部分加密使用的口令。
口令编码规则分析系统利用数据挖掘技术及自有规则分析算法对密码库进行统计分析,提取常用口令编码规则,提高口令的命中率,本系统属于信息安全,数据挖掘领域,目前还没有发现使用该技术进行口令分析的应用系统。
技术实现要素:
本发明的目的在于克服现有技术的不足,本发明提供了一种基于口令编码规则的分析方法及系统,可以自由扩充发掘规则,自由扩充密码库,编码规则自动调整。
为了解决上述技术问题,本发明实施例提供了一种基于口令编码规则的分析方法,所述分析方法包括:
根据密码项出现规律进行挖掘处理,获取密码项的关联规则;
根据所述密码项的常用编码规则进行迭代分层分析处理,获取第一常用编码规则;
对所述关联规则和所述第一常用编码规则进行规则提取处理,获取易分解编码规则。
优选地,所述根据密码项出现规律进行挖掘处理,包括:
对所述密码项口令中出现的单项进行拆分处理,获取拆分单项列表;
根据所述单项列表进行逐层搜索迭代处理,获取单项最小支持度阈值和最小置信度阈值;
根据所述单项最小支持度阈值和最小置信度阈值获取所述密码项的关联规则。
优选地,所述根据密码项出现规律进行挖掘处理还包括:
构建所述单项出现频率集合作为待学习集合;
采用神经网络模型的隐藏逻辑对所述待学习集合进行计算评判处理,获取评判结果;
将所述评判结果作为反馈进行迭代循环处理,当输出迭代处理结果没有新反馈时,迭代循环处理结束,将所述处理结果输出作为学习结果;
根据所述学习结果在新的密码库上进行数据挖掘处理,根据挖掘处理结果自动修正所述关联规则。
优选地,所述根据所述密码项的常用编码规则进行迭代分层分析处理,包括:
采用所述常用编码规则进行密码重复对称分析,获取密码重复分析结果;
对所述密码重复分析结果进行迭代分析处理,获取迭代分析结果;
将在所述密码重复分析和所述迭代分析中的不能识别密码进行遍历处理;
根据遍历处理结果进行编码处理,获取编码结果;
根据所述迭代分析结果和所述编码结果获取所述第一常用编码规则;
所述迭代分析处理至少包括迭代拼音分析处理、迭代英文单词分析处理和迭代日期格式分析处理。
优选地,所述对所述关联规则和所述第一常用编码规则进行规则提取处理,包括:
对所述关联规则和所述第一常用编码规则进行统计分析处理,获取统计分析结果;
根据所述统计分析结果进行优先级计算处理,获取规则优先级;
根据所述规则优先级进行易分解规则编码处理,获取易分解编码规则。
另外,本发明实施例还提供了一种基于口令编码规则的分析系统,所述分析系统包括:
关联规则获取模块:用于根据密码项出现规律进行挖掘处理,获取密码项的关联规则;
迭代分析模块:用于根据所述密码项的常用编码规则进行迭代分层分析处理,获取第一常用编码规则;
规则提取模块:用于对所述关联规则和所述第一常用编码规则进行规则提取处理,获取易分解编码规则。
优选地,所述关联规则获取模块包括:
拆分处理单元:用于对所述密码项口令中出现的单项进行拆分处理,获取拆分单项列表;
迭代单元:用于根据所述单项列表进行逐层搜索迭代处理,获取单项最小支持度阈值和最小置信度阈值;
关联规则获取单元:用于根据所述单项最小支持度阈值和最小置信度阈值获取所述密码项的关联规则。
优选地,所述关联规则获取模块还包括:
待学习集合构建单元:用于构建所述单项出现频率集合作为待学习集合;
计算评判单元:用于采用神经网络模型的隐藏逻辑对所述待学习集合进行计算评判处理,获取评判结果;
迭代循环处理单元:用于将所述评判结果作为反馈进行迭代循环处理,当输出迭代处理结果没有新反馈时,迭代循环处理结束,将所述处理结果输出作为学习结果;
关联规则修正单元:用于根据所述学习结果在新的密码库上进行数据挖掘处理,根据挖掘处理结果自动修正所述关联规则。
优选地,所述迭代分析模块包括:
重复对称分析单元:用于采用所述常用编码规则进行密码重复对称分析,获取密码重复分析结果;
迭代分析单元:用于对所述密码重复分析结果进行迭代分析处理,获取迭代分析结果;
遍历处理单元:用于将在所述密码重复分析和所述迭代分析中的不能识别密码进行遍历处理;
编码处理单元:用于根据遍历处理结果进行编码处理,获取编码结果;
规则获取单元:用于根据所述迭代分析结果和所述编码结果获取所述第一常用编码规则;
所述迭代分析处理至少包括迭代拼音分析处理、迭代英文单词分析处理和迭代日期格式分析处理。
优选地,所述规则提取模块包括:
统计分析处理单元:用于对所述关联规则和所述第一常用编码规则进行统计分析处理,获取统计分析结果;
优先级计算单元:用于根据所述统计分析结果进行优先级计算处理,获取规则优先级;
易分解规则编码处理单元:用于根据所述规则优先级进行易分解规则编码处理,获取易分解编码规则。
在本发明实施例中,采用本发明实施例可以根据密码编码习惯可以扩展出大量常用密码,覆盖量与已有库命中率进行优先级排序,极大极快破解加密密码,还可以自由扩充发掘规则,自由扩充密码库,编码规则自动调整;采用上述实施例,在对密码解码时密码覆盖量是撞库方式的百亿倍以上,密码命中率是撞库方式的50倍以上,破解效率是撞库方式的10倍以上。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见的,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1是本发明实施例中的基于口令编码规则的分析方法的方法流程示意图;
图2是本发明又一实施例中的基于口令编码规则的分析方法的方法流程示意图;
图3是本发明另一实施例中的基于口令编码规则的分析方法的方法流程示意图;
图4是本发明第四实施例中的基于口令编码规则的分析方法的方法流程示意图;
图5是本发明实施例中的基于口令编码规则的分析系统的系统结构组成示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
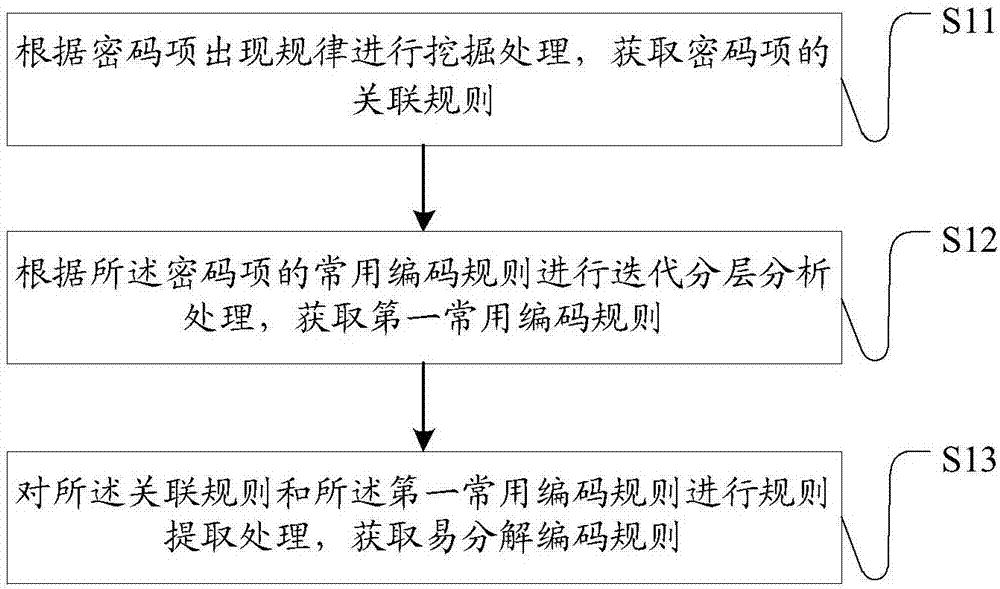
图1是本发明实施例中的基于口令编码规则的分析方法的方法流程示意图,如图1所示,所述分析方法包括:
s11:根据密码项出现规律进行挖掘处理,获取密码项的关联规则;
s12:根据所述密码项的常用编码规则进行迭代分层分析处理,获取第一常用编码规则;
s13:对所述关联规则和所述第一常用编码规则进行规则提取处理,获取易分解编码规则。
对s11作进一步说明:
首先获取密码项出现的规律,然后根据获取到的密码项出现的规律进行规则挖掘处理,经过挖掘处理之后,获取到密码项的关联规则。
具体的,根据获取到的密码项出现规律,对密码项进行拆分,获取拆分出来的密码项中出现的单项,形成单项列表,统计单项出现的频率,统计所有密码单项出现的频率表,对单项列表采用apriori算法进行处理,获取关联规则。
当有新的密码库加入时,在获得相关的关联规则后采用深度学习的方式进行学习,根据学习结果修改相关的关联规则;学习过程如下:构建所述单项出现频率集合作为待学习集合;采用神经网络模型的隐藏逻辑对所述待学习集合进行计算评判处理,获取评判结果;将所述评判结果作为反馈进行迭代循环处理,当输出迭代处理结果没有新反馈时,迭代循环处理结束,将所述处理结果输出作为学习结果;根据所述学习结果在新的密码库上进行数据挖掘处理,根据挖掘处理结果自动修正所述关联规则。
构建单项出现的频率集合,作为input,按照神经网络模型建模,把频率集合逐一作为input项输入,经过隐藏层逻辑进行计算,输出output项按照关联规则的结果进行评判,把评判结果作为反馈重新作为input进行迭代,多轮迭代当没有反馈输出后,学习完毕,output即为学习结果,输出结果在新库的基础上进行数据挖掘,自动修正关联规则。
对s12作进一步说明:
在上述的数据挖掘的基础上,根据所述密码项的常用编码规则进行迭代分层分析处理,获取第一常用编码规则。
具体的,这里的常用编码规则是常见的语法或者字典的规则,如有些密码是单个字母的重复则把其编码为(c){n},有的密码为3个拼音,如woshishui,则编码为(p)(p)(p),进行迭代分层分析,先进行密码重复对称分析,然后进行迭代拼音,英文单词,日期格式分析,当分析不再产生新项时分析结束,将不能识别的部分作为遍历处理,然后进行编码,缩短密码的长度,提取最频繁出现的常用编码规则,如(p)(p)(p)(d);ccccccccnnn(n){5}(p4)(id)(d8)(m);{}(),ccnp等为关键字,需要转义,转义符号为\;c:大写字母;c:小写字母;n:数字;p:代表拼音;e:英文单词;(c){n}表示把括号中的内容重复n次;{rv}取反如12344321=[1234]{rv};(34){r}头尾数字重复如88adfadsfsadfas88(88){r}(adfadsfsadfas);(s):常用数字123,456,147。。。。。。;(b)二进制;(z3)001002003,100200300。
对s13作进一步说明:
对所述关联规则和所述第一常用编码规则进行规则提取处理,获取易分解编码规则。
具体的,对上述获得的关联规则和第一常用编码规则进行统计分析,并计算出这些规则的优先级,根据统计分析和计算获得的优先级进行易分解规则编码,获取易分解编码规则;易分解规则编码包含以上所有规则,如(p)(p)(p)(d),三个拼音加一个生日[ilove](p)(p)(p)[1314]ilove,1314为固定项,中间加三个拼音(n)(n)(n)(n)(n)(n)包含所有6个数字的口令[woaini](c)(c)(c)固定项woaini加所有3个字母的组合。
图2是本发明又一实施例中的基于口令编码规则的分析方法的方法流程示意图,如图2所示:
s21:对所述密码项口令中出现的单项进行拆分处理,获取拆分单项列表。
具体的,对获取到的所有的密码项口令出现的密码单项进行拆分处理,获取单项,统计单项出现的频率,统计所有密码中的单项出现的频率表和单项列表。
s22:根据所述单项列表进行逐层搜索迭代处理,获取单项最小支持度阈值和最小置信度阈值。
具体的,根据获得的单项列表进行逐层搜索迭代处理(apriori算法),过程如:k项集用于探索(k+1)项集。首先,通过扫描事务(交易)记录,找出所有的频繁1项集,该集合记做l1,然后利用l1找频繁2项集的集合l2,l2找l3,如此下去,直到不能再找到任何频繁k项集。最后再在所有的频繁集中找出强规则,即产生用户感兴趣的关联规则。强规则即关联规则,既发现哪些单项在密码中频繁同时出现,如ilove和1314经常同时出现;其中,apriori算法具有这样一条性质:任一频繁项集的所有非空子集也必须是频繁的。因为假如p(i)<最小支持度阈值,当有元素a添加到i;支持度指a->b的支持度support=p(ab),指的是事件a和事件b同时发生的概率;置信度confidence=p(b|a)=p(ab)/p(a),指的是发生事件a的基础上发生事件b的概率;根据获取的支持度和置信度获取单项最小支持度阈值和最小置信度阈值。
s23:根据所述单项最小支持度阈值和最小置信度阈值获取所述密码项的关联规则。
具体的,同时满足单项最小支持度阈值和最小置信度阈值称为强规则,即是根据支持度和置信度获取强规则,其中强规则称为关联规则。
s24和s25的详细过程参照上述s12和s13,这里不再赘述。
图3是本发明另一实施例中的基于口令编码规则的分析方法的方法流程示意图,如图3所示,如下:
其中s31、s32、s33和s39的详细执行过程参照上述步骤中的s21、s22、s23和s13,这里不再赘述。
s34:采用所述常用编码规则进行密码重复对称分析,获取密码重复分析结果。
具体的,根据所述唱歌编码规则对密码重复进行对称分析,这里常用编码规则为常见语法或者字典规则,如有些密码是单个字母的重复则把其编码为(c){n},有的密码为3个拼音,先进行密码重复对称分析,然后获取密码重复分析结果。
s35:对所述密码重复分析结果进行迭代分析处理,获取迭代分析结果。
具体的,根据上述获取到的密码重复分析结果,进行迭代分析,其中迭代分析至少包括迭代拼音分析处理、迭代英文单词分析处理和迭代日期格式分析处理,当迭代分析不再产生新项时,分析结束,获取迭代分析结果。
s36:将在所述密码重复分析和所述迭代分析中的不能识别密码进行遍历处理。
在上述密码重复对称分析和迭代分析过程中,有些密码不能识别,对那些不能识别的密码进行遍历分析处理,该遍历处理可以为深度遍历或广度遍历。
s37:根据遍历处理结果进行编码处理,获取编码结果。
具体的,在上述遍历处理之后,进行编码处理,这样可以缩短密码的长度,获取编码结果。
s38:根据所述迭代分析结果和所述编码结果获取所述第一常用编码规则。
具体的,根据上述的迭代分析结果和编码结果,通过统计出现编码规则,提起最频繁出现的前5的编码规则,作为第一常用编码规则。
图4是本发明第四实施例中的基于口令编码规则的分析方法的方法流程示意图,如图4所示:
具体的,s41-s48参照上述步骤进行相应处理,这里不再赘述。
s49:对所述关联规则和所述第一常用编码规则进行统计分析处理,获取统计分析结果。
具体的,采用数理统计中的统计分析对所述关联规则和所述第一常用编码规则进行分析,然后获取统计分析结果。
s10:根据所述统计分析结果进行优先级计算处理,获取规则优先级。
具体的,采用常用的优先级计算方法,如运算符优先级计算方法;通过上述优先级计算,获取规则的优先级。
s11:根据所述规则优先级进行易分解规则编码处理,获取易分解编码规则。
具体的,根据优先级对上述规则进行易分解规则编码处理,易分解规则编码包含上述所有规则,如:(p)(p)(p)(d),三个拼音加一个生日;[ilove](p)(p)(p)[1314]ilove,1314为固定项,中间加三个拼音;(n)(n)(n)(n)(n)(n)包含所有6个数字的口令;[woaini](c)(c)(c)固定项woaini加所有3个字母的组合。
图5是本发明实施例中的基于口令编码规则的分析系统的系统结构组成示意图,如图5所示,所述分析系统包括:
关联规则获取模块11:用于根据密码项出现规律进行挖掘处理,获取密码项的关联规则;
迭代分析模块12:用于根据所述密码项的常用编码规则进行迭代分层分析处理,获取第一常用编码规则;
规则提取模块13:用于对所述关联规则和所述第一常用编码规则进行规则提取处理,获取易分解编码规则。
优选地,所述关联规则获取模块11包括:
拆分处理单元:用于对所述密码项口令中出现的单项进行拆分处理,获取拆分单项列表;
迭代单元:用于根据所述单项列表进行逐层搜索迭代处理,获取单项最小支持度阈值和最小置信度阈值;
关联规则获取单元:用于根据所述单项最小支持度阈值和最小置信度阈值获取所述密码项的关联规则。
优选地,所述关联规则获取模块11还包括:
待学习集合构建单元:用于构建所述单项出现频率集合作为待学习集合;
计算评判单元:用于采用神经网络模型的隐藏逻辑对所述待学习集合进行计算评判处理,获取评判结果;
迭代循环处理单元:用于将所述评判结果作为反馈进行迭代循环处理,当输出迭代处理结果没有新反馈时,迭代循环处理结束,将所述处理结果输出作为学习结果;
关联规则修正单元:用于根据所述学习结果在新的密码库上进行数据挖掘处理,根据挖掘处理结果自动修正所述关联规则。
优选地,所述迭代分析模块12包括:
重复对称分析单元:用于采用所述常用编码规则进行密码重复对称分析,获取密码重复分析结果;
迭代分析单元:用于对所述密码重复分析结果进行迭代分析处理,获取迭代分析结果;
遍历处理单元:用于将在所述密码重复分析和所述迭代分析中的不能识别密码进行遍历处理;
编码处理单元:用于根据遍历处理结果进行编码处理,获取编码结果;
规则获取单元:用于根据所述迭代分析结果和所述编码结果获取所述第一常用编码规则;
所述迭代分析处理至少包括迭代拼音分析处理、迭代英文单词分析处理和迭代日期格式分析处理。
优选地,所述规则提取模块13包括:
统计分析处理单元:用于对所述关联规则和所述第一常用编码规则进行统计分析处理,获取统计分析结果;
优先级计算单元:用于根据所述统计分析结果进行优先级计算处理,获取规则优先级;
易分解规则编码处理单元:用于根据所述规则优先级进行易分解规则编码处理,获取易分解编码规则。
具体地,本发明实施例的系统相关功能模块的工作原理可参见方法实施例的相关描述,这里不再赘述。
在本发明实施例中,采用本发明实施例可以根据密码编码习惯可以扩展出大量常用密码,覆盖量与已有库命中率进行优先级排序,极大极快破解加密密码,还可以自由扩充发掘规则,自由扩充密码库,编码规则自动调整;采用上述实施例,在对密码解码时密码覆盖量是撞库方式的百亿倍以上,密码命中率是撞库方式的50倍以上,破解效率是撞库方式的10倍以上。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
另外,以上对本发明实施例所提供的一种基于口令编码规则的分析方法及系统进行了详细介绍,本文中应采用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!