一种基于智能推导的方块苗文生成方法与流程
本发明涉及一种文字生成方法,尤其涉及一种基于智能推导的方块苗文生成方法。
背景技术:
当前操作系统处理表意文字时,通常是“逐字”进行编码和字符设计,字符数据存储量巨大,编码字符集亦难以瘦身。方块苗文是武陵山片区民间苗族文化的主要载体,是一种具有固定结构特性的表意文字,基本上都是合体字。因其信息处理研究起步很晚,unicode及其它字符集标准尚未为其分配码位。现有技术中,有一种基于构件组合运算表达式的方块苗文动态生成方法。该方法通过借助opentype字体技术,构造方块苗文合体字的字模,规划字体布局表,编写组合替换的映射脚本,就能在不占用unicode编码区间的情况下生成不同结构的苗文字符。然而,这种方法必须以方块苗文合体字的字符数据为基础,需要对每个方块苗文制作字模。无字模对应的方块苗文将无法显示。
技术实现要素:
本发明的目的在于提供一种基于智能推导的方块苗文生成方法,解决了字符数据存储量巨大,编码字符集难以瘦身的问题。
本发明是这样实现的,种基于智能推导的方块苗文生成方法包括以下步骤:
a:建立构件包围盒并对其进行归一化处理;
b:确定包围盒拓扑变换系数;
c:对构件包围盒进行变换操作;
d:建立对应推导过程的编码树;
e:建立智能推导模型;
f:根据智能推导算法生成方块苗文。
本发明的进一步技术方案是:所述步骤a为:给定一个苗文字符网格,其宽和高分别为w和h;以网格左上角为原点,建立一个x轴向右、y轴向下的直角坐标系;在此坐标系中,构件包围盒是由构件字符图像的左上顶点坐标(x,y)以及宽(w)和高(h)共同决定的一个最小外接矩形,可表示为一个四元组b:b=(x,y,w,h)。其中,x∈(0,w),y∈(0,h),w∈(0,w-x),h∈(0,h-y);并将构件包围盒归一化处理为:
本发明的进一步技术方案是:所述步骤b为:给定包围盒b=(x,y,w,h)和b'=(x',y',w',h'),将b变换为b’的拓扑变换系数用式(1)计算:
本发明的进一步技术方案是:所述步骤c中,计算目标构件在苗文中所处的位置和大小,涉及到居中、平铺和纵横比调整变换操作;
居中
调整后包围盒的宽和高不变,仅左上顶点坐标发生变化。给定包围盒b1=(x1,y1,w1,h1)和b2=(x2,y2,w2,h2),将b1沿x轴方向、y轴方向、同时沿x轴和y轴方向居中到b2中,三种情况下得到新包围盒b’1=(x’,y’,w1,h1)中的x’和y’分别用式(2)、(3)、(4)计算:
平铺
将上述包围盒b1沿x轴方向、y轴方向,同时沿x轴和y轴方向平铺到包围盒b2中,分别得到新包围盒b'=(x2,y1,w2,h1)、b'=(x1,y2,w1,h2)和b'=(x2,y2,w2,h2)。
纵横比调整
设原构件包围盒为b=(x,y,w,h),按纵横比为r进行调整后得到的包围盒为b’;那么,对于左右型构件,保持高度不变,按式(5)进行调整;对于上下型构件,保持宽度不变,按式(6)进行调整;对于外包构件或内含构件,高度和宽度都变化,如果h/w≤r,则按式(5)进行调整,否则,按式(6)进行调整。
b’=(x,y,h/r,h)(5)
b’=(x,y,w,w.r)(6)
本发明的进一步技术方案是:所述步骤d为:利用二叉树的递归性,把树中各结点数据的求解分解到简单的子树中求解,建立对应推导过程的编码树;编码树是推导树的符号化描述;编码树中,将左右型、上下型、内外型,以及侧围型的左上包、左下包和右上包这7种苗文结构,分别用字母“z”、“s”、“n”、“a”、“b”和“c”表示;将构件用其标准字符的unicode编码表示;2构件型苗文的编码树为1级结构,分2层;3构件型苗文的编码树为2级结构,分3层。
本发明的进一步技术方案是:所述步骤e为按3个层次建立苗文智能推导模型;顶层为完成编码树分解工作的子模块;中间层为针对不同结构苗文进行结构推导的子模块,用于完成编码树中各结点拓扑变换系数的求解工作;底层为构件纵横比调整的子模块;由于可以将左右结构和上下结构归为纵横结构一类,将内外结构和3种侧围结构归为包含结构一类,故中间层只针对纵横结构和包含结构设计两个结构推导子模块。
本发明的进一步技术方案是:所述步骤f包括以下算法:
顶层子模块的算法:
1)根据苗文所含构件的unicode编码序列及苗文结构类型,建立相应的苗文生成编码树;
2)对编码树进行深度优先的先根遍历,得到苗文的生成编码序列;
3)分析生成编码序列,按照流程,调用相应的结构推导子模块,推导出苗文所包含全部构件的变换参数;
4)根据获得的构件变换参数,将原始构件变换成苗文中的目标构件。纵横结构推导子模块的算法:
1)根据各构件的标准包围盒,确定其在整个苗文结构中的比重,并根据其在苗文结构中出现的次序,确定其最大可能包围盒;
2)对于左右结构,按式(2)将各个构件沿x轴方向居中到苗文结构的最大包围盒中;对于上下结构,按式(3)将各个构件沿y轴方向居中到苗文的最大包围盒中;
3)调用纵横比调整子模块调整各构件的纵横比,得到各构件在苗文中的包围盒;
4)利用式(1)计算各构件的变换系数。
包含结构推导子模块的推导算法:
1)取外包构件的最大包围盒作为其在苗文中的实际包围盒;
2)调用纵横比调整子模块,将内含构件的标准包围盒调整为其在苗文中的最大包围盒的大小;
3)将调整后内含构件的包围盒同时沿x轴和y轴方向平铺到外包构件的最大包围盒中,得到其在苗文中的实际包围盒;
4)利用式(1)计算出各构件的变换系数。
纵横比调整子模块的算法:
1)对纵横结构的构件,检查其纵横比值是否位于最小值和最大值之间。若是,则保持当前纵横比不变;否则,按式(5)将左右型构件的调整纵横比为平均值,按式(6)将上下型构件的纵横比调整为平均值;
2)对包含结构的构件,将其纵横比与平均值进行比较。若等于,则保持当前纵横比不变;若大于,则按式(6)将纵横比调整到平均值;若小于,则按式(5)将纵横比调整到平均值。
本发明的有益效果是:基于智能推导求得的目标构件字形数据所生成的方块苗文字形整齐规范,且不占用编码空间,能够满足实用性要求;该方法有3个特点:一是,基于构件变换来生成方块苗文的思想是该模型的核心;二是,利用二叉树的递归性来实现构件变换参数的求解,不但保证了方块苗文生成方法的简单有效性,而且体现了字符推导的智能性;三是,该模型中,方块苗文生成的智能推导所需的各类数据存放在独立的信息库中,使得方块苗文的语言特征得以从文字处理软件的程序逻辑中分离,便于日后进行软件功能的调整优化和扩展。
附图说明
图1是本发明提供的一种方块苗文结构示意图;
图2是本发明提供的一种识别方块苗文的dfa状态图;
图3是本发明提供的一种构件包围盒示意图;
图4是本发明提供的一种智能推导系统的结构示意图;
图5是本发明提供的一种基于智能推导的方块苗文生成方法的推导流程图;
图6是本发明提供的一种方块苗文字例c6的推导示意图;
图7是本发明提供的一种方块苗文字例c6的推导结果。
具体实施方式
实施例一:
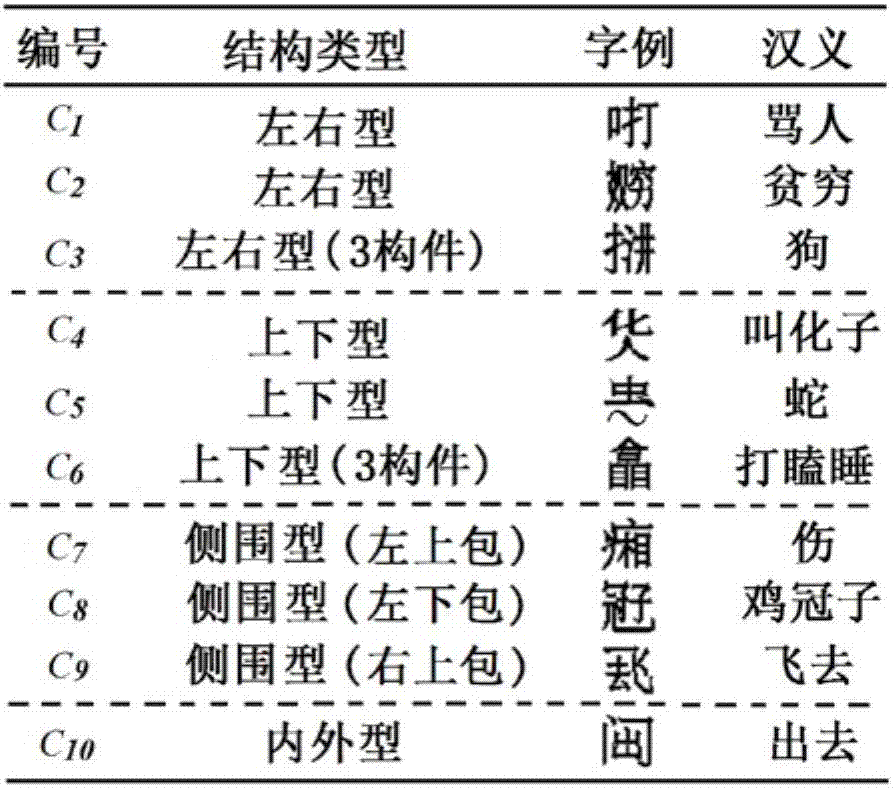
图1-图7为一种基于智能推导的方块苗文生成方法的示意图。方块苗文其结构大致分为图1所示的4类:左右型、上下型、侧围型和内外型。其中,侧围型又可分为左上包、左下包和右上包3种。根据方块苗文的造字原理和构字方式,当一个苗文由3个及3个以上部分构成时,其中的某两个或3个部分通常可组成一个简单汉字。此时,宜将此简单汉字视为一个构件。对已整理出的1129个方块苗文进行统计的结果表明,大部分苗文均可视为2构件型,仅个别左右型和上下型的苗文需当作3构件型处理。
方块苗文的构件可归为16类:左构件(cl)、右构件(cr)、上构件(cu)、下构件(cd)、左上外包构件(colu)、右下内含构件(cird)、左下外包构件(cold)、右上内含构件(ciru)、右上外包构件(coru)、左下内含构件(cild)、全外包构件(coa)、全内含构件(cia)、右左构件(crl)、右右构件(crr)、下左构件(cdl)和下右构件(cdr)。如果用sg代表方块苗文,ci代表构件字符(i=start,end,first,middle,final),则方块苗文的构成可用集合形式表示为sg={cstartcend}或sg={cfirstcmiddlecfinal}。其中,cstart={cl,cu,colu,cold,coru,coa},cend={cr,cd,cird,ciru,cild,cia},cfirst={cl,cu},cmiddle={crl,cdl},cfinal={crr,cdr}。
一个方块苗文由2-3个构件构成。基于16类构件,可构造出识别方块苗文的确定有穷自动机dfa(deterministicfiniteautomata)。该dfa用五元组表示为m=(k,a,f,s,z),其中:
1)k是状态有穷集,k={0,1,2,3,4,5,6,7,8,9};
2)a是输入符号有穷集,a={cl,cu,colu,cold,coru,coa,cr,cd,cird,ciru,cild,cia,crl,cdl,crr,cdr};
3)f是k×a→k上的映射集,f={f(0,cl)=1,f(0,cu)=2,f(0,colu)=3,f(0,cold)=4,f(0,coru)=5,f(0,coa)=6,f(1,crl)=7,f(1,cr)=9,f(2,cdl)=8,f(2,cu)=9,f(3,cird)=9,f(4,ciru)=9,f(5,cild)=9,f(6,cia)=9,f(7,crr)=9,f(8,cdr)=9};
4)s∈k,是初态,取值唯一,s=0;
5)
图2给出了该dfa的状态图表示。从图2中的初态0出发,到达终态9(用双圆圈表示)的任意路径上的构件字符序列合成一个方块苗文。
本文将作为方块苗文构件使用的汉字、汉字部首及纯粹符号的字符称为原始构件,将方块苗文显示时的构成部分称为目标构件。目标构件由原始构件经拓扑变换得到。当一个苗文所包含的全部目标构件均已由原始构件变换得到时,这个方块苗文就可直接由这些目标构件组合得到。
包围盒是一种能够正确反映复杂几何对象的位置和大小特性的简单且几何图形。为了简化构件变换操作,本文对苗文构件字符图像的处理转化为对其包围盒的处理。为此,给出苗文构件包围盒的定义如下:
定义1给定一个方块苗文字符网格,其宽和高分别为w和h。以网格左上角为原点,建立一个x轴向右、y轴向下的直角坐标系。在此坐标系中,构件包围盒是由构件字符图像的左上顶点坐标(x,y)以及宽(w)和高(h)共同决定的一个最小外接矩形(如图2所示),可表示为一个四元组b:b=(x,y,w,h)。其中,x∈(0,w),y∈(0,h),w∈(0,w-x),h∈(0,h-y);为了便于分析,根据拓扑不变性原理,将构件包围盒归一化处理为:
方块苗文的生成过程可转换为构件包围盒的计算过程。该过程就是通过计算确定拓扑变换系数,将原始构件的标准包围盒逐步调整为目标构件包围盒的过程。
给定包围盒b=(x,y,w,h)和b'=(x',y',w',h'),将b变换为b’的拓扑变换系数用式(1)计算:
因原始构件的标准包围盒信息可以直接从相应汉字字库中获取,故拓扑变换系数的确定问题就转化成目标构件包围盒的求解问题。
求解目标构件包围盒就是计算目标构件在苗文中所处的位置和大小,涉及到居中、平铺和纵横比调整等变换操作。
1)居中
居中系指沿某个坐标轴方向将一个包围盒调整到另一个包围盒的中间位置。调整后包围盒的宽和高不变,仅左上顶点坐标发生变化。给定包围盒b1=(x1,y1,w1,h1)和b2=(x2,y2,w2,h2),将b1沿x轴方向、y轴方向、同时沿x轴和y轴方向居中到b2中,三种情况下得到新包围盒b’1=(x’,y’,w1,h1)中的x’和y’分别用式(2)、(3)、(4)计算:
2)平铺
平铺系指将一个包围盒沿某一坐标轴方向扩展或压缩到另外一个包围盒中。将上述包围盒b1沿x轴方向、y轴方向,同时沿x轴和y轴方向平铺到包围盒b2中,分别得到新包围盒b'=(x2,y1,w2,h1)、b'=(x1,y2,w1,h2)和b'=(x2,y2,w2,h2)。
3)纵横比调整
纵横比是反映构件在苗文中形状的重要参数。不同类型的构件进行纵横比调整的方法不同。设原构件包围盒为b=(x,y,w,h),按纵横比为r进行调整后得到的包围盒为b’。那么,对于左右型构件,保持高度不变,按式(5)进行调整;对于上下型构件,保持宽度不变,按式(6)进行调整;对于外包构件或内含构件,高度和宽度都变化,如果h/w≤r,则按式(5)进行调整,否则,按式(6)进行调整。
b’=(x,y,h/r,h)(5)
b’=(x,y,w,w.r)(6)
求解目标构件包围盒的关键是获取拓扑变换系数和包围盒的位置及大小数据。本文采用“结构+构件”形式的二叉树表示苗文生成的推导过程。推导树的非叶结点代表苗文结构,叶结点代表具体构件。利用二叉树的递归性,即可把树中各结点数据的求解分解到简单的子树中去求解。编码树是推导树的符号化描述。编码树中,将左右型、上下型、内外型,以及侧围型的左上包、左下包和右上包这7种苗文结构,分别用字母“z”、“s”、“n”、“a”、“b”和“c”表示;将构件用其标准字符的unicode编码表示。2构件型苗文的编码树为1级结构,分2层。3构件型苗文的编码树为2级结构,分3层。图1中字例c6和c8的编码分别为“s5408z76ee76ee”和“b51a05b50”。
苗文智能推导模型可按图4所示的3个层次进行结构设计。顶层为完成编码树分解工作的子模块;中间层为针对不同结构苗文进行结构推导的子模块,用于完成编码树中各结点拓扑变换系数的求解工作。底层为构件纵横比调整的子模块。考虑到推导过程的相似性,可将左右结构和上下结构归为纵横结构一类,将内外结构和3种侧围结构归为包含结构一类。因此,中间层只需针对纵横结构和包含结构设计两个结构推导子模块。
顶层子模块首先按深度优先后序遍历整棵编码树,将编码树依次分解为多个子树。每分解出一棵子树,就将该子树交给相应的结构推导子模块求解,并用求解结果代替这棵子树。如此循环,直到所有子树求解完毕。
顶层子模块的算法设计如下:
1)根据苗文所含构件的unicode编码序列及苗文结构类型,建立相应的苗文生成编码树。
2)对编码树进行深度优先的先根遍历,得到苗文的生成编码序列。
3)分析生成编码序列,按照图5所示流程,调用相应的结构推导子模块,推导出苗文所包含全部构件的变换参数。
4)根据获得的构件变换参数,将原始构件变换成苗文中的目标构件。
纵横结构苗文的构件,在苗文中显现的形状不仅与其在苗文中出现的次序有关,也与其本身的大小有关。构件所占的比重同原始构件大小成正比。2构件型苗文构件的包围盒,直接取原始构件的标准包围盒。3构件型苗文构件的包围盒,是对生成树进行深度优先遍历得到的结果。各个构件的包围盒相关信息均保存在构件位置信息库中。该库具体包含有构件名、构件类型、结构名、位置数、各位置的最大包围盒列表等数据。求解时,直接从该库中取出相关数据作用于各个构件上,即可获得相应构件的最大包围盒。
纵横结构推导子模块的算法设计如下:
1)根据各构件的标准包围盒,确定其在整个苗文结构中的比重,并根据其在苗文结构中出现的次序,确定其最大可能包围盒。
2)对于左右结构,按式(2)将各个构件沿x轴方向居中到苗文结构的最大包围盒中;对于上下结构,按式(3)将各个构件沿y轴方向居中到苗文的最大包围盒中。
3)调用纵横比调整子模块调整各构件的纵横比,得到各构件在苗文中的包围盒。
4)利用式(1)计算各构件的变换系数。
包含结构苗文的共同特征是,由外包构件充当框架,内含构件嵌入到这个框架中,各构件的最大可能包围盒由外包构件决定。各个构件的包围盒相关信息亦保存在构件位置信息库中。求解时,直接从该库中取出相关数据作用于各个构件上,即可获得相应构件的最大包围盒。
包含结构推导子模块的推导算法设计如下:
1)取外包构件的最大包围盒作为其在苗文中的实际包围盒。
2)调用纵横比调整子模块,将内含构件的标准包围盒调整为其在苗文中的最大包围盒的大小。
3)将调整后内含构件包围盒同时沿x轴和y轴方向平铺到外包构件的最大包围盒中,得到其在苗文中的实际包围盒。
4)利用式(1)计算出各构件的变换系数。
苗文智能推导时,各结构推导子模块需调用纵横比调整子模块,根据从构件纵横比信息库中读取的相关数据,按不同的调整方式对构件进行调整。构件纵横比信息库包含了构件名、构件类型、结构名、构件出现次数,以及纵横比的最小值、最大值、平均值、方差等数据。
纵横比调整子模块的算法设计如下:
1)对纵横结构的构件,检查其纵横比值是否位于最小值和最大值之间。若是,则保持当前纵横比不变;否则,按式(5)将左右型构件的调整纵横比为平均值,按式(6)将上下型构件的纵横比调整为平均值。
2)对包含结构的构件,将其纵横比与平均值进行比较。若等于,则保持当前纵横比不变;若大于,则按式(6)将纵横比调整到平均值;若小于,则按式(5)将纵横比调整到平均值。
基于上述算法,苗文的生成求解过程可分解为从编码树叶结点开始的一系列一级结构的字符生成求解。下面以苗文c6为例来说明苗文生成的智能推导求解过程,据图6,苗文c6的构件变换系数求解步骤描述如下:
1)确定结构级数。c6有2级结构:顶级结构为“s”,末级结构为“z”。
2)将末级结构分离出来,当作一个伪苗文求解,如图7(a)所示。此时的生成编码序列为“z76ee76ee”。利用纵横结构推导子模块,求出两个子构件“76ee”和“76ee”在伪苗文中的包围盒。
3)将伪苗文(表示为“#1”)视为一个构件,并入上一级结构中,如图7(b)所示。此时,的生成编码序列为“s5408#1”。利用纵横结构推导子模块,求出两个构件“5408”和“#1”作为c6中目标构件显现的包围盒。
4)根据式(1),计算苗文各构件的拓扑变换系数。
5)将各构件按上述拓扑变换系数进行变换得到相应的目标构件,将这些目标组合到一起,得到苗文字符c6。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!