一种基于LRFMD模型的共享交通客户价值分析方法与流程
本发明属于数据挖掘技术领域,具体涉及一种基于lrfmd模型的共享交通客户价值分析方法。
背景技术:
信息时代的来临使得企业营销焦点从产品中心转变为客户中心,客户关系管理成为企业的核心问题。客户关系管理的关键问题是客户分类,通过客户分类,区分无价值客户、高价值客户。由于共享交通的飞速发展,共享交通平台客户的规模增大,客户背景、行为特征的不同,准确的客户分类结果是企业优化营销资源分配的重要依据,客户分类越来越成为客户关系管理中亟待解决的关键问题之一。
现有的针对共享交通客户行为分类的方法主要是基于经验分类方法、统计分析方法和数据挖掘方法。经验分析方法一般由决策者根据自己经验对客户进行类别划分,具有很强的主观性,细分的结果不客观,缺少说服力。基于统计方法的客户分类是一种量化研究,根据对客户属性的特征统计结果进行客户类别划分,细分的结果往往与分类标准具有极强的关联性,如果分类标准不合理,分类的结果也不合理。基于数据挖掘的方法能从大量的、不完全的、有噪声的、模糊的原始数据中,挖掘出有用、可信、新颖的信息,其中k-means聚类是一种重要的数据挖掘方法,但是传统的k-means聚类方法并不能从海量数据、大量的特征属性准确依据有效的特征属性挖掘到想要的信息,并且算法本身对数据的预处理、初始聚类中心的选取、聚类类别数的确定要求很高。
技术实现要素:
鉴于上述,本发明提出了一种基于lrfmd模型的共享交通客户价值分析方法,能够根据建模的数据及筛选的指标对客户进行分类,具有划分精度高的优点。
一种基于lrfmd模型的共享交通客户价值分析方法,包括如下步骤:
(1)从数据库中抽取大量客户的租用驾驶数据,并基于分析观测窗口将这些驾驶数据分为历史数据集和增量数据集;
(2)对历史数据集和增量数据集进行预处理,包括数据清洗、属性规约以及数据变换,从而得到每个客户的lrfmd向量;所述lrfmd向量由lrfmd五个指标组成:l表示客户注册时间start_time距分析观测窗口结束时间load_time的月数,r表示客户最后一次租用驾驶结束时间end_time距分析观测窗口结束时间load_time的月数,f表示客户在分析观测窗口内的租用驾驶次数,m表示客户在分析观测窗口内的累计行驶里程,d表示客户在分析观测窗口内每次租用驾驶所享受的平均折扣金额;
(3)利用客户的lrfmd向量通过基于客户价值的lrfmd模型进行客户分群,进而对得到的各个客户群进行特征分析,以识别出有价值的客户。
所述步骤(1)的具体实现过程为:首先,选定过去的某一时间点load_time,以时间点load_time为结束时间,截取宽度为一年的时间段作为分析观测窗口,使分析观测窗口内有租用驾驶记录的所有客户租用驾驶数据作为历史数据集;然后,使时间点load_time至当前时间点区间内有租用驾驶记录的所有客户租用驾驶数据作为增量数据集。
所述步骤(2)中数据清洗的具体实现过程为:首先,丢弃存在缺失值的租用驾驶记录,即租用驾驶记录中某列属性存在空值,则删除该条记录;然后,丢弃行驶距离大于0且消费金额以及折扣金额均等于0的租用驾驶记录。
所述步骤(2)中属性规约的具体实现过程为:从客户的租用驾驶数据中提取出以下8个属性:客户id、客户的注册时间start_time、客户最后一次租用驾驶的结束时间end_time、分析观测窗口的结束时间load_time、每次租用驾驶的行驶里程current_miles、每次租用驾驶的总消费金额cost、每次租用驾驶的实际支付金额money、每次租用驾驶的折扣金额bonus。
所述步骤(2)中数据变换的具体实现过程为:首先,基于属性规约所得到的8个属性计算出每个客户的lrfmd五个指标,然后,对这五个指标进行z-score标准化处理后即得到lrfmd向量。
所述步骤(3)中通过基于客户价值的lrfmd模型进行客户分群,即采用改进型k-means算法根据lrfmd向量对客户进行聚类分群,将客户分成k类,对应k个客户群,k为设定的类别数且为大于1的自然数。
所述改进型k-means算法的具体过程如下:
3.1将所有客户的lrfmd向量组成样本集,初始情况下通过计算从样本集中选取出k个lrfmd向量作为聚类中心;
3.2逐个将样本集中的lrfmd向量按最小距离原则分配给k个聚类中心,形成k个种群;
3.3重新构建每个种群的中心点,使其作为种群新的聚类中心;若每个种群新聚类中心与旧聚类中心的距离均小于阈值,则计算结束,以当前的k个种群作为分类结果,否则转为执行步骤3.2。
所述步骤3.1中初始选取聚类中心的具体过程如下:
3.1.1随机从样本集中选取k个lrfmd向量,并重复k次,得到k×k个lrfmd向量;
3.1.2对这k×k个lrfmd向量进行聚类,聚成k类,并计算出每类的中心点;
3.1.3构建这k个中心点的中心点o,取样本集中与中心点o距离最近的lrfmd向量作为备选点,并保存该距离;
3.1.4重复执行步骤3.1.1~3.1.3,得到k个备选点及其与中心点o的距离,根据距离与概率正相关的原则随机从这k个备选点中选取出一个备选点,作为初始化的聚类中心;
3.1.5重复执行步骤3.1.1~3.1.4,从而得到k个聚类中心。
所述步骤(3)通过分群得到多个客户群后,采用增量数据集通过同样的过程对分类结果进行验证以及修正。
优选地,所述步骤(3)通过分群将客户分成5类,对应如下5个客户群,然后根据雷达图来分析总结每个客户群的优势特征和弱势特征;
重要保持客户群,该类客户d值较低,r值低,但f值或m值高;
重要发展客户群,该类客户d值较低,r值低,且f值或m值低;
重要挽留客户群,该类客户l值高,r值高,但f值和m值不低;
一般客户群,该类客户d值很高,r值较高,但f值或m值低;
低价值客户群,该类客户d值很高,r值很高,但f值或m值很低。
本发明客户价值分析方法从数据库进行选择性抽取与新增数据抽取分别形成历史数据与增量数据;对两个数据集进行数据探索分析与预处理,包括数据缺失值与异常值的探索分析,数据的属性规约、清洗和变换;本发明利用已完成的数据预处理的建模数据,结合具体业务,创造性地提出了基于客户价值lrfmd模型进行客户分群,对各个客户群进行特征分析,识别出有价值的客户;本发明针对分类结果得到的不同价值客户,可采用不同的营销手段,提供定制化服务,提高用户的满意度,促进企业的发展。
附图说明
图1为本发明客户价值分析方法的流程示意图。
图2为本发明k-means聚类算法的流程示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
如图1所示,本发明基于lrfmd模型的共享交通客户价值分析方法,包括如下步骤:
(1)从萝卜车后台数据库抽取数据,以2017/1/12为结束时间,选取宽度为一年的时间段作为分析观测窗口,抽取观测窗口内有驾驶记录的所有客户的详细数据形成历史数据;对于后续新增的客户详细信息,以后续新增数据中最新时间点作为结束时间,采用上述同样的方法进行抽取,形成增量数据;从萝卜车系统内的客户基本信息、驾驶记录、消费信息以及积分信息等详细数据中,抽取2016/1/12-2017/1/12内所有客户的详细数据,总共有563489条记录,其中包括了客户id号、注册时间、交易时间、行驶距离、性别、年龄、支付形式等30个属性。
(2)对两个数据集进行探索分析,主要是对数据进行缺失值与异常值分析,分析出数据规律以及异常值,通过对数据观察发现原始数据中某列属性存在空值即为缺失值,行驶距离大于0,消费金额等于0,折扣金额等于0的记录为异常值;接着对数据进行预处理,本实施方式主要采用数据清洗、属性规约和数据变换的预处理方法;数据清洗即丢弃存在缺失值及异常值的记录;属性规约即选择与lrfmd模型指标相关的8个属性:客户id号user_id、注册时间start_time、最近一次驾驶结束时间end_time、观测窗口结束时间load_time、行驶历程current_miles、消费金额cost、实际支付金额money、折扣金额bonus,删除与其不相关、弱相关或者冗余的属性,例如性别、交易识别码、刹车次数、支付类型等属性;进而将数据转成“适当”的格式,以适应挖掘任务及算法需要,本实施方式采用的数据变换方式为属性构造和数据标准化,由于原始数据中并没有给出lrfmd五个指标,需要通过原始数据提取这五个指标,具体计算方式如下:
l=load_time-start_time
r=load_time-end_time
f=count
m=sum(current_miles)
d=avg(bonus)
其中:count为单个用户在观测的时间窗口内的驾驶次数,sum(current_miles)为单个用户在观测时间窗口内的驾驶距离之和,avg(bonus)为单个用户在观测时间窗口内所享受折扣的平均值。
从以上5个指标的数据提取后,对每个指标数据分布情况进行分析,需要对数据进行标准化处理,z-score标准化处理公式如下:
其中:x为某一用户某一属性的取值,μ为该属性下所有用户的均值,σ为该属性下所有用户的均方差。
(3)模型构建,客户价值分析模型构建主要由两个部分构成,第一部分根据萝卜车客户5个指标数据,对客户进行聚类分群;第二部分结合业务对每个客户群进行特征分析,分析其客户价值,并对每个客户群进行排名。
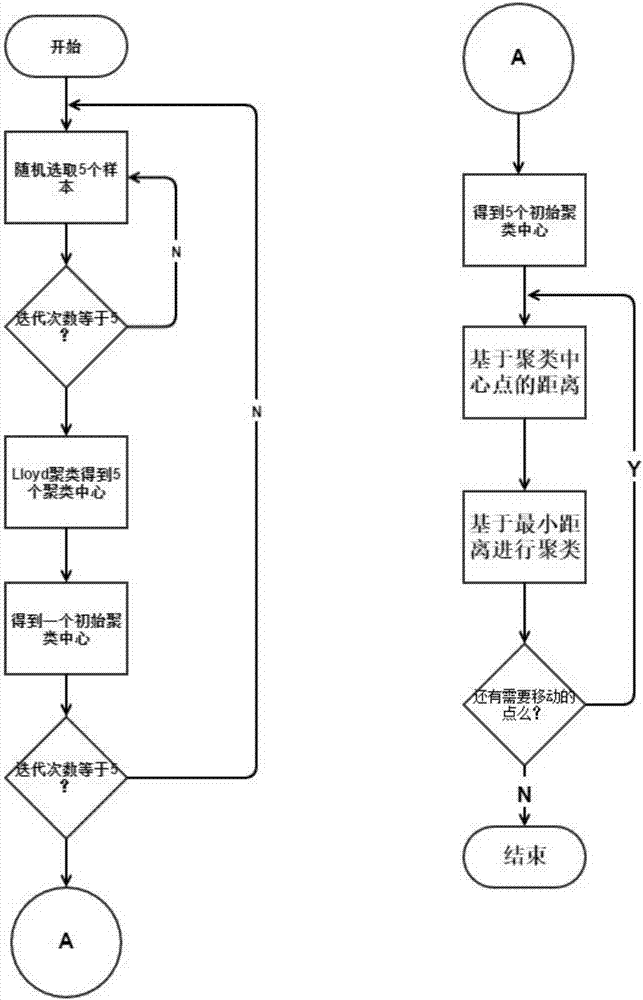
第一部分,本实施方式采用改进型k-means聚类算法对客户数据进行客户分群,聚成5类,具体步骤如图2所示:
a1.从客户集中选择5个客户作为质心;改进型k-means聚类算法的改进之处即在于初始质心的选取,具体过程为:
a1-1随机选择5个点(客户),重复5次,得到5×5个点;
a1-2对这5×5个点进行聚类,聚成5类,每类均有中心点;
a1-3构建这5个中心点的中心点o,使中心点o作为初始随机点;
a1-4取客户集中与该初始随机点距离最近的点,并保存该距离;
a1-5重复执行步骤a1-1~a1-4,得到k个距离,根据距离与概率正相关的原则随机从中选取一个距离对应的点,作为初始聚类中心;
a1-6重复执行步骤a1-1~a1-5,得到k个初始质心。
a2.对剩余的每个用户测量其到每个质心的距离,并把它归到最近的质心的类;距离计算公式为:
a3.重新计算已经得到的各个类的质心;
a4.迭代步骤a2~步骤a3直至新的质心与原质心相等或距离小于指定阈值,算法结束。
第二部分,特征分析的具体步骤如下:
b1.针对聚类结果,画出客户群特征分析雷达图;
b2.根据步骤b1的雷达图,画出客户群特征分析描述表;
b3.根据步骤b2的客户群特征分析描述表将客户定义为五个等级的客户类别:重要保持客户、重要发展客户、重要挽留客户、一般客户、低价值客户;
b4.根据步骤b3定义的客户类别,将客户群进行排名及客户类别确定。其中需要根据雷达图总结出特征分析表,提取出客户群的优势和弱势特征,具体表现如下:
重要保持客户:这类客户的平均折扣率(d)较低,最近驾驶萝卜车(r)低,驾驶次数(f)或者驾驶里程(m)高;
重要发展客户:这类客户的平均折扣率(d)较低,最近驾驶萝卜车(r)低,但是驾驶次数(f)或者驾驶里程(m)低;
重要挽留客户:这类客户入会时间(l)长,最近驾驶萝卜车(r)长,但是总的行驶里程(m)和驾驶次数(f)不低;
一般客户与低价值客户:这类客户的平均折扣率(d)很高,较长时间没有驾驶萝卜车(r)高,驾驶次数(f)或者驾驶里程(m)低。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!