一种用于背景建模的训练图像序列的收敛方法与流程
本发明属于计算机视觉技术领域,尤其涉及一种运用于训练背景模型时的训练数据的收敛方法。
背景技术:
在计算机视觉领域,背景建模主要用于对前景目标的检测与识别,更进一步地可对检测的目标进行一些高级操作,如姿态判断、动作分析等。因此,背景模型的建立作为首要任务,其准确性对后续的应用起到至关重要的作用。从灵长类动物对目标(即前景)的理解来看,不同于背景且具有可移动性的对象,如动物、交通工具、短暂停留的物体等,都可以理解为前景。帧差法(differencingofadjacentframes)作为最初的背景模型是由rameshjain和h.-h.nagel(文献1)提出的,根据对前景的理解,对于在静态场景中检测运动目标会有效果,但是如果背景中存在动态物体的话,该方法将不能适应,因为该模型没有获取到背景在时间轴上的演变属性。在现实场景中,尤其在室外,动态的背景对象如风中摇摆的树木、荡漾的水面、摆动的旗帜、喷泉和电梯等,都不是一帧图像可以刻画和描述的,而是需要对连续多帧图像的学习来实现对背景的“理解”,即对模型参数的学习。根据模型的不同,需要求解的参数也各不相同。
统计学方法以对象的发生数据为基础,在研究对象的不确定性(uncertainty)方面具有优势,目前主要分为有参估计和无参估计。单高斯模型的代表pfinder(文献2)是christopherwren等人提出的有参模型,在背景学习时通过将一段相对较长的“空背景(emptybackground)”视频帧作为数据源来学习模型关于每个像素的颜色属性,如方差等。在此基础上,对其扩展的混合高斯模型(mog)得到众多科研人员的青睐和长足的发展,最近的归一化区域混合高斯模型(regularizedregionmog,rrmog)(文献3)通过引入一个动量项(momentumterm)来加快rrmog的收敛速度,并证明该速率为o(1/k2),因此提高了算法的性能。然而,该方法假定了一些局限性条件,如估计函数含有一个lipschitz连续梯度,且具有光滑、可凸和可微属性等,这在面对现实场景中的数据时有些不具可操作性。ahmedelgammal等人提出的无参估计模型(文献4)在处理复杂场景如杂乱的树林、波动的物体等时,可以不用关心参数问题,并具有很高的灵敏度。在此基础上,pierre-lucst-charles等人(文献5)通过引入时空信息和lbsp(localbinarysimilaritypattern)特征来增加模型的鲁棒性,并使用循环反馈的方式来更新模型的参数,从而使得模型具有更高的适应性。这些方法都取得了不错的结果,但是,在模型训练时,它们都是简单地采用最近的一段长度为n的背景数据作为训练数据,基于这样的一种假设:只有最近的信息才会对当前产生影响,过去的信息不会产生影响。这其中忽略了一个问题:最近的信息有可能存在重复,即模型训练有可能不需要n个数据,因此存在着效率问题;同时,忽略了噪声在模型训练时的影响。
相关文献:
【文献1】r.jainandh.nagel,“ontheanalysisofaccumulativedifferencepicturesfromimagesequencesofrealworldscenes”,ieeetrans.patternanalysisandmachineintelligence,1979.
【文献2】c.wren,a.azarbayejani,t.darrel,anda.pentland,“pfinder:realtimetrackingofthehumanbody”,ieeetrans.patternanalysisandmachineintelligence,1997.
【文献3】varadarajan,sriram,etal.“fastconvergenceofregularizedregion-basedmixtureofgaussiansfordynamicbackgroundmodelling”,computervisionandimageunderstanding136(2015):45-58.
【文献4】elgammal,ahmed,davidharwood,andlarrydavis.“non-parametricmodelforbackgroundsubtraction”,computervision—eccv2000(2000):751-767.
【文献5】st-charles,pierre-luc,guillaume-alexandrebilodeau,androbertbergevin.“subsense:auniversalchangedetectionmethodwithlocaladaptivesensitivity”,ieeetransactionsonimageprocessing24.1(2015):359-373.
技术实现要素:
针对以往背景模型在训练时没有考虑训练数据的个数而产生的效率问题。本发明以统计学中关于随机变量的数字特征为理论基础,以实际发生的数据为数据基础,提出了一种用于判断一个位置上的灰度值在多长时间内达到收敛状态的方法—双重方差法(bivariation);同时为了避免噪声的干扰,提出了一种简单且有效地去除噪声的方法。
本发明所采用的技术方案是:一种用于背景建模的训练图像序列的收敛方法,其特征在于,包括以下步骤:
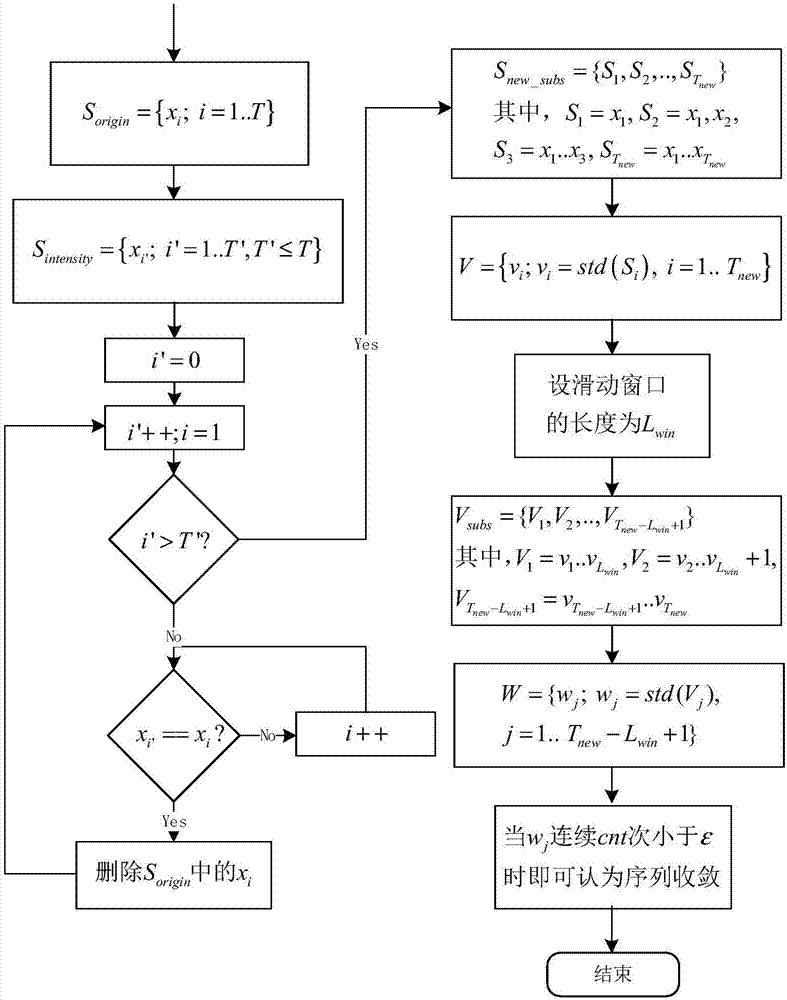
步骤1:获取场景位置p在时间t内的灰度值信息,设为序列sorigin={xi;i=1…t},其中xi表示i时刻该位置的灰度值;
步骤2:按照灰度值大小排序并获得灰度值序列sintensity(length(sintensity)≤length(sorigin)),其中length(sintensity)表示排序后序列sintensity的长度,length(sorigin)表示原始序列sorigin的长度;
步骤3:每次都从sorigin的第一个位置开始搜索每一个sintensity中的元素第一次出现的位置并删除,得到去噪后的序列snew,长度为tnew;
步骤4:对去噪后的序列snew,计算方差序列v:{vi;vi=std(x1…xi),i=1…tnew},其中std(x1…xi)表示标准差;
步骤5:设置滑动窗口,长度为lwin;
步骤6:计算方差序列w:{wj;wj=std(vj…vj+lwin-1),j=1…tnew-lwin+1};
步骤7:判断收敛;
当方差wj连续cnt次低于预设值ε时,则序列w在j-lwin+1处开始收敛。
与现有技术相比,本发明具有以下的创新与优势:
本发明提出了一种双重方差法来计算训练数据的收敛性,依据设置的阈值(cnt和ε)获得最佳的收敛点,从而减少重复训练数据参与模型的训练,提高了训练效率。本发明提出的灰度值个数减一法可以有效地去除噪声的干扰,提高了训练数据的质量,从而保证了最后获得的模型的准确性。
附图说明
图1是本发明实施例的流程图;
图2是本发明实施例中在一个背景模型数据集中随机选取的两个位置的灰度值分布的示意图;
图3是图2中两个位置灰度值的方差的结果图;
图4是图2中两个位置灰度值的双重方差的结果图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种用于背景建模的训练图像序列的收敛方法,包括以下步骤:
步骤1:获取每个位置的每个通道在时间t内(针对不同的背景数据集,通常都会有一个默认的训练长度)的灰度值信息,由于针对每个通道的处理方式一样,即以位置p的一个通道为例,记灰度序列为:
sorigin={xi;i=1…t}(1);
其中xi表示i时刻该位置的灰度值;
步骤2:根据灰度值大小对其进行排序,得到如x′11,x′12,x'21,x'22,x'23,...,x't6序列,其中,每个灰度值下标的第一个数字表示灰度值标签,第二个数字表示相同灰度值的时间顺序。如x't6则表示有6个相同的灰度值x't。提取灰度值序列:
sintensity={xi';i'=1…t',t'≤t}(2);
即序列x′11,x'21,...,x't1。
步骤3:去噪方法,即灰度值个数减一法;
对sintensity中的每一个元素xi',从头遍历sorigin,将第一次遇到的xi'从sorigin中删除并结束此次遍历,直到sintensity中的所有元素都访问完毕。记去噪后的序列为:
snew={xi;i=1…tnew,tnew=t-t'}(3);
步骤4:对去噪后的序列snew进行方差求解;
首先,每次从snew的第一个元素开始,分别以长度为1,2,…,tnew形成tnew个子序列snew_subs={s1,s2,..,stnew};然后对snew_subs求取方差v:
{vi;vi=std(x1…xi),i=1…tnew}(4);
其中std(x1…xi)表示标准差;
步骤5:为了发现数据的规律性(这里主要是收敛性),并以一个统一的标准来判断收敛点,采用滑动窗口的方式在v上滑动求取方差,设置窗口长度为lwin;
步骤6:对方差序列v进行方差求解,首先,从v的第一个元素开始,以lwin为固定长度,依次向方差序列v的右侧移动,直到位置为tnew-lwin+1,此时得到最后一个子序列,其末尾元素为vtnew。最后,得到方差子序列
{wj;wj=std(vj…vj+lwin-1),j=1…tnew-lwin+1}(5);
步骤7:通过双重方差的求解,将收敛的判断标准统一为0,即达到0时可以认为序列已经收敛。但是现实中很少有这样标准的数据,因此,将判断标准设置为一个很小的正常数ε。同时,为了保证收敛的稳定性,设置收敛次数cnt,即达到cnt次收敛时即可认为序列已经稳定,且此时的收敛点为j-lwin+1。
以下通过实验验证本发明方法的准确性和高效性。
通过在公开数据集changedetection.net(n.goyette,p.-m.jodoin,f.porikli,j.konrad,andp.ishwar,changedetection.net:anewchangedetectionbenchmarkdataset,inproc.ieeeworkshoponchangedetection(cdw-2012)atcvpr-2012,providence,ri,16-21jun.,2012)上选取一个分类shadow下的busstation视频序列,随机选取两个位置p1(217,332)和p2(15,52)为例,其灰度值的分布如图2所示。从图中可以看出,这两个位置的灰度分布呈现出一定的规律性,如p1是在47上下以幅度2左右进行震动,p2是在54上下以幅度4左右进行震动。因此,可以利用方差来发现其中的规律。它们的方差如图3所示。经过一段时间的波动,p1大约在50帧处开始趋于平稳,方差约为0.95,p2大约在60帧处开始稳定,方差大约为3.9。从此处可以看出一个问题,即对于多个数据序列,没有统一的标准来判断其是否稳定,或收敛。因此,双重方差的目的就是让有规律变化但偏离程度不同的随机变量可以以统一的标准(接近0的一个正常数ε)收敛。图4展示的是p1和p2的双重方差。如果设定阈值ε为0.04的话,则这两点的收敛位置分别大约为30帧和60帧处。如果设置为其他值,则收敛的位置随之而变。ε值越大,包容性则强,序列收敛的早;ε值越小,则显得越苛刻,序列收敛的晚。
综上所述,本发明通过定义并求解随机变量的双重方差来“归一化”其收敛标准,即让有规律变化但偏离程度不同的随机变量可以以统一的标准判断其收敛,该方法有效地避免了“重复”训练数据的运算,提高了模型的效率;并且在求解过程中先对训练数据进行了去噪处理,该方法简单有效,提高了数据的质量,从而保证了模型的准确性。
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!