一种基于分布式数据库的全文搜索引擎的制作方法
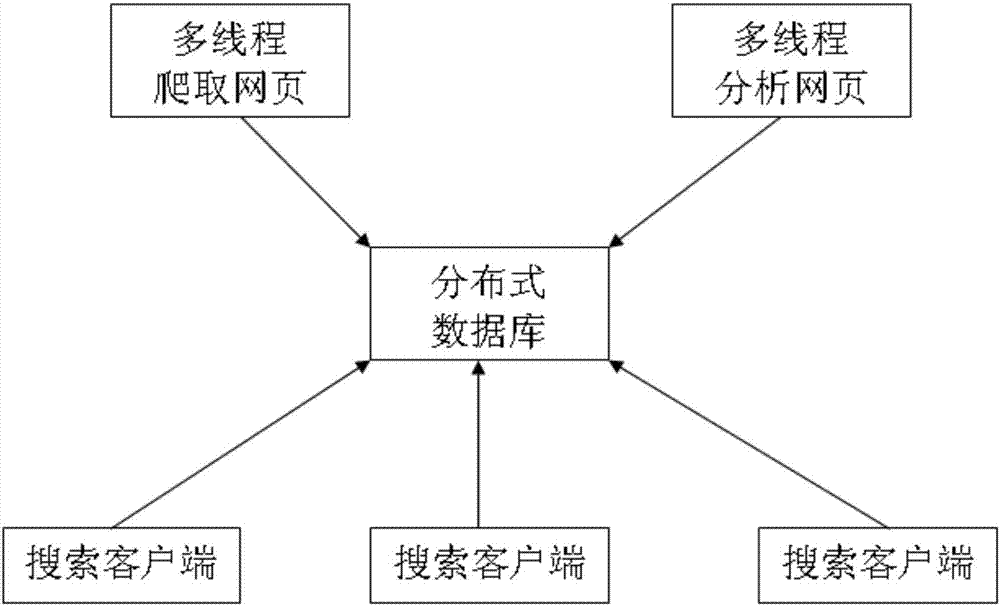
本发明基于分布式数据库和全文搜索引擎领域技术领域,尤其涉及一种基于分布式数据库的全文搜索引擎。
背景技术:
随着计算机和互联网的大力普及和发展,例如数千万用户每天产生亿级别的数据,迫切需要分布式的存储和全文搜索工具。目前的方案:文档和单词都是按照文档来进行分布式存储的,查询的时候是按照单词来查询的,所以需要到所有节点上查询。
技术实现要素:
为了解决上述的技术问题,本发明的设计思路是将文档和单词分开,按照不同的策略存储,在查询的时候,只需要到单词所在的节点进行查询,即本发明的目的是提供一种能够提高搜索效率、又具有很强的扩展能力的基于分布式数据库的全文搜索引擎。
为了达到上述的目的,本发明采用了以下的技术方案:
本发明提出一种基于分布式数据库的全文搜索引擎,包括索引和搜索,其中:
索引包括下载文档、分析文档、以及将文档和文档经过分词后得到的单词存入分布式数据库;搜索是根据用户的输入,查询分布式数据库,返回包含用户输入的、按照得分进行排序的结果文档。其中:搜索引擎的绝大部分内容都没有变,变的只是存储使用了分布式数据库,所以导致索引部分和搜索部分发生了变化。
作为优选:文档id、文档内容、文档地址等存入分布式数据库中对应节点的文档表中,对文档进行分词和分析,得到单词id、单词、单词所在的文档id以及单词的频率存入到分布式数据库中对应节点的单词表中。
作为优选:文档id以及单词id是通过将文档地址的hash值以及文档分词后的每个单词的hash值转换为整数得到,然后对文档id、单词id分别对分布式数据库内的节点数取余数,得到文档对应的节点id以及单词对应的节点id。
其中:文档地址是文档的标识,并非网页内容本身,文档id是通过文档地址的hash值转换来的;单词的内容本身是单词的标识,单词的id通过单词内容本身的hash值转换来的。
作为优选:搜索的基本步骤如下:对用户的输入进行分词,得到单词和单词之间的逻辑关系,针对每个单词到对应节点的单词表中搜索;
根据单词表的文档id和单词逻辑关系计算结果文档id的集合,并且根据文档id提取文档内容;同时相同文档id内所有单词的频率逆文档频率之和构成文档的得分,文档按照得分从高到低排名;
其中:单词的频率逆文档频率为单词的频率和语料库中单词的逆文档频率相乘结果;
单词之间的逻辑关系是指与、或、非、及三种逻辑运算的任意组合。
作为优选:文档存储在分布式数据库相关节点的文档表中,单词存储在分布式数据库相关节点的单词表中,单词的逆文档频率存储在分布式数据库相关节点的语料库表中,其中:文档与单词的关系是:一份文档是由若干个单词组成,将一份文档进行分词即可得到若干个单词;其中:所谓分词是指将由若干个单词组成的一份文档分为这若干个单词。
作为优选:分布式数据库中节点的文档表基本属性包括文档id、文档地址、文档内容等,文档表的均衡字段采用文档id;分布式数据库中节点的单词表基本属性包括单词id、单词、单词所在的文档id、单词的频率,单词表的均衡字段采用单词id;
分布式数据库中节点的语料库表基本属性包括单词id、单词、单词的逆文档频率,语料库表的均衡字段采用单词id。
与现有技术相比,本发明的有益效果是:
本发明由于采用了以上的技术方案,从结构上来说,本发明使用三张表(即单词表、文档表和语料库表),采用不同的均衡字段,单词表用单词id分表,文档表用文档id分表,语料库表用单词id分表,从而在查询的时候,按照单词进行查询,单词表按照单词id作为均衡字段,只需要到指定的某些节点上执行即可,其搜索效率大大地提高。
使用了分布式数据库作为存储介质,可以利用其强大的缓存和sql计算功能,另外分布式数据库自身带有分布式功能,使其具有很强的扩展能力。
附图说明
图1是本发明的整体架构示意图;
图2是本发明中分布式数据库的架构示意图。
具体实施方式
下面结合附图对本发明的具体实施方式做一个详细的说明。
如图2所示,分布式数据库中节点的文档表、单词表以及语料库表的设计,具体如下:
●文档表
其中:
doc_download_status
为0:表示初始状态,还没有开始下载;
为1:表示正在下载,就是说某个线程查询时,这个值为1,则跳过下载;
为2:下载完成的时候,更新记录,表示下载完成;此时下载内容,下载时间也会更新。
doc_parse_status
为0:表示初始状态,还没有开始分析存储;
为1:表示正在分析存储,就是说某个线程查询时,这个值为1,则跳过分析存储;
为2:分析存储完成的时候,更新记录,表示分析存储完成;此时分析存储内容,分析存储时间也会更新。
下载时间和分析存储时间是指下载完成的时间和分析存储完成的时间。
●单词表
●语料库表
文档索引过程:包括下载和分析存储
1、多线程下载过程:
根据文档地址得到文档id,查询文档表,看是否有这个文档id的记录
——没有,插入初始记录(文档id,文档地址,空,空,0,空,0,空),(标识11)更新doc_download_status=1,开始下载,看下载是否成功
成功,更新doc_download_status=2,下载内容,下载时间也会更新
失败,更新doc_download_status=0,下载内容,下载时间不会更新——有,查询doc_download_status的值
0,从(标识11)开始
1,跳过这个文档的下载
2,看下载时间是否是定时更新下载的周期(如一个月)之前
是,从(标识11)开始
否,跳过这个文档的下载
2、多线程分析存储
查询文档表中的记录,查询doc_parse_status的值
0,(标识12)更新doc_parse_status=1,开始分析存储,看分析存储是否成功——成功,更新doc_parse_status=2,分析存储内容,分析存储时间也会更新,然后将分析存储的单词结果(单词id,单词,文档id,单词频率)插入到单词表中——失败,更新doc_parse_status=0,分析存储内容,分析存储时间不会更新
1,跳过这个文档的分析存储
2,看分析存储时间是否是定时更新分析存储的周期(如一个月)之前
是,从(标识12)开始
否,跳过这个文档的分析存储
文档搜索过程:
1、如图1所示,对用户在搜索客户端中输入的关键词进行分词,得到单词和单词之间的逻辑关系(即与、或、非、及三种逻辑运算的任意组合),针对每个单词到对应节点的单词表中搜索;
2、根据单词表的文档id和单词逻辑关系计算结果文档id的集合,并且根据文档id提取文档内容;按照文档id进行分组,所有单词的频率逆文档频率之和构成文档的得分,文档按照得分从高到低排名;其中:单词的频率逆文档频率为单词的频率和语料库中单词的逆文档频率相乘结果。
以下结合具体实施例子,具体展开本发明一种基于分布式数据库的全文搜索引擎。
说明
●节点数为100,编号从0到99
●爬取的文档数为1000万
●语料库是基于100亿个文档建立,建立1000亿个单词的信息
●文档的id通过使用文档地址的md5,取md5的4个长整数之和,作为文档的id
●单词的id通过计算单词的md5,取md5的4个长整数之和,作为单词的id
为了示例,选择3篇个文档和8个单词作为演示用
文档的id和主要单词的id
索引
文档表的数据如下:
经过分词,统计单词的出现次数,得到分词表的数据如下,(出现次数为0的记录实际不存在,仅为说明)
语料库,收集的文档数10亿
搜索
例如用户输入“机器学习开源“
●第一步对用户输入,得到两个单词和单词之间的关系
机器学习并且开源
●第二步对每个单词进行查询,得到如下的记录
●第三步,根据单词之间的关系合并文档,并且计算每个文档的得分(得分=每个单词的得分之和,每个单词的得分=出现次数*逆文档频率)
●第四步,根据文档id查询文档内容,按照得分从高到低返回给用户,并且搜索词高亮显示
需要强调的是:以上仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!