一种基于TCMU虚拟磁盘的多数据副本一致性保证方法与流程
本发明涉及数据存储技术领域,尤其涉一种基于tcmu虚拟磁盘的多数据副本一致性保证方法及其装置。
背景技术:
分布式存储系统都是通过网络通信,网络的不稳定性容易造成后端数据不一致,并且分布式存储系统一般包含较多的服务器主机和磁盘数量,硬件损坏的概率也比较高。如果不能快速检测和保证数据副本的一致性,分布式存储系统的数据完整性和高可用性就大大降低。现有技术数据副本一致性检验过于复杂,数据修复过慢,占用过高的网络带宽,并且在有写i/o的情况下很难达到数据一致性。
技术实现要素:
为解决以上问题,本发明提出一种基于快照技术的多数据副本一致性检测和数据修复方法。
具体方案为:
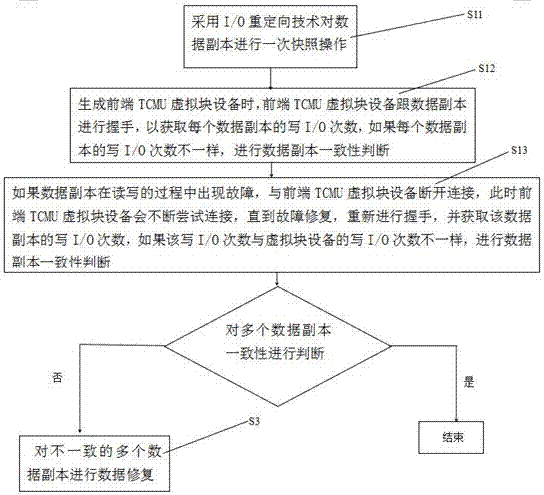
一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,应用于分布式存储系统中,分布式存储系统前端tcmu虚拟块设备对应后端存储设备的多个数据副本,其特征在于,所述方法包含以下步骤:
s1、对多个数据副本一致性进行判断,如果不一致,进入s3;
s3、对不一致的多个数据副本进行数据修复;
其中,所述步骤s1,具体为:
s11、采用i/o重定向技术对数据副本进行一次快照操作;
s12、生成前端tcmu虚拟块设备时,前端tcmu虚拟块设备跟数据副本进行握手,以获取每个数据副本的写i/o次数,如果每个数据副本的写i/o次数不一样,进行数据副本一致性判断;
s13、如果数据副本在读写的过程中出现故障,与前端tcmu虚拟块设备断开连接,此时前端tcmu虚拟块设备会不断尝试连接,直到故障修复,重新进行握手,并获取该数据副本的写i/o次数,如果该写i/o次数与虚拟块设备的写i/o次数不一样,进行数据副本一致性判断。
2、根据权利要求4所述的一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,其特征在于,所述方法还包括:
在步骤s3之前还有步骤s2,判断在对数据进行一致性检验时是否创建了快照,如果没有,返回s11。
3、根据权利要求1所述的一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,其特征在于,所述前端tcmu虚拟块设备统计数据副本写i/o次数方法为,前端tcmu虚拟块设备进行一次写i/o操作,前端tcmu虚拟块设备和多个数据副本的写i/o次数都加1。
4、根据权利要求所述的一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,其特征在于,所述步骤s1还包括:
s14、数据副本扫描操作,在分布式存储系统负载比较低的时候,对数据副本进行扫描操作,如果扫描到数据副本不一致,进入步骤s3。
5、根据权利要求1所述的一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,其特征在于,步骤s3中所述数据修复操作对象为哈希值不一样的快照文件。
6、根据权利要求4所述的一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,其特征在于,步骤s3方法为分段修复方法,具体为:
s31、将每4m数据分一个数据段;
s32、将每一数据段再分成1024份,每一份4k,并且4k数据对齐;
s33、如果数据副本2数据丢失,读取数据副本1数据往数据副本2修复。
7、根据权利要求4所述的一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,其特征在于,所述步骤s33,具体为:
s331、先从数据副本2读取4m数据,每4k数据计算一个哈希值,得到1024个哈希值,然后把1024哈希值传给数据副本1;
s332、数据副本1读取对应的数据段,也计算出1024个哈希值;
s333、将数据副本1中与数据副本2对应哈希值不相等的数据块,发送给数据副本2,数据副本2进行数据修复。
本发明的有益效果如下:
本发明提出的基于tcmu虚拟磁盘的多数据副本一致性保证方法,具有高速度、低网络带宽消耗、低磁盘带宽消耗的特点,数据修复过程不影响前段正常的读写i/o。
附图说明
下面结合附图,通过对本发明的具体实施方式详细描述,将使本发明的技术方案及其它有益效果显而易见。
图1为一种基于tcmu虚拟磁盘的多数据副本一致性保证方法流程图;
图2为数据修复方法流程图;
图3为将副本1中数据修复至副本2中的方法流程图。
具体实施方式
为更进一步阐述本发明所采取的技术手段及其效果,以下结合本发明的优选实施例及其附图进行详细描述。
请参考图1,一种基于tcmu虚拟磁盘的多数据副本一致性保证方法,应用于分布式存储系统中,分布式存储系统前端tcmu虚拟块设备对应后端存储设备的多个数据副本,所述方法包含以下步骤:
s1、对多个数据副本一致性进行判断,如果多个数据副本不一致,进入s3;
s3、对不一致的多个数据副本进行数据修复;
其中,所述步骤s1,具体为:
s11、采用i/o重定向技术对数据副本进行一次快照操作;
s12、生成前端tcmu虚拟块设备时,前端tcmu虚拟块设备跟数据副本进行握手,以获取每个数据副本的写i/o次数,如果每个数据副本的写i/o次数不一样,进行数据副本一致性判断;
s13、如果数据副本在读写的过程中出现故障,与前端tcmu虚拟块设备断开连接,此时前端tcmu虚拟块设备会不断尝试连接,直到故障修复,重新进行握手,并获取该数据副本的写i/o次数,如果该写i/o次数与虚拟块设备的写i/o次数不一样,进行数据副本一致性判断。因为采用i/o重定向进行快照,创建快照之后,所有写i/o操作都被重定向到其他位置,所以只需判断快照文件的一致性。并且快照文件不会被写i/o修改,所以在进行文件一致性判断的过程中,前段虚拟块设备不用暂停i/o。
本发明提出的基于tcmu虚拟磁盘的多数据副本一致性保证方法,具有高速度、低网络带宽消耗、低磁盘带宽消耗的特点,数据修复过程不影响前段正常的读写i/o。
在所述步骤s3之前还有步骤s2,判断在对数据进行一致性检验时是否创建了快照,如果没有,返回s11。使用i/o重定向进行快照保证了前端i/o不会影响数据修复,前段所有写i/o都会落到新创建的head文件上,此时修复快照文件不需要暂停前端i/o。
优选地,所述前端tcmu虚拟块设备统计数据副本写i/o次数方法为,前端tcmu虚拟块设备进行一次写i/o操作,前端tcmu虚拟块设备和多个数据副本的写i/o次数都加1。
优选地,所述步骤s1还包括:
s14、数据副本扫描操作,在分布式存储系统负载比较低的时候,对数据副本进行扫描操作,如果扫描到数据副本不一致,进入步骤s3,避免外部修改和磁盘坏块造成的数据不一致。
优选地,步骤s3中所述数据修复操作对象为哈希值不一样的快照文件。副本可能包含很多快照文件,数据修复时只需修复哈希值不一样的快照文件。一般不一致的快照文件是最新的快照文件,旧的快照的文件一般是一致的,大大减低了需要数据重建的数据量。
请参考图2,优选地,步骤s3方法为分段修复方法,具体为:
s31、将每4m数据分一个数据段;
s32、将每一数据段再分成1024份,每一份4k,并且4k数据对齐;
s33、如果数据副本2数据丢失,读取数据副本1数据往数据副本2修复。
请参考图3,优选地,所述步骤s33,具体为:
s331、先从数据副本2读取4m数据,每4k数据计算一个哈希值,得到1024个哈希值,然后把1024哈希值传给数据副本1;
s332、数据副本1读取对应的数据段,也计算出1024个哈希值;
s333、将数据副本1中与数据副本2对应哈希值不相等的数据块,发送给数据副本2,数据副本2进行数据修复。
如果每段不分成多份进行修复,只要其中有4k数据的修改,就必须传输4m数据,副本2也必须写入4m,增加了网络的传输带宽和磁盘的写入带宽。如果每4k分成一段,这样段数会增加1024倍,增加了副本1和副本2交互的次数,减低了修复的速度,也不利于i/o合并,降低了磁盘的性能。据重建过程中,采用分段修复,分数据块计算哈希值,减少了不必要的数据拷贝,大大加快了数据修复的速度,并且消耗很低的网络带宽和磁盘带宽,对集群资源消耗低,大大降低了对集群业务的影响。
本发明提出一种高速度,低网络带宽消耗,低磁盘带宽消耗的块设备多副本数据一致性保证方法。前端应用为tcmu虚拟块设备,其最小写i/o为4k,并且数据4k对齐。使用写i/o计数和计数文件哈希值的方法来校验副本之间的一致性。并基于快照技术进行数据修复。快照的i/o重定向功能使前段写i/o不影响后端数据的修复,数据修复过程中不用停止i/o,保证了前端业务不受影响。数据重建过程中,采用分段修复,分数据块计算哈希值,减少了不必要的数据拷贝,大大加快了数据修复的速度,并且消耗很低的网络带宽和磁盘带宽,对集群资源消耗低,大大降低了对集群业务的影响。
以上所述,对于本领域的普通技术人员来说,可以根据本发明的技术方案和技术构思作出其他各种相应的改变和变形,而所有这些改变和变形都应属于本发明权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!