基于协作模糊均值鉴别分析的多姿态人脸识别方法与流程
本发明涉及一种基于协作模糊均值鉴别分析的多姿态人脸识别方法,属于图像识别的技术领域。
背景技术:
人脸识别是身份鉴别的一种重要方法,在档案管理系统、安全验证系统、信用卡验证、公安系统的罪犯身份识别、银行和海关的监控、人机交互等领域有着广泛的应用前景。一般而言,人脸识别的步骤可以分为三个部分:一是从复杂的场景中检测并分割出人脸;二是从找到的人脸图像中提取出人脸特征;三是根据提取的人脸特征采用合适的算法匹配和识别出人脸。其中人脸图像特征提取主要用于降低人脸图像维数,提取图像中有效的鉴别信息,减少图像中冗余信息、噪声等对识别率的影响,从而提高识别精度与识别速度。
现有的人脸特征提取与识别方法有:(1)特征脸(eigenfaces),即基于主成分分析(pca)的人脸识别方法,记载于m.turk与a.pentland于1991年在journalofcognitiveneuroscience第3卷第1期71-86页发表的《eigenfacesforrecognition》中,该方法旨在寻找一个投影方向,使得人脸样本投影后总体散度最大,(2)费舍尔脸(fisherface),即基于线性鉴别分析(lda)的人脸识别方法,记载于p.n.belhumeur,j.p.hespanha,d.j.kriegman于1997年在ieeetransactionsonpatternanalysisandmachineintelligence第19卷第7期711-720页发表的《eigenfacesvs.fisherfaces:recognitionusingclassspecificlinearprojection》,该方法利用样本的类别信息,刻画了样本包含的鉴别结构,(3)拉普拉斯脸(laplacianface),即基于局部保持投影(lpp)的人脸识别方法,记载于x.he,s.yan,y.hu等人于2005年在ieeetransactionsonpatternanalysisandmachineintelligence第27卷第3期328-340页发表的《facerecognitionusinglaplacianfaces》,该方法利用了样本间的近邻关系,旨在寻找一个投影方向,使得人脸样本投影后局部结构得到保持,(4)模糊费舍尔脸(fuzzyfisherface),该方法利用了样本的类隶属度关系,旨在寻找一个投影方向,使得样本投影后模糊类内散度最小同时模糊类间散度最大。fuzzyfisherface算法考虑了每个样本对不同类的隶属度,增强了算法在光照、遮挡、人脸姿态变化时的鲁棒性。
以上特征提取算法中,pca没有考虑样本的鉴别结构,因此鲁棒性较差,lda并没有考虑样本的类隶属度,因此无法鲁棒地处理多姿态问题,lpp尽管考虑了样本的局部结构,但属于无监督方法,未考虑样本的类别结构,fuzzyfisherface方法尽管考虑了样本的类隶属度,但在求解类隶属度过程中,需预先设定近邻参数k,并且基于欧氏距离度量选择近邻,因此受噪声、野点影响较严重。
技术实现要素:
本发明所要解决的技术问题在于克服现有技术的不足,提供一种基于协作模糊均值鉴别分析的多姿态人脸识别方法,解决现有方法无法同时考虑同类样本的相似性及不同类样本的差异性,当样本存在光照、姿态、表情多种变化时,无法对噪声、野点的鲁棒性进行有效处理的问题,本发明基于协作表示的隶属度计算方法,运用获得的每个样本的隶属度信息计算样本的模糊类均值,满足实际应用中对多姿态人脸识别的高精度需求。
本发明具体采用以下技术方案解决上述技术问题:
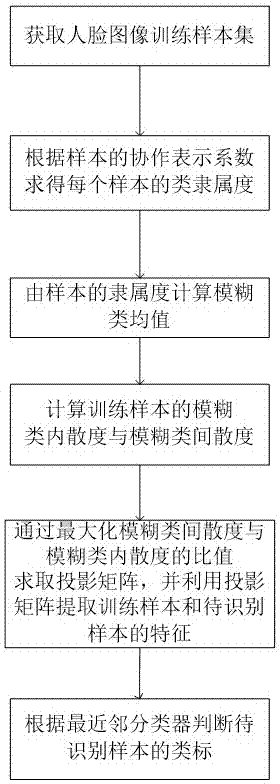
基于协作模糊均值鉴别分析的多姿态人脸识别方法,包括如下步骤:
步骤1、获取包括若干个不同类的多姿态人脸图像训练样本集,对训练样本集中的每个训练样本和待识别样本均进行归一化并利用pca进行降维;
步骤2、利用所得降维后训练样本的协作表示系数计算每个训练样本的类隶属度;
步骤3、利用所得训练样本的类隶属度计算模糊类均值;
步骤4、根据训练样本与模糊类均值之间的距离计算训练样本的模糊类内散度与模糊类间散度;
步骤5、通过最大化训练样本的模糊类间散度与模糊类内散度的比值求取投影矩阵,并利用投影矩阵提取训练样本和待识别样本的特征;
步骤6、根据最近邻分类器判断和确定待识别样本的类标。
进一步地,作为本发明的一种优选技术方案,所述步骤2计算每个训练样本的类隶属度采用公式:
其中,uci表示训练样本xi对于第c类的隶属度,所述c=1,2,...,c,且c表示训练样本集的类数;li为训练样本xi的类别标签,
进一步地,作为本发明的一种优选技术方案,所述步骤3计算模糊类均值采用公式:
其中,mfc表示第c类训练样本的模糊类均值,所述c=1,2,...,c,且c表示训练样本集的类数;uci表示训练样本xi对于第c类的隶属度。
本发明采用上述技术方案,能产生如下技术效果:
本发明设计一种基于协作表示的隶属度计算方法,运用获得的每个样本的隶属度信息计算样本的模糊类均值,并构造模糊类内散度与类间散度,通过最大化模糊类间散度同时最小化模糊类内散度获得投影矩阵。运用获得的投影矩阵实现对待识别样本的特征提取,并由分类准则判断待识别样本的类标。
因此,本发明充分利用了样本的类别信息,考虑了同类样本的相似性及不同类样本的差异性,继承了fuzzyfisherface方法的优点,当样本存在光照、姿态、表情多种变化时,通过引入隶属度信息增强了对噪声、野点的鲁棒性。但是相比于fuzzyfisherface及其他现有的方法,具有如下优点:(1)避免预先设定近邻参数k,(2)可以自适应地获得训练样本的重构系数以计算隶属度,(3)协作表示系数本身就具备了对人脸光照、姿态、表情等变化的鲁棒性,(4)受限于类间散布矩阵,fuzzyfisherface与模糊二维核主成分分析方法最多仅可获取c-1个特征,而本发明所提方法可获取特征数远远多于c-1个。因此,本发明可满足实际应用中对多姿态人脸识别的高精度需求。
附图说明
图1为本发明基于协作模糊均值鉴别分析的多姿态人脸识别方法的流程示意图。
具体实施方式
下面结合说明书附图对本发明的实施方式进行描述。
如图1所示,本发明设计了一种基于协作模糊均值鉴别分析的多姿态人脸识别方法,该方法具体包括如下步骤:
步骤1、获取包括c个不同类的多姿态人脸图像训练样本集,对训练样本集中的每个训练样本和待识别样本均进行归一化并利用pca进行降维。
假设图像的大小为w×h,训练样本来自于训练样本集的c个图像类,将每幅人脸图像进行矩阵向量化操作,得到第i幅人脸图像为xi∈rd,其中d=w×h。训练样本集可表示为x=[x1,x2,...,xn],待识别样本可表示为xtest,其中n表示人脸图像训练样本数。
对于训练样本xi,进行模为1的归一化操作:
xi=xi/||xi||2,(i=1,2,...,n)
同样,对于待识别样本xtest,也需进行归一化操作:
xtest=xtest/||xtest||2
利用pca对归一化后的样本进行预处理以降低数据维数,为方便起见,仍用x=[x1,x2,...,xn]和xtest代表pca预处理后的训练样本集和待识别样本,则计算步骤为:
(1).令z=[x1-m,x2-m,…,xn-m],计算
(2).pca投影向量可表示为:
(3).令apca=[a1,a2,…,ad],则可得pca预处理后的数据为:
xi=apcatxi,其中,i=1,2,...,n;
xtest=apcatxtest
步骤2、利用所得降维后训练样本的协作表示系数计算每个训练样本的类隶属度。
对于步骤1中获得的每个训练样本xi(i=1,2,...,n),可将其协作表示成训练集中其它样本的线性组合,而组合系数可通过求解下列l2范数问题获得:
其中wi=[wi,1,...,wi,i-1,0,wi,i+1,...,wi,n]t∈rn表示xi的重构系数向量,wij(i≠j)表示xj对重构xi的贡献度,wi可由下列计算式获得:
其中xi=[x1,...,xi-1,0,xi+1,...,xn]t。
然后,由每个训练样本的协作表示系数可得样本的类隶属度为:
其中uci表示训练样本xi对于第c类的隶属度,所述c=1,2,...,c,且c表示训练样本集的类数;li为训练样本xi的类别标签,
步骤3、利用所得训练样本的类隶属度计算模糊类均值,采用如下公式:
其中,mfc表示第c类训练样本的模糊类均值。
步骤4、根据训练样本与模糊类均值之间的距离计算训练样本的模糊类内散度与模糊类间散度。
所述样本的模糊类间散度计算为:
其中,
所述样本的类内模糊散度计算为:
其中,a是投影矩阵;
步骤5、通过最大化训练样本的模糊类间散度与模糊类内散度的比值求取投影矩阵,并利用投影矩阵提取训练样本和待识别样本的特征。
投影矩阵可通过求解以下最优化问题获得:
以上投影矩阵可通过求解以下特征方程d个最大特征值对应的特征向量获得:
sfba=λsfwa
其中λ是特征值,a是对应的特征向量。
设a1,a2,...,ad是特征方程sfba=λsfwa的d个最大的特征值对应的特征向量,则投影矩阵可表示为:a=[a1,a2,...,ad]。
利用投影矩阵可对训练样本和待识别样本进行特征提取,如对于训练样本集x=[x1,x2,...,xn],提取出的特征为:
y=[y1,y2,...,yn]=atx
对于某一待识别样本xtest,提取出的特征为:
ytest=atxtest
步骤6、根据最近邻分类器判断和确定待识别样本的类标。
通过以下规则判别待识别样本的类标:
如果||ytest-yk||=mini||ytest-yi||,则label(ytest)=label(yk)。
其中,ytest为待识别样本,yk、yi分别表示第k个和第i个训练样本所提取出的特征,即如根据第k个训练样本离待识别样本的距离,判断待识别样本类别应和第k个训练样本属于同一类。
综上,本发明的方法,充分利用了样本的类别信息,考虑了同类样本的相似性及不同类样本的差异性,继承了fuzzyfisherface方法的优点,当样本存在光照、姿态、表情多种变化时,通过引入隶属度信息增强了对噪声、野点的鲁棒性。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!