一种员工信用评价和应用的方法、装置及电子设备与流程
本发明涉及计算机应用领域,更具体的说,涉及一种员工信用评价和应用的方法、装置及电子设备。
背景技术:
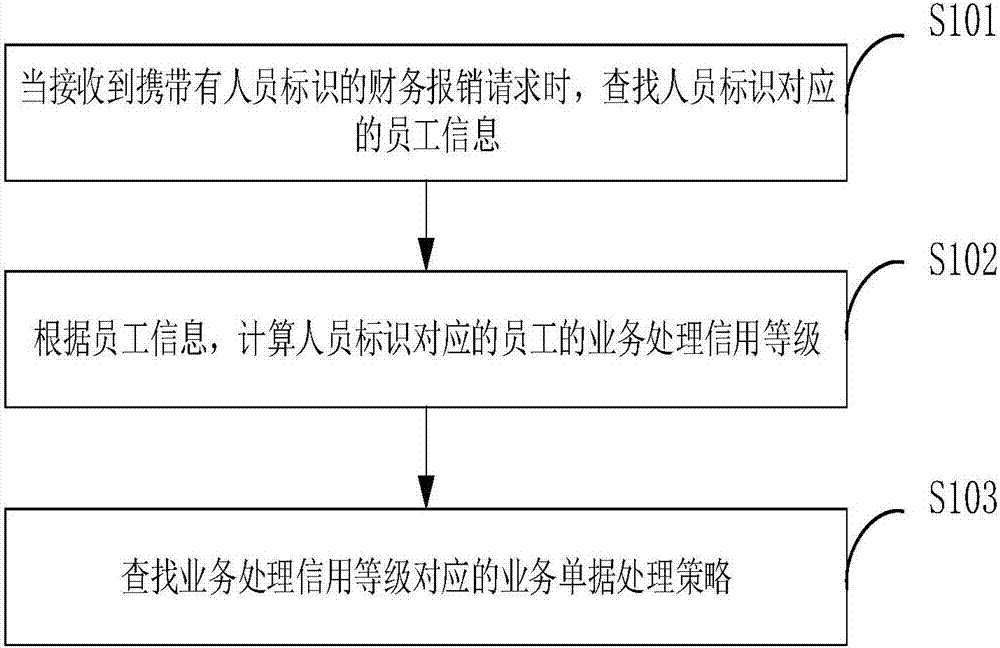
:每个公司都有一套标准的业务处理流程,即公司中的每个员工对应的业务处理流程是一样的,即将业务单据发送到公司的流程处理人员进行审核,审核通过后进入下一道审批流程,直至流程审批结束进行业务处理。对于公司中表现优异和表现较差的员工,业务处理流程都是相同的,即员工权益相同。如员工a为该公司高管、从未旷工,员工b为一般员工,经常旷工,员工a和员工b同时进行业务处理申请时,给予处理的进度和时间是相同的,这样会导致员工a有一定的心理落差,进而会影响员工a的工作积极性。技术实现要素:有鉴于此,本发明提供一种员工信用评价和应用的方法、装置及电子设备,以解决对于公司中表现优异和表现较差的员工,业务处理流程一样,员工权益相同的问题。为解决上述技术问题,本发明采用了如下技术方案:一种员工信用评价和应用的方法,包括:当接收到携带有人员标识的财务报销请求时,查找所述人员标识对应的员工信息;根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级;查找所述业务处理信用等级对应的业务单据处理策略;其中,每个所述业务单据处理策略对应于一个所述业务处理信用等级,且每个所述业务单据处理策略对应的所述业务处理信用等级不同。优选地,根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级,包括:将所述员工信息中的每个指标的数值与相应的指标对应的权重相乘,得到多个指标值;将多个所述指标值相加,得到所述员工的当前信用度;根据所述当前信用度,计算得到当前信用分数;根据公式f=αf0+βfx计算得到所述员工的信用分数;查找所述信用分数对应的业务处理信用等级;其中,f为所述信用分数,f0为数据库中存储的所述员工的历史信用分数,fx为所述当前信用分数,α、β为常数。优选地,每个所述指标对应的权重的计算过程包括:获取样本数据;根据所述样本数据、预先建立的用于计算员工业务处理信用等级的logistic模型、以及每个所述指标的各个分类的量化值,采用极大似然估计算法,计算得到每个所述指标对应的权重。优选地,所述指标包含至少一个业务单据指标和至少一个业务处理指标;其中,所述业务单据指标的数值的计算过程包括:根据所述员工信息中与所述业务单据指标有关联关系的信息、预先建立的用于计算员工子业务处理信用等级的logistic子模型和所述业务单据指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务单据指标的数值;所述业务处理指标的数值的计算过程包括:根据所述员工信息中与所述业务处理指标有关联关系的信息、所述logistic子模型和所述业务处理指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务处理指标的数值。优选地,还包括:采用k-s检验算法验证所述logistic模型的输出结果的准确度。一种员工信用评价和应用的装置,包括:第一查找单元,用于当接收到携带有人员标识的财务报销请求时,查找所述人员标识对应的员工信息;计算单元,用于根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级;第二查找单元,用于查找所述业务处理信用等级对应的业务单据处理策略;其中,每个所述业务单据处理策略对应于一个所述业务处理信用等级,且每个所述业务单据处理策略对应的所述业务处理信用等级不同。优选地,所述计算单元包括:第一计算单元,用于将所述员工信息中的每个指标的数值与相应的指标对应的权重相乘,得到多个指标值;第二计算单元,用于将多个所述指标值相加,得到所述员工的当前信用度;第三计算单元,用于根据所述当前信用度,计算得到当前信用分数;第四计算单元,用于根据公式f=αf0+βfx计算得到所述员工的信用分数;第三查找单元,用于查找所述信用分数对应的业务处理信用等级;其中,f为所述信用分数,f0为数据库中存储的所述员工的历史信用分数,fx为所述当前信用分数,α、β为常数。优选地,还包括:获取单元,用于获取样本数据;第五计算单元,用于根据所述样本数据、预先建立的用于计算员工业务处理信用等级的logistic模型、以及每个所述指标的各个分类的量化值,采用极大似然估计算法,计算得到每个所述指标对应的权重。优选地,所述指标包含至少一个业务单据指标和至少一个业务处理指标;相应的,所述装置还包括:第六计算单元,用于根据所述员工信息中与所述业务单据指标有关联关系的信息、预先建立的用于计算员工子业务处理信用等级的logistic子模型和所述业务单据指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务单据指标的数值;第七计算单元,用于根据所述员工信息中与所述业务处理指标有关联关系的信息、所述logistic子模型和所述业务处理指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务处理指标的数值。优选地,还包括:验证单元,用于采用k-s检验算法验证所述logistic模型的输出结果的准确度。一种电子设备,包括:存储器和处理器;其中,所述存储器用于存储程序;处理器用于调用程序,其中,所述程序用于:当接收到携带有人员标识的财务报销请求时,查找所述人员标识对应的员工信息;根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级;查找所述业务处理信用等级对应的业务单据处理策略;其中,每个所述业务单据处理策略对应于一个所述业务处理信用等级,且每个所述业务单据处理策略对应的所述业务处理信用等级不同。相较于现有技术,本发明具有以下有益效果:本发明提供了一种员工信用评价和应用的方法、装置及电子设备,本发明中计算得到员工的业务处理信用等级后,查找所述业务处理信用等级对应的业务单据处理策略。业务处理信用等级不同,业务单据处理策略不同,解决了现有的业务处理流程中,对于公司中表现优异和表现较差的员工,业务处理流程相同,员工权益相同的问题。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。图1为本发明提供的一种员工信用评价和应用的方法的方法流程图;图2为本发明提供的另一种员工信用评价和应用的方法的方法流程图;图3为本发明提供的一种员工信用评价和应用的装置的结构示意图;图4为本发明提供的另一种员工信用评价和应用的装置的结构示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明实施例提供了一种员工信用评价和应用的方法,参照图1,包括:s101、当接收到携带有人员标识的财务报销请求时,查找所述人员标识对应的员工信息;其中,每个员工有唯一的、用于表示该员工的身份的人员标识。员工信息包括多个指标,其中,参照表1,表1中介绍了每个指标中各个分类的量化值的定义方法。现以员工的财务报销流程为例,介绍下指标。表1中总共介绍了15个指标,包括文化程度、职称等。以文化程度指标为例,文化程度中包含本科以下、本科学历、硕士学历、博士研究生及以上四个分类,其中,本科以下对应的量化值为0,本科学历对应的量化值为1,硕士学历对应的量化值为2,博士研究生及以上对应的量化值为3。其他指标中各个分类的量化值的定义方法同文化程度指标类似,请参照图表1,在此不再赘述。表1每个指标中各个分类的量化值的定义方法当一个员工要进行财务报销时,就能够查找到该员工的员工信息,其中,员工信息存储在数据库中,如员工为员工a,学历为本科,职称为工程师,从业年限为5年以下等数据。需要说明的是,上述15个指标是从多个指标中,采用主成分分析法筛选出来的。其中,采用主成分分析法筛选指标时,应该满足综合性原则、可操作性原则、预见性原则、可量化原则和灵活性原则。具体的,采用主成分分析法筛选的原理为:设对某一事物的研究设计p个指标,分别用x1,x2,...,xp表示,这p个指标构成的p维随机变量为x=(x1,x2,...,xp)′。设随机向量x的均值为μ,协方差矩阵为φ。对x进行线性变换,可以形成新的综合变量,用y表示。新的综合变量可以由原来的变量线性表示。即满足下式。由于可以任意地对原始变量进行上述线性变换,由不同的线性变换得到的综合变量y的统计特性也不尽相同。为了取得较好的效果,我们希望yi=ui′x的方差尽可能大且各yi之间相互独立,由于var(yi)=var(ui′x)=ui′∑ui,对于任意给定的常数c,有var(cui′x)=cui′∑uic=c2ui′∑ui。因此对ui不加限制时,可使var(yi)任意增大,问题将没有意义,我们将线性变换约束在下面的原则之下:1、ui′ui=1,即ui12+ui22+...+uip2=1(i=1,2,...,p)2、yi与yj相互无关(i≠j;i,j=1,2,...,p)3、y1是x1,x2,...,xp的一切满足综合性原则的线性组合中方差最大者;y2是与y1不相关的x1,x2,...,xp所有线性组合中方差最大者;......;yp是与y1,y2,...,yp-1都不相关的x1,x2,...,xp的所有线性组合中方差最大者。(3)基于以上三条原则决定的综合变量y1,y2,...,yp分别称为原始变量的第一,第二,...,第p个主成分。其中,各综合变量在总方差中占得比重依次递减。只挑选前几个方差最大的主成分,达到简化系统结构,抓住问题实质目的。s102、根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级;s103、查找所述业务处理信用等级对应的业务单据处理策略;其中,每个所述业务单据处理策略对应于一个所述业务处理信用等级,且每个所述业务单据处理策略对应的所述业务处理信用等级不同。仍以财务报销流程为例,财务报销流程分为多个财务报销策略,参照表2。表2中介绍了信用等级与财务报销策略的对应关系。表2业务处理信用等级与财务报销策略的对应关系从表2中可以看出,业务处理信用等级分为四种,分别为a+、a、b和c四种,其中,a+等级对应的财务报销策略为付款期为1天,费用票据交财务后可立即将费用打到员工的银行卡中,其他三种业务处理信用等级对应的财务报销策略请参照表2。需要说明的是,表2中的不同的业务处理信用等级对应的不同的财务报销策略,仅为一个实施例,只要是能够保证不同的业务处理信用等级对应的不同的财务报销策略的方案均属于本发明的保护范围。本实施例提供了一种员工信用评价和应用的方法,本实施例中计算得到员工的业务处理信用等级后,查找所述业务处理信用等级对应的业务单据处理策略。业务处理信用等级不同,业务单据处理策略不同,解决了现有的业务处理流程中,对于公司中表现优异和表现较差的员工,业务处理流程相同,员工权益相同的问题。可选的,本发明的另一实施例中,参照图2,步骤s102包括:s201、将所述员工信息中的每个指标的数值与相应的指标对应的权重相乘,得到多个指标值;从表1中可以看出,每个指标均有对应的数值,如指标为文化,指标的数值为0-3中的一个。由于每个员工信息中的每个指标均对应于一数值,如文化程度为本科学历对应的数值为1,文化程度对应的权重为0.5,则文化程度的指标值为1*0.5,采用同样的方法,将每个指标的数值与相应的指标对应的权重相乘,得到多个指标值。其中,指标对应的权重的计算过程为:获取样本数据;根据所述样本数据、预先建立的用于计算员工业务处理信用等级的logistic模型、以及每个所述指标的各个分类的量化值,采用极大似然估计算法,计算得到每个所述指标对应的权重。其中,样本数据为公司的500个员工的员工信息。在挑选样本数据时,应该剔除不合理的样本数据。首先构建logistic模型,logistic逻辑回归:是一种广义的线性回归分析模型,自变量可以连续也可以是分类的,通过logistic回归,可以得到各个指标对应的权重。具体的,其中xi∈rp是员工的指标的数值,yi∈{0,1}是一个二分类的属性变量(yi=1表示第i个员工信用较差,yi=0表示第i个员工信用较好),用logistic回归建立员工业务处理信用等级模型的目的是用下式估计一个员工的信用好坏:其中x是m维向量,代表m个指标的数值,β是m维待估计的参数,代表每项指标对应的权重,β0为常数,p(y=1|x)为给定x的条件下,y为1的概率。logistic模型是非线性模型,不能利用通常的最小二乘法估计。估计logistic回归最常用的方法是极大似然估计法。原理可简单描述如下:假设有n个个体构成的总体:y1,y2,...,yn。从中随机抽取n个样本,其观测值记为y1,y2,...,yn。设:pi=p(yi=1|xi)为给定xi的条件下得到的结果yi=1的条件概率,则在同样条件下得到结果yi=0的条件概率为p(yi=0|xi)=1-pi。于是,我们得到了一个观察值的概率为:由于各项观测相互独立,所以他们的联合分布可以表示为:其中,如式2推导出,式3也称为似然函数。我们的目的是求出能够使似然函数达到最大的参数的估计值。由于直接求出式3的最大值比较困难,一般的做法是对式3取自然对数。因为ln[l(θ)]是l(θ)的单调函数,使ln[l(θ)]取得最大值的参数也必然使l(θ)取得最大值。因此式4称为似然对数函数。为了求出估计其中的参数,使式4取最大值,分别对βi(i=1,2,...,m)求偏导,并令其为0,得:式5、式6称为似然方程。由式5和式6提供的的估计值称为极大似然估计,我们用来表示,而相应的条件概率的估计值则用表示,这个值是在给定xi的条件下yi=1的概率的估计,它代表了logistic模型的拟合值或预测值。可以证明,在随机样本情况下,logistic回归模型的极大似然估计具有一致性、有效性和渐进正态性等特点。由式1得到:式7左边是员工为信用差的员工的比例的对数。β0为常数,β1至βm为各个指标对应的权重。根据式7可以得到,ln[p1/(1-p1)]=β0+β1x1+β2x2+......βmxm。左边为员工为信用差的员工的比例的对数,x1至x15代表指标的数值。得到式7之后,由于已经有500个员工的样本数据,将500个员工的员工信息中相应的数值带入到式7中,即能够得到β0至βm。s202、将多个所述指标值相加,得到所述员工的当前信用度;s203、根据所述当前信用度,计算得到当前信用分数;具体的,计算当前信用分数的过程为:1、假设员工信用好的发生比是1∶1时的信用分数是20,以此为基准分数。2、当好员工发生比翻倍时信用分数增加30。即:score=30/ln(2)*logit+20。其中logit是信用差的员工发生比的对数,即分数越高,企业风险越低。从式7中,可以计算得到的数值,进而能够计算得到score的数值。s204、计算员工的信用分数;具体的,根据公式f=αf0+βfx计算得到员工的信用分数。其中,f为信用分数,f0为数据库中存储的员工的历史信用分数,fx为当前信用分数,α、β为常数。优选的,α=0.3,β=0.7。需要说明的是,历史信用分数为该员工上次报销时的信用分数,若该员工为第一次报销时,无上次报销时的信用分数时,此时将业务处理指标和每个业务单据指标的数值设置为1,再根据该员工其他指标的数值,计算得到该员工的信用分数。s205、查找信用分数对应的业务处理信用等级;具体的,参照表2,表2中给出了不同信用分数对应的业务处理信用等级,举例来说,信用分数为80-100分时,对应的业务处理信用等级为a+,信用分数为50-100分时,对应的业务处理信用等级为a。本实施例中,通过计算得到当前信用分数,再结合历史信用分数,计算得到信用分数,能够保证信用分数是随着员工报销的次数而不断改变的,能够反应出员工的实时信用分数。可选的,本发明的另一实施例中,还包括:采用k-s检验算法验证logistic模型的输出结果的准确度。在模型中,设fn1(x)为信用好员工的累积概率分布,fn2(x)为信用差员工的累积概率分布,得到k-s值为k-s=max|fn1(x)-fn2(x)|当n→∞时,可得到信用好员工和信用差员工的累积分布曲线与概率密度曲线。k-s值就是累积分布函数中所取得的最大值。一般认为,当k-s的检验值大于0.35时,就可以认为该logistic模型是可用的。本实施例中,采用k-s检验算法验证logistic模型的输出结果的准确度,能够验证建立的logistic模型是否是可用的模型,即logistic模型的输出结果是否准确。可选的,本发明的另一实施例中,指标包含至少一个业务单据指标和至少一个业务处理指标;其中,业务单据指标的数值的计算过程包括:根据所述员工信息中与所述业务单据指标有关联关系的信息、预先建立的用于计算员工子业务处理信用等级的logistic子模型和所述业务单据指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务单据指标的数值。具体的,根据子样本数据,采用预先建立的用于计算员工子业务处理信用等级的logistic子模型和所述业务单据指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到每个业务单据指标中的各个子指标的权重;再根据权重和所述员工信息中与所述业务单据指标有关联关系的信息,计算得到业务单据指标的数值。所述业务处理指标的数值的计算过程包括:根据所述员工信息中与所述业务处理指标有关联关系的信息、所述logistic子模型和所述业务处理指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务处理指标的数值。需要说明的是,计算得到业务处理指标的数值的过程同计算得到业务单据指标的数值的过程相似,请参照计算业务单据指标的数值的过程,在此不再赘述。具体参照表1中的指标x10至x15,其中包含的业务单据指标为差旅业务单据指标、交通业务单据指标、培训费业务单据指标和会议费业务单据指标,包含的业务处理指标为采购业务处理指标。具体的,业务单据和业务处理指标中各个子指标的各个分类的量化值的定义方法见表3至表7。表3差旅业务单据指标中各个子指标的各个分类的量化值的定义方法差旅业务单据指标定义发票开具时间x1超过时效性=0;未超过时效性=1单据是否涂改x2涂改=0;未涂改=1发票类型x3与申请不一致=0;一致=1影像是否清晰x4不清晰=0;清晰=1出差起止时间是否与票据一致x5不一致=0;一致=1表4交通业务单据指标中各个子指标的各个分类的量化值的定义方法交通业务单据指标定义发票开具时间x1超过时效性=0;未超过时效性=1单据是否涂改x2涂改=0;未涂改=1发票类型x3与申请不一致=0;一致=1公章是否清晰x4不清晰=0;清晰=1表5采购业务处理指标中各个子指标的各个分类的量化值的定义方法采购业务处理指标定义单据开具时间x1超过时效性=0;未超过时效性=1单据是否涂改x2涂改=0;未涂改=1发票类型x3与申请不一致=0;一致=1是否开具法人单位全称x4否=0;是=1公章是否合格x5不合格=0;合格=1表6培训费业务单据指标中各个子指标的各个分类的量化值的定义方法培训费业务单据指标定义单据开具时间x1超过时效性=0;未超过时效性=1单据是否涂改x2涂改=0;未涂改=1发票类型x3与申请不一致=0;一致=1培训单位提供的发票或证明x4无=0;有=1影像是否清晰x5不清晰=0;清晰=1表7会议费业务单据指标中各个子指标的各个分类的量化值的定义方法会议费业务单据指标定义单据开具时间x1超过时效性=0;未超过时效性=1单据是否涂改x2涂改=0;未涂改=1发票类型x3与申请不一致=0;一致=1附有会议文件或证明x4无=0;有=1影像是否清晰x5不清晰=0;清晰=1现结合表3,介绍下表3中的内容,表3中定义了差旅业务单据指标中各个子指标的各个分类的量化值的定义方法。差旅业务单据指标包含发票开具时间、单据是否涂改、发票类型、影像是否清晰和出差起止时间是否和票据一致五个子指标,其中,以发票开具时间子指标为例,当发票开具时间超过时效性时,发票开具时间对应的量化值为0,当发票开具时间未超过时效性时,发票开具时间对应的量化值为1。现以差旅业务单据指标为例,介绍下计算差旅业务单据指标的数值的方法。首先,根据预先建立的用于计算员工子业务处理信用等级的logistic子模型和极大似然估计算法计算得到ln[p2/(1-p2)]=α0+α1x1+α2x2+.....αmxm。其中,为了区分logistic子模型和logistic模型,将logistic模型中的p写为p1,将logistic子模型中的p写为p2。α0至αm是常数,其中,α0至αm是通过子样本数据计算得到,具体计算过程参照β0至βm的计算过程。当有员工报销时,根据该员工的员工信息中与差旅业务单据指标有关联关系的信息,即发票开具时间、单据是否涂改、发票类型、影像是否清晰和出差起止时间是否和票据一致信息,计算得到的数值,进而能够求出p2的数值,再根据p2的数值,查找表1中相关的差旅业务单据指标的数值。需要说明的是,其他业务单据指标或者是业务处理指标的计算过程同差旅业务单据指标的数值的计算过程相似,请参照差旅业务单据指标的数值的计算过程。此外,若在计算员工信用分数时,发现该待报销员工并未提交过业务单据或者是没有进行过业务处理。此时,默认没有提交过的业务单据指标或者是业务处理指标的p2值为0.5。本实施例中,通过为业务单据指标或者是业务处理指标建立logistic子模型,进而能够求出业务单据指标或者是业务处理指标的数值。可选的,本发明的另一实施例中提供了一种员工信用评价和应用的装置,参照图3,包括:第一查找单元101,用于当接收到携带有人员标识的财务报销请求时,查找所述人员标识对应的员工信息;计算单元102,用于根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级;第二查找单元103,用于查找所述业务处理信用等级对应的业务单据处理策略;其中,每个所述业务单据处理策略对应于一个所述业务处理信用等级,且每个所述业务单据处理策略对应的所述业务处理信用等级不同。可选的,本发明的另一实施例中,还包括:获取单元,用于获取样本数据;第五计算单元,用于根据所述样本数据、预先建立的用于计算员工业务处理信用等级的logistic模型、以及每个所述指标的各个分类的量化值,采用极大似然估计算法,计算得到每个所述指标对应的权重。可选的,本发明的另一实施例中,所述指标包含至少一个业务单据指标和至少一个业务处理指标;相应的,所述装置还包括:第六计算单元,用于根据所述员工信息中与所述业务单据指标有关联关系的信息、预先建立的用于计算员工子业务处理信用等级的logistic子模型和所述业务单据指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务单据指标的数值;第七计算单元,用于根据所述员工信息中与所述业务处理指标有关联关系的信息、所述logistic子模型和所述业务处理指标中各个子指标的各个分类的量化值,采用极大似然估计算法,计算得到所述业务处理指标的数值。可选的,本发明的另一实施例中,还包括:验证单元,用于采用k-s检验算法验证logistic模型的输出结果的准确度。本实施例提供了一种员工信用评价和应用的装置,本实施例中计算得到员工的业务处理信用等级后,查找所述业务处理信用等级对应的业务单据处理策略。业务处理信用等级不同,业务单据处理策略不同,解决了现有的业务处理流程中,对于公司中表现优异和表现较差的员工,业务处理流程相同,员工权益相同的问题。需要说明的是,本实施例中的各个单元的工作过程,请参照上述实施例中的说明,在此不再赘述。可选的,本发明的另一实施例中,参照图4,计算单元102包括:第一计算单元1021,用于将所述员工信息中的每个指标的数值与相应的指标对应的权重相乘,得到多个指标值;第二计算单元1022,用于将多个所述指标值相加,得到所述员工的当前信用度;第三计算单元1023,用于根据所述当前信用度,计算得到当前信用分数;第四计算单元1024,用于根据公式f=αf0+βfx计算得到所述员工的信用分数;第三查找单元1025,用于查找所述信用分数对应的业务处理信用等级;其中,f为所述信用分数,f0为数据库中存储的所述员工的历史信用分数,fx为所述当前信用分数,α、β为常数。本实施例中,通过计算得到当前信用分数,再结合历史信用分数,计算得到信用分数,能够保证信用分数是随着员工报销的次数而不断改变的,能够反应出员工的实时信用分数。需要说明的是,本实施例中的各个单元的工作过程,请参照上述实施例中的说明,在此不再赘述。可选的,本发明的另一实施例中提供了一种电子设备,包括:存储器和处理器;其中,所述存储器用于存储程序;处理器用于调用程序,其中,所述程序用于:当接收到携带有人员标识的财务报销请求时,查找所述人员标识对应的员工信息;根据所述员工信息,计算所述人员标识对应的员工的业务处理信用等级;查找所述业务处理信用等级对应的业务单据处理策略;其中,每个所述业务单据处理策略对应于一个所述业务处理信用等级,且每个所述业务单据处理策略对应的所述业务处理信用等级不同。本实施例中计算得到员工的业务处理信用等级后,查找所述业务处理信用等级对应的业务单据处理策略。业务处理信用等级不同,业务单据处理策略不同,解决了现有的业务处理流程中,对于公司中表现优异和表现较差的员工,业务处理流程相同,员工权益相同的问题。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1