一种基于运算时间统计的纠删参数提取方法与流程
本发明涉及数据存储技术领域,具体地说是一种基于运算时间统计的纠删参数提取方法。
背景技术:
随着互联网的高速发展,数据也随之爆发式增长。如何存储这些数据和如何保证数据安全成为了各个互联网公司的遇到的一大难题。在这种背景下ceph(分布式存储系统)应运而生,由于ceph具有高可靠性、可伸缩、分布式、管理简单、开源等特点,迅速成为了各家互联网公司争相使用的大数据存储系统。在ceph存储系统中数据的安全性是通过数据冗余实现。
目前实现数据冗余有副本方式和纠删方式两种方式,副本方式即一份数据保存多(n个)副本,当一个副本出现问题时可以通过读取其他副本将其恢复;纠删方式将数据分割成一定数量(k个)的数据块,使用纠删算法为这些数据块计算出一定数量(m个)的校验块,当一个或多个(小于等于m)数据块出现问题时可以读取其他数据块并通过纠删算法将其恢复。由此可见副本方式的数据冗余度是n/1,纠删方式的数据冗余度是(k+m)/k,由于通常m远小于k。因此不难看出纠删方式明显比副本方式节省空间。随着数据量增大,这一优势越来越明显,越来越多的用户选择纠删方式作为数据存储方式。
在工程应用中测试发现,利用纠删方式在不同硬件环境下不同的k和m以及条带尺寸的设置会导致数据读写的效率有明显的差别。若随意选用k、m或条带尺寸的值不能充分发挥ceph集群部署的性能,且错误的ceph部署会带来风险。
技术实现要素:
为克服上述现有技术存在的不足,本发明的目的在于提供一种基于运算时间统计的纠删参数提取方法,能够快速准确的找到一定硬件环境下k和m以及条带尺寸的最优值,提高ceph集群部署的性能。
本发明解决其技术问题所采用的技术方案是:一种基于运算时间统计的纠删参数提取方法,其特征是:对不同纠删参数组合分别进行纠删运算,比较纠删运算所用的时间,获得最优纠删参数组合。
进一步地,具体步骤为,
s1,获取用户设置的纠删算法类型;
s2,加载对应的纠删算法库;
s3,生成测试数据;
s4,取得一组纠删参数组合;
s5,根据取得的纠删参数组合对步骤s3生成的测试数据进行纠删运算;
s6,重复步骤s5的纠删运算n次,并计算n次运算所用时间的平均值;
s7,调整纠删参数组合并重复步骤s5和步骤s6,在参数调整结束后转到步骤s8;
s8,输出不同纠删参数组合下的统计结果并给出最优组合建议。
进一步地,步骤s2加载对应的纠删算法库的步骤为,
s21,读取纠删类型的配置文件,获取对应纠删算法库的位置;
s22,使用算法主函数名声明函数指针;
s23,使用函数指针调用算法。
进一步地,步骤s3生成测试数据的大小为1gb。
进一步地,纠删参数包括数据块值k,纠删块值m和纠删条带尺寸;数据块k的取值为1~32的整数,纠删块值m的取值为1~k的整数,纠删条带尺寸的取值为1k~64k的整数值。
进一步地,步骤s6中n的取值为100。
进一步地,步骤s7调整纠删参数组合的步骤为,
s71,数据块k的初始取值为1;
s72,判断数据块k的取值是否小于等于32,如果小于等于32则转到步骤s73,否则结束参数的调整;
s73,设置校验块m的值为1;
s74,判断校验块m的取值是否小于等于k,如果小于等于k则转到步骤s75,否则使数据块k的取值加1,转到步骤s72;
s75,设置条带尺寸初始值为1k;
s76,判断条带尺寸是否小于等于64k,如果条带尺寸小于等于64k则转到步骤s77,否则使校验块m的取值加1,转到步骤s74;
s77,调用纠删算法,对测试数据进行纠删运算;
s78,使条带尺寸加1k,转到步骤s76。
进一步地,步骤s8输出的统计结果为不同纠删参数组合进行纠删运算所用时间的平均值。
本发明的有益效果是:
数据块值k,纠删块值m,纠删条带尺寸这三个参数在ceph集群开始存储数据后将无法再修改,本发明采用的参数提取方式在系统部署之前使用户获得参数最优值,指导工作人员部署出最优的集群,使计算资源得到充分利用,降低了错误部署的风险;
本发明的进行参数提取时自动调整k、m以及纠删条带尺寸的值,全程无人员干预,准确可靠;
本发明通过调整k、m及纠删条带尺寸的值,提取到的参数组合数量庞大,最终得到的最优参数组合的可靠性强。
附图说明
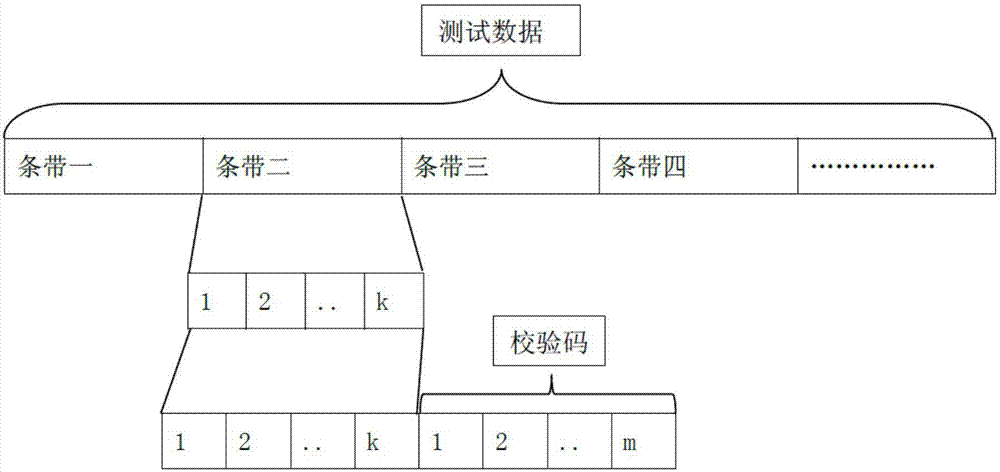
图1是纠删参数k、m和条带的关系示意图;
图2是纠删参数提取方法的流程示意图;
图3是调整纠删参数组合的流程示意图。
具体实施方式
为能清楚说明本方案的技术特点,下面通过具体实施方式,并结合其附图,对本发明进行详细阐述。下文的公开提供了许多不同的实施例或例子用来实现本发明的不同结构。为了简化本发明的公开,下文中对特定例子的部件和设置进行描述。此外,本发明可以在不同例子中重复参考数字和/或字母。这种重复是为了简化和清楚的目的,其本身不指示所讨论各种实施例和/或设置之间的关系。应当注意,在附图中所图示的部件不一定按比例绘制。本发明省略了对公知组件和处理技术及工艺的描述以避免不必要地限制本发明。
本发明经过对ceph纠删存储方式的仔细研究发现,纠删存储的时间主要消耗在纠删算法的运算过程中,而纠删数据块数(k),校验码数(m),纠删条带尺寸这三个参数对纠删算法的性能影响最大。在进行ceph的纠删算法实现过程中,将测试数据切割成一定尺寸的条带,如图1所示,然后将每个条带切割成k块进行纠删计算和存储,使用纠删算法为数据块计算出一定数量的校验块,用m表示校验块的数量。
本发明的纠删参数提取方法对不同参数组合分别进行纠删运算,比较纠删运算所用的时间,获得最优参数组合。如图2所示,方法的具体步骤为:
s1,获取用户设置的纠删算法类型;
s2,加载对应的纠删算法库;
s3,生成测试数据;
s4,取得一组纠删参数组合;
s5,根据取得的纠删参数组合对步骤s3生成的测试数据进行纠删运算;
s6,重复步骤s5的纠删运算n次,并计算n次运算所用时间的平均值;
s7,调整纠删参数组合并重复步骤s5和步骤s6,在参数调整结束后转到步骤s8;
s8,输出不同纠删参数组合下的统计结果并给出最优组合建议。
步骤s1中,通过读取用户输入的算法名称,获取用户需要提取参数的纠删算法类型,其中纠删算法类型有jerasure算法、isa-l算法或lrc算法等。根据纠删算法类型动态加载对应的纠删算法库,加载的具体步骤为:
s21,读取纠删类型的配置文件,获取对应纠删算法库的位置;
s22,使用算法主函数名声明函数指针;
s23,使用函数指针调用算法。
由于不同算法库的主函数名相同,因此,无需针对不同算法类型做特殊设置。
在本发明的实施例中,步骤s3生成的测试数据的大小为1gb;步骤s6纠删运算次数n取值100。为降低随机问题对单次测试结果的影响,对同一纠删参数组合反复执行纠删运算100次,并计算算法执行时间的平均值。
在本发明的实施例中,对纠删参数分别取值,其中数据块k的取值为1~32的整数,纠删块值m的取值为1~k的整数,纠删条带尺寸的取值为1k~64k的整数值。本发明的步骤s7中,利用c++作为开发语言,自动调整k、m以及纠删条带尺寸的值。调整的具体流程如图3所示,具体步骤为,
s71,数据块k的初始取值为1;
s72,判断数据块k的取值是否小于等于32,如果小于等于32则转到步骤s73,否则结束参数的调整;
s73,设置校验块m的值为1;
s74,判断校验块m的取值是否小于等于k,如果小于等于k则转到步骤s75,否则使数据块k的取值加1,转到步骤s72;
s75,设置条带尺寸初始值为1k;
s76,判断条带尺寸是否小于等于64k,如果条带尺寸小于等于64k则转到步骤s77,否则使校验块m的取值加1,转到步骤s74;
s77,调用纠删算法,对测试数据进行纠删运算;
s78,使条带尺寸加1k,转到步骤s76。
根据s71-s78的步骤调整纠删参数的组合,分别改变数据块k、校验块m和条带尺寸的值,获得的参数组合数量庞大,因此得到的最优参数组合较可靠。在不同的纠删参数组合下分别调用纠删算法库,对相同规模的测试数据进行计算,统计算法执行时间,将不同纠删参数组合下的平均值输出并给出最优组合建议。算法执行时间平均值最小的参数组合即为最优参数。
客户在进行ceph集群部署时,直接选用本发明提供的最优纠删参数组合,节省时间,降低错误部署带来的风险。
以上所述只是本发明的优选实施方式,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也被视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!