融合区间模糊信息和统计信息的多目标阈值图像分割方法与流程
本发明属于图像处理技术领域,涉及融合区间模糊信息和统计信息的多目标阈值图像分割方法,具体的是一种基于图像区间值模糊熵和改进otsu的多目标进化自适应多阈值分割方法。
背景技术:
图像分割是图像处理和前期视觉中最为基础和重要的技术之一。图像分割就是把图像分成若干个特定的、具有独特性质的区域,并且将感兴趣的目标提取出来的过程。二十世纪以来,研究者们提出了很多图像分割方法,主要包括阈值的方法、区域的方法、聚类的方法等。在众多的图像分割技术中,阈值法因其实现简单,计算量小,性能稳定而成为最重要而有效的技术之一。
现有的研究大多关注图像阈值数目固定后最佳阈值的选取及其应用对于如何自适应选取阈值数目的研究则少有提,而及使得算法的人为干预较大。2012年djerou等人提出在二进制粒子群算法的框架下,以类间方差、熵和误差率函数作为目标函数进行多目标优化,并提出利用均一性度量标准(u指标)选择最佳阈值和最佳阈值数目。通过大量实验发现u指标对阈值数目不同的个体有偏好性,并不能准确地选出最佳阈值数目。而且上述算法没有引入任何图像空间信息,使得算法对于图像中的噪声比较敏感,无法在含噪声图像分割中获得满意的分割结果。何志勇等人在2012年提出了基于otsu准则和直线截距直方图的阈值分割方法,此方法中直线截距直方图的二维信息是像素点的灰度及其邻域平均灰度组成。虽然上述方法可以对图像中的噪声起到一定的抑制作用,但是其图像分割速度和性能并不理想。而且上述方法的阈值数目是提前设定的,不能随图像的改变而自适应出合适的阈值数目。
技术实现要素:
本发明的目的在于提供融合区间模糊信息和统计信息的多目标阈值图像分割方法;该方法能够实现自适应阈值图像分割,对含噪图像也可获得满意的分割结果。
本发明的目的是通过以下技术方案来解决的:
这种融合区间模糊信息和统计信息的多目标阈值图像分割方法,包括以下步骤:
步骤1,输入待分割的图像,并且将图像转换为灰度图像;
步骤2,设置图像的初始种群数目n,最大迭代次数g和最大阈值数目smax,然后将种群按照阈值数目分成若干个大小相同的分组种群qs;
步骤3,对步骤2中得到的分组种群qs采用同时优化区间模数熵函数和基于直线截距直方图的类间方差函数进行多目标进化,使每个分组种群得到一组非支配解集;
步骤4,通过类间差异与类间差异的加权比值在每个分组种群的非支配解集中选择一个最优解,该最优解为最优阈值数目和最优阈值;
步骤5,根据步骤4中得到的最优解对原图像中的像素点进行标记赋值,得到最终的分割结果。
更进一步的,本发明的特点还在于:
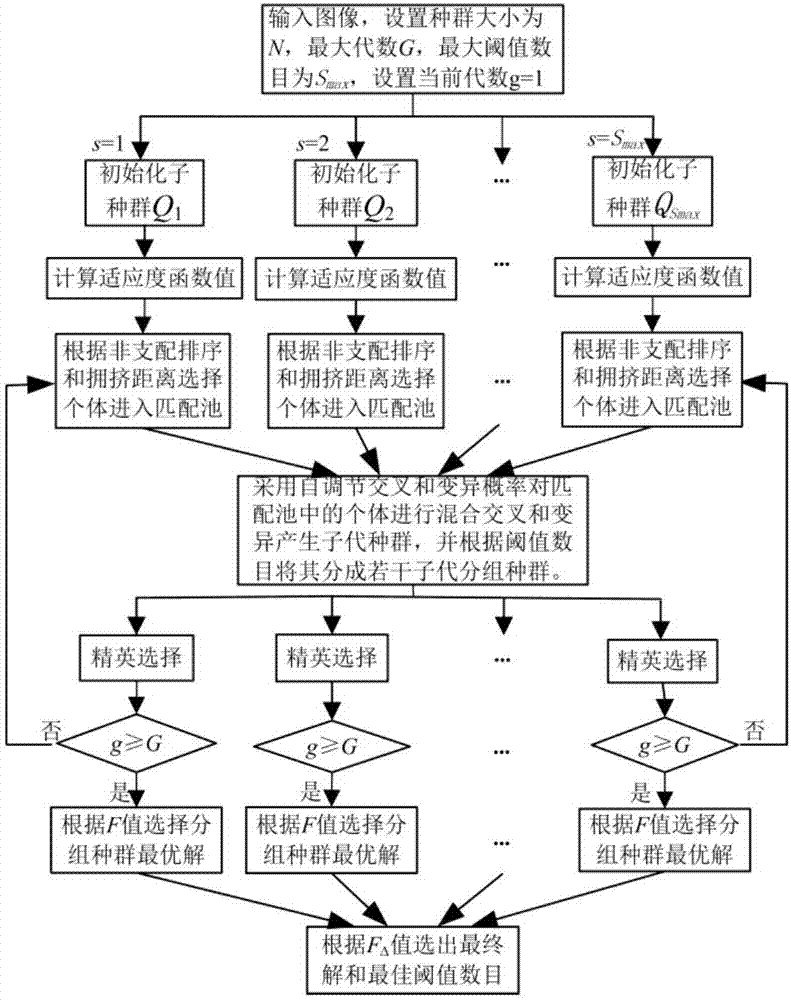
其中步骤3中,对每个分组种群进行多目标进化的具体过程是:
步骤3.1,对每个分组种群进行染色体编码及初始化;
步骤3.2,计算每个分组种群个体的2个适应度函数值,并进行非支配排序进而选择染色体进入各自的匹配池;
步骤3.3,对每个分组种群对应的匹配池内的染色体进行自调节的交叉和变异操作,得到子代种群,然后根据阈值数目将子代种群分为若干子代分组种群,最后采用精英策略得到新的分组种群;
步骤3.4,循环进行步骤3.2和3.3,得到最大迭代次数g。
其中步骤3.1中对每个分组种群进行染色体编码及初始化的具体过程是:染色体编码为对求解阈值使用实数编码,种群中每个染色体是由[2imin,2imax]区间内的s个不同的随机整数组成,s为阈值数目,其中imin和imax分别表示图像灰度的最大值和最小值。
其中步骤3.2中2个适应度函数值为区间模糊熵函数和基于直线截距直方图的类间方差函数。
其中步骤3.3中自调节的交叉和变异操作是将所有的分组种群进行混合交叉突变。
其中步骤4中选择最优解的方法具体为:首先计算各个分组种群中个体对应的类间差异与类内差异的加权比值f,选取使得f取最大值的个体作为分组种群的最优解,然后利用个体的类间差异与类内差异的加权比值f的差值fδ来确定最终解。
与现有技术相比,本发明的有益效果是:利用原始图像和像素邻域窗内的灰度值及空间位置定义一个新的非线性加权和图像,用原始图像灰度和得到的非线性加权和图像灰度构成直线截距直方图。在上述直线截距直方图的基础上设计多阈值类间方差函数作为适应度函数,以克服图像分割过程中噪声对分割效果的影响。设计的多阈值区间模糊熵函数通过增加其模糊性以得到更多图像分割的细节信息。采用所有个体混合交叉和自调节交叉突变概率来提高算法的分割性能与分割速度。最后用类内差异与类间差异的加权比值指标来确定每个分组种群的最优解,然后在这些分组种群的最优解上进行评价来选取一个最终解,即最佳阈值及其对应的阈值数目。继而实现了图像分割的自适应,能够在图像处理中对目标自动分割和提取。
附图说明
图1为本发明的方法流程图;
图2为本发明中实施例中使用berkeley图像数据库图像#55067的分割结果对比图;
图3为本发明中实施例中使用berkeley图像数据库图像#241004的分割结果对比图。
其中,a为原图;b为高斯含噪图;c为椒盐含噪图;d为标准分割图;e为otsu分割图(高斯噪声);f为模糊熵分割图(高斯噪声);g为基于差分优化的模糊熵分割图(高斯噪声);h为本发明方法自适应分割图(高斯噪声);i为otsu分割图(椒盐噪声);j为模糊熵分割图(椒盐噪声);k为基于差分优化的模糊熵分割图(椒盐噪声);l为本发明方法自适应分割结果(椒盐噪声)。
具体实施方式
下面结合附图对本发明做进一步详细描述:
本发明提供了融合区间模糊信息和统计信息的多目标阈值图像分割方法,如图1所示,其具体过程包括以下步骤:
步骤1,输入待分割图像,并且将图像转换为灰度图像。
步骤2,设置该待分割图像的初始种群数目n,最大迭代次数g和最大阈值数目smax,然后将种群按照阈值数目分成若干个大小相同的分组种群qs,设置控制参数k1和k2。
步骤3,将初始种群按照阈值数目分成若干个大小相同的分组种群qs,并对每个个体的染色体编码及初始化;具体的过程是,染色体编码的方式是对求解的阈值使用实数编码,阈值数目为s的分组种群的初始化方法如下:种群中每个染色体是由[2imin,2imax]区间内的s个不同的随机整数组成,其中imin和imax分别表示图像灰度的最大值和最小值。
步骤4,计算每个分组种群个体的2个适应度函数区间值模糊熵f1(t1,t2,…,tn)和基于直线截距直方图的类间方差f2(t1,t2,…,tn)的值,并将其值依次排放在染色体的基因位上,然后将上述2个适应度函数值对应的匹配池内的染色体按照自调节交叉突变概率pc和pm对匹配池内的染色体进行混合交叉与突变产生子代种群,然后根据子代种群的阈值数目将其分成若干子代分组种群,最后采用精英策略得到新的分组种群。
步骤5,循环执行步骤3和步骤4,当迭代次数达到最大值g时,每个分组种群均会得到一组非支配解集,然后利用类间差异与类内差异的加权比值指标在各个分组种群得到的非支配解集上选择一个最优解;选择最优解的方法具体为:首先计算各个分组种群中个体对应的类间差异与类内差异的加权比值f,选取使得f取最大值的个体作为分组种群的最优解,然后利用个体的类间差异与类内差异的加权比值f的差值fδ来确定最终解。
步骤6,利用步骤5得到的最优阈值数目和最优阈值两项参数对原图像中的像素点进行标记赋值,得到最终的分割结果。
本发明中2个适应度函数区间值模糊熵f1(t1,t2,…,tn)和基于直线截距直方图的类间方差f2(t1,t2,…,tn)的具体设计为:
多阈值(t1,t2,…,tn)下的区间模糊熵函数的具体设计如下:
f1(t1,t2,…,tn)=h1+h2+…hn+hn+1
上式中
其中
其中,α是区间模糊指数,可根据经验设置,这里取值为0.8,模糊隶属度函数的定义如下所示:
f1(t1,t2,…,tn)取最大时,说明图像分割结果包含原图的信息呈最大,此时可以获得最佳阈值
基于直线截距直方图的类间方差函数的具体设计是先设计直线截距直方图,然后设计多阈值类间方差函数。用(xi,εj)表示由像素点的灰度以及线性加权和图像的灰度组成的二元组,则xi+εj=l可以表示二维直方图中与主对角线垂直且直线截距为l的直线。直线截距直方图的定义如下:nl表示xi+εj=l出现的次数,则xi+εj=l出现的概率pl可以表示为pl=nl/n,l=0,1,…,2l-1。其中线性加权和图像ε的具体构造如下所示:
其中,εj是图像ε在j处的灰度值,sj表示以像素j为中心的邻域窗,ejp表示像素j和像素p之间的局部相似性,它是根据邻域窗sj内像素的空间坐标和灰度值来计算的,具体形式如下:
基于直线截距直方图的多阈值类间方差函数的定义如下:
其中
使得类间方差函数
步骤4中交叉突变策略采用的是所有个体混合交叉突变,即所有分组种群的个体之间均可进行交叉,并且选用的是双点交叉,交叉点亦是随机选取得到。自调节交叉突变概率pc和pm的具体设计如下:
其中,σl(ci,cj)=((fi,l-fave,l)+(fj,l-fave,l))/2,(l=1,2,…,l),fi,l和fj,l分别表示第i个和第j个个体在第l个目标下的适应度函数值,fave,m表示第l个目标的平均适应度函数值,l表示适应度函数的个数,本文采用两个适应度函数,所以l=2,k1和k2为两个控制参数。当个体的适应度函数值较大时,pc和pm的值就越小;反之,pc和pm的值就越大。按照自调节交叉概率pc和变异概率pm对个体进行交叉和变异,既不破坏好的基因,又能保证群体的多样性。交叉和变异完成后,将产生的子代种群按照阈值数目分成若干子代分组种群。然后将各个子代分组种群与阈值数目相同的父代分组种群混合后进行非支配排序选出下一代分组种群,因此,迄今为止发现的最优阈值分割结果就会被保留下来。
步骤5中最优阈值数目和最优阈值的选取方法是首先计算各个分组种群中个体对应的类间差异与类内差异的加权比值f,选取使得f取最大值的个体作为分组种群的最优解,然后利用个体的类间差异与类内差异的加权比值f的差值fδ来确定最终解。加权比值f和fδ的定义如下:
其中,
实施例及进行仿真实验分析
选取berkeley图像数据库中的#55067和#241004两幅图像,如图2中的a和图3中的a所示,使用该两幅图片通过本发明的方法进行仿真分析,验证本发明的有效性,具体如下:
本实施例中#55067和#241004两幅图像两种类型噪声分别为椒盐噪声(0,0.001),如图2和图3中的c所示,高斯噪声(0,0.001)如图2和图3中的b所示。通过otus方法对两种不同噪声的图片进行分割得到的结果图2和图3中e和i所示;通过模糊熵分割图方法对两种不同噪声的图片进行分割得到的结果如图2和图3中的f和j所示;通过基于差分优化的模糊熵分割图方法对两种不同噪声的图片进行分割得到的结果如图2和图3中的g和k所示;使用本发明的方法对两种不同噪声的图片进行分割得到的结果如图2和图3中的h和l所示;使用标准分割图方法对原图a进行分割得到的结果如图2和图3中d所示。由对比图可以看出本发明对目标和背景的分割准确度比其余几种对比方法更加准确。本发明不仅克服了噪声的影响,自适应出合适的阈值数目而且取得了很理想的分割结果。
- 还没有人留言评论。精彩留言会获得点赞!