一种量测数据随机缺失的线性变参数时滞系统的鲁棒辨识方法与流程
本发明涉及工业系统建模以及工业系统模型参数辨识技术领域。
背景技术:
实际的工业系统,包括机械设备、发动机等,都属于复杂的非线性系统,对这些系统的精确建模是控制和优化方法设计与实现的前提条件。而线性变参数模型能够有效的对此类工业过程进行建模,其实际意义远远超过了传统的建模方法。因此,对线性变参数模型的研究很有必要。
在利用线性变参数模型对复杂工业过程进行建模时,对已经建好的模型进行参数辨识需要考虑以下常见因素:存在系统时滞、系统的输出数据随机缺失、系统的输出数据中含有异常值。这些因素都会很大程度上影响模型参数辨识的精度。
技术实现要素:
本发明的目的是为了解决现有技术存在系统时滞、系统的输出数据随机缺失、系统的输出数据中含有异常值导致模型参数辨识精度较低的问题,而提出一种量测数据随机缺失的线性变参数时滞系统的鲁棒辨识方法。
一种量测数据随机缺失的线性变参数时滞系统的鲁棒辨识方法包括以下步骤:
步骤一:建立线性变参数(lpv)时滞模型;
步骤二:根据步骤一建立线性变参数(lpv)时滞模型,建立基于学生氏t-分布线性变参数(lpv)时滞鲁棒概率模型;
步骤三:基于广义期望最大化(generalizedexpectationmaximization,gem)算法,对步骤二建立的基于学生氏t-分布lpv时滞鲁棒概率模型进行辨识,得到线性变参数时滞模型的参数θ*,δ*,
本发明的有益效果为:
本发明方法在考虑系统时滞、输出数据缺失、包含异常值的情况下,在gem算法的框架下,提出了一种lpv时滞系统的鲁棒辨识方法,能够有效的解决此类系统的模型参数辨识问题,对线性变参数系统辨识理论的完善及其工业实际应用起到了极大的促进作用。
将本发明方法lpvt-gem与经典方法lpv-riv(refinedinstrumentalvariable)对相同的仿真模型进行仿真,仿真结果的对比能够很好的证明本发明方法的有效性。当输出数据中包含不同比例的奇异值,信噪比的情况下,参数估计结果为:当真值为1时,本发明方法的均值为1.0014,标准差为0.0305,经典方法lpv-riv的均值为0.9462,标准差为0.0414;当真值为-0.5时,本发明方法的均值为-0.5039,标准差为0.0874,经典方法lpv-riv的均值为0.7054,标准差为0.4068;当真值为-0.1时,本发明方法的均值为-0.0861,标准差为0.1066,经典方法lpv-riv的均值为-1.5323,标准差为0.4517。当信噪比增加时,每个参数估计的标准差不断减小,标准差越小,估计的效果越好;在信噪比一致的条件下,本发明方法lpvt-gem的参数估计效果要明显好于作为对比的lpv-riv方法。
附图说明
图1为输出数据缺失10%以及输出异常值比例为10%的情况下,lpvt-gem方法中,q-函数的迭代过程图。在图中,q-函数的值不断增加,在第25次迭代时,q-函数收敛;
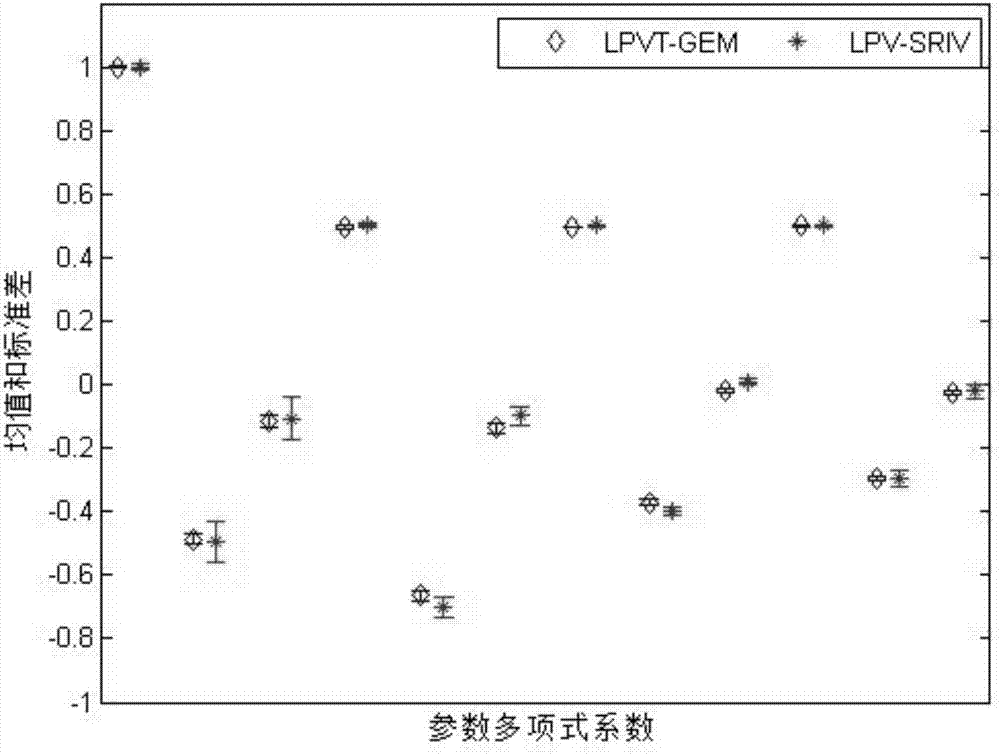
图2为信噪比为snr=20db以及输出异常值比例为0%的情况下,lpvt-gem与lpv-riv方法的系统参数估计均值与标准差对比图;
图3为信噪比为snr=10db以及输出异常值比例为0%的情况下,lpvt-gem与lpv-riv方法的系统参数估计均值与标准差对比图;
图4为信噪比为snr=5db以及输出异常值比例为0%的情况下,lpvt-gem与lpv-riv方法的系统参数估计均值与标准差对比图。
具体实施方式
具体实施方式一:一种量测数据随机缺失的线性变参数时滞系统的鲁棒辨识方法包括以下步骤:
步骤一:建立线性变参数(lpv)时滞模型;
步骤二:根据步骤一建立线性变参数(lpv)时滞模型,建立基于学生氏t-分布线性变参数(lpv)时滞鲁棒概率模型;
步骤三:基于广义期望最大化(generalizedexpectationmaximization,gem)算法,对步骤二建立的基于学生氏t-分布lpv时滞鲁棒概率模型进行辨识,得到线性变参数时滞模型的参数θ*,δ*,
θ*:是最优的模型参数多项式系数,θ是模型参数多项式系数;δ*为最优的尺度变量,δ为尺度变量;
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一中建立线性变参数时滞模型的具体过程为:
假设一个线性变参数(lpv)时滞系统用下面的线性变参数(lpv)输出误差(outputerror,oe)模型表示:
xk=g(ωk,z-1)uk-d
yk=xk+εk
其中yk表示系统的输出,xk为系统的无噪声输出,uk表示系统的输入,ωk为可测量的调度变量,调度变量决定了系统的操作模式,d表示时间延迟,εk表示零均值的随机噪声;g(ωk,z-1)表示输入与输出之间的传递函数,表示为:
其中的多项式a和b都是与调度变量ωk相关的;与调度变量ωk相关的也是就是,如果ωk的值改变,那么a和b的值也相应的改变;
写成如下表达式:
其中na为模型输出的阶次;nb为模型输入的阶次;m和n为迭代变量,m的取值为:1,2,3……na,n的取值为:1,2,3……nb;ωk为可测量的调度变量,调度变量决定了系统的操作模式。z-m为m阶递归因子,物理含义为z-mxk=xk-m;z-n为n阶递归因子,物理含义为z-nxk=xk-n;am(ωk)和bn(ωk)表示的是两个函数;z-1表示一个递归因子,它表示后退一个采样时刻,比如:k时刻的模型无噪声输出为xk,k-1时刻的模型无噪声输出为xk-1,那么这两个时刻的输出之间的关系是z-1xk=xk-1;am(ωk):是一个多项式函数,它表示k-m时刻,模型无噪声输出xk-m前面的系数;bn(ωk):是一个多项式函数,它表示k-n-d时刻,模型输入uk-n-d前面的系数。
在多项式a和b中,系数写为ωk的亚纯函数的线性组合:
其中
由此可以看出,调度变量的改变会引起系统的动态特性变化,当调度变量为常值时,系统的动态特性也保持不变。根据上述描述,线性变参数(lpv)时滞系统的模型写为:
a(ωk,z-1)xk=b(ωk,z-1)uk-d
其中uk-d表示k-d时刻的模型输入;
分别定义两个维数为na(nα+1)+nb(nβ+1)的向量
其中θ是模型参数多项式系数(θ本身也是一个向量);xk-1为k-1时刻的模型无噪声输出;xk-2为k-2时刻的模型无噪声输出;
φ0(ωk)是构成as(ωk)的第一项亚纯函数;
χ0(ωk)是构成bj(ωk)的第一项亚纯函数;
θ由多项式函数
得到:
其中θ为自由度参数,
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤二中根据步骤一建立线性变参数时滞模型,建立基于学生氏t-分布线性变参数时滞鲁棒概率模型的具体过程为:
一般来说,噪声序列{εk}k=1,…,n假设为零均值的高斯白噪声,服从分布
基于t-分布来建立lpv时滞系统的鲁棒概率模型,步骤可分为:
步骤二一:将局部噪声变化参数为δ/λk,由此得到:
其中δ为尺度变量,εk为噪声序列,k=1,….n;表示噪声序列εk服从高斯分布,均值为0,方差为δ/λk;λk是权重参数:
其中
步骤二二:yk的边缘分布通过联合边缘分布
通过上式不难看出,yk的边缘分布实际上是一个t-分布,其中:
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤三中广义期望最大化算法的具体过程为:
<1>先作一个简单符号解释:
在整个辨识过程中,能够直接获取的数据集包括:输入数据u1;n={uk}k=1,…,n,输出数据y1:n={yk}k=1,…,n,调度变量ω1:n={ωk}k=1,…,n。在本发明方法中,考虑了随机缺失了部分数据,表示为
<2>gem本质上是一种求解极大似然(maximumlikelihood,ml)估计的优化算法,通过两个步骤:e-step(期望步骤)和m-step(最大化步骤)不断迭代优化以达到最后的优化效果。在e-step中,先计算出完整数据集c={cobs,cmis}的对数似然函数logp(cmis,cobs|θ),基于当前的参数估计θs和观测数据集cobs,将对数似然函数对缺失数据集cmis求取期望,所得函数被称为q-函数,其数学表达式为:
在m-step中,通过最大化q-函数,得到新的参数估计θs+1,再令θs=θs+1,不断循环迭代,直到最后全部被估计参数收敛。综上所述,gem算法总结如下:
待估计的参数θ1:在迭代开始之前,对需要辨识的模型参数θ赋予一个初始值,这个初始值θ=θ1;
步骤1)初始化:初始化待估计的参数θ1,迭代次数s设为1;
步骤2)e-step:计算推导出q-函数:
其中logp(cmis,cobs|θ)为完整数据集c={cobs,cmis}的对数似然函数,θs为当前的模型参数(第s次迭代得到的线性变参数时滞模型的参数),
θs为上一次迭代得到的模型参数,也是这一次迭代的参数初始值,也就是当前的模型参数。
步骤3)m-step:通过最大化q-函数,得到新的参数估计θs+1,使得:
q(θs+1|θs)≥q(θs|θs)
再令:θs=θs+1;
q(θs|θs)为上一次迭代中求得的q函数值;q(θs+1|θs)为本次迭代中,所希望得到的q函数值;
步骤4)令s=s+1,返回到步骤2),不断重复执行e-step和m-step,直到最后待估参数收敛为止。收敛条件是:
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述步骤三中对步骤二建立的基于学生氏t-分布lpv时滞鲁棒概率模型进行辨识,得到线性变参数时滞模型的参数θ*,δ*,
e-step:
(1)计算完整数据集c={cobs,cmis}的对数似然函数logp(cmis,cobs|θ),利用概率链式法则,对数似然函数写为:
此时,为了推导得到q-函数(q(θ|θs)),将上述对数似然函数分别对离散的时间延迟d、随机缺失的数据
其中τ为时间延迟,τ1表示时间延迟的下限值;τ2表示时间延迟的上限值;m1,m2,m3……mβ表示输出数据随机丢失的时刻;o1,o2,o3……oα表示输出数据没有丢失的时刻,输出数据可用的时刻;n:表示系统的输入输出数据一共包含的采样时刻数;
(2)为了计算q-函数,先计算d=τ的后验概率和上述公式中的所有积分项;d=τ的后验概率表示为:
其中δs为当前迭代中得到的尺度变量的值;
对于积分项,需要分情况讨论:
当yk缺失时,λk的后验分布表示为:
λk以及logλk的期望为:
<λk>m=∫p(λk|cobs,d=τ,θs)λkdλk=1
ψ(x)是gamma函数γ(x)的一阶导数;
q-函数中的双重积分表示为:
在双重积分中,gs(ωk,z-1)表示传递函数在第s次迭代中,用该次迭代中得到的估计参数θs代替参数θ所得;
当yk属于观测数据时,λk的后验分布表示为:
其中:
此时,λk以及logλk的期望为:
<λk>o是分配给每个观测数据对应模型预测偏差的平方的权重;
(3)q-函数中,第二个积分项
当yk属于观测数据集时,q-函数中第三个积分项
当yk缺失时,第三个积分项可以写为:
则q-函数表示为:
q1(θ,δ)表示关于变量θ,δ的函数,它是q(θ|θs)函数的一部分;
其中:
c1与任何变量都不相关,所以认为它是一个常量。
m-step:
步骤三一:为了计算尺度变量δ,将q1(θ,δ)对δ求导,并令导数等于零,得:
步骤三二:为了计算模型参数θ,将δs+1代入到函数q1(θ,δ)中,得到:
在准则函数q3(θ)中,<λk>o是分配给每个观测数据对应模型预测偏差的平方的权重。如果yk是异常值时,<λk>o就非常趋近于零,因此可以很大程度上消除异常值对辨识算法带来的负面影响。为了得到模型参数θ的估计表达式,利用阻尼牛顿方法优化准则函数q3(θ),利用辅助模型准则构造辅助模型,并利用辅助模型的输出来替代向量
其中μ表示阻尼牛顿常数,取值范围在0到1之间;i为单位矩阵;
其中:
向量
基于当前的参数估计和辅助模型准则构造辅助模型,通过对下式中的辅助模型进行仿真求得
步骤三三:为了估计自由度参数
解上述方程得参数
步骤三四:获得时间延迟d=τ的估计值;假设τ均匀分布在整数区间[τ1,τ2]中,在每次迭代过程中,已经计算得到时间延迟d的后验概率函数pd,τ,则d的估计值通过下式更新得到:
步骤三五:在m-step中,通过循环迭代步骤三一至步骤三四估计得到系统的模型参数,分别将最后的迭代结果记作:
其它步骤及参数与具体实施方式一至四之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例一种量测数据随机缺失的线性变参数时滞系统的鲁棒辨识方法具体是按照以下步骤实施的:
算法的输入为
步骤一、分别构造观测数据集:cobs和缺失数据集:cmis;
步骤二、初始化参数θ1,并且设置s=1;
步骤三、更新后验概率分布以及期望:
利用e-step中给出的公式,在k=1,…,n时,计算各个时刻λk的后验分布以及期望<λk>m,<logλk>m,<λk>o,and<logλk>o;
τ在整数区间[τ1,τ2]中,对于整数区间[τ1,τ2]中的每一个值,计算τ的后验概率分布;
步骤四、更新模型参数估计:
更新无噪声输出估计
更新模型参数估计θ,尺度参数δ,自由度参数
步骤五、令s=s+1,直到估计参数收敛。
<1>考虑下面的lpv时滞模型:
yk=xk+εk
其中:
a(ωk,z-1)=1+a1(ωk)z-1+a2(ωk)z-2
b(ωk,z-1)=b1(ωk)z-1+b2(ωk)z-2
并且:
<2>设置仿真参数:
系统的输入选取为均匀分布的随机噪声:
图1展示了在每次迭代过程中,q-函数(q(θs+1|θs))值的变化情况,不难看出,q-函数的值一直在不断增加,且在第25次迭代时,q-函数收敛。
<3>仿真验证:
为了方便描述,将本发明方法简记为:lpvt-gem。作为对比,我们利用经典方法lpv-riv(refinedinstrumentalvariable)对相同的仿真模型进行仿真,仿真结果的对比能够很好的证明本发明方法的有效性。
lpv-riv方法是无法估计输出时间延迟的,故而在lpv-riv方法的仿真中,我们假设τ=2是已知的。
为了较好的验证本发明方法,针对lpvt-gem和lpv-riv方法,在输出数据中不包含奇异值、信噪比分别为snr=20db、snr=10db、snr=5db的情况下,分别做了100次蒙特卡洛仿真,每组仿真将得到100个参数估计序列,求取每个参数的均值和标准差。具体的对比仿真结果见附图2到附图4。图2为信噪比为snr=20db以及输出异常值比例为0%的情况下,lpvt-gem与lpv-riv方法的系统参数估计均值与标准差对比图,菱形表示lpvt-gem方法参数估计的均值,*表示lpvt-riv方法参数估计的均值,菱形上的棒条表示lpvt-gem方法参数估计的标准差,*上的棒条表示lpvt-riv方法参数估计的标准差,棒条的长度越短,标准差越小,参数估计效果越好;图3为信噪比为snr=10db以及输出异常值比例为0%的情况下,lpvt-gem与lpv-riv方法的系统参数估计均值与标准差对比图,菱形表示lpvt-gem方法参数估计的均值,*表示lpvt-riv方法参数估计的均值,菱形上的棒条表示lpvt-gem方法参数估计的标准差,*上的棒条表示lpvt-riv方法参数估计的标准差,棒条的长度越短,标准差越小,参数估计效果越好;图4为信噪比为snr=5db以及输出异常值比例为0%的情况下,lpvt-gem与lpv-riv方法的系统参数估计均值与标准差对比图,菱形表示lpvt-gem方法参数估计的均值,*表示lpvt-riv方法参数估计的均值,菱形上的棒条表示lpvt-gem方法参数估计的标准差,*上的棒条表示lpvt-riv方法参数估计的标准差,棒条的长度越短,标准差越小,参数估计效果越好。
当输出数据中包含不同比例的奇异值,信噪比的情况下,参数估计结果如下表所示:
表1异常值比例为10%、信噪比为snr=5db时参数估计结果
仿真结果总结:
当信噪比增加时,每个参数估计的标准差不断减小,标准差越小,估计的效果越好;
在信噪比一致的条件下,本发明方法lpvt-gem的参数估计效果要明显好于作为对比的lpv-riv方法;
根据表1的仿真结果,可以看出在lpv-riv方法中,部分参数估计的结果是错误的,说明本发明方法对存在系统时滞、异常值、缺失输出数据情况下有很强的鲁棒性。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!