一种基于FPGA的卷积神经网络实现方法及装置与流程
本发明属于计算机领域,尤其涉及一种基于fpga的卷积神经网络实现方法及装置。
背景技术:
fpga,即现场可编程门阵列,是一种高速、高密度的半定制ic芯片。原厂(如xilinx、altera、lattice等)生产出的是空白的不含配置信息的fpga芯片,用户可根据自己的需要,利用片上所提供的各种资源开发自己的逻辑,将生成的配置信息写入,从而将其变成自己所需功能的芯片,fpga可近乎不限次数反复重配。不同于cpu的是,fpga上的所有逻辑资源都可以以自己的时钟频率并行运行,所以很适合高计算密度算法的实现。
卷积神经网络(cnn)是人工神经网络的一种,广泛应用于图像分类、目标识别、行为识别、语音识别、自然语言处理和文档分类等领域。近几年来,随着计算机计算能力的增长以及神经网路结构的发展,cnn的网络性能和识别准确度都有了很大的提高。但与此同时,网络的深度不断加深,网络的计算量也越来越大,因此需要gpu、fpga等并行计算设备来加速运算。
传统的fpga开发都是使用vhdl/verilog等硬件描述语言实现,其可以充分利用fpga的硬件资源,但是开发周期长,程序的维护和升级困难,目前的卷积神经网络结构复杂,网络结构发展迅速,使用传统的vhdl/verilog开发效率低、成本高。因此,需要一种新的卷积神经网络实现技术,来解决开发效率问题。
技术实现要素:
本发明提供卷积神经网络实现方法及装置,以解决上述问题。
本发明提供一种基于fpga的卷积神经网络实现方法。上述方法包括以下步骤:
基于fpga实现的卷积神经网络中的多层之间串行处理,通过全局存储器进行数据交互;
使用opencl编程语言在所述fpga上实现所述卷积神经网络的处理过程。
本发明还提供一种基于fpga的卷积神经网络实现装置,包括:fpga处理器和全局存储器,其中,所述fpga处理器与所述全局存储器连接,
fpga处理器,用于实现卷积神经网络中的多层之间串行处理,使用opencl编程语言在所述fpga上实现所述卷积神经网络的处理过程;
全局存储器,用于所述卷积神经网络中的数据交互。
通过以下方案:通过消息中间件传输来自不同数据源的数据,实现了数据一次收取,多出分发,不必将数据进行多次抽取,减轻了源头数据库的压力。
通过以下方案:使用opencl编程语言在fpga上实现所述卷积神经网络的处理过程,解决由于卷积神经网络结构复杂,网络结构发展迅速,使用传统的vhdl/verilog语言开发效率低、成本高的问题。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1所示为本发明实施例1的基于fpga的卷积神经网络实现方法处理流程图;
图2所示为本发明实施例2的基于fpga的卷积神经网络实现架构图;
图3所示为本发明实施例3的基于fpga的卷积神经网络的每一层实现原理示意图;
图4所示为本发明实施例4的基于fpga的卷积神经网络实现装置结构图。
具体实施方式
下文中将参考附图并结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
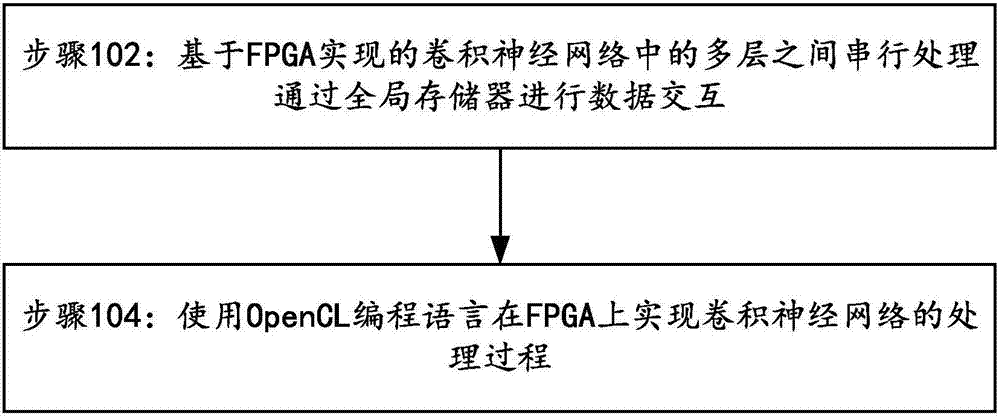
图1所示为本发明实施例1的基于fpga的卷积神经网络实现方法处理流程图,包括以下步骤:
步骤102:基于fpga实现的卷积神经网络中的多层之间串行处理,各层之间通过全局存储器进行数据交互。
步骤104:使用opencl编程语言在所述fpga上实现所述卷积神经网络的处理过程。
进一步地,所述卷积神经网络中每一层的处理过程包括:
对每层的输入数据和输出数据进行向量化;
使用多线程opencl核从所述全局存储器中并行读取多个卷积操作处理的数据;
使用单线程opencl核依次对所述卷积操作处理的数据进行卷积和激活操作;
使用单线程opencl核依次对经过卷积和激活操作的数据进行池化操作;
使用多线程opencl核向所述全局存储器写入经过池化操作的数据。
进一步地,所述卷积神经网络中每一层的数据处理结果通过channel进行传递。
进一步地,并行从所述全局存储器读取多个卷积操作处理的数据、串行对多个所述卷积操作处理的数据进行卷积和激活操作、串行对所述数据进行池化操作、并行向所述全局存储器写入经过池化操作的数据。
其中,所述卷积神经网络的模型包括以下任意一种:
lenet,a1exnet,vgg-net,googlenet,resnet。
如图2所示,对于卷积神经网络的多个层,在fpga上串行实现,各层之间通过全局存储器进行数据交互。卷积神经网络的每一层,包括全局数据读取、卷积、激活、池化、全局数据写入操作单元,这些计算单元并行进行,不同计算单元之间通过channel进行通信。
对于卷积神经网络的每一层,参考图3,具体实现方案如下:
将每层计算涉及的多个输入特征图、输出特征图都进行向量化处理,分别设为vec_size、lane_size,即vec_size个输入特征图为一组进行运算,输出一组即lane_size个输出特征图。
(1)全局数据读取使用多线程opencl核实现,即从全局存储器读取需要处理的数据。每个线程块中的多个线程并行读取每个卷积操作(如3×3卷积操作)的数据;多个线程块并行读取多组输入特征图的多个卷积操作的数据。读取的数据写入channel中。
(2)卷积和激活操作使用单线程opencl核实现,从(1)的输出channel中读取数据,以流水线的方式依次处理每组输出特征图的每个卷积操作。每组内的单个卷积操作并行进行。每个时钟周期可实现一次卷积操作。输出结果写入channel中。
(3)池化操作使用单线程opencl核实现,从(2)的输出channel中读取数据,以流水线的方式依次处理每组输出特征图的池化操作。每组内的单个池化操作并行进行。每个时钟周期可实现一次池化操作。输出结果写入channel中。
(4)全局数据写入使用多线程opencl核实现,即向全局存储器写入处理完成的数据。每个线程块中的多个线程并行从(3)的输出channel中读取数据,并写入每组输出特征图的数据。多个线程块并行写入多组输出特征图的数据。每组特征图的数据以循环展开的方式并行写入全局存储器。
需说明的是,用于fpga平台的通用卷积神经网络实现架构,如lenet、alexnet、vgg-net、googlenet、resnet等,通过opencl语言实现。卷积神经网络的实现包括模型训练和和应用推理两个阶段。本发明适用于应用推理阶段。对于不同的卷积神经网络模型,采用不同的配置实现,即对于lenet、alexnet、vgg-net、googlenet、resnet等网络模型,只需要修改配置文件,即设置各层的参数即可实现,不用修改算法实现代码。
图4所示为本发明实施例4的基于fpga的卷积神经网络实现装置结构图。
如图4所示,根据本发明的实施例的一种基于fpga的卷积神经网络实现装置,包括:fpga处理器402和全局存储器404,其中,所述fpga处理器402与所述全局存储器404连接,
fpga处理器402,用于实现卷积神经网络中的多层之间串行处理,使用opencl编程语言在所述fpga上实现所述卷积神经网络的处理过程;
全局存储器404,用于所述卷积神经网络中的数据交互。
进一步地,所述fpga处理器402使用多线程opencl核从所述全局存储器中并行读取多个卷积操作处理的数据,使用单线程opencl核依次对所述卷积操作处理的数据进行卷积和激活操作,使用单线程opencl核依次对经过卷积和激活操作的数据进行池化操作,使用多线程opencl核向所述全局存储器写入经过池化操作的数据。
进一步地,所述卷积神经网络中每一层的数据处理结果通过channel进行传递;对每层的输入数据和输出数据均进行向量化处理。
进一步地,并行从所述全局存储器404读取多个卷积操作处理的数据、串行对多个所述卷积操作处理的数据进行卷积和激活操作、串行对所述数据进行池化操作、并行向所述全局存储器写入经过池化操作的数据。
进一步地,所述卷积神经网络的模型包括以下任意一种:
lenet,alexnet,vgg-net,googlenet、resnet。
卷积神经网络架构基于intel的softwaredevelopmentkit(sdk)开发环境和opencl语言实现。硬件平台安装intelsdk开发环境后,编译即可运行于不同的intelfpga平台。
通过以下方案:使用opencl编程语言在fpga上实现所述卷积神经网络的处理过程,解决由于卷积神经网络结构复杂,网络结构发展迅速,使用传统的vhdl/verilog语言开发效率低、成本高的问题。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!