一种针对非易失性内存的Shuffle方法与流程
本发明涉及大数据处理技术领域,特别涉及一种针对非易失性内存的shuffle方法。
背景技术:
随着科学技术的发展,当今世界已进入大数据时代,mapreduce是当下流行的一种用于大规模数据并行运算的编程模型,如何优化mapreduce的性能一直是业界热点。
shuffle是mapreduce框架中,介于map阶段和reduce阶段之间的一个特定的阶段,图1是mapreduce流程示意图,如图1所示,shuffle是指当map的输出结果要被reduce使用时,输出结果按key哈希,并且分发到每一个reduce上的过程,其中,shuffle涉及了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
现有技术中,针对shuffle阶段的优化主要有以下方法:
themis发表在proceedingsofthe3rdacmsymposiumoncloudcomputing(socc),2012上的文章,提出在shuffle阶段使用动态内存分配策略对该过程中的数据进行存储,即作业在处理数据的过程中,数据从磁盘的读写次数只有两次,其余过程都不会与磁盘交互;spongefiles发表在proceedingsofthe2014acmsigmodinternationalconferenceonmanagementofdata上的文章,提出共享task中未使用的内存空间,以上两种方法仅通过内存进行加速,对内存性能要求较高;
另外,sailfish发表在proceedingsofthe3rdacmsymposiumoncloudcomputing(socc),2012上的文章,提出在写shuffle数据时,聚集每个maptask相对应的分区的数据,利用分布式文件系统来存储相应的数据;hadoop-a发表在proceedingsofthe2011internationalconferenceforhighperformancecomputing,networking,storageandanalysis上的文章,提出利用高速网络(rdma)的特性,使用network-levitatedmerge算法来执行shuffle阶段,但以上两种方法的缺陷在于过于依赖网络性能,并且采用文件系统的方式进行数据的存取的时间开销较大。
因此,目前需要一种时间开销小且内存利用率高的shuffle优化方法。
技术实现要素:
本发明的目的是提供一种针对非易失性内存的shuffle方法,该方法能够克服上述现有技术的缺陷,具体包括以下步骤:
步骤1)、利用分区id将map任务的输出数据分别写入持久化缓冲区;
步骤2)、拉取reduce任务对应的所述持久化缓冲区中的数据。
优选的,所述步骤1)中,每个map任务的每个分区id分别对应一个私有持久化缓冲区。
优选的,所述步骤1)进一步包括:在数据写入时,判断对应的所述私有持久化缓冲区是否存在;如不存在,申请新的所述私有持久化缓冲区;否则执行数据写入当前私有持久化缓冲区。
优选的,利用所述私有化缓冲区与分区id之间的关联判断所述私有持久化缓冲区是否存在。
优选的,所述步骤1)进一步包括:在执行数据写入所述当前私有持久化缓冲区时,判断所述当前私有缓冲区是否满足数据大小,如满足,则执行数据写入,否则申请新的所述私有持久化缓冲区。
优选的,当一个私有持久化缓冲区写满时,记录所述私有化缓冲区及关联的分区id,从而在每个map任务的输出数据写入完成后,建立与所述map任务关联的映射表。
优选的,所述步骤2)进一步包括利用所述映射表执行数据拉取。
根据本发明的另一方面,还提供一种mapreduce编程方法,包括采用上述针对非易失性内存的shuffle方法。
根据本发明的另一方面,还提供一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其中,所述处理器运行所述程序时执行如上所述的步骤。
根据本发明的另一方面,还提供一种计算机可读存储介质,包括存储在所述可读存储介质上的计算机程序,其中,所述程序执行如上所述的步骤。
相对于现有技术,本发明取得了如下有益技术效果:本发明提供的针对非易失性内存的shuffle方法,利用nvm的特点,为大数据平台提供了java的持久化内存访问接口,使其能够直接使用与访问nvm;同时采用延迟分配策略将数据写入基于哈希的私有持久化缓冲区,一方面提升了nvm的空间利用率,另一方面提高了处理并发的效率;并且采用了映射表对nvm缓冲区进行管理,实现了数据读取阶段的快速定位。
附图说明
图1是mapreduce流程示意图。
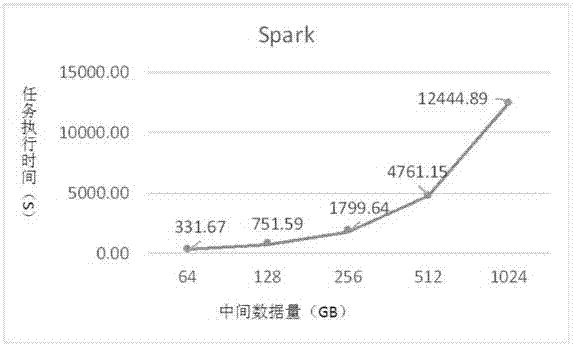
图2是shuffle数据量对于sort执行时间的影响曲线图。
图3是本发明提供的基于非易失内存的shuffle方法的架构图。
图4是本发明提供的基于哈希的私有持久化缓冲区划分示意图。
图5是本发明提供的延迟分配流程图。
图6是本发明提供的nvm缓冲区的读取示意图。
图7是本发明提供的映射表管理nvm缓冲区示意图
具体实施方式
为了使本发明的目的、技术方案以及优点更加清楚明白,以下结合附图,对根据本发明的实施例中提供的针对非易失性内存的shuffle方法进行说明。
为了研究shuffle性能对于整体性能的影响,发明人以sort应用为例,评测了该应用在spark上的运行时间随着shuffle数据量的变化的结果。
图2是shuffle数据量对于sort执行时间的影响曲线图,如图2所示,随着shuffle数据量的增大,spark的性能大幅度地下降。这是由于在执行map任务与reduce任务之间的数据读取时,数据是进行分区的,因此对于某一个reduce任务而言,从一个map任务中读取的数据量是与reduce任务总数量成反比,这会导致大量的小粒度和随机读,极易造成磁盘性能的下降,影响作业的执行时间。所以i/o开销是影响shuffle性能的一个重要因素,尤其是对基于内存计算的大数据处理平台,例如spark,shuffle阶段的i/o开销可能大大延长数据处理的时间。
为了优化shuffle阶段的读写性能,以便缓解i/o性能瓶颈,发明人发现非易失性内存(non-volatilememory,nvm)在内存计算的场景下有着广泛的应用场景。nvm是一种断电时其内容仍能保持的非易失、可持久化的内存。nvm有着与dram相接近的读写延迟和吞吐率,但nvm的存储密度比dram更大,与nandflashssd相似。但是对于nvm现有的系统软件,例如nvm文件系统,其开销过高,不能充分发挥nvm的性能,针对上述问题,发明人经研究,提出了一种高效使用nvm来提升shuffle阶段的i/o性能的方法。
在本发明的一个实施例中,提供一种针对非易失性内存的shuffle方法,该方法采用持久化内存的方式,直接在用户态访问持久化内存。
图3是本发明提供的基于非易失内存的shuffle方法的架构图,如图3所示,本发明的针对非易失性内存的shuffle方法通过建立作为java的持久化内存访问接口的nv-shuffle接口,使大数据平台能够直接使用与访问nvm,具体包括以下步骤:
s10.将数据写入缓冲区
当map开始产生输出时,数据首先写入到内存中的缓冲区。发明人提出了一种将数据写入基于哈希的私有持久化缓冲区的方法,即通过分区id和map任务对nvm缓冲区进行区分,使每个map任务的每个分区id都对应一个单独的持久化缓冲区。例如,图4是本发明提供的基于哈希的私有持久化缓冲区划分示意图,如图4所示,在job执行时,maptask的个数是m,每个task在数据进行partition后对应有n个id,则可将nvm缓冲区相应划分为m*n个nv-buffer,使得m个task分别按n个id对应单独的持久化缓冲区。
通过采用上述方法,可以使任务在并发写时没有锁竞争开销,同时可以将各任务之间的数据利用私有持久化缓冲区完成隔离,当部分任务数据失效时,直接进行删除即可,不会影响其他任务的数据。
s20.采用延迟策略分配缓冲区
在执行步骤s10,将每个map任务的输出数据写入私有持久化缓冲区时,可以根据参数,例如io.sort.mb,来设置缓冲区的大小。
为了有效的利用nvm缓冲区的存储空间,发明人提出了一种延迟策略,图5是本发明提供的延迟分配流程图,如图5所示,当需要将一个map任务的输出数据,按分区id写入其对应的私有持久化缓冲区时,首先需要判断对应的nv-buffer是否存在,如果不存在,则申请新的nv-buffer,进行数据的写入,其中,可以利用步骤s10在进行划分时,私有化缓冲区与分区id之间的关联判断所述私有持久化缓冲区是否存在;如果存在,则判断当前nv-buffer的空间是否满足数据大小;如果不满足,则申请新的nv-buffer,进行数据的写入;如果满足,则将数据写入到nv-buffer中。通过采用上述延迟的分配策略,能够大幅度提升nvm缓冲区的空间利用率。
s30.利用映射表管理缓冲区
在利用s20的延迟策略为每个map任务的每个id都分配一个单独的持久化缓冲区后,每个reduce任务将对map任务的输出数据进行读取。由于reduce任务拥有多个线程,可以并行的获取map输出,同时reduce任务的输入数据分布在集群内的多个map任务的输出中。发明人提出使用映射表方式来存储步骤s10获得的分区id与nvm缓冲区的对应关系,以便在数据读取过程中快速的定位。
例如,图6是本发明提供的nvm缓冲区的读取示意图,如图6所示,共有n'个reduce任务需要读取与之对应的数据,由于这些数据是根据分区id进行区分的,所以在读取的过程中,一个分区id会对应多个nv-buffer,例如,reducetask1'读取map各task中的id为p1的数据,reducetask2'读取map各task中的id为p2的数据……reducetaskn'读取map各task中的id为pn的数据。
为了提高reduce任务的读取效率,发明人提出,在完成上述步骤s10,s20后,建立映射表以记录记录分区id与nv-buffer之间的对应关系。例如,图7是本发明提供的映射表管理nvm缓冲区示意图,如图7所示,为每个maptask分别建立一个映射表,当该maptask所对应的一个nv-buffer写满时,将相应的<分区id,nv-buffer>添加到上述映射表中,在该maptask执行完成之后,将该映射表的内容上传到driver中;在reducetask拉取数据时,可以先从driver处获取表示分区id与nv-buffer之间的对应关系的映射表,再依据其上记录的位置信息进行数据拉取。
通过采用映射表的方式对nvm缓冲区进行管理,提高了定位速度,有利于读取数据,并且在出现故障之后能够进行快速的数据恢复。
相对于现有技术,在本发明实施例中所提供的针对非易失性内存的shuffle方法,充分利用了nvm的优势,提供一种java的持久化内存访问接口,即nv-shuffle接口,使大数据平台能够直接使用与访问nvm;利用基于哈希的私有持久化缓冲区来组织shuffle阶段的数据,可以实现高效处理并发、错误厝里、网络传输等方面的问题;同时采用了延迟分配策略提升nvm的空间利用率,以及映射表方式提高对缓冲区的管理。通过使用该方法能够高效的利用nvm提升shuffle阶段的i/o性能,尤其特别适用于shuffle阶段的数据量大且所占的时间比例大的shuffle-heavy类型的负载,例如,sort负载。
虽然本发明已经通过优选实施例进行了描述,然而本发明并非局限于这里所描述的实施例,在不脱离本发明范围的情况下还包括所作出的各种改变以及变化。
- 还没有人留言评论。精彩留言会获得点赞!