一种基于可靠队列服务的高效分布式爬虫系统设计的制作方法
本发明涉及计算机软件领域,特别是涉及分布式信息抓取,行业数据积累使用场景。
背景技术:
随着信息技术的发展,人们获取信息的方式也越来越精进,人们不再只是通过报纸和电视来获取各种资讯信息,而是通过app应用来查看app应用提供商已经归纳好的资讯信息。这些app应用提供商中,当然也包括大部分互联网金融企业。爬⾍系统,⼜称作“网络蜘蛛系统”是⼀种按照⼀定的规则⾃动的从万维⽹中各个⽹站抓取信息的系统。互联⽹⾦融企业积累⾏业数据需要从⾏业相关站点抓取有价值的内容信息,因此都需要建⽴⾃⼰的⼀套爬⾍系统。爬虫系统利用万维网及时抓取企业所需要的资讯信息,通过对不同的抓取目标网站配置相应规则来实现个性化内容抓取。
爬⾍系统设计是否优良主要看以下⼏个⽅⾯:
(1)爬⾍系统的稳定性,即是否存在单点故障;
(2)爬⾍系统的及时性,即站点新发布的内容是否在要求的时间内被系统抓取到;
(3)爬⾍系统的伸缩性,即当需要爬取的站点增多或减少时,爬⾍系统是否能够轻易地通过增加或减少系统资源(系统资源包括:进程数,机器数量,外⽹带宽等等)来适应相应的爬取压⼒;
(4)爬⾍系统的可控性,即是否能够对重要度不同的站点分配适宜的系统资源,是否能通过配置来实现对不同站点的个性化抓取;
(5)爬⾍系统的有效监控,即是否能够有效监控爬⾍系统的运⾏状态,包括:页⾯解析错误,各站点的实时抓取数量,提供报警机制等等。
该发明从以上各个⽅⾯着⼿,基于通过binlog⽅式实现的主从队列服务创造出了⼀个⾼效,稳定,可靠,可伸缩的分布式爬⾍系统。
技术实现要素:
本发明的目的是为了解决目前互联网金融企业无法高效可靠地积累资讯数据的问题,设计出一种基于binlog主从队列服务,并且具有高稳定性、及时性、高伸缩性、可控性的分布式爬虫系统。
为了解决上述问题,本发明采用的技术方案是:总体上采用分布式系统架构。系统整体可分成七大模块:调度模块、抓取及页面解析模块、附件处理模块、图片处理模块、监控模块、配置平台模块、http代理模块。
同时为实现合理的调度功能,系统的核心模块:调度模块和抓取及页面解析模块通过基于binlog实现主从逻辑的可靠队列服务来进行通信。
进一步,所述调度模块为爬虫系统负责调度待抓取站点的模块,不同的待抓取站点重要程度不同,调度的频率和优先级就存在差别;“通常重要度高的站点调度要频繁一些,分配的抓取资源要多一些”,调度模块正是实现这一点而设计的。
进一步,所述抓取及页面解析模块为爬虫系统负责下载页面及解析页面结构化字段的模块。
进一步,所述附件处理模块为爬虫系统负责下载页面的附件并存储的模块。
进一步,图片处理模块为爬虫系统负责下载图片、上传图片至cdn、替换原网页img标签的模块。
进一步,监控模块为爬虫系统负责监控各个需要爬取的站点日爬取状态的模块,同时它还负责监控队列服务的队长,防止系统负载过重而带来的抓取不及时等问题。
进一步,配置平台模块为爬虫系统的web控制台,负责配置各个需要抓取站点的调度规则、结构化字段样式,同时它还以图表的形式展示监控模块统计的监控数据。
进一步,http代理模块为爬虫系统提供应对一些站点的反爬虫功能;通过对几十上百个动态ip进行http代理,使得站点针对某些ip实行封禁的反爬虫策略失效。
由于采用上述方案,本发明的有益效果是:
(1)系统稳定性、可靠性强。本爬虫系统中的所有模块均可采用多点部署,并且对系统资源使用最多的模块“抓取及页面解析模块”是“无状态的”,一个或多个模块挂掉不影响系统整体的运行;
(2)伸缩、扩展性强。本爬虫系统可以根据需要爬取的资源数量,动态的增加或减少相应模块部署的数量。这里的“资源”可以是站点数量、页面数量,也可以是附件下载量,所需处理的页面图片流量,伸缩的“粒度”不可谓不精细;
(3)可控性强。本爬虫系统,可以通过配置平台模块来控制不同站点的抓取频率、抓取的结构化字段,对企业积累自己的资讯数据提供及时、个性化的强力保证。
附图说明
图1是本发明的系统架构图。
图2是本发明的系统调度流程图。
图3是本发明的配置存储结构er图。
图4是本发明的数据存储结构er图。
具体实施方式
下面结合附图对本发明的较佳实例进行详细阐述,以使本发明的优点和特征更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
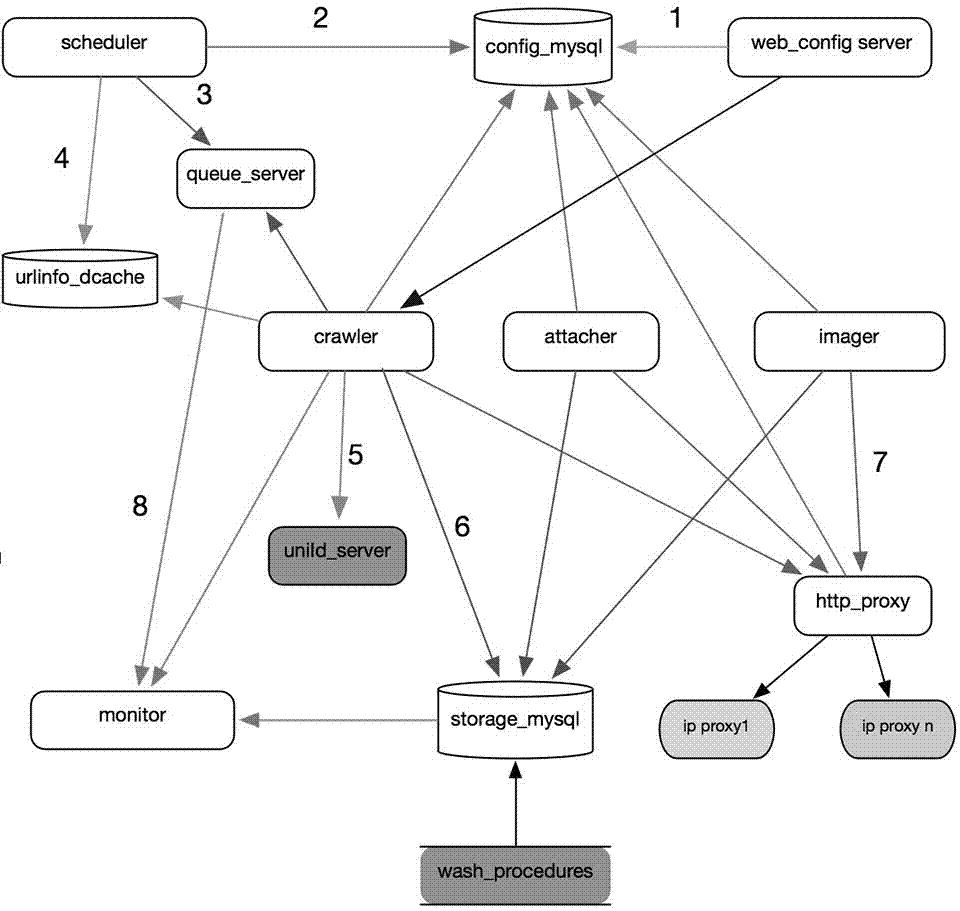
图1为本发明的基础架构图:
模块scheduler为调度模块,负责根据需要抓取的站点的重要程度不同来合理地确定调度频率,和分配抓取资源;
模块crawler为抓取与页面解析模块,主要⽤来下载⽹⻚以及抽取链接或者结构化字段,⽆状态,可同时启⽤多个;
模块attacher为附件抓取模块,主要⽤来抓取⽹页页⾯可能存在的附件,⽆状态,可同时启⽤多个;
模块imager为图⽚抓取模块,主要⽤来抓取⽹页页⾯可能存在的图⽚,上传cdn后替换原⽹站的图⽚地址到抓取的⻚⾯数据中,⽆状态,可同时启⽤多个;
模块queue_server通过binlog⽅式实现的主从同步队列服务模块,总共包含两种队列,“总队列”和“待调度站点队列”;
模块monitor为抓取监控模块,实时监控各站点的抓取情况,提供抓取异常报警机制;
模块web_config_server为爬⾍系统站点配置控制台模块,⽤来可视化编辑各爬取站点的配置;
数据库config_mysql:各站点配置信息存放的mysql数据库,配置信息包括了各站点的权重,以及最终落地数据库的结构化字段的抓取特征(cssselector,regex);
数据库storage_mysql为抓取数据最终落地的mysql数据库;
模块http_proxy为⽤来应对拥有“反爬⾍”机制⽹站的http代理模块,它可以动态分配不同ip供有下载需求的服务进⾏http代理下载;
模块urlinfo_dcache为⽤来保存链接爬取状态的key-value形式的nosql数据库,爬⾍系统主要使⽤它来滤重以及跟踪链接爬取得状态;
模块uniid_server为成全局唯⼀的id号的服务,供多个crawler调⽤,保证落地数据id的唯⼀性。
图2为本发明的系统调度流程图,结合图1所示,对步骤进行详细描述:
流程1-1为调度模块scheduler将种子链接放入“总队列”中;
流程2为抓取与页面解析模块将要下载和进行解析的连接从“总队列”中取出;
流程3-1为抓取与页面解析模块如果处理链接是详情页链接,则直接把解析出来的结构化字段信息存入结果库;
流程3-2为抓取与页面解析模块如果处理的链接为列表页,则把解析出来的下一级列表页或者详情页放入相应站点对应的“待抓取队列”中;
流程4为调度模块根据各个站点的抓取频率和权重来适宜地从各个“待抓取队列”中获取适宜数量的待抓取链接,然后通过流程1-2,将这些链接放入总队列中。
图3为配置存储结构er图。下面对具体的er图实体进行说明:
t_crawl_config为基本配置表,对应为某个网站额某一类页面,例如:“新浪博客新闻列表页”或者“东方财富国际新闻详情页”;
t_crawl_detail_pattern为详情页模板配置表,t_crawl_config和t_crawl_detail_pattern为1对多的关系,可以理解为某一类详情页的页面可能有多种版面,所以需要抽取结构化字段的特征值也会有所不同;
t_crawl_list_template为列表页模板配置表,它和t_crawl_detail_template与t_crawl_config的关系有些类似,只是列表页和详情页关注的结构化字段会有所不同,因而会有差别;
以上各表各字段的含义基本可以做到“见名知意”。
图4为本发明的数据存储结构er图。结合图4所示,对对具体的er图实体进行说明:
t_temp_storage_***为资讯存储的主表,存储了爬取解析到的资讯详情结构化信息,例如:标题,作者,资讯内容等;
t_temp_attach_***为资讯附件信息表,存储了爬取到的资讯详情页所带的附件;
以上各表各字段的含义基本可以做到“见名知意”;
表2大致列出了表t_temp_storage_***和表t_temp_attach_***的字段含义。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所做的等效结构或等效流程变化,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!