基于深度神经网络的端到端的图像多字符定位和匹配方法与流程
本发明涉及人工智能技术领域,更具体地,涉及一种基于深度神经网络的端到端的图像多字符定位和匹配方法。
背景技术:
对于两张包含有相同字符的图片,查询图x和被查询图y,现有技术主要通过以下方法对查询图x中的字符在被查询图y中的位置进行定位及匹配:
s1.首先基于卷积神经网络识别出查询图x中从左到右出现的字符内容;
s2.基于dbscan算法定位被查询图y中的所有字符,并将它们从被查询图y中切割出来;
s3.基于卷积神经网络识别切割出来的所有字符内容;
s4.将步骤s1中识别出的字符内容与步骤s3中识别出的字符内容进行匹配,即可得到查询图x中的字符在被查询图y中的位置。
但是上述方案在进行定位和匹配的时候是将整个流程划分为四个步骤的,每个流程步骤在执行的时候均需要花费不少时间,这导致方法的运行效率较低,且最终定位和匹配的准确率依赖于每个流程步骤的准确率,若其中某一流程步骤的准确率不高,将会导致方法的准确率不高。
技术实现要素:
本发明为解决以上现有技术的缺陷,提供了一种基于深度神经网络的端到端的图像多字符定位和匹配方法。
为实现以上发明目的,采用的技术方案是:
基于深度神经网络的端到端的图像多字符定位和匹配方法,包括有以下步骤:
s1.令查询图片与对应的被查询图片为一对图片对,收集大量的图片对作为数据集,并对图片对中查询图片中的字符在被查询图片中的位置进行标注;
s2.将数据集按照一定比例划分为三部分,分别为训练集、验证集和测试集;
s3.搭建深度神经网络,利用训练集中的图片对作为输入对深度神经网络进行训练,并利用adam算法对深度神经网络进行优化;
s4.使用验证集中的图片对作为输入对优化后的深度神经网络进行验证,深度神经网络输出图片对中查询图片中的字符在被查询图片中的定位及匹配结果,由于步骤s1已经对图片对中查询图片中的字符在被查询图片中的位置进行标注,因此可计算深度神经网络在验证集上的准确率;
s5.重复步骤s3~s4直至深度神经网络在验证集上的准确率满足设定的条件;
s6.将测试集中的图片对作为输入对步骤s5训练好的深度神经网络进行测试,并根据深度神经网络输出的测试结果对深度神经网络的在测试集上的准确率进行统计,作为对深度神经网络的评估结果;
s7.对于新的一对图片对,将其作为深度神经网络的输入,即可通过深度神经网络得到图片对中查询图片中的字符在被查询图片中的定位及匹配结果。
与现有技术相比,本发明的有益效果是:
1)方法的运行效率更高,整个方法流程在深度神经网络训练好之后,每次使用,只需要经过一次深度神经网络的前向传播计算,而不像现有方法有多个神经网络需计算多次,还有用聚类算法做字符提取等比较耗时的步骤。
2)方法的准确率更高。整个方法流程就是直接优化最终目标的准确率,通过深度神经网络可以很好的做到这一点。而现有技术,最终目标的准确率依赖于各个步骤流程的准确率,由于只能分别优化各个步骤的准确率,没法直接优化最终目标,导致准确率较低,也很难改进。
附图说明
图1为方法的原理示意图。
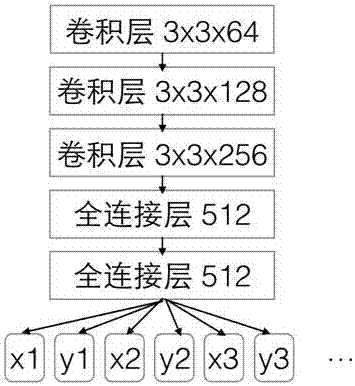
图2为深度神经网络的结构示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
本发明提供的方法具体包括有以下步骤:
s1.令查询图片与对应的被查询图片为一对图片对,收集大量的图片对作为数据集,并对图片对中查询图片中的字符在被查询图片中的位置进行标注;
s2.将数据集按照7:2:1的比例划分为三部分,分别为训练集、验证集和测试集;
s3.搭建深度神经网络,利用训练集中的图片对作为输入对深度神经网络进行训练,并利用adam算法(考虑动量和梯度历史大小的梯度下降法)对深度神经网络进行优化,调整学习率等参数;训练过程中,如果发现深度神经网络的偏差较高,方差较低,则应当继续使用adam算法,迭代多轮;如果发现偏差较低,方差较高,此时应收集更多数据作为训练集,或者减少梯度优化算法迭代的轮数;
s4.使用验证集中的图片对作为输入对优化后的深度神经网络进行验证,深度神经网络输出图片对中查询图片中的字符在被查询图片中的定位及匹配结果,具体如图1、图2所示,由于步骤s1已经对图片对中查询图片中的字符在被查询图片中的位置进行标注,因此可计算深度神经网络在验证集上的准确率;
s5.重复步骤s3~s4直至深度神经网络在验证集上的准确率满足设定的条件;
s6.将测试集中的图片对作为输入对步骤s5训练好的深度神经网络进行测试,并根据深度神经网络输出的测试结果对深度神经网络的在测试集上的准确率进行统计,作为对深度神经网络的评估结果;
s7.对于新的一对图片对,将其作为深度神经网络的输入,即可通过深度神经网络得到图片对中查询图片中的字符在被查询图片中的定位及匹配结果。
其中,所述步骤s3、s4、s6、s7将图片对作为深度神经网络的输入时,是将查询图片、被查询图片的rgb像素值作为两个矩阵输入至深度神经网络中,深度神经网络经过前向传播的运算,计算得到的输出有多个值,这些值的含义是查询图片中的字符,按从左到右的顺序,在被查询图片中的位置坐标。最终还有两个-1,-1结束标志符,代表所有字符位置已经全部输出。在结束标志符前面的所有数字,每相邻两个组合,就是字符位置坐标。
本实施例中,如图2所示,所述深度神经网络基于keras深度学习框架进行搭建,深度神经网络包括有从左到右依次连接的三层卷积层和两层全连接层。其中所述第一层卷积层的卷积核大小为3x3,卷积核个数为64个,激活函数是relu函数。第二层卷积层的卷积核大小为3x3,卷积核个数为128个,激活函数是relu函数。所述第三层卷积层的卷积核大小为3x3,卷积核个数为256,激活函数是relu函数。所述第一层全连接层的维数为512,激活函数是relu函数。所述第二层全连接层的维数为512,激活函数是relu函数。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
技术特征:
技术总结
本发明涉及一种基于深度神经网络的端到端的图像多字符定位和匹配方法,其具有以下有益效果:1)方法的运行效率更高,整个方法流程在深度神经网络训练好之后,每次使用,只需要经过一次深度神经网络的前向传播计算,而不像现有方法有多个神经网络需计算多次,还有用聚类算法做字符提取等比较耗时的步骤。2)方法的准确率更高。整个方法流程就是直接优化最终目标的准确率,通过深度神经网络可以很好的做到这一点。而现有技术,最终目标的准确率依赖于各个步骤流程的准确率,由于只能分别优化各个步骤的准确率,没法直接优化最终目标,导致准确率较低,也很难改进。
技术研发人员:费行健;潘嵘
受保护的技术使用者:中山大学
技术研发日:2017.10.27
技术公布日:2018.02.02
- 还没有人留言评论。精彩留言会获得点赞!