基于单肿瘤样本拷贝数变异及缺失类型检测方法、计算机与流程
本发明属于拷贝数变异检测技术领域,尤其涉及一种基于单肿瘤样本拷贝数变异及缺失类型检测方法、计算机。
背景技术:
目前国内外已有专家提出多种拷贝数变异检测方法,这些方法大致可分为三种类型:基于多个肿瘤样本的拷贝数变异检测,其中第一种类型侧重于检测多样本中一致性拷贝数变异模式,为同一种类的癌症发现共同变异模式,为致病基因的发现及研究提供科学依据;第二种类型和第三种类型的检测方法侧重于对某一病人的基因组进行拷贝数变异检测,以观察致病基因或潜在致病基因是否发生变异,为疾病的预测、诊断、靶点药物的寻找提供科学依据。在实际医疗过程中,考虑到DNA测序的成本问题,往往仅对肿瘤组织进行测序,而并没有对非肿瘤组织进行采样及测序。目前针对单肿瘤样本的拷贝数变异检测,但其检测性能较低,即正确检测率不高且假阳性过高。CNVnator和readDepth 方法主要通过分析全基因组或染色体读段数的差异性,构建统计计算模型,从而检测显著的拷贝数变异;FREEC方法是通过对全基因组GC含量进行分析,利用GC含量在不同基因组片段中的偏差性推断拷贝数的扩展与缺失状态。这些方法均未考虑拷贝数扩增与缺失幅度的不平衡性,从而使得拷贝数变异幅度不太明显的区域难以被检测。具体来说,拷贝数扩展幅度可从3高达几十甚至上百,而拷贝数缺失幅度只有1和0,那么相应的测序读段数会在拷贝数扩展区域和拷贝数缺失区域产生明显的区别,利用这样的数据构建拷贝数检测基准及检验分布,往往会导致偏差,如以全基因组的读段数均值为基准,结合其方差建立检验分布,那么该基准往往接近拷贝数扩增幅度较小的区域,如下图场景所示,其平均读段数为50,对应于第2段扩增区域,以该平均读段数为基准,那么第2段区域无法被检测出,同时其它正常区域还有可能会被检测为拷贝数缺失。另一个方面,现有多数方法没有充分考虑肿瘤纯度引起肿瘤测序数据的偏差,即:在测序过程中所测序的肿瘤组织往往含有一定量的正常细胞,从而使得所观察到的数据是一个肿瘤-正常细胞的混合信号,降低了肿瘤细胞中读段数在发生拷贝数变异与未发生变异区域中的差异性,这无疑增加了拷贝数变异检测的难度,而如果没有充分考虑该问题,那么拷贝数变异幅度较小的区域也不能被检测。最后,目前现有多数方法没有考虑拷贝数缺失类型的检测问题,即杂合子缺失和同源缺失,而这两种缺失对于生物功能会有不同的表现。
综上所述,现有技术存在的问题是:对基因组读段数的基准难以定位;现有基于单肿瘤样本的方法在拷贝数变异检测过程中,没有考虑肿瘤组织的纯度问题,且没有考虑拷贝数缺失类型的检测,使得拷贝数变异准确度下降,且无法提供杂合子缺失与同源缺失的信息。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于单肿瘤样本拷贝数变异及缺失类型检测方法、计算机。
本发明是这样实现的,一种基于单肿瘤样本拷贝数变异及缺失类型检测方法,所述基于单肿瘤样本拷贝数变异及缺失类型检测方法建立拷贝数扩展和拷贝数缺失幅度的动态平衡机制,迭代检测过程不断更正读段数的基准,更正统计检验分布的参数,客观检测显著性拷贝数变异以及弱显著的拷贝数变异;构建贝叶斯推理模型,正确检测拷贝数变异状态及拷贝数缺失类型。
进一步,所述基于单肿瘤样本拷贝数变异及缺失类型检测方法利用读段数服从泊松分布的性质,计算每个bin的概率值,依据概率值建立正态分布,计算每个bin的p值,设置显著性水平阈值,低于阈值的bins发生了显著的拷贝数变异;
将显著的bins剔除掉,重复利用对RC进行平衡,重新构建零分布,检测弱显著的拷贝数变异。
进一步,所述构建贝叶斯推理模型位:
拷贝数扩展与缺失,拷贝数杂合子缺失与同源缺失状态:
先验概率通过显著的bins概率进行估计,条件概率p(bini∈CNV|gain)和 p(bini∈CNV|loss)通过观察到的RC值计算:
进一步,所述基于单肿瘤样本拷贝数变异及缺失类型检测方法的数据输入包括:SAM文件,Read.txt文件以及参考序列。
进一步,所述基于单肿瘤样本拷贝数变异及缺失类型检测方法的读段数规整化处理包括:比对后的读段数,设置bin的大小为1000,计算每个bin的read count(RC),进行规整化处理,对GC含量进行更正并对RC进行平衡化处理:
其中,表示所观察到的第i个bin的RC,和分别表示全基因RC平均值和哪些与第i个bin具有相同GC含量bins的RC平均值,re表示错误比对的RC,L_read,N_read,和L_bin分别表示读段的长度,SAM文件中读段的个数,以及全基因组中bin的个数,Qj表示第j个读段的比对质量;rmax和rmin分别表示全基因中最大的RC和最小的RC。
本发明建立拷贝数扩展和拷贝数缺失幅度的动态平衡机制,通过迭代检测过程不断更正读段数的基准,更正统计检验分布的参数,以客观检测显著性拷贝数变异以及弱显著的拷贝数变异。
本发明充分考虑肿瘤组织纯度及比对错误问题,构建贝叶斯推理模型,以正确检测拷贝数变异状态及拷贝数缺失类型,提供杂合子缺失与同源缺失的信息。
本发明考虑比对质量及错误问题,合理地更正了全基因组GC含量,而现有方法在GC更正时都没有考虑比对质量及错误;本发明建立拷贝数扩展和拷贝数缺失幅度的动态平衡机制,以准确定位拷贝数的基准,准确检测拷贝数的变异状态,而现有方法大多以全基因组读段数均值作为基准,对于高度复杂变异的测序数据难以获得客观的检测性能。
本发明构建了贝叶斯推理模型,对显著的bins进行拷贝数扩增和缺失状态的推理;同时利用肿瘤纯度构建拷贝数同源缺失条件概率的计算模型,以客观对杂合子缺失和同源缺失进行区分。如在真实数据中,同源缺失并不意味着该片段的读段数为0,因为测序过程中极有可能采集到测序组织中正常组织的 DNA,从而使得肿瘤细胞中发生同源缺失,而观察到的读段数并不为0;因此,本发明考虑的肿瘤纯度有利于正确区别杂合子缺失和同源缺失。
本发明为病人个性化的检测与治疗提供数据参考,提供了更全面、更丰富的基因组变异数据,为深入理解生命机理、癌细胞发展机制提供了重要数据支撑。本发明建立以统计理论为基础的计算方法,构建动态平衡机制及贝叶斯推理模型,检测单肿瘤样本中拷贝数变异模式,为医生对病人的诊断提供依据。本发明能够在缺乏对照样本的情况下,对测序深度较低的单肿瘤样本准确检测拷贝数变异;能够检测拷贝数缺失类型,即杂合子缺失和同源缺失;通过动态平衡拷贝数扩展和拷贝数缺失幅度,更正统计检验分布参数(即均值和方差),以检测显著性较弱的拷贝数变异。
附图说明
图1是本发明实施例提供的基于单肿瘤样本拷贝数变异及缺失类型检测方法流程图。
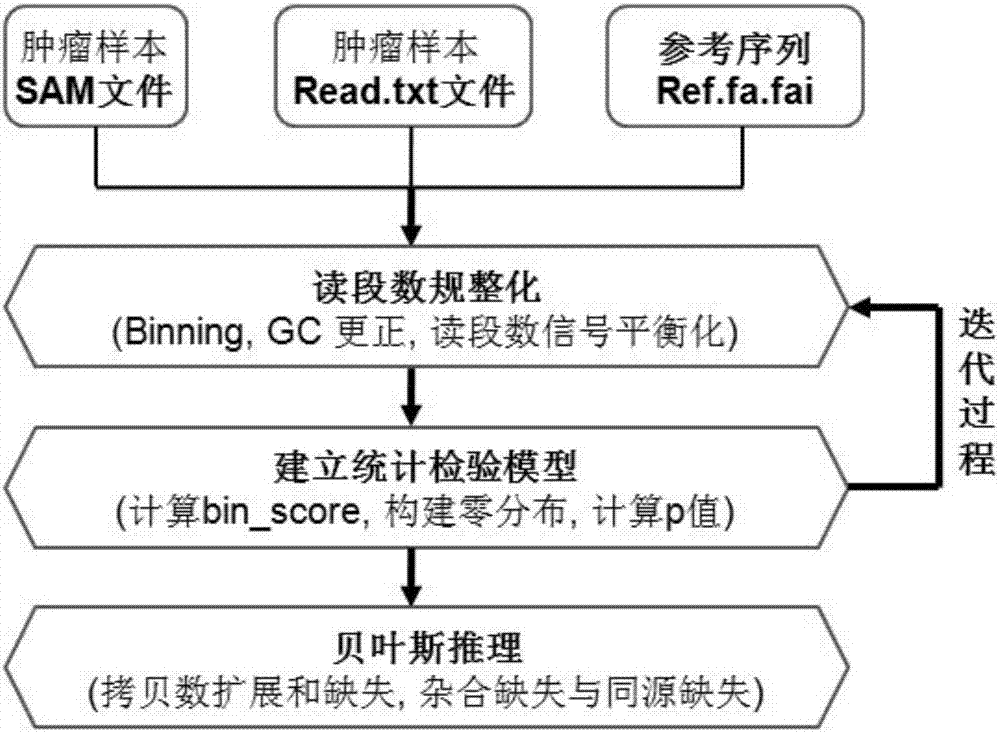
图2是本发明实施例提供的基于单肿瘤样本拷贝数变异及缺失类型检测方法的实现流程图。
图3是本发明实施例提供的基于单肿瘤样本拷贝数变异及缺失类型检测方法方法(CONDEL)与FREEC,ReadDepth,CNVnator,CNV-seq,SeqCNV及cn.MOPS 进行性能对比图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明构建以统计理论为基础的拷贝数扩增与缺失幅度的动态平衡机制及贝叶斯推理模型,以检测单肿瘤样本中多样化的拷贝数变异形式及拷贝数缺失类型,为癌症预测、诊断、靶点药物查找提供可靠依据。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的基于单肿瘤样本拷贝数变异及缺失类型检测方法包括以下步骤:
S101:建立拷贝数扩展和拷贝数缺失幅度的动态平衡机制,通过迭代检测过程不断更正读段数的基准,更正统计检验分布的参数,客观检测显著性拷贝数变异以及弱显著的拷贝数变异;
S102:构建贝叶斯推理模型,以正确检测拷贝数变异状态及拷贝数缺失类型,提供杂合子缺失与同源缺失的信息。
下面结合附图对本发明的应用原理作进一步的描述。
如图2所示,本发明实施例提供的基于单肿瘤样本拷贝数变异及缺失类型检测方法包括以下步骤:
(1)数据输入,SAM文件,Read.txt文件,以及参考序列。
(2)读段数规整化处理。在输入文件的基础上,针对比对后的读段数,设置bin的大小为1000,计算每个bin的readcount(RC),设计以下公式进行规整化处理,即对GC含量进行更正并对RC进行平衡化处理:
其中,表示所观察到的第i个bin的RC,和分别表示全基因RC平均值和哪些与第i个bin具有相同GC含量bins的RC平均值,re表示错误比对的RC,L_read,N_read,和L_bin分别表示读段的长度,SAM文件中读段的个数,以及全基因组中bin的个数,Qj表示第j个读段的比对质量。
公式(3)主要是用于对读段数进行平衡化处理,其中rmax和rmin分别表示全基因中最大的RC和最小的RC,这样做的好处是能够平衡潜在的拷贝数扩增与缺失幅度,以构建合理的统计检验分布。
(3)建立统计检验模型
在进行GC含量更正及RC平衡化处理基础之上,利用读段数服从泊松分布的性质,计算每个bin的概率值,依据该概率值建立正态分布(即零分布),进而计算每个bin的p值。设计显著性水平阈值,如0.01,0.001等。低于该阈值的bins被认为发生了显著的拷贝数变异。
为了建立更真实的零分布,设计迭代检测过程,即将显著的bins剔除掉,重复利用公式(3)对RC进行平衡,进而重新构建零分布,以检测弱显著的拷贝数变异。这种动态平衡的好处是可以将正态分布的均值逐渐接近拷贝数的基准,客观检测拷贝数变异。
(4)基于贝叶斯理论的拷贝数变异状态推导
针对显著的bins,通过构建贝叶斯推理模型,如公式(4)和(5),对拷贝数扩展与缺失,拷贝数杂合子缺失与同源缺失状态进行推理:
针对公式(4)其贝叶斯概率计算方法如公式(6)和(7)。其中先验概率可以通过显著的bins概率来进行估计,而条件概率p(bini∈CNV|gain)和 p(bini∈CNV|loss)可通过观察到的RC值计算。类似地,针对公式(5),也可采用同样的方法进行计算:
在条件概率计算过程中,本发明充分考虑了肿瘤纯度、比对错误等因素带来的影响,有效降低拷贝数变异状态及缺失类型检测错误率。
下面结合仿真对本发明的应用效果作详细的描述。
将本发明方法(CONDEL)与其他同行方法FREEC,ReadDepth,CNVnator, CNV-seq,SeqCNV,及cn.MOPS进行性能比较。具体过程如下:以人类参考序列21号染色体为基础,利用IntSIM仿真系统模拟14个拷贝数变异(包括6个扩展区域,4个杂合子缺失和4个同源缺失区域),根据肿瘤纯度和测序覆盖深度设置两中不同的仿真,每一种仿真产生50组数据。在该数据集上对本发明方法(CONDEL)与其他同行6中方法进行实验并比较其性能,如下图所示,利用boxplot刻画7种方法的正确识别率。从图3中可见,本发明方法具有较高和相对稳定的正确识别率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!