基于深度学习和环境自适应的目标跟踪算法的制作方法
本发明涉及计算机视觉的目标跟踪领域,更具体地,涉及一种基于深度学习方法来对环境自适应的目标跟踪算法。
背景技术:
人类是通过感觉来与外界联系和沟通的,但是人的精力和视野是非常有限的。因此在各个领域的应用中,人类的视觉是受到了很大的限制甚至低效的。在数字计算机技术飞速发展的今天,计算机视觉也越来越引起人们的广泛关注,人们意图用计算机来代替人的“眼睛”,使之具有智能化,让计算机能够处理视觉信息、完善人类视觉上的诸多短板。计算机视觉是融合了人工神经网络、心理学、物理学、计算机图形学以及数学等众多领域的一门交叉性很强的学科。
目前在计算机视觉领域,目标跟踪是非常活跃的课题之一,人们也越来越把注意点放在了这个领域上。目标跟踪的应用领域非常广泛,例如,动作分析、行为识别、监控和人机交互等都用到了这方面的知识,在科学和工程中有着重要的研究价值与极大的应用前景,吸引着国内外大批研究者的兴趣。
深度学习已经很好的应用于图像处理方向当中,为目标跟踪方向提供了一种新的解决思路。在目标跟踪领域,利用深度学习的深层架构自动地从获取的样本中学习更加抽象和本质的特征,从而来测试新的序列。结合深度学习方法的跟踪技术,在性能上逐渐超越了传统的跟踪方法,成为了这一领域的一个新趋势。
迄今为止,在国内外公开发表的论文和文献中尚未见开展有关基于深度学习和环境自适应的目标跟踪算法。
技术实现要素:
基于上述现有技术,本发明提提出一种基于深度学习和环境自适应的目标跟踪算法,利用卷积神经网络,自适应调节网络的参数,使得跟踪器在多种跟踪场景都有很高的准确率结合显著性检测的预处理优势,。
本发明的一种基于深度学习和环境自适应的目标跟踪算法,该方法包括以下步骤:
步骤1、采用107×107像素点大小的图片作为输入;
步骤2、预处理包括正样本预处理和负样本的处理,包括正样本预处理和负样本预处理;其中,正样本预处理的步骤包括:首先,根据groundtruth值在正样本中的目标周围取一个比目标的groundtruth值大矩形,计算正样本的显著图,占整个采样框的比例,若是比例大于设定的某个阈值,当成纯正的正样本,若是比设定的阈值小,则予以丢弃;然后,利用显著性检测算法检测出目标的形状,然后将得到的显著图二值化,将其插回原来的一帧的图像中,再根据前面的采样的流程对二值化之后的整帧图像来进行采样;负样本预处理的步骤包括:使用难例挖掘算法对于负样本进行筛选,将采样的样本在卷积神经网络中进行一次正向传播,将loss比较大的样本按照顺序排列,,并将前面的选出来作为“难例”,用这部分样本来训练网络;
步骤(3)、在第一帧被训练时采用边界框回归模型,具体处理包括:对于测试的视频序列中所给定第一帧,使用三层卷积网络来训练一个线性回归模型来预测目标的位置、提取目标特征;在随后的视频序列的每一帧中,使用回归模型来调整目标的边界框的位置。
与现有技术相比,本发明具有以下效果:
(1)能够在降低计算复杂度的同时,精确使用图像的预处理信息,使得跟踪效果更加精确,因此,本发明内容具有独创性;
(2)该跟踪器能适应多种环境复杂的场景,有着广泛的应用前景。
附图说明
图1为本发明的基于深度学习和环境自适应的目标跟踪算法整体框架;图1(a)为本文跟踪算法的基本模型;图1(b)为显著性检测模型;图1(c)深度学习跟踪模型;
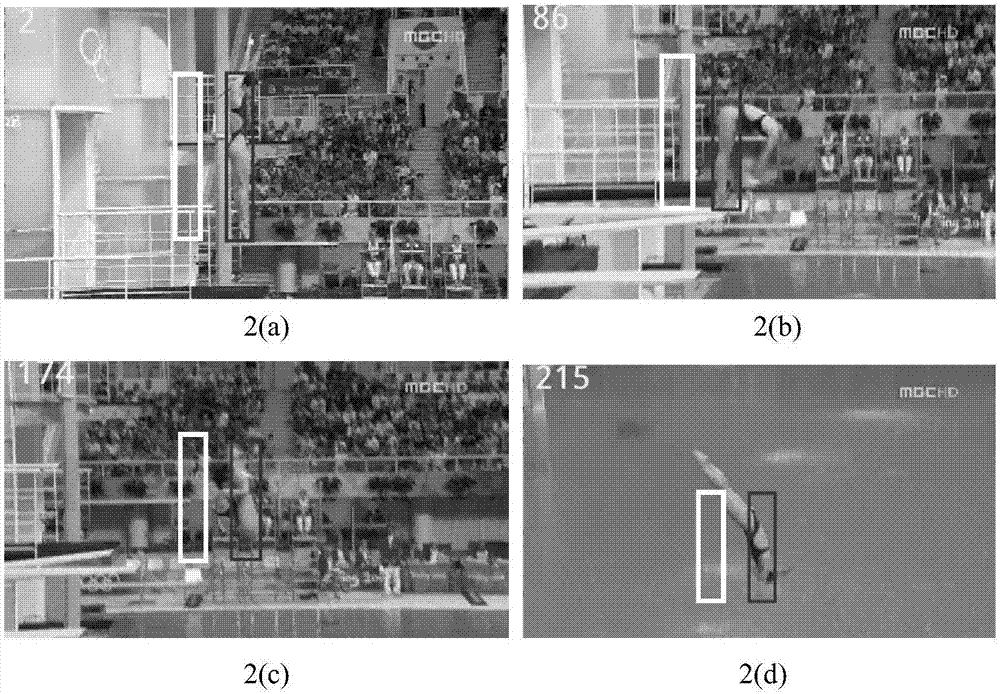
图2为diving序列跟踪测试结果
图3为ball序列跟踪测试结果
具体实施方式
本发明的基于深度学习和环境自适应的目标跟踪算法,该跟踪算法由两部分组成,一部分是预处理,对跟踪视频的每一帧图像来提取信息,然后通过显著性检测、卷积神经网络算法来对采取的正负样本进行进一步的筛选;另外一部分是实现vgg模型的卷积神经网络:首先利用三层的卷积网络来提取目标特征,其次利用全连接层来对目标和背景来进行分类,最后得到想要跟踪的目标的位置,再开始下一帧的跟踪流程。
具体流程详细描述如下:
步骤1、采用107×107像素点大小的图片作为输入;为了保证卷积层输出的特征图与输入的大小相匹配,要保证输入全卷积层的为一维向量;
步骤2、预处理包括正样本预处理和负样本的处理
(1)正样本预处理:一般的方法采取的正样本有的时候是包含了大部分背景的负样本,这样的“正样本”对于卷积神经网络中的训练是会造成一定误差的。因此,本发明对所采取的的正样本进行一定的筛选,使得正样本更加的纯正。具体的实现方法如下:
首先,根据groundtruth值在正样本中的目标周围取一个矩形,矩形一定要比目标的groundtruth值大;计算显著图占整个采样框的比例,若是比例大于设定的某个阈值,就可以当成纯正的正样本来输入进网络,若是比设定的阈值小,则予以丢弃。这样可以用来保证得到的正样本都几乎是纯正的。
然后,进行“显著性”检测,即对于在一个区域内显著的物体进行检测。具体作法是利用显著性检测算法大致的检测出目标的形状,然后将得到的显著图二值化,将其插回原来的一帧的图像中,再根据前面的采样的流程对二值化之后的整帧图像来进行采样,后面要利用“显著性”方法来对目标进行检验。
本步骤中的正样本筛选,在大多数的跟踪算法中是一个通用的正样本筛选方法;将这个思想用到了预训练的网络中,可以对于整个网络的参数有一定的影响。
(2)负样本预处理
在跟踪检测中,大多数的负样本通常是冗余的,只有很少的具有代表性的负样本是对于训练跟踪器有用的。对于平常的sgd方法,很容易造成跟踪器的漂移问题。对于解决这个问题,最常用的就是难例挖掘的思想。对于负样本的筛选应用难例挖掘的思想,将采样的样本在卷积神经网络中进行一次正向传播,将loss比较大的样本按照顺序排列,并将前面的选出来,因为这部分样本与正样本足够接近,同时又不是正样本,因此被称为“难例”,用这部分样本来训练网络,可以使网络更好的学习到正负样本之间的差别。
步骤3、在第一帧被训练时采用边界框回归模型,具体处理包括:对于测试的视频序列中所给定第一帧,使用三层卷积网络来训练一个线性回归模型来预测目标的位置、提取目标特征;在随后的视频序列的每一帧中,使用回归模型来调整目标的边界框的位置,利用全连接层对图像中的目标和背景进行分类,得到目标概率大的图像块,将该图像块视为要跟踪的目标,即可得到要跟踪目标的位置,再开始下一帧的跟踪流程。
在正样本预处理中,还可以采用长短更新策略:利用一段时间内收集到的正样本来重新更新网络。在跟踪目标的时候,一旦发现跟丢了,就使用短期的更新策略,在短期更新策略中,用于更新网络的正样本还是这一段时间内采集到的正样本。两个更新策略中所使用的负样本都使用的短期更新模型中所收集到的负样本。规定ts和tl是两个帧索引集,短期设定为ts=20帧,长期设定为tl=100帧。采用这一个策略的目的就是使得样本保持为最“新鲜”的,这样对于跟踪结果更有利。
在离线训练好神经网络之后,对于需要测试的视频序列,是在线跟踪的。因此在整体跟踪算法中,需要有在线跟踪算法部分。在线跟踪的算法具体实现过程如下:
输入:预训练卷积神经网络cnn的滤波器{w1,...,w5}
初始化目标的状态x1
输出:估计目标的状态
(1)随机初始化第6个全连接层的权重w6,使得w6获得一个随机的初始值;
(2)训练一个边界框回归模型;
(3)抽取正样本
(4)利用显著性网络对正样本进行筛选,
(5)使用抽取出的正样本
(6)设置长短更新初始值:ts←{1}和tl←{1};
(7)重复以下操作:
抽取目标的候选样本
通过公式
如果
ts←ts∪{t},tl←tl∪{t}
其中,t表示第t帧,ts和tl分别代表短和长的索引集。将t与ts和tl的最大值分别的赋给ts和tl,更新两个帧索引集的值;
如果短的帧索引集的位置长度大于设置的20,即:|ts|>τs,然后将短索引集ts中的最小的元素剔除
如果长的帧索引集的位置长度大于设置的100,即:|tl|>τl,然后将长索引集tl中的最小的值剔除
使用边界框回归模型来调整预测的目标的位置
如果
其他情况,使用短期模型中的正样本和负样本来更新权重{w4,w5,w6}。
下面将结合附图对本发明的实施方式作进一步的详细描述。
下面对专利提出的基于深度学习和环境自适应的目标跟踪算法进行验证。同时,通过仿真实验比较该算法的训练误差与未改进前的算法的训练误差进行对比,通过大量的实验结果来证实算法的有效性。实验结果以跟踪的目标框的形式表示。
候选目标生成为了在每一帧中生成候选目标,选取n=256个样本,
其中,
训练数据:在离线多域训练时,从每一帧中采用50个正样本和200个负样本,正样本和负样本分别和ground-truth的框有≥0.7和≤0.5的重合率,就是根据这个标准来分别选取正负样本的。同样的,对于在线学习,收集
网络学习:对于训练k个分支的多域网络学习,把卷积层的学习率参数设置为0.0001,把全连接层的学习率设置为0.001。最开始训练全连接层的时候,我们迭代30次,全连接层4和5的学习率设置为0.0001,第六个全连接层学习率设置为0.001。
表1为改进算法是加入“显著性”预处理网络,表2为未改进算法是没加入预处理网络的实验结果:
表1、改进算法后的训练结果
表2、未改进算法的训练结果
- 还没有人留言评论。精彩留言会获得点赞!