一种高坝多点变形性态联合预报方法与流程
本发明涉及高坝多点变形性态联合预报方法,属于高坝工程安全监测领域。
背景技术:
水利工程,尤其是高坝大库工程,在防洪、发电、航运、供水、灌溉、养殖、旅游等方面带来了巨大的社会经济效益,为国民经济的发展做出了巨大贡献。但是由于人们对自然力量、材料性能、结构机理、施工控制以及人为损坏等影响高坝安全的因素认识不够充分,使得很多大坝都处于带病状态,病变隐患若得不到及时发现和处理,很有可能引发大坝整体或者局部的灾变甚至溃坝失事,给社会造成严重的经济损失、生命财产损失。
若能布设齐全的安全监测设施并持续监测,及时对安全监测资料进行处理与分析,重视大坝变形、渗流等监控模型、监控指标等的构建和应用,很多安全隐患可以被发现、灾难性事故能够被避免。变形作为大坝安全状况最直观、最综合的体现,对其变化特征的科学分析、辨识、预报以及评价,一直是大坝安全管理的重点,相关模型、方法等长期被坝工安全科研人员所关注和探研,但由于大坝变形影响因素众多、驱动机制复杂,给精细辨识变形时空特征、精确预报变形变化性态带来了极大的困难。
近年来,虽然相关学者通过不断引入模糊数学、灰色理论、小波分析、人工神经网络、支持向量机等理论用于监测资料进行,研究了大坝安全预报方法,但其存在预报精度较低、模型大、运行速度慢、计算时间长、只能单点预测等问题,故急需研发一种大坝变形性态多测点联合预报模型与方法。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种高坝多点变形性态联合预报方法,解决了传统方法预报精度低、模型大、运行速度慢、计算时间长、单测点预测等问题,具有精度高、处理周期短、效率高、多测点时空联合预报等优点。
技术方案:为解决上述技术问题,本发明的一种高坝多点变形性态联合预报方法,包括以下步骤:
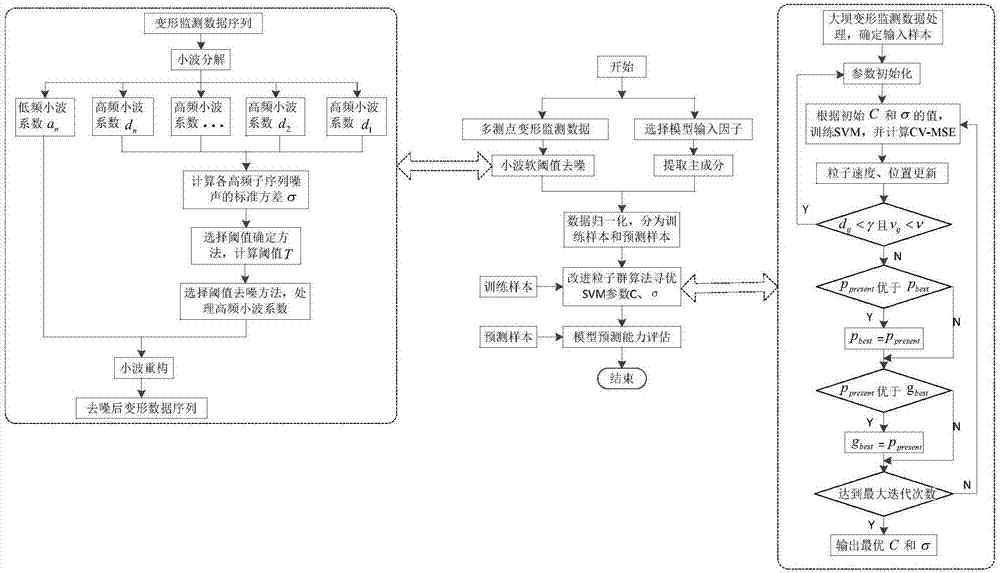
(1)选取高坝工程中若干测点的变形监测数据,采用小波软阈值去噪法去噪;
(2)确定模型输入因子,对所选因子进行主成分分析,提取主成分;
(3)对多测点去噪后数据及各主成分进行归一化处理,分为训练样本、预测样本;
(4)依据训练样本,利用改进粒子群算法对支持向量机svm参数c、σ进行寻优,完成对支持向量机的训练;
(5)依据预测样本,用训练好的模型进行样本预测,进行模型预报效果评价。
作为优选,所述步骤(1)中小波软阈值去噪法包括以下步骤:
(11)根据大坝变形监测数据序列s的特性,选择合适的小波函数和分解层数n;
(12)对数据序列s进行小波分解,得各低频、高频子序列的小波系数;
(13)计算各高频子序列的噪声标准方差σ;
(14)选择一种阈值确定方法,确定各高频子序列的阈值t,对各高频子序列的小波系数进行处理
(15)将低频子序列的小波系数与经过阈值去噪处理后的高频子序列小波系数进行重构,即可得去噪后的变形监测数据序列。
作为优选,所述步骤(4)步骤以下步骤:
(41)对选取的大坝变形测值序列样本进行归一化处理,并确定输入样本,设定粒子个数、种群迭代次数、惯性权重、惩罚因子、核参数的范围、数据分组k、学习因子的初始以及速度因子v与位置因子γ的值,在规定范围内随机生成初始速度及初始位置,初始位置即对应初始c、σ的值,
(42)根据当前的c、σ的值,训练支持向量机,并计算适应度函数值cv-mse,并记忆个体与群体对应最佳适应值的pbest和gbest;
(43)对粒子的速度进行更新,若出现dij<γ且vij<ν的情况,则继续步骤(41),将该粒子的位置重新初始化,否则进行步骤(44),对粒子的位置进行更新;
(44)将粒子当前位置的ppresent与历史最优解pbest做比较,若ppresent>pbest,则令pbest=ppresent,否则pbest不变,将粒子当前位置的ppresent与种群最优解gbest做比较,若ppresent>gbest,则令gbest=ppresent,否则gbest不变,若达到最大迭代次数,则终止迭代,输出最优解。
作为优选,模型预报效果评价方法的具体量化评价指标为均方根误差(mse)、平均绝对百分比误差(mape)和拟合优度(r2)。
其中,均方根误差(mse):
平均绝对百分比误差(mape):
拟合优度(r2):
式中:n为预测值个数;yi为原始测值;
有益效果:本发明的高坝多点变形性态联合预报方法,通过引入多输出支持向量机学习方法,在对其损失函数论述的基础上,构建了基于多输出支持向量机的高坝工程变形性态多测点联合预报模型;为削弱建模因子多重共线性对模型精度的不利影响,发明了以模型因子主成分提取结果作为支持向量机输入量的处理方式,解决了传统方法预报精度低、模型大、运行速度慢、计算时间长、单测点预测等问题,具有精度高、处理周期短、效率高、多测点时空联合预报等优点。
附图说明
图1为本发明高坝多点变形性态联合预报技术的流程图;
图2为本发明步骤(1)小波阈值去噪流程图;
图3为本发明步骤(4)基于改进pso算法的svm参数寻优实现流程图;
图4为本发明实施例pp2测点测值过程线图;
图5为本发明实施例pp2测点变形预测结果图。
具体实施方式
如图1所示,本发明一种高坝多点变形性态联合预报技术,具体包括如下步骤:
步骤(1)选取多个测点的变形监测数据,例如可以在大坝上均匀的分布若干个测点,采用图2所述小波软阈值去噪法对变形监测数据进行去噪处理,具体子步骤如下:
①根据大坝变形监测数据序列s的特性,选择合适的小波函数和分解层数n,对数据序列s进行小波分解,得各低频、高频子序列的小波系数。其中,合适的小波函数和分解层数n是指选择满足小波基函数正交性、正则性、紧支性、对称性性质的小波函数和分解层数。
②根据公式σ=median(|ωj|)/0.6745计算各高频子序列的噪声标准方差σ。
σ=median(|ωj|)/0.6745
式中:median(|ωj|)表示小波分解后对应分解层数下小波系数{ω}绝对值的中值;j是小波分解尺度。
③选择一种阈值确定方法,优选为无偏似然估计法,确定各高频子序列的阈值t。
④选择一种阈值去噪方法,优选为非线性小波变换阈值去噪法,对各高频子序列的小波系数进行处理。
⑤将低频子序列的小波系数与经过阈值去噪处理后的高频子序列小波系数进行重构,即可得去噪后的变形监测数据序列。
步骤(2)确定模型输入因子,对所选因子进行主成分分析,根据特征值大于1或特征值的累计贡献率超过85%原则提取主成分。
步骤(3)对多测点去噪后数据及各主成分进行归一化处理,从中选取模型训练样本、预测样本,以按时间顺序排列的各主成分因子作为支持向量机的输入,以按时间顺序排列的去噪后变形监测数据为支持向量机的输出。
步骤(4)依据训练样本,利用改进粒子群算法对支持向量机参数进行寻优,寻优结束后输出最优c、σ的值,完成对支持向量机(svm)的训练。改进粒子群算法实现支持向量机参数寻优的过程如附图3所示,具体子步骤如下:
①对选取的大坝变形测值序列样本进行归一化处理,并确定输入样本。
②粒子群相关参数初始化。设定粒子个数、种群迭代次数、惯性权重、惩罚因子、核参数的范围、数据分组k、学习因子的初始以及速度因子v与位置因子γ的值。在规定范围内随机生成初始速度及初始位置。初始位置即对应初始c、σ的值。
③根据当前的c、σ的值,训练svm,并计算cv-mse,并记忆个体与群体对应最佳适应值的pbest和gbest。
④对粒子的速度进行更新,若出现dij<γ且vij<v的情况,则将该粒子的位置重新初始化,否则对粒子的位置进行更新。
⑤将粒子当前位置的ppresent与历史最优解pbest做比较,若ppresent>pbest,则令pbest=ppresent,否则pbest不变。
⑥将粒子当前位置的ppresent与种群最优解gbest做比较,若ppresent>gbest,则令gbest=ppresent,否则gbest不变。
⑦若达到最大迭代次数,则终止迭代,输出最优解,否则重复步骤③~⑦。
步骤(5)依据预测样本,用训练好的模型进行样本预测,进行模型预报效果评价。具体量化评价指标为均方根误差(mse)、平均绝对百分比误差(mape)和拟合优度(r2)。
①均方根误差(mse):
②平均绝对百分比误差(mape):
③拟合优度(r2):
式中:n为预测值个数;yi为原始测值;
实施例:本发明所述的一种高坝多点变形性态联合预报技术,以某重力坝为例,选取该大坝pp2变形测点,依据三个测点2008年1月1日至2008年7月20日共200个监测数据为样本,测值如附图4所示。遵照附图1所述流程,构建三测点联合预报模型,前180个数据用来训练模型,后20个数据用来验证模型的预测效果。
选h-h0、(h-h0)2、(h-h0)3、(h-h0)4、
表1因子贡献率
提取主成分依据的原则是成分的初始特征值大于1并且成分的累计贡献率大于85%,依据此原则以及表1数据可知应选前4个成分。因子载荷矩阵的数值如表2所示,根据因子载荷矩阵,得出各主成分与原指标的线性关系,进而求出各主成分的值,表达式如下:
式中主成分的系数是由因子载荷矩阵中的值除以相应特征值的平方根求得。
表2因子载荷矩阵
对上述主成分提取结果进行归一化处理作为支持向量机的输入样本,以三个变形测点测值归一化结果为支持向量机输入样本,训练得到三个测点变形联合预报模型(pca-msvm模型),并与基于主成分分析的单输出支持向量机模型(简称pca-svm模型)进行预测效果对比。两个模型均采用改进的pso算法进行寻优,核函数为morlet小波核函数。两种模型的预测结果如图5所示,基于步骤(5)所给评价指标进行两模型预测能力的评价,结果如表3所示,从图5及表3可以看出:
(1)pca-msvm模型的运算时间较pca-svm模型明显减小,其具有运行速度快、节约计算时间的优点。
(2)pca-msvm模型的mse、mape等指标均比pca-svm模型要小,而拟合优度r2又高于pca-svm模型。
表3单输出与多输出svm预测模型预测性能评价指标
- 还没有人留言评论。精彩留言会获得点赞!