一种基于管线概化与搜素引擎的排水管网追溯分析方法与流程
本发明涉及一种基于管线概化与搜素引擎的排水管网追溯分析方法。
背景技术:
随着我国城镇化进程加快,每年都有大量新建管网水管通水运行。城市中有大量的排水设备,形成相应的城市排水系统,排水系统由检查井、排水泵站、污水处理厂、雨水口、排放口等等组成,排水设备中的检查井、雨水口、排放口等通过排水管网进行连接,日常的雨污水进入排水管网进行运输排放。
一个城市或区域里,排水管网的数量巨大,关联关系错综复杂,现有排水管网的追溯分析(在排水管网中的某一点追溯它的上游或下游管网)耗时大且结果单一,不是用户所需要的。
技术实现要素:
针对上述现有技术所存在的问题,本发明的目的是提供一种能够提升分析速度、提高分析结果的可用性和可读性的基于管线概化与搜素引擎的排水管网追溯分析方法。
为达到上述目的,本发明所采用的技术方案是:
一种基于管线概化与搜素引擎的排水管网追溯分析方法,包括下述步骤:
步骤一,在原始管线sde数据库基础上进行管线概化,形成概化管线sde库;
步骤二,根据追溯分析需要的字段,把概化管线sde库的管线数据导入到elasticsearch数据库;
步骤三,根据选择的起始管线进行追溯分析。
作为优选,所述步骤一中的管线概化具体过程如下:
a、判断管线直径是否小于300mm,当管线直径小于300mm时,删除管线数据,当管线直径大于等于300mm时,保留管线数据;
b、把连续的两段管线合成一段管线。
作为优选,所述管线包括管线和沟渠,所述管线的水平直径等于垂直直径,所述沟渠的宽度等于水平管径,高度等于垂直管径,判断时以水平管径为准。
作为优选,执行所述步骤一中的管线概化具体过程中的b需满足前提条件,该前提条件包括:
1)两段管线的水平角度均在170度至190度之间;
2)两段管线坡度相差不大于0.5度。
作为优选,所述步骤一中的管线概化具体过程中的b,处理方式具体是:假设把两段管线命名为管线1和管线2,其中管线1的终点连接管线2的起点,把管线2的终点点号和终点点坐标,以及其他跟终点有关的属性字段,赋值到管线1的终点相关字段,再删除管线2,到此完成管线合并的概化。
作为优选,所述步骤二,根据追溯分析需要的字段,把sde数据库的管线数据导入到elasticsearch数据库,需要按照追溯分析所需的管线数据格式进行导入。
作为优选,所述步骤三中的追溯分析具体过程是:
①选择追溯分析的起始管线,用户点击地图选择管线,从地图的点击事件获取到点击的坐标,然后使用坐标,通过st_geometry的sql语句进行空间查询,查询点击到的管线,此管线则作为追溯分析的起始管线,得到这条管线的字段信息;
②选择追溯分析的方向,包括向上、向下、上下,向上是只向上游追溯管线,向下是只向下游追溯管线,上下就是同时向上下游追溯管线;
③通过管线点号作为标识进行追溯查询,从管线取出起点点号和终点点号,调用嵌套循环追溯方法追溯相邻的管线,且,每追溯到一段管线后,要对其设置“已成为追溯结果”的标记,并把管线添加到追溯分析结果数据集;
④读取追溯分析结果数据集里的管线数据,并进行分析处理,得到分析结果。
作为优选,所述追溯分析得到的分析结果以概化后的管线呈现,可以根据不同的管线段呈现该段管线的纵剖面图的详细图和概要图。
本发明的有益效果是:
一、本发明在分析前对数据进行概化处理,提高追溯分析速度。
二、本发明根据追溯分析需要的字段,把sde数据库的管线数据导入到elasticsearch数据库,利用elasticsearch进行数据的二次入库和搜索是大大提高了分析速度。
三、本发明的分析结果以概化后的管线呈现,同时反映管网存在逆坡、大管接小管、雨污混接等问题,同时反映管网存在的问题更贴合用户对城市或区域排水管网追溯分析的需求,提高了分析结果的可用性和可读性。
四、本发明的分析结果也可以挂接窨井水位监测实时数据,根据历史数据可以模拟管类水位变化过程,实现静态排水管网设施数据与动态实时监测数据的结合。
下面结合附图和实施例对本发明作进一步说明。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的实施例中一种基于管线概化与搜素引擎的排水管网追溯分析方法的总流程图。
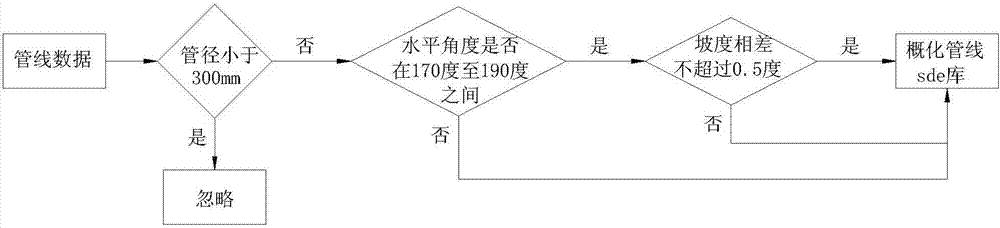
图2是本发明的实施例中一种基于管线概化与搜素引擎的排水管网追溯分析方法的管线概化流程图。
图3是本发明的实施例中一种基于管线概化与搜素引擎的排水管网追溯分析方法的管线数据导入elasticsearch数据库流程图。
图4是本发明的实施例中一种基于管线概化与搜素引擎的排水管网追溯分析方法的追溯查询流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面以具体实施例详细阐述本发明更多的技术细节。
如图1-4所示,本实施例的基于管线概化与搜素引擎的排水管网追溯分析方法,包括下述三个步骤:
步骤一,在原始管线sde数据库基础上进行管线概化,形成概化管线sde库;
由于排水管网分析场景是大范围的管线追溯分析,只需要追溯出管线主要的流向,同时也为了提高追溯分析速度,因此在分析前,会对管线数据进行概化处理。
如图2所示,管线概化具体过程如下:首先,判断管线直径是否小于300mm,由于追溯分析只要分析出总体流向,因此只需要主干管,而不需要太细的支管,当管线直径小于300mm时,删除管线数据,当管线直径大于等于300mm时,保留管线数据,管线包括管线和沟渠,管线的水平直径等于垂直直径,沟渠的宽度等于水平管径,高度等于垂直管径,判断时以水平管径为准。
然后,把连续的两段管线合成一段管线,由于追溯分析只要分析出管线的总体流向,而管线数据是一段一段的,即使只是连成一段直线也会分段,因此我们会根据此特性进行概化,处理方式具体是:假设把两段管线命名为管线1和管线2,其中管线1的终点连接管线2的起点,把管线2的终点点号和终点点坐标,以及其他跟终点有关的属性字段,赋值到管线1的终点相关字段,再删除管线2,到此完成管线合并的概化。另外,能否把连续的两段管线合成一段管线需满足前提条件,该前提条件包括:
1)两段管线的水平角度均在170度至190度之间;
2)两段管线坡度相差不大于0.5度。
假设两段管线line1和line2,其起点和终点坐标分别为sx1,sy1,ex1,ey1,sx2,sy2,ex2,ey2,首先用sx1,sy1,ex1,ey1作为线段1,sx2,sy2,ex2,ey2作为线段2求出两线段的夹角ang,判断ang是否大于等于170且小于等于190,如果是则判断为可概化,反之为不可概化。并从管线line1和line2分别取出坡度slope1和slope2,求abs(slope1-slope2)的值是否大于0.5,是则判断为可概化,反之不可概化。
经过概化后,管线数据量减少到只有原数据的20%,对提高追溯分析速度有明显作用。
步骤二,根据追溯分析需要的字段,把概化管线sde库的管线数据导入到elasticsearch数据库;
elasticsearch数据库是一个高性能的数据库,优点是在大数据量时依然能保持很高的查询速度,在本次分析中,在20万管线数据的情况下,查询一次只需几十毫秒,而使用arcgissde数据库查询一次要近10秒,elasticsearch性能优势十分明显,使用elasticsearch需要先把sde数据库的管线数据导入到elasticsearch,且按照追溯分析所需的管线数据格式进行导入。从sde数据库读取管线数据使用的是sde的st_geometry的sql语句,使用jdbc执行sql语句进行查询,写入elasticsearch我们用的是spring-data-elasticsearch。如图3所示,管线数据导入elasticsearch不需要全部字段都导入,只需要导入追溯分析需要的字段,需要的字段有:oid(对象id)、startusid(起点点号)、endusid(终点点号)、material(材质)、sort(类型)、ds1(管径1,水平管径)、ds2(管径2,垂直管径)、startheight(起点管底高程)、endheight(终点管底高程)、startx(起点x),starty(终点y)、endx(起点x)、endy(终点y)。其中ds1和ds2的计算由于管线和沟渠的表达管径字段格式不同,因此需要分别处理,处理格式与上述概化时判断管径的方式一样,startheight和endheight需要通过管线数据的地面高程和埋深计算,值为:地面高程-埋深;startx、starty、endx、endy的值可以通过管线的几何对象shape,然后获取线的起点frompoint和终点topoint对象,最后从点获取其坐标x和y即可。
利用elasticsearch进行数据的二次入库和搜索是大大提高了分析速度。
步骤三,根据选择的起始管线进行追溯分析,具体过程是:
①选择追溯分析的起始管线,用户点击地图选择管线,从地图的点击事件获取到点击的坐标,然后使用坐标,通过st_geometry的sql语句进行空间查询,查询点击到的管线,此管线则作为追溯分析的起始管线,得到这条管线的字段信息;
②选择追溯分析的方向,包括向上、向下、上下,向上是只向上游追溯管线,向下是只向下游追溯管线,上下就是同时向上下游追溯管线,通常情况下,如果想从污水处理厂的入口追溯出这个污水厂服务的所有范围,那就应该向上追溯,如果想分析某一段管线最终流向的位置,就可以用向下追溯;
③通过管线点号作为标识进行追溯查询,从管线取出起点点号和终点点号,调用嵌套循环追溯方法追溯相邻的管线,且,每追溯到一段管线后,要对其设置“已成为追溯结果”的标记,防止有环状管线导致重复追溯出结果,并把管线添加到追溯分析结果数据集,直到追溯到每一段管线不再存在相连的管线,也就是管线路径的末端,到此标志着追溯分析完成。如果追溯查询到的管线是数组,需遍历数组里的每条管线。在使用elasticsearch库之前,追溯分析的性能瓶颈就在此,因为每次查询都要几秒钟,每条管线追溯一次都要查询一到两次,总体耗时就很高了,在使用elasticsearch库后一次查询只要数十毫秒,最终每次追溯分析平均只要几秒,基本能达到实用的效果。
④读取追溯分析结果数据集里的管线数据,并进行分析处理,得到分析结果。以下举例说明,基于追溯分析结果数据集里的管线数据,遍历每段管线,首先读取管线里的起止点高程,发现终点高程比起点高的,复制该记录存到“逆坡”问题列表,接着读取管线的管径与下游的管线管径对比,发现下游管线的管径大于原管线的,复制该记录存到“大管接小管”问题列表,最后读取管线的类型与下游的管线类型对比,发现下游管线的类型与原管线不一致且不为“雨污合流”类型的,复制该记录存到“雨污混接”问题列表,并可输出分析结果。
分析结果以概化后的管线呈现,同时反映管网存在逆坡、大管接小管、雨污混接等问题,可以根据不同的管线段呈现该段管线的纵剖面图的详细图和概要图,提高了分析结果的可用性和可读性。另外,分析结果也可以挂接窨井水位监测实时数据,根据历史数据可以模拟管类水位变化过程,实现静态排水管网设施数据与动态实时监测数据的结合。
以本发明的方法对广州市20000多公里管线数据进行追溯分析,结果可行且运算速度比原来提高了约90%。
尽管本发明是参照具体实施例来描述,但这种描述并不意味着对本发明构成限制。参照本发明的描述,所公开的实施例的其他变化,对于本领域技术人员都是可以预料的,这样的变化应属于所属权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!