一种基于多语言的数据挖掘方法与流程
本发明涉及用于处理跨域的大数据网站的挖掘技术。
背景技术:
截止到2016年9月,全球互联网网站数量已超过11.6亿,并且这个数字目前还在不断增加,另外互联网网民的数量也将突破40亿大关。2016年我们每天在互联网产生至少4eb的数据。针对如此庞大的数据资源,通过人工方式获取已不能满足需求。
技术实现要素:
本发明所要解决的技术问题是提供一种基于多语言的数据挖掘方法,能够提高数据识别效率和准确性,解决背景技术中的问题。
本发明解决上述技术问题所采用的技术方案是:一种基于多语言的数据挖掘方法,包括以下步骤:
(1)登入载有数据资料的网站;
(2)识别网站语言;
(3)采集网站数据资料;
(4)利用分类器对数据资料进行分类;
(5)将分类后的数据按照类别不同分别存放。
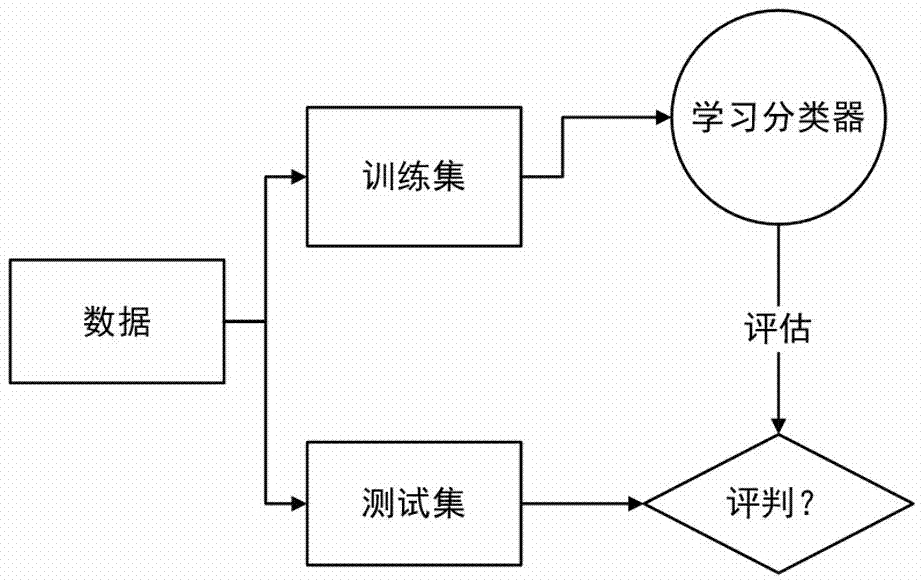
进一步地,上述步骤中使用到的分类器,需要预先经过训练,训练的步骤具体包括:收集数据,将数据按照一定的比例分为训练集和测试集,利用训练集对分类器进行分类,然后再用测试集对训练结果进行评估,当分类误差和精度达到一定阈值时,判断为训练结束。
进一步地,采集网站数据资料具体包括以下步骤:
(3.1)识别数据源;
(3.2)判断该数据源是否已被采集,如果已被采集,则直接存入已采集数据库,如果未被采集,进入下一步;
(3.3)利用scrapy框架对数据进行采集,并将采集到的数据存入已采集数据库;
(3.4)根据scrapy框架中的response数据判断该数据来源的网站是否属于目标类型网站。
本发明的有益效果是:本发明能够自动识别语种,然后进行对应的采集,将采集的内容按照语种的不同进行存入库中,有效的解决了网站数据源发现越来越困难,对网站源的地域判断效率低下,对网站源的语言判断准确性低,不能快速、高效的识别广告、电商、问答、视频、音频等非新闻类数据,对数据源的管理没有统一的修改,保存机制等问题。本方法的优势在于不使用人工对网站语种以及网站注册地的判断,而是将这些操作交给机器来操作,极大的降低了人力的资源而且还提高了对网站源判断的精准度和效率。同时本方法会对不同语言进行分类,这样完成了数据的跨语言问题,还解决了人工对语言进行分类的效率低下问题。
附图说明
图1是本发明的整体流程图。
图2是分类器的训练方法示意图。
具体实施方式
以下结合附图对本发明的具体实施方案做进一步详细说明,应当指出的是,实施例只是对方案的具体阐述,并不是对本发明的限定。
如图1所示,本发明的基于多语言的数据挖掘方法,包括以下步骤:
(1)登入载有数据资料的网站;
(2)利用语言识别模块识别网站语言;
(3)采集网站数据资料;
(3.1)识别数据源;
(3.2)判断该数据源是否已被采集,如果已被采集,则直接存入已采集数据库,如果未被采集,进入下一步;
(3.3)利用scrapy框架对数据进行采集,并将采集到的数据存入已采集数据库;
(3.4)根据scrapy框架中的response数据判断该数据来源的网站是否属于目标类型网站。
(4)利用分类器对数据资料进行分类;
(5)将分类后的数据按照类别不同分别存放。
本发明的分类前提是,对分类器需要预进行训练,如图2所示,训练的步骤具体包括:首先提取一批精准的并且带有标签的数据,然后将这批数据分为测试和训练集,一般把训练和测试比例分为80%和20%这样训练出来的分类器再用这20%的测试数据进行评估,评估结果也就是分类误差/精度,其中,
误差=错误/句子样本;
误差最优为0.0;
精度=正确预测/句子样本;
精度最优为1.0。
技术特征:
技术总结
本发明提供一种基于多语言的数据挖掘方法,包括步骤:登入载有数据资料的网站;识别网站语言;采集网站数据资料;利用分类器对数据资料进行分类;将分类后的数据按照类别不同分别存放。本发明能够自动识别语种,然后进行对应的采集,将采集的内容按照语种的不同进行存入库中,有效的解决了网站数据源发现越来越困难,对网站源的地域判断效率低下,对网站源的语言判断准确性低,不能快速、高效的识别广告、电商、问答、视频、音频等非新闻类数据,对数据源的管理没有统一的修改,保存机制等问题。
技术研发人员:王晓东
受保护的技术使用者:中译语通科技(青岛)有限公司
技术研发日:2017.12.28
技术公布日:2018.05.15
- 还没有人留言评论。精彩留言会获得点赞!