串流开关的制作方法
本公开整体涉及深度卷积神经网络(DCNN)。更具体地但不排他地,本公开涉及被布置为实现DCNN的一部分的硬件加速器引擎。
背景技术:
已知的计算机视觉、语音识别和信号处理应用受益于使用深度卷积神经网络(DCNN)。DCNN技术中的一项重要工作是由Y.LeCun等人在1998年的IEEE会报第86期第11卷第2278-2324页上发表的“Gradient-Based Learning Applied To Document Recognition”,该文章利用“AlexNet”赢得了2012年的ImageNet大型视觉识别挑战赛。如由Krizhevsky,A.、Sutskever,I.和Hinton,G.于2012年在内达华州太浩湖的NIPS第1-9页发表的“ImageNet Classification With Deep Convolutional Neural Networks”中所描述的,AlexNet是第一次显著优于经典方法的DCNN。
DCNN是处理大量数据并通过以下方式进行自适应地“学习”的基于计算机的工具:将数据内的近端相关的特征融合、对数据进行广泛预测、并基于可靠的结论和新的融合来改进预测。DCNN被布置在多个“层”中,并且在每一层处进行不同类型的预测。
例如,如果面部的多个二维图片被提供作为DCNN的输入,则DCNN将学习诸如边缘、曲线、角度、点、颜色对比度、亮点、暗点等的面部的各种特性。在DCNN的一个或多个第一层处学习这些一个或多个特征。然后,在一个或多个第二层中,DCNN将学习诸如眼睛、眉毛、前额、头发、鼻子、嘴、脸颊等的面部的各种可识别的特征;其中的每一个都能与所有其他特征区分开。即,DCNN学习识别和区分眼睛与眉毛或任何其他面部特征。在一个或多个第三层及随后的层中,DCNN学习诸如种族、性别、年龄、情绪状态等的整个面部特性及更高阶的特性。在某些情况下,DCNN甚至被训练来识别个人的特定身份。例如,随机图像可以被标识为面部,并且面部可以被识别为奥兰多·布鲁姆、安德烈·波切利或其他一些身份。
在其他示例中,可以向DCNN提供多个动物图片,并且可以训练DCNN来标识狮子、老虎和熊;可以向DCNN提供多个汽车图片,并且可以训练DCNN来标识和区分不同类型的车辆;并且还可以形成许多其他的DCNN。DCNN可以用于学习句子中的单词模式、标识音乐、分析个体购物模式、玩视频游戏、创建交通路线,并且DCNN也可以用于许多其他基于学习的任务。
图1包括图1A-图1J。
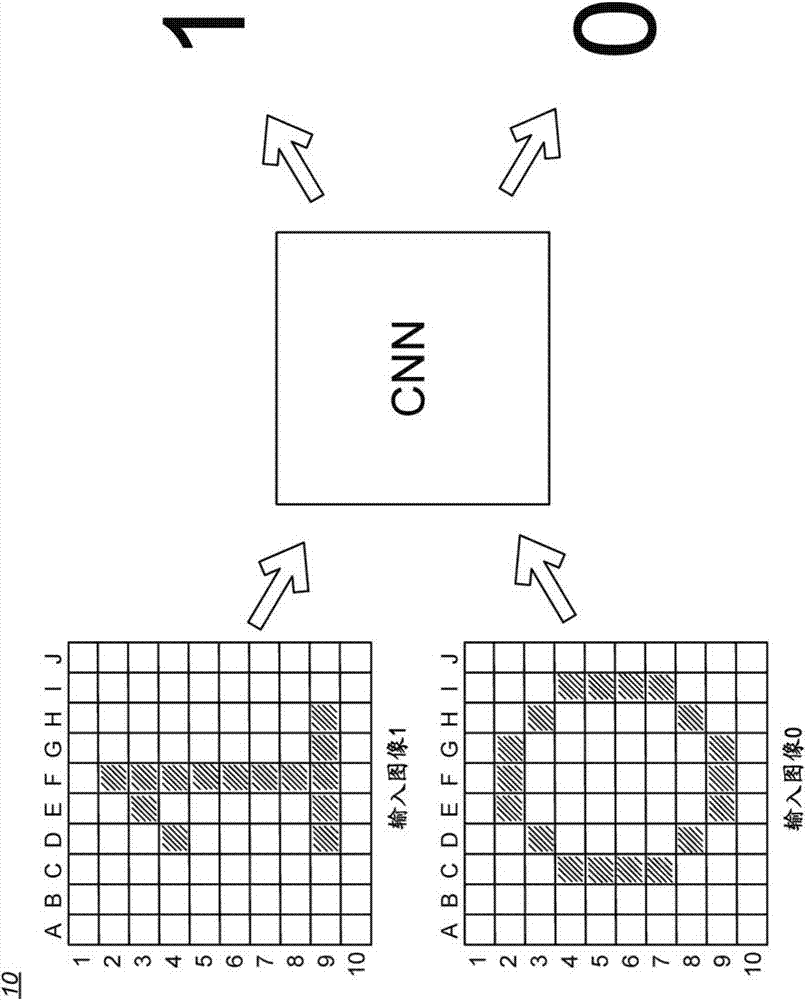
图1A是卷积神经网络(CNN)系统10的一个简化图示。在CNN系统中,由CNN处理像素的二维阵列。CNN分析10×10的输入对象平面,以确定在平面中是否表示“1”、在平面中是否表示“0”、或者在平面中未表示“1”或“0”。
在10×10的输入对象平面中,每个像素被点亮或不被点亮。为了图示的简单起见,被点亮的像素被填充(例如,深色),且未被点亮的像素未被填充(例如,浅色)。
图1B图示了图1A的CNN系统10,该系统确定第一像素图案图示“1”,且第二像素图案图示“0”。然而,在现实世界中,图像并不总是如图1B所示的那样清晰地排列整齐。
在图1C中,示出了不同形式的0和1的若干变型。在这些图像中,平均的人类观察者将容易地识别特定数字被平移或缩放,但是观察者也将正确地确定图像是否表示“1”或“0”。沿着这样的思路,在不用思考的情况下,人类观察者看穿图像旋转、数字的各种加权、数字的尺寸、移位、反转、重叠、分段、同一图像中的多个数字以及其他这样的特性。然而,以编程方式,在传统的计算系统中,这样的分析是非常困难的。各种图像匹配技术是已知的,但是即使使用非常小的图像尺寸,该类型的分析也很快压倒了可用的计算资源。然而,相比之下,即使CNN系统10以前从未“看到”确切的图像,CNN系统10也可以正确地标识每个经处理的图像中的1、0、1和0或者既不是1也不是0。
图1D表示分析(例如,数学地组合)未知图像的部分与已知图像的对应部分的CNN操作。例如,可以将左侧未知图像的3个像素部分B5-C6-D7识别为匹配右侧已知图像的对应的3个像素部分C7-D8-E9。在这些情况和其他情况下,还可以识别各种其他对应的像素布置。一些其他的对应关系如表1所示。
表1–对应的已知到未知的图像分段
认识到已知图像的分段或部分可以被匹配到未知图像的对应分段或部分,还可以认识到,通过统一部分匹配操作,可以以完全相同的方式处理整个图像,同时实现先前未经计算的结果。换言之,可以选择特定的部分尺寸,然后可以逐个部分地分析已知的图像。当已知图像的任何给定部分内的图案与未知图像的类似尺寸的部分数学地组合时,生成表示部分之间的相似度的信息。
图1E图示了图1D的右侧已知图像的六个部分。每个部分(也称为“内核”)被布置为3像素×3像素的阵列。在计算上,被点亮的像素在数学上表示为正“1”(即,+1);并且未被点亮的像素在数学上表示为负“1”(即,-1)。为了简化图1E中的图示,还使用图1D的列和行参考来示出每个所图示的内核。
图1E中示出的六个内核是代表性的并且被选择以便于理解CNN系统10的操作。很明显,可以使用重叠或不重叠的内核的有限集合来表示已知的图像。例如,考虑到3像素×3像素的内核尺寸和具有1的步幅的重叠内核的系统,每个10×10像素的图像可以具有64个对应的内核。即,第一内核跨越A、B、C列和1、2、3行中的9个像素。
第二内核跨越B、C、D列和1、2、3行中的9个像素。
第三内核跨越C、D、E列和1、2、3行中的9个像素等,直到第八内核跨越H、I、J列和1、2、3行中的9个像素。
内核对准以这种方式继续,直到第57内核跨过A、B、C列和8、9、10行,并且第64内核跨越H、I、J列和8、9、10行。
在其他CNN系统中,内核可以重叠或不重叠,并且内核可以具有2、3或一些其他数字的步幅。基于过去的结果、分析研究或以其他方式,CNN系统设计人员选择了用于选择内核尺寸、步幅、位置等的不同策略。
返回到图1D和图1E的示例,使用已知图像中的信息形成总共64个内核。第一内核开始于3×3阵列的最上最左的9个像素。接下来的七个内核按顺序向右移位,每个移动一列。第九内核返回到前三列并下拉一行,类似于基于文本的文档的回车操作,该概念来自二十世纪的手动打字机。遵循该模式,图1E示出第7、第18、第24、第32、第60和62个内核。
顺序地,或以一些其他已知的模式,每个内核与被分析的图像像素的相应尺寸的集合对准。在完全分析的系统中,例如,第一内核在概念上被叠加在每一个内核位置中的未知图像上。考虑图1D和图1E,第一内核在概念上被叠加在1号内核的位置中的未知图像上(图像的最左、最上的部分),然后第一内核在概念上被叠加在2号内核的位置中的未知图像上,等,直到第一内核在概念上被叠加在64号内核的位置中的未知图像上(图像的最下、最右部分)。针对64个内核中的每一个重复该过程,并且执行总共4096个操作(即,64个位置中的每一个中的64个内核)。以该方式,还示出,当其他CNN系统选择不同的内核尺寸、不同的步幅和不同的概念叠加模式时,操作次数将发生变化。
在CNN系统10中,在被分析的未知图像的每个部分上的每个内核的概念叠加被执行为称为卷积的数学过程。基于像素是被点亮还是未被点亮,内核中的九个像素中的每一个被赋予正值“1”(+1)或负值“1”(-1),并且当内核被叠加在被分析的图像的部分上时,内核中每个像素的值乘以图像中对应像素的值。由于每个像素的值为+1(即,被点亮)或-1(即,未被点亮),因此乘法将总是导致+1或-1。附加地,由于均使用9像素内核来处理4096个内核操作中的每一个,所以在非常简单的CNN中,在单个未知图像分析的该第一阶段处执行总共36864个数学操作(即9×4096)。很明显,CNN系统需要巨大的计算资源。
如上所述,内核中的9个像素中的每一个乘以被分析的图像中的对应像素。当在主题未知图像中乘以未被点亮的像素(-1)时,内核中未被点亮的像素(-1)将在像素位置处产生+1表示“匹配”(即,内核和图像都具有未被点亮的像素)。类似地,内核中的被点亮的像素(+1)乘以未知图像中的被点亮的像素(+1)也产生匹配(+1)。另一方面,当内核中的未被点亮的像素(-1)乘以图像中被点亮的像素(+1)时,结果表示在该像素位置处不匹配(-1)。并且当内核中被点亮的像素(+1)乘以图像中未被点亮的像素(-1)时,结果也表示在该像素位置处不匹配(-1)。
在执行单个内核的九次乘法操作之后,乘积结果将包括九个值;九个值中的每一个值是正一(+1)或负一(-1)。如果内核中的每一个像素匹配未知图像的对应部分中的每一个像素,则乘积结果将包括九个正一(+1)值。备选地,如果内核中的一个或多个像素与未知图像被分析的部分中的对应像素不匹配,则乘积结果将至少具有一些负一(-1)值。如果内核中的每个像素均不能匹配被分析的未知图像的对应部分中的对应像素,则乘积结果将包括九个负一(-1)值。
考虑像素的数学组合(即,乘法操作),可以认识到,乘积结果中的正一(+1)值的数量和负一(-1)值的数量表示内核中的特征与内核在概念上叠加的图像部分匹配的程度。因此,通过将所有乘积求和(例如,将九个值求和)并除以像素的数量(例如,九个),确定单个“质量值”。质量值表示内核与被分析的未知图像的该部分之间的匹配程度。质量值的范围可以从负一(-1)(当没有内核像素匹配时)到正一(+1)(当内核中的每个像素与未知图像中的其对应像素具有相同的被点亮/未被点亮的状态时)。
本文中相对于图1E所描述的动作也可以在所谓的“滤波”操作中统称为第一卷积处理。在滤波器操作中,在未知图像中搜索已知图像中的特定感兴趣部分。滤波器的目的是标识在未知图像中是否找到具有对应的似然预测的感兴趣的特征以及在哪里找到具有对应的似然预测的感兴趣的特征。
图1F图示了滤波处理中的十二个卷积动作。图1G示出了图1F的十二卷积动作的结果。在每个动作中,使用所选择的内核处理未知图像的不同部分。所选择的内核可以被识别为图1B的代表性数字一(“1”)中的第十二内核。在图1B中将代表性“1”形成为10像素×10像素图像中被点亮的像素的集合。从最上、最左的角落开始,第一内核涵盖3像素×3像素的部分。第二到第八内核依次向右移动一列。以回车的方式,第九内核从第二行、最左列开始。内核10-内核16针对每个内核依次向右移动一列。内核17-内核64可以类似地形成,使得在至少一个内核中表示图1B中的数字“1”的每一个特征。
在图1F(a)中,3像素×3像素的所选择的内核概念上叠加在未知图像的最左、最上部分。在该情况下,所选择的内核是图1B的数字“1”的第十二内核。对于人类观察者,图1F(a)中的未知图像可能看起来像被移位的、形成较差的数字一(即“1”)。在卷积处理中,所选择的内核中的每个像素的值(对于被点亮的像素为“+1”,并且对于未被点亮的像素为“-1”)乘以未知图像中的每一个对应像素。在图1F(a)中,五个内核像素被点亮,并且四个内核像素未被点亮。未知图像中的每个像素均未被点亮。因此,当执行所有九次乘法时,五个乘积被计算为“-1”,并且四个乘积被计算为“+1”。九个乘积被求和,并且将产生的值“-1”除以9。因此,图1G(a)的对应图像示出了针对未知图像最左、最上部分中的内核产生的内核值为“-0.11”。
在图1F(b)、图1F(c)和图1F(d)中,内核像素横跨图像的列顺序地向右移动。由于前六列及跨越前六列的前三行的区域中的每个像素也未被点亮,所以图1G(b)、1G(c)和1G(d)各自示出所计算的内核值为“-0.11”。
图1F(e)和图1G(e)示出了与先前计算的内核值“-0.11”不同的所计算的内核值。在图1F(e)中,被点亮的内核像素中的一个与未知图像中的被点亮的像素中的一个匹配。由图1F(e)中的较暗像素示出该匹配。由于图1F(e)现在具有不同集合的匹配/不匹配特性,并且此外,由于内核像素中的另一个与未知图像中的对应像素匹配,所以预期所产生的内核值将增加。实际上,如图1G(e)所示,当执行九次乘法操作时,内核中的四个未被点亮的像素与未知图像中的四个未被点亮的像素匹配,内核中的一个被点亮的像素与未知图像中的一个被点亮的像素匹配,并且内核中四个其他被点亮的像素不与未知图像中未被点亮的四个像素匹配。当九个乘积被求和时,在第五内核位置中,结果“+1”除以九,以计算出内核值“+0.11”。
当在图1F(f)中,内核进一步向右移动时,被点亮的内核像素中的不同的一个与未知图像中的对应的被点亮的像素匹配。图1G(f)将匹配和不匹配像素的集合表示为内核值“+0.11”。
在图1F(g)中,内核再向右移动一列,并且在该位置中,内核中的每个像素与未知图像中的每个像素匹配。由于当内核的每个像素乘以未知图像中的其对应像素时,执行的九次乘法产生“+1.0”,所以九个乘积的总和被计算为“+9.0”,并且针对具体位置的最终内核值被计算(即,9.0/9)为“+1.0”,这表示完美匹配。
在图1F(h)中,内核再次向右移动,这导致单个被点亮的像素匹配,四个未被点亮的像素匹配,并且内核值为“+0.11”,如图1G(h)所示。
内核继续如图1F(i)、1F(j)、1F(k)和1F(1)所示移动,并且在每个位置中,数学计算内核值。由于在1F(i)至1F(1)中,未知图像的被点亮的像素上没有叠加内核的被点亮的像素,所以针对这些位置的每一个所计算的内核值为“-0.11”。在图1G(i)、1G(j)、1G(k)和1G(1)中将相应四个内核位置中的内核值示出为“-0.11”。
图1H图示了内核值的映射的堆栈。在图1B中的数字“1”的第十二内核被移动到未知图像的每个位置中时,形成图1H中最上的内核映射。第十二内核将被识别为在图1F(a)-图1F(l)和图1G(a)-图1G(l)的每一个中使用的内核。针对所选择的内核在概念上叠加在未知图像上的每个位置,计算内核值,并将内核值存储在内核映射上的其相应位置中。
同样在图1H中,其他滤波器(即,内核)也被应用于未知图像。为了简化讨论,图1B中的数字“1”的第29内核被选择,并且图1B中的数字“1”的第61内核被选择。对于每个内核,创建不同的内核映射。多个创建的内核映射可以被设想为内核映射堆栈,内核映射堆栈具有等于被应用的滤波器(即,内核)的数量的深度。内核映射的堆栈也可以被称为经滤波的图像的堆栈。
在CNN系统10的卷积处理中,单个未知图像被卷积,以创建经滤波的图像的堆栈。堆栈的深度与应用于未知图像的滤波器(即,内核)的数量相同,或者以其他方式基于应用于未知图像的滤波器的数量。将滤波器应用于图像的卷积处理也被称为“层”,因为它们可以堆叠在一起。
如图1H所示,在卷积层处理中生成大量的数据。另外,每个内核映射(即,每个经滤波的图像)在其中具有与原始图像几乎一样多的值。在图1H所示的示例中,原始未知输入图像由100(10×10)个像素形成,并且所生成的滤波器映射具有64个值(8×8)。因为所应用的9像素内核值(3×3)不能完全处理图像边缘处的最外的像素,所以只实现内核映射的尺寸的简单减少。
图1I示出了显著减少由卷积处理产生的数据量的池化功能。可以对一个、一些或全部经滤波的图像执行池化处理。图1I中的内核映射被识别为图1H的最上面的滤波器映射,其利用图1B中数字“1”的第12内核形成。
池化处理引入了“窗口尺寸”和“步幅”的概念。窗口尺寸是窗口的维度,使得在池化处理中选择窗口内的单个最大值。可以形成具有m个像素乘以n个像素的维度的窗口,其中“m”和“n”是整数,但是在大多数情况下,“m”和“n”相等。在图1I所示出的池化操作中,每个窗口被形成为2像素×2像素的窗口。在池化操作中,4像素的窗口概念上叠加在内核映射的所选择的部分上,并且在该窗口内,选择最高的值。
在池化操作中,以与概念上将内核叠加在未知图像上相似的方式,池化窗口概念上叠加在内核映射的每个部分上。“步幅”表示在每个池化动作之后移动池化窗口的程度。如果步幅被设置为“2”,则在每次池化动作之后,池化窗口被移动两个像素。如果步幅被设置为“3”,则在每次池化动作之后,池化窗口被移动三个像素。
在图1I的池化操作中,池化窗口的尺寸被设置为2×2,并且步幅也被设置为2。通过选择内核映射最上、最左角落中的四个像素来执行第一池化操作。由于窗口中的每个内核值均被计算为“-0.11”,所以来自池化计算的值也是“-0.11”。值“-0.11”被置于图1I中经池化的输出映射的最上、最左角落中。
然后,池化窗口向右移动两个像素的所选择的步幅,并且执行第二池化动作。再次,由于第二池化窗口中的每个内核值均被计算为“-0.11”,所以来自池化计算的值也是“-0.11”。值“-0.11”被置于图1I中经池化的输出映射的顶行的第二条目中。
池化窗口向右移动两个像素的步幅,并且窗口中的四个值被评估。第三个池化动作中的四个值是“+0.11”、“+0.11”、“+0.11”和“+0.33”。这里,在四个内核值的该组中,“+0.33”是最高值。因此,在图1I中,值“+0.33”置于经池化的输出映射的顶行的第三条目中。池化操作不关心在窗口中哪个位置找到最高值,池化操作只是选择落入窗口边界内的最高(即,最大)值。
剩余的13个池化操作也以类似的方式执行,以填充图1I的经池化的输出映射的剩余部分。对于其他生成的内核映射(即,经滤波的图像)中的一些或全部,也可以执行类似的池化操作。进一步考虑图1I的经池化的输出,并且进一步考虑所选择的内核(即,图1B中的数字“1”的第十二内核)和未知图像,认识到,在经池化的输出的右上角落中找到最高值。这是因为当将内核特征应用于未知图像时,所选择的感兴趣特征的像素(即,内核)与未知图像中被类似布置的像素之间的最高相关性也可以在右上角落中找到。还认识到,经池化的输出具有在其中捕获的值,该值松散地表示未经池化的、较大尺寸的内核映射中的值。如果正在搜索未知图像中的特定图案,则可以从经池化的输出映射中学习图案的近似位置。即使确定不知道特征的实际位置,观察者也可以认识到在经池化的输出中检测到该特征。实际特征可能在未知图像中稍微向左或稍微向右移动,或者实际特征可以被旋转或以其他方式与内核特征不同,但是,无论如何可以识别特征的出现及其整体位置。
图1I中还示出了可选的归一化操作。归一化操作通常由修正线性单元(ReLU)来执行。ReLU标识经池化的输出映射中的每个负数,并在归一化的输出映射中将负数替换为零(即,“0”)值。由一个或多个ReLU电路的可选的归一化处理有助于减少不然使用负数执行的计算所需要的计算资源的工作负载。
在ReLU层中的处理之后,可以对归一化输出映射中的数据进行平均,以预测在未知图像中是否找到由内核表征的感兴趣的特征。以这种方式,归一化输出映射中的每个值被用作指示该特征是否在图像中是否存在的加权的“投票”。在一些情况下,对若干特征(即,内核)进行卷积,并且进一步组合预测以更广泛地表征该图像。例如,如图1H所示,从数字“1”的已知图像导出的三个感兴趣的内核与未知图像进行卷积。在通过各层处理每个内核之后,对未知图像是否包括显示数字“1”的一个或多个像素图案进行预测。
总结图1A-图1I,从已知图像中选择内核。CNN不需要使用已知图像的每个内核。相反,可以选择被确定为“重要”特征的内核。在卷积处理产生内核映射(即,特征图像)之后,内核映射通过池化层和归一化(即,ReLU)层。输出映射中的所有值被平均(即,求和并相除),并且从平均获得的输出值被用作对未知图像是否包含已知图像中发现的特定特征的预测。在示例性情况下,输出值被用于预测未知图像是否包含数字“1”。在某些情况下,“投票列表”也可以用作后续堆叠层的输入。这种处理方式强烈地加强了所标识的特征,并减小了弱标识(或未标识)特征的影响。考虑到整个CNN,二维图像被输入到CNN,并在其输出处产生投票的集合。输出处的投票集合被用于预测输入图像是否包含由特征所表征的感兴趣对象。
图1A的CNN系统10可以被实现为一系列操作层。一个或多个卷积层之后可以是一个或多个池化层,并且可选地一个或多个池化层之后可以是一个或多个归一化层。卷积层从单个未知图像创建多个内核映射(或称为经滤波的图像)。使用一个或多个池化层来减少多个经滤波的图像中的大量数据,并且通过一个或多个ReLU层(其通过去除所有负数将数据归一化)进一步减少数据量。
图1J更详细地示出了图1A的CNN系统10。在图1J(a)中,CNN系统10将10像素×10像素的输入图像接受到CNN中。CNN包括卷积层、池化层、修正线性单元(ReLU)层和投票层。一个或多个内核值与未知的10×10图像协同卷积,并且来自卷积层的输出被传递到池化层。在由卷积层提供的每个内核映射上执行一个或多个最大池化操作。来自池化层的经池化的输出映射被用作产生归一化输出映射的ReLU层的输入,并且在归一化输出映射中包含的数据被求和并相除,以确定输入图像是否包括数字“1”或数字“0”的预测。
在图1J(b)中,示出了另一CNN系统10a。CNN系统10a中的CNN包括多个层,多个层可以包括卷积层、池化层、归一化层和投票层。来自一个层的输出用作下一层的输入。在每次通过卷积层时,数据被滤波。因此,可以将图像数据和其他类型数据进行卷积,以搜索(即,滤波)任何特定特征。当通过池化层时,输入数据通常保留其预测信息,但数据量被减少。由于图1J(b)的CNN系统10a包括许多层,所以CNN被布置为预测输入图像包含许多不同特征中的任何一个。
CNN的另一特性是使用反向传播来减少误差并提高神经网络的质量,以识别大量输入数据中的特定特征。例如,如果CNN到达小于1.0的预测,并且该预测稍后被确定为是准确的,那么所预测的值与1.0之间的差被认为是误差率。由于神经网络的目标是准确地预测特定特征是否被包括在输入数据集中,所以可以进一步引导CNN来自动调整在投票层中应用的加权值。
反向传播机制被布置为实现梯度下降的特征。梯度下降可以应用在二维映射上,其中映射的一个轴表示“误差率”,而映射的另一个轴表示“权重”。以这种方式,这样的梯度下降映射将优选地采取抛物线形状,使得如果误差率高,则导出的值的权重将较低。当误差率下降时,导出的值的权重将增加。因此,当实现反向传播的CNN继续操作时,CNN的准确性具有继续自动改善自身的潜能。
使用机器学习方法的已知对象识别技术的性能通过将更强大的模型应用于更大的数据集、并实现更好的技术以防止过拟合来改进。两个已知的大型数据集包括LabelMe和ImageNet。LabelMe包括数十万个完全分段的图像,并且ImageNet中包括超过1500万个高分辨率,超过22000个类别的标签图像。
为了从数百万图像中学习数千个对象,应用于图像的模型需要大的学习能力。具有足够学习能力的一个类型的模型是卷积神经网络(CNN)模型。为了补偿不存在关于巨大数据池的特定信息,CNN模型被布置为具有数据集的至少一些先验知识(例如,统计平稳性/非平稳性、空间性、时间性、像素依赖性的局部性等)。CNN模型进一步被布置为具有设计者可选择的特征集(例如,容量、深度、宽度、层数等)。
早期的CNN是使用大型专用超级计算机实现的。常规的CNN是使用自定义的强大图形处理单元(GPU)来实现的。如Krizhevsky所描述的,“当前的GPU,与2D卷积的高度优化实现相结合,足够强大来帮助相当大型的CNN进行训练,并且最近的数据集(例如,ImageNet)包含足够的标签示例,以在没有严重的过拟合的情况下,对这些模型进行训练。”
图2包括图2A-图2B。
图2A是已知的AlexNet DCNN架构的图示。如Krizhevsky所述,图1示出了“两个GPU之间的责任划分。一个GPU运行图的顶部处的层部分,而另一个则运行底部处的层部分。GPU仅在某些层进行通信。网络输入为150,528维度的,并且网络的剩余层中的神经元的数量为253,440-186,624-64,896-64,896-43,264-4096-4096-1000。”
Krizhevsky的两个GPU实现了高度优化的二维(2D)卷积框架。最终的网络包含具有权重的八个学习层。八个层由五个卷积层CL1-CL5(其中一些之后是最大池化层)和具有最终的1000路softmax(其产生超过1000个类标签的分布)的三个全连接层FC组成。
在图2A中,卷积层CL2、CL4、CL5的内核仅被连接到在同一GPU上处理的先前层的内核映射。相比之下,卷积层CL3的内核被连接到卷积层CL2中的所有内核映射。全连接层FC中的神经元被连接到前一层中的所有神经元。
响应归一化层在卷积层CL1、CL2之后。最大池化层在响应归一化层以及卷积层CL5之后。最大池化层总结同一内核映射中相邻神经元组的输出。修正线性单元(ReLU)的非线性被应用于每个卷积层和全连接层的输出。
图1A的AlexNet架构中的第一卷积层CL1利用4像素的步幅通过尺寸为11×11×3的96个内核对224×224×3的输入图像进行滤波。该步幅是内核映射中相邻神经元的接受域的中心之间的距离。第二卷积层CL2将第一卷积层CL1的经响应归一化并经池化的输出作为输入,并且将具有尺寸为5×5×48的256个内核的第一卷积层的输出进行滤波。在没有任何中间池化层或归一化层的情况下,第三、第四和第五卷积层CL3、CL4、CL5彼此连接。第三卷积层CL3具有尺寸为3×3×256的384个内核,384个内核被连接到第二卷积层CL2的归一化的池化输出。第四卷积层CL4具有尺寸为3×3×192的384个内核,并且第五卷积层CL5具有尺寸为3×3×192的256个内核。全连接层各自具有4096个神经元。
AlexNet架构的八个层的深度似乎非常重要,因为特定的测试表明,去除任何卷积层导致不可接受的降低的性能。网络的尺寸受以下项限制:所实现的GPU上可用的存储量以及被认为可容忍的训练时间的量。在两个NVIDIA GEFORCE GTX 580 3GB GPU上,图1A的AlexNet DCNN架构需要五到六天的时间来进行训练。
图2B是已知GPU(例如,NVIDIA GEFORCE GTX 580GPU)的框图。GPU是流式多处理器,流式多处理器包含32个采用灵活标量架构的统一设备架构处理器。GPU被布置用于纹理处理、阴影映射处理和其他以图形为中心的处理。GPU中的32个处理器中的每一个包括完全流水线的整数算术逻辑单元(ALU)和浮点单元(FPU)。FPU符合针对浮点算术的IEEE 754-2008行业标准。在这种情况下,GPU被特别配置用于桌面应用程序。
在被称为经线的32个线程的组中调度GPU中的处理。32个线程中的每一个同时执行相同的指令。GPU包括两个经线调度器和两个指令分派单元。在该布置中,可以同时发出和执行两个独立的经线。
背景技术部分中讨论的所有主题都不一定是现有技术,并且不应仅仅因为在背景技术部分的讨论而被认为是现有技术。沿着这样的思路,除非明确地声明是现有技术,否则在背景技术部分中讨论的现有技术或与该主题相关联的现有技术中的任何问题的认识都不应被视为现有技术。相反,对背景技术部分中任何主题的讨论应被视为发明人到特定问题的途径的一部分,该问题本身也可以是具有创造性的。
技术实现要素:
本公开的实施例的目的在于提供至少部分解决上述技术问题的串流开关。
在一个示例性架构中,在片上系统(SoC)中形成两个或更多个(例如,八个)数字信号处理器(DSP)集群。每个DSP集群可以包括两个或更多个DSP、一个或多个多路(例如,4路)多字节(例如,16kB)指令高速缓存、一个或多个多字节(例如,64KB)本地专用存储器(例如,随机存取存储器(RAM))、一个或多个多字节共享存储器(例如,64kB共享RAM)、一个或多个直接存储器访问(DMA)控制器和其他特征。可重新配置的数据流加速器结构可以被包括在示例性架构中,以将大型数据产生设备(例如,高速相机、音频捕获设备、雷达或其他电磁捕获或生成设备等)与互补电子设备(例如,传感器处理流水线、裁剪器、颜色转换器、特征检测器、视频编码器、多通道(例如,8通道)数字麦克风接口、流式DMA、以及一个或多个(例如,八个)卷积加速器)连接。
示例性架构可以在SoC中包括一个或多个(例如,四个)静态随机存取存储器(SRAM)库或具有多字节(例如,1M字节)存储器的一些其他架构存储器、一个或多个专用总线端口以及粗粒度功率门控逻辑、细粒度功率门控逻辑或粗粒度与细粒度的功率门控逻辑。该示例性架构被布置为,针对在不进行剪枝或较大拓扑(并且在一些情况下,如果使用较少的比特用于激活和/或权重,则是特别大的拓扑)的情况下对诸如AlexNet的DCNN拓扑进行适配的卷积级,在不需要访问外部存储器的情况下维持可接受的高通量。在不需要这种外部存储器访问的情况下,节省电力。
当在常规的非移动硬件平台上实现最先进的DCNN时,已知这样的DCNN产生了极好的结果。然而,这样的DCNN需要具有许多层、数百万个参数和不同的内核尺寸的更深度的拓扑。这些附加特征需要非常高的带宽、高功率以及迄今为止在嵌入式设备中不可用的其他计算资源成本。然而,本文所呈现的设备和方法已经实现了足够的带宽、足够的功率和足够的计算资源来提供可接受的结果。这样的结果部分归因于利用分层存储器系统和对本地数据的有效复用实现的改进的效率。加速DCNN卷积层占高达90%,并且更多的总体操作需要在不会碰触任何相关的上限的情况下,针对带宽和面积两者来有效地平衡计算资源和存储器资源,以实现可接受的高通量。
在示例性架构中,设计时间可配置的加速器框架(CAF)包括经由可配置的全连接的开关传输数据串流(来自源设备、被传输到宿设备,或被传输到宿设备并且来自源设备)的单向链路。源设备和宿设备可以包括DMA、输入/输出(I/O)接口(例如,多媒体、卫星、雷达等)以及包括一个或多个卷积加速器(CA)的各种类型的加速器中的任何一个或多个。
可重新配置的数据流加速器结构允许在运行时定义任何期望的确定数量的并发虚拟处理链。全功能的背压机制处理数据流控制,并且串流多播使得在多个块实例中能够复用数据串流。可以形成链接的列表,以控制整个卷积层的完全自主处理。多个加速器可以被分组或以其他方式链接在一起,以并行地处理不同尺寸的特征映射数据和多个内核。
可以将多个CA分组以实现更大的计算实体,更大的计算实体通过使得能够选择可用数据带宽、功率和可用处理资源的期望平衡,为神经网络设计提供灵活性。内核集合可以被分批划分并顺序处理,并且中间结果可以被存储在片上存储器中。单个CA实例可以处理各种内核大小(例如,高达12×12)、各种批次大小(例如,高达16个)和并行内核(例如,高达4个),并且利用累加器输入可以容纳任何大小的内核。CA包括线缓冲器,以与单个存储器访问并行地获取多个(例如,多达12个)特征映射数据字。基于寄存器的内核缓冲器提供多个读取端口(例如,多达36个),而多个(例如,36个)多比特(例如,16比特)定点乘法累加(MAC)单元在每个时钟周期执行多个(例如,多达36个)MAC操作。加法器树累加针对每个内核列的MAC结果。MAC操作的重叠的基于列的计算允许针对多个MAC的特征映射数据的可接受的最优复用,这降低了与冗余存储器访问相关联的功耗。可配置的批次大小与可变数量的并行内核为神经网络设计者提供了灵活性,以权衡在不同的单元和可用的计算逻辑资源之间共享的可用的输入和输出带宽。
在一些情况下,为每个DCNN层手动定义CA的配置;在其他一些情况下,例如,可以使用整体性工具从DCNN描述格式(例如,Caffe'或TensorFlow)开始自动定义CA配置。在示例性架构的一些实施例中,每个CA可以被配置为:当以每个权重8比特或更少比特(对于8比特,top-1误差率最高为0.3%)对内核进行非线性量化时,支持即时内核解压缩和舍入。
在示例性架构的一些实施例中,每个32比特DSP被布置为执行特定指令集中的任何一个或多个指令(例如,Min、Max、Sqrt、Mac、Butterfly、Average、2-4SIMD ALU),以加速和支持DCNN的卷积操作。具有16比特饱和的MAC、高级存储器缓冲器寻址模式和零延时环路控制的双负载在单个循环中执行,而独立的二维(2D)DMA通道允许数据传递的叠加。DSP执行池化(例如,最大池化、平均池化等)、非线性激活、跨通道响应归一化和分类,这些代表在灵活和适应未来算法演化的架构中,总体DCNN计算的所选择的部分。示例性架构中的DSP可以与CA和数据传递并行操作,同时使用中断、邮箱或用于并发执行的其他此类机制来同步操作和事件。当通量目标要求时,DSP可以被逐步激活,从而留下足够的余量来支持与复杂应用相关的其他任务。这样的附加任务可以包括对象定位和分类、基于多感官(例如,音频、视频、触觉等)DCNN的数据融合和识别、场景分类或任何其他此类应用中的任何一个或多个。在本发明人构建的一个实施例中,示例性架构在使用28nm完全耗尽型绝缘体上硅(FD-SOI)工艺制造的测试设备中形成,从而证明了对于高级真实世界功率约束的嵌入式应用(例如,智能互联网事物(IoT)设备、传感器和其他移动或移动类设备)有效的架构。
在第一实施例中,在集成电路中形成一种可重新配置的串流开关。串流开关包括多个输出端口、多个输入端口和多个选择电路。多个输出端口均具有输出端口架构组成,并且每个输出端口被布置为在多个输出线上单向传递输出数据并输出控制信息,其中输出端口架构组成由N个数据路径定义。N个数据路径包括A个数据输出和B个控制输出,其中N、A和B是非零整数。多个输入端口均具有输入端口架构组成,并且每个输入端口被布置为在第一多个线上单向接收第一输入数据和第一输入控制信息,其中输入端口架构组成由M个数据路径定义。M个数据路径包括A个数据输入和B个控制输入,其中M是等于N的整数。多个选择电路中的每一个被耦合到多个输出端口中的相关联的一个。每个选择电路还被耦合到所有多个输入端口,使得每个选择电路被布置为在任何给定时间将其相关联的对应输出端口重新配置地耦合到不超过一个输入端口。
在第一实施例的至少一些情况下,输出端口架构组成的线具有输入端口架构组成的相应线。在这些情况中的一些情况下,输出端口架构组成和输入端口架构组成的线包括被布置为在第一方向上单向传递第一数据的第一多个数据线、被布置为在第一方向上单向传递第二数据的第二多个数据线、被布置为在第一方向上单向传递第三数据的第三多个数据线、被布置为在第一方向上单向传递控制信息的多个控制线、以及被布置为在第二方向上单向传递流控制信息的至少一个流控制线,第二方向不同于第一方向。
在第一实施例的至少一些情况下,多个选择电路允许多个输入端口中的每一个并发地可重新配置地耦合到至少两个输出端口。在这些情况中的一些情况下,组合背压逻辑模块被耦合到每个输入电路。这里,组合背压逻辑模块被布置为鉴别多个流控制信号。鉴别被布置为将有效的流控制信号从可重新配置地耦合到相关联的输入端口的任何输出端口传递到其相关联的输入端口,并且鉴别还被布置为忽略来自不可重配置地耦合到相关联的输入端口的任何输出端口的每个无效流控制信号。在这些情况中的一些情况下,有效的流控制信号被布置为在断言有效的流控制信号的同时减慢或停止来自相关联的输入端口的流式数据,并且在这些情况的一些情况下,多个选择电路中的每一个包括配置逻辑。配置逻辑被布置为引导其相关联的对应输出端口的可重新配置的耦合。配置逻辑还被布置为从包括以下项的多个源获得引导:通过耦合的输入端口传递的第一输入数据、通过耦合的输入端口传递的第一输入控制信息、以及存储在与可重新配置的串流开关相关联的至少一个控制寄存器中的控制寄存器信息。
在第一实施例的至少一些情况下,可重新配置的串流开关还包括与可重新配置的串流开关相关联的控制寄存器集合。控制寄存器集合被布置用于在运行时进行编程,并被布置为控制多个选择电路中的输入端口和输出端口的可重新配置的耦合。在这些情况中的一些情况下,可重新配置的串流开关还包括消息/命令逻辑,消息/命令逻辑被布置为从通过多个输入端口中的一个传递的至少一些第一输入数据捕获命令信息。命令信息被布置为在运行时对控制寄存器集合中的至少一个进行编程。在第一实施例的一些情况下,可重新配置的串流开关还包括输出同步级,输出同步级被布置为当耦合到多个输入端口中的第一输入端口的源设备和耦合到多个输出端口的输出端口的接收设备异步操作时,通过可重新配置的串流开关协调数据传输。
在第二实施例中,一种形成在片上系统(SoC)的协处理器中的串流开关包括N个多比特输入端口(其中N是第一整数)以及M个多比特输出端口(其中M是第二整数)。在该实施例中,串流开关还包括M个多比特串流链路。M个多比特串流链路中的每一个专用于M个多比特输出端口中的不同的一个,并且M个多比特串流链路中的每一个在运行时可重新配置地耦合到N个多比特输入端口中的可供选择的数量的多比特输入端口。可供选择的数量是零和N之间的整数。
在第二实施例的一些情况下,M个多比特串流链路中的每个多比特串流链路包括多个数据线、多个控制计划和背压机制。多个数据线被布置为仅在第一方向上传递流式数据,其中第一方向是从耦合到多比特串流链路的输入端口朝向其专用的输出端口。多个控制线被布置为仅在第一方向上传递控制数据,并且背压机制被布置为仅在第二方向上传递背压数据。第二方向是从专用串流链路的输出端口朝向耦合到多比特串流链路的输入端口。
在第二实施例的一些情况下,N=M。在第二实施例的这些情况的一些情况下,M个多比特串流链路中的每个多比特串流链路包括串流开关配置逻辑,串流开关配置逻辑布置为根据存储在与串流开关相关联的至少一个控制寄存器中的控制寄存器信息,引导专用输出端口的可重新配置的耦合。
根据本公开的实施例,新的加速器和接口的设计和集成被大大简化。此外,现有加速器的复用变得更加容易。在一些情况下,调试和原型设计被大大简化,原因是每个数据串流都可以在运行时被复制并被路由到处理链的任一级处的调试模块。以这种方式,算法设计者或其他软件从业者可以在运行时有效地跟踪、监视和调试或以其他方式评估系统中的任何处理链。
在本公开中所讨论的工具和方法阐述了支持基于数据流的处理链的设计时间参数化的、运行时可重新配置的硬件加速器互连框架的一个或多个方面。
本公开中所描述的创新是新的和有用的,并且创新在硅制造行业中不是众所周知的、常规的或传统的。本文所描述的创新的一些部分可以使用以新的和有用的方式组合的已知的构造块以及其他结构和限制,来创建比常规已知的东西更多的东西。实施例在已知的计算系统上进行改进,在未经编程或以不同方式被编程时,已知的计算系统不能执行或提供本文要求保护的特定可重新配置的框架特征。
在这里的实施例中所描述的计算机化动作不是完全常规的,也没有被很好地理解。相反,这些动作对于业界而言是新的。此外,结合本实施例所描述的动作的组合提供了当单独考虑这些动作时并不存在的新的信息、动机和商业结果。
对于什么被视为抽象想法,并不存在普遍接受的定义。在本公开中讨论的概念可以被认为是抽象的范围内,权利要求提出了所述所谓的抽象概念的实际、实践和具体应用。
本文所描述的实施例使用计算机化技术来改进硅制造技术和可重新配置的互连技术,但是其他技术和工具仍然可用于制造硅并提供可重新配置的互连。因此,所要求保护的主题不排除硅制造或可重新配置的互连技术领域的整体或任何相当大的部分。
这些特征以及随后将变得显而易见的其他目的和优点存在于下文更全面地描述的且参考形成其一部分的附图所要求保护的结构和操作的细节中。
已经提供了本实用新型内容以简化形式介绍某些概念,这些概念将在具体实施例中被进一步详细描述。除非另有明确说明,否则本实用新型内容不标识所要求保护的主题的关键或必要特征,也不意图限制所要求保护的主题的范围。
附图说明
参考以下附图描述了非限制性和非穷尽的实施例,其中除非另有说明,否则在贯穿各种视图,相同的标签指代相同的部分。附图中的元素的尺寸和相对位置不一定按比例绘制。例如,选择、放大和定位各种元素的形状来提高附图的可读性。所绘制的元素的特定形状已被选择,用于在附图中易于识别。以下参考附图描述一个或多个实施例,其中:
图1包括图1A-图1J;
图1A是卷积神经网络(CNN)系统的简化图示;
图1B示出了确定第一像素图案示出“1”并且第二像素图案示出“0”的图1A的CNN系统;
图1C示出了0和1的不同形式的若干变化;
图1D表示将未知图像的部分与已知图像的对应部分进行分析(例如,数学组合)的CNN操作;
图1E示出了图1D的右侧已知图像的六个部分;
图1F示出了滤波处理中的12个卷积动作;
图1G示出了图1F的12个卷积动作的结果;
图1H示出了内核值的映射的堆叠;
图1I示出了显著减少由卷积处理产生的数据量的池化特征;
图1J更详细地示出了图1A的CNN系统;
图2包括图2A-图2B;
图2A是已知的AlexNet DCNN架构的图示;
图2B是已知GPU的框图;
图3是以框图示出的其中集成了DCNN处理器实施例的示例性移动设备;
图4包括图4A-图4C;
图4A是可配置的加速器框架(CAF)的一个实施例;
图4B是被配置用于简单对象检测的一个CAF实施例;
图4C是到系统总线接口架构的串流开关的一个实施例;
图5包括图5A-图5B;
图5A是一个串流开关实施例;
图5B是示出了串流开关实施例的示例性使用的操作;
图6包括图6A-图6D;
图6A是第一卷积加速器(CA)实施例;
图6B是第二卷积加速器(CA)实施例;
图6C是图6B的第二CA实施例的组织参数的集合;
图6D是示出了示例性卷积操作的框图;
图7是示出用于训练深度卷积神经网络(DCNN)并使用经训练的DCNN配置片上系统(SoC)的数据路径的高级框图;以及
图8包括图8A-图8B,其示出了用于设计和配置SoC(图8A)并利用所配置的SoC来识别图像中的对象(图8B)的处理的流程图。
具体实施方式
本发明人已经认识到,已知的深度卷积神经网络(DCNN)系统很大,并且需要大量的功率来实现。由于这些原因,在移动设备中没有发现常规的DCNN系统,并且在尝试使用DCNN移动系统的情况下,系统有许多缺点。
为了在日常生活中部署这些技术,使其在移动和可穿戴设备中普遍存在,本发明人进一步认识到硬件加速起着重要的作用。当如本文所描述的来实现时,硬件加速为移动DCNN提供能够以降低功耗和嵌入式存储器进行实时工作的能力,从而克服了常规的完全可编程解决方案的限制。
本文所描述的高性能、高能效的硬件加速DCNN处理器包括支持内核解压缩、快速数据通量和高效数学运算的DCNN硬件卷积加速器的能量高效的集合。处理器还包括改进数据复用、降低片上和片外存储器流量的片上可重新配置的数据传输构造以及支持完整的真实世界计算机视觉应用的DSP的功率高效的阵列。
图3-图6及其所附的详细描述示出并呈现了可配置为高性能、高能效的硬件加速DCNN处理器的示例性片上系统(SoC)110的元件。SoC 110对神经网络应用特别有用。神经网络的一个重要挑战是其计算的复杂度。在示例性SoC 110中通过集成架构有效的串流开关500(图5)和卷积加速器600的集合(图6)来克服这个挑战,卷积加速器600对输入特征数据和从神经网络训练得到的内核数据执行卷积。
卷积神经网络通常由多个层组成。已知的AlexNet(图2A)具有五个卷积层和三个全连接层。现在结合AlexNet的神经网络的非限制性模型实现来讨论图3-图6的示例性SoC 110的操作以及图6的卷积加速器600的特定操作和示例性参数、配置及限制。
AlexNet神经网络的每个卷积层包括相互关联的卷积计算的集合,随后是其他较不复杂的计算(例如,最大池化计算、非线性激活计算等)。卷积处理阶段执行被应用到大的数据集的大量的乘法累加(MAC)操作。在该上下文中,卷积加速器600被明确地配置为增加卷积计算的速度和效率,同时也减少了所消耗的功率。
卷积加速器600可以如本文所述地布置,以实现(例如,电池供电的)嵌入式设备中的低功率神经网络。卷积加速器600可以在可用于实时应用的时间帧中执行处理卷积神经网络所需的大量操作。例如,用于图像帧中的对象识别的已知神经网络AlexNet的单个处理运行对于具有227×227像素大小的帧需要超过700个百万乘法累加(MMAC)操作。来自相机传感器的合理视频数据串流以每帧多个兆的像素的分辨率提供每秒15到30帧。虽然所需的处理性能超出了常规嵌入式中央处理单元(CPU)的限制,但是在SoC 110的示例性实施例中,发明人在嵌入式设备可持续的功率耗散水平上已经证明这种操作。
在下面的描述中,阐述了某些具体细节,以提供对各种所公开的实施例的透彻理解。然而,相关领域的技术人员将认识到,可以在没有这些具体细节中的一个或多个的情况下、或利用其他方法、部件、材料等来实践实施例。在其他实例中,与计算系统(包括客户端和服务器计算系统以及网络)相关联的众所周知的结构没有被详细地示出或描述,以避免不必要地遮蔽对实施例的描述。
通过参考下面对本实用新型的优选实施例的详细描述,可以更容易地理解本实用新型。应当理解,本文所使用的术语仅用于描述具体实施例的目的,而不是限制性的。还应当理解,除非本文特别限定,否则本文所使用的术语应被赋予其在相关领域中已知的传统含义。
然而,在阐述实施例之前,对于理解这些实施例,首先阐述以下使用的某些术语的定义可能是有帮助的。
半导体从业者通常是半导体设计和制造领域的普通技术人员。半导体从业者可以是具有引导和平衡半导体制造项目的特征的技能的技术人员或系统,这些特征例如是诸如几何、布局、功率使用、所包括的知识产权(IP)模块等。半导体从业者可以理解或可能不理解为形成管芯、集成电路或其他这样的器件而进行的制造过程的每个细节。
图3是以框图示出的其中集成有DCNN处理器实施例的示例性移动设备100。移动DCNN处理器被布置为片上系统(SoC)110,然而也考虑其他布置。图3的示例性移动设备100可以被配置在任何类型的移动计算设备中,例如,智能电话、平板、膝上型计算机、可穿戴设备(例如,眼镜、夹克、衬衫、裤子、袜子、鞋子、其他服装、帽子、头盔、其他头饰、腕表、手镯、吊坠、其他首饰)、车载设备(例如,火车、飞机、直升机、无人机、无人水下航行器、无人陆上车辆、汽车、摩托车、自行车、滑板车、悬停板、其他个人或商业运输设备)、工业设备等。因此,移动设备100包括未示出的其他部件和电路系统,例如,显示器、网络接口、存储器、一个或多个中央处理器、相机接口、音频接口和其他输入/输出接口。在一些情况下,图3的示例性移动设备100也可以被配置在不同类型的低功率设备中,例如,安装的摄像机、物联网(IoT)设备、多媒体设备、运动检测设备、入侵者检测设备、安全设备、人群监控设备或一些其他设备。
参考图3-图6,其示意性地示出了示例性移动设备100和片上系统(SoC)110的一部分、SoC 110的至少一部分、以及SoC 110和移动设备100的附加更多或更少的电路可以被提供在集成电路中。在一些实施例中,可以在集成电路中提供图3-图6所示的所有元件。在备选实施例中,图3-图6所示的一个或多个布置可以由两个或更多个集成电路提供。一些实施例可以由一个或多个管芯实现。一个或多个管芯可以被封装在相同或不同的封装件中。可以在集成电路或管芯的外部提供图3-图6所示的部件中的一些。
图3-图6的SoC 110设备在设计时可以在拓扑、最大可用带宽、每单位时间的最大可用操作、最大并行执行单元和其他这样的参数中的一个或多个方面固定。SoC 110的一些实施例可以在运行时提供可重新编程的功能(例如,重新配置SoC模块和特征以实现DCNN)。可以在一个或多个初始化阶段期间配置可重新编程的功能中的一些或全部。可以在无延时、可屏蔽的延时或可接受的延时水平的情况下在飞行中配置可重新编程的功能中的一些或全部。
考虑具有被布置为片上系统(SoC)110的示例性移动DCNN处理器的示例性移动设备100的实现。所示的SoC 110包括多个SoC控制器120、可配置的加速器框架(CAF)400(例如,图像和DCNN协处理器子系统)、SoC全局存储器126、应用(例如,主机)处理器128、以及多个DSP 138,其中每一个被直接或间接地通信耦合到主(例如,系统)通信总线132和次级通信(例如,DSP)总线166。
在一些实施例中,如图所示,多个DSP 138被布置在多个DSP集群中,例如,第一DSP集群122、第二DSP集群140以及为了简化图示而未被参考的若干其他DSP集群。下面更多地描述多个DSP 138中的单独的DSP集群。
可配置的加速器框架(CAF)400被通信耦合到系统总线166,系统总线166提供CAF 400的卷积加速器根据需要访问SoC全局存储器126和根据需要与DSP 138通信的机制。下面更详细地描述CAF 400。
SoC 110包括各种SoC控制器120,SoC控制器120中的一些控制SoC 110,并且SoC控制器120中的其他一些控制一个或多个外围设备。SoC控制器120包括应用(例如,主机)处理器128(例如,ARM处理器或一些其他主机处理器)、时钟发生器168(例如,时钟管理器)、复位控制器170和电源管理器172,以提供对SoC 110和其他部件的各种时序、功耗和其他方面的附加的支持、控制和管理。控制外围设备的其他SoC控制器120包括低速外围设备I/O接口130和外部存储器控制器174,以与SoC 110所嵌入的示例性设备100的外部芯片、部件或存储器进行通信或以其他方式对其进行访问。
应用处理器128可以充当中间模块或到集成SoC 110的示例性电子设备100的其他程序或部件的接口。在一些实施例中,应用处理器128可以被称为应用处理器核心。在各种实施例中,应用处理器128在启动时加载SoC配置文件,并根据配置文件配置DSP 138和CAF 400。当SoC 110处理一个或多个批次的输入数据(例如,图像)时,应用处理器128可以基于配置文件协调CAF 400或DSP 138的重新配置,配置文件本身可以基于DCNN层和拓扑。
SoC 110还包括支持SoC控制器120和DSP 138之间以及SoC控制器120和CAF 400之间的通信的主通信总线132(例如,AXI-高级可扩展接口)。例如,DSP 138或CAF 400可以经由主通信总线132与应用处理器128进行通信,经由外部存储器控制器174或其他部件与一个或多个外围控制器/外围通信接口(低速外围设备I/O)130、外部存储器(未示出)进行通信。SoC控制器120还可以包括其他支持和协作设备,诸如时钟管理器(例如,时钟发生器)168、复位控制器170、功率管理器172,以向SoC 110提供附加定时和功率管理,以及其他部件。
如上所述,多个DSP 138可以被布置在多个DSP集群(例如,DSP集群122、140)中。此外,SoC 110可以包括其他DSP集群,但为了简化图示,这里不再参考这些集群。
每个DSP集群122、140包括:多个(例如,两个)DSP 142、152;多个(例如,两个)本地DSP纵横开关144、154;以及DSP集群纵横开关145、155。在特定集群中的每个DSP 142、152经由DSP集群纵横开关145、155彼此通信。每个DSP 142、152经由其对应的本地DSP纵横开关144、145访问对应的指令高速缓存146、156和本地DSP存储器148、158。在一个非限制性实施例中,每个指令高速缓存146、156是4路16kB指令高速缓存,并且每个本地DSP存储器148、158是针对其对应DSP的64kB的本地RAM存储装置。每个DSP集群122、140还包括共享DSP集群存储器160、159和用于访问SoC全局存储器160、159的集群DMA 162、164。
每个DSP集群122、140经由DSP集群纵横开关145、155通信耦合到全局DSP集群纵横开关150,以使得每个DSP集群122、140中的每个DSP 142、152能够彼此通信,并且与SoC 110上的其他部件通信。全局DSP集群纵横开关150使得每个DSP能够与多个DSP集群138中的其他DSP进行通信。
此外,全局DSP集群纵横开关150通信耦合到系统总线166(例如,辅助通信总线、xbar-SoC纵横开关等),这使得每个DSP能够与SoC 110的其他部件通信。例如,每个DSP 142、152可以与CAF 400的一个或多个部件(例如,一个或多个卷积加速器)进行通信,或者经由系统总线166访问SoC全局存储器126。在一些实施例中,每个DSP 142、152可以经由其对应的DSP集群122、140的DMA 162、164与SoC存储器126通信。此外,DSP 142、152可以根据需要经由系统总线166与控制器120或SoC 110的其他模块进行通信。每个DSP经由其本地DSP纵横开关144、154、其DSP集群纵横开关145、155以及全局DSP集群纵横开关150来访问系统总线166。
可以分配或指派多个DSP 138,以执行特定指令来对DCNN的其他操作进行加速。这些其他操作可以包括在DCNN处理期间执行(在一些情况下主要由CAF 400执行)的非卷积操作。这些非卷积操作的示例包括但不限于最大池化或平均池化、非线性激活、跨通道响应归一化、表示总DCNN计算的一小部分但更适合未来的算法演进的分类、或其他运算(例如,Min、Max、Sqrt、Mac、Butterfly、Average、2-4SIMD ALU)。
DSP 138可以与CAF 400中的CA的操作并发(例如,并行)地操作,并且与数据传递并发(例如,并行)地操作,可以通过中断、邮箱或用于并发执行的一些其他同步机制来对数据传递进行同步。当通量目标需要时,DSP 138可以被递增地激活,留下足够的余量以支持与复杂应用相关联的附加任务,例如,对象定位和分类、多感觉(例如,音频、视频、触觉等)基于DCNN的数据融合和识别、场景分类以及其他这样的任务。在一些情况下,DSP 138可以包括具有多比特(例如,16比特)饱和MAC、高级存储器缓冲器寻址模式和零延时环路控制特征的双重负载。DSP 138可以在单个周期中执行,而独立的2D DMA通道允许数据传递的叠加。
在各种实施例中,SoC存储器126包括用于存储CAF 400或DSP 138的部件可访问的数据的多个存储器部件。在至少一个实施例中,SoC存储器126以分级型存储器结构配置。在一个非限制性示例中,SoC存储器126包括各具有1M字节的四个SRAM库、专用总线端口和细粒度电源门控。该存储器有助于增加并维持在不剪枝的情况下适合特定DCNN拓扑(例如,AlexNet)的卷积级可接受的最大通量。附加地或备选地,如果较少的比特用于激活和/或权重,则在不需要访问外部存储器以节省功率的情况下,SoC存储器126还可以维持较大的拓扑。
在至少一个示例性情况中,SoC 110被布置为使得通过CAF 400中的处理逻辑对SoC存储器126的访问将消耗平均每个字50皮焦(50pJ/字)的功率,这大大小于访问在SoC 110的板外的存储器的功率。例如,对片外存储器的访问将平均消耗640pJ/字。相反,在本公开的至少一些实施例中,CAF 400中的处理逻辑将仅访问CAF 400板上的本地SRAM,并且在这些情况下,对存储器的访问将平均消耗5pJ/字或更少。因此,CAF 400的设计允许可接受的非常低的功耗,这对于嵌入式设备是期望的。
在至少一个实施例中,可配置的加速器框架(CAF)400可以被组织为SoC 110的图像和DCNN协处理器子系统。如本文所述,CAF 400包括可重新配置的数据流加速器结构,数据流加速器结构将高速相机接口与传感器处理流水线、裁剪器、颜色转换器、特征检测器、视频编码器、八通道数字麦克风接口、流式DMA和多个卷积加速器中的任何一个或多个进行连接。关于CAF 400的附加细节将结合图4进行描述。简而言之,CAF 400从相机接口或其他传感器接收传入图像数据,并将传入数据分配到CAF 400的各种部件(例如,结合图6更详细地描述的卷积加速器)和/或多个DSP 138中的一个或多个,以使用DCNN并识别传入图像中的对象。
各种DCNN利用具有许多层、数百万个参数和不同内核大小的更深度的拓扑,这导致带宽、功率和面积成本挑战的升级。这些各种DCNN也可以使用本文所述的SoC 110来实现。可以使用分层存储器系统和本地数据的有效复用来实现可接受的效率。在某些情况下,对DCNN卷积层加速可以占用总操作调用的高达90%甚至超过90%。在SoC 110中实现的CAF 400允许计算资源与存储器资源(例如,带宽和物理面积/布局)的有效平衡,使得可以在不触碰任何相关联的上限的情况下,实现可接受的最大通量。
CAF 400利用单向链路经由可配置的、完全连接的开关将数据串流传输到不同种类的宿部件或传输来自不同种类的源部件的数据串流。例如,可配置的完全连接的开关(结合图5更详细地描述)可以经由直接存储器访问(DMA)将数据传输到SoC全局存储器126、I/O接口(例如,相机)以及各种类型的加速器(例如,卷积加速器(CA))。在某些情况下,基于从特定SoC配置工具接收的信息,在启动时配置CAF 400,并且基于从一个或多个DSP 138、应用处理器128等接收的拓扑或信息和所定义的DCNN层在运行时期间重新配置CAF 400。
CAF 400允许在运行时定义可选数量的并发虚拟处理链。CAF 400还包括全功能的背压机制来控制到框架的各个部件的数据流。CAF 400被布置用于串流多播操作,这使得能够在多个块实例处复用数据串流。链接列表控制整个卷积层的完全自主处理。分组或链接在一起的多个加速器可以并行处理不同大小的特征映射数据和多个内核。对卷积加速器(CA)600进行分组以实现更大的计算实体使得能够选择可用数据带宽、预算功率以及可用处理资源的可接受的最佳平衡。每个CA 600包括线缓冲器,以与单个存储器访问并行地获取多达预定数量(例如,12个)的特征映射数据字。
在每个CA(600)中,基于寄存器的内核缓冲器提供多个读取端口(例如,36),而多个定点乘法累加(MAC)单元(例如,36个16比特的MAC单元)在每个时钟周期执行多个MAC操作(例如,每个时钟周期多达36个操作)。加法器树对每个内核列的MAC结果进行累加。MAC操作的叠加的、基于列的计算允许针对多个MAC的特征映射数据的可接受的最佳复用,从而降低与冗余存储器访问相关联的功耗。
内核集合被分区为顺序处理的批次,并且中间结果可以被存储在SoC全局存储器126中。各种内核大小(例如,多达12×12)、各种批次大小(例如,多达16个)以及并行内核(例如,多达4个)可以由单个CA 600实例来处理,但是可以使用累加器输入来容纳任何大小的内核。
可配置的批次大小和可变数量的并行内核使得能够对跨越不同单元和可用计算逻辑资源共享的可用输入和输出带宽进行可接受的最佳权衡。
针对每个DCNN层确定CAF 400中的CA 600的不同的可接受的最佳配置。可以使用以DCNN描述格式(例如,Caffe'或TensorFlow)开始的整体性工具来确定或调整这些配置。当内核以每个权重8比特或更少比特被非线性量化时,CA 600支持即时内核解压缩和舍入,其中对于8比特,top-1误差率增加上至0.3%。
图4A是可配置的加速器框架(CAF)400(例如,图3的图像和深度卷积神经网络(DCNN)协处理器子系统400)的一个实施例。CAF 400可以被配置用于图像处理、音频处理、预测分析(例如,技能游戏、营销数据、人群行为预测、天气分析和预测、遗传作图、疾病诊断以及其他科学、商业的这样的处理)或一些其他类型的处理;特别是包括卷积操作的处理。CAF 400包括串流开关500,串流开关500提供设计时间参数化的、运行时可重新配置的加速器互连框架以支持基于数据流的处理链。
当集成已知的硬件数据路径加速器时,发明人已经认识到,系统设计者必须经常在紧密耦合或松散耦合的架构之间进行选择。基于该选择,将需要部署在这种设备(例如,片上系统)中的特定可编程元件(例如,处理器、DSP、可编程逻辑控制器(PLC)和其他可编程器件)中采用合适的但是限制性的编程模型。通常,可以通过传统上已经使用硬连线数据路径实现的半静态数据流图来支持与这些硬件块中的一些相关联的功能和特定处理任务。然而,这是不期望的并且是限制性的,因为硬连线数据路径在运行时即启用够提供灵活性,也只能提供很少的灵活性,相反,硬连线数据路径通常限于在系统设计期间预见的路径。
为了克服这些限制,如本公开所描述的,串流开关500的可重新配置的数据传递构造改进了逻辑块(IP)的复用、数据的复用和其他部件和逻辑的复用,这允许减小片上和片外存储器流量,并且提供更大的灵活性以在不同的应用使用情况下利用相同的逻辑块。集成在串流开关500中的是多个单向链路,多个单向链路被布置为经由可配置的完全连接的开关将数据串流传输到不同种类的数据宿、传输来自不同种类的数据源的数据串流以及将数据串流传输到不同种类的数据宿并且传输来自不同种类的数据源的数据串流,数据源和数据宿例如是直接存储器访问(DMA)控制器、I/O接口(例如,相机)和各种类型的加速器。
CAF 400可以被布置为具有若干可配置的模块。一些模块是可选的,一些模块是必需的。许多可选模块通常被包括在CAF 400的实施例中。CAF 400的一个必需模块是例如串流开关500。另一必需的模块例如是CAF控制寄存器402的集合。还可以需要其他模块。CAF 400的可选模块包括系统总线接口模块404、所选择的数量的DMA控制器406、所选择的数量的外部设备接口408、所选择的数量的处理模块410、以及所选择的数量的卷积加速器(CA)600。
串流开关500是形成有多个单向“串流链路”的单向互连结构。串流链路被布置为将多比特数据串流从加速器、接口和其他逻辑模块传输到串流开关500,并将多比特数据串流从串流开关500传输到加速器、接口和其他逻辑模块。所传输的数据可以采取任何期望的格式,例如,光栅扫描图像帧流、宏块定向图像流、音频流、原始数据块或任何其他格式。串流开关500还可以沿处理链传输消息、命令或其他类似的控制信息,由每个单元转发到处理控制信息的一个或多个目标单元。控制信息可以用于用信号传递事件,重新配置处理链本身,或引导其他操作。
在一些实施例中,CAF 400使用单个时钟域。在一些实施例中,CAF 400采用多个时钟域。例如,CAF 400中的某些块可以根据从CAF 400的主时钟导出的较慢时钟来操作。在CAF 400的特定模块以不同的时钟性质(例如,频率、相位等)操作的情况下,穿过时钟边界的每个串流链路可以配备有一个或多个专用或共享的再同步电路。可以利用异步先进先出(FIFO)寄存器、采样寄存器和其他部件来形成这样的再同步电路。
除了传输数据之外,或者在传输数据的备选方案中,每个串流链路也可以用于传递控制信息。控制信息可以包括开始标签、结束标签和其他控制信息,例如,用于基于光栅扫描的图像数据的线型信息。
继续描述图4A,除了串流开关500之外,CAF 400还可以包括系统总线接口模块404。系统总线接口模块404提供到SoC 110的其他模块的接口。如图3的示例性实施例所示,CAF 400被耦合到次级通信总线166。在其他情况下,CAF 400可以被耦合到主通信总线132或一些其他通信机构。控制信息可以单向或双向传递通过CAF 400的系统总线接口模块404。这样的接口被用于提供对所有CAF控制寄存器402的主机处理器(例如,DSP集群130的DSP、应用处理器128、或另一处理器)访问,CAF控制寄存器402被用于控制、操作或以其他方式引导框架的特定特征。在一些实施例中,每个DMA控制器406、外部设备接口408、处理模块410和卷积加速器600具有到配置网络的接口,配置网络具有配置寄存器的定义的集合(例如,在CAF控制寄存器402中形成)。
在一些情况下,CAF控制寄存器402包括被配置为控制CAF 400中的一个或多个模块的操作的其他结构。例如,可以包括中断控制器。中断控制器收集在加速器、DMA引擎和外部接口中生成的所有中断信号。专用配置寄存器用于定义将哪些中断转发到哪个外部处理器以进行进一步的动作。时钟和复位控制单元可以被配置和引导以分配、门控并最终划分主时钟信号。时钟和复位控制单元还可以将单独的时钟和复位信号转发到所选数量的卷积加速器600、DMA引擎406、系统总线接口模块404、处理模块410、外部设备接口408等。调试支持单元可以被配置为在CAF 400或SoC 110中收集探测信号。调试支持单元还可以被配置为提供连接到分析器单元的可配置数量的串流输入端口,并且提供事件计数器的集合来辅助系统调试。
在一些情况下,系统总线接口模块404也可执行仲裁任务。由于系统总线接口模块404提供CAF 400和SoC 110系统的其余部分之间的主数据连接,所以可以对从CAF 400传递出或传递到CAF 400的控制信息进行仲裁。仲裁可以遵循轮询方案、最近最少使用的方案、加权优先方案或一些其他方案。
CAF 400包括多个DMA控制器406。在图4A中,示出了16个DMA控制器406a至406p,但是根据半导体从业者在设计时做出的一个或多个选择,可以在SoC 110的其他实施例中包括一些其他数量的DMA引擎。
多个DMA引擎406可以经由总线端口链路或某些其他数据通信机构通信耦合到一个或多个总线仲裁器,一个或多个总线仲裁器被集成在系统总线接口模块404中,或以其他方式与系统总线接口模块404相关联。在一些情况下,系统总线接口模块404包括多个总线接口以改进带宽。在示例性实施例中,CAF 400具有集成在系统总线接口404中的至少两个仲裁器和至少两个总线接口。在这种情况下,仲裁器支持各种运行时可选择的仲裁方案(例如,轮询)以及使得能够可接受地最佳使用可用带宽的多个优先级。
DMA引擎406被布置成为输入数据流、输出数据流或输入和输出数据流提供双向通道。在这些情况下,大量的数据被传递到CAF 400中、从CAF 400传递出来、或传递到CAF 400中并从CAF 400传递出来。例如,在某些情况下,使用一个或多个DMA引擎406来传递来自存储器或来自数据源设备(例如,高清晰度(HD)视频相机)的流式视频数据,数据源设备产生大量视频数据。视频中的一些或全部可以从源设备传递进来,从SoC全局存储器126传递进来,或者传递到SoC全局存储器126,等。
每个DMA引擎406可以包括一个或多个输入缓冲器(未示出)、一个或多个输出缓冲器(未示出)、或输入和输出缓冲器二者。每个DMA引擎406可以包括打包逻辑(未示出),以用于打包数据、解包数据、或者打包数据并解包数据。每个DMA引擎406还可以包括定义的配置寄存器的集合,其引导源地址信息、目的地址信息、数量到传输信息、步幅、字节顺序、压缩等中的任何一个或多个。在一些情况下,配置寄存器被布置为支持DMA引擎406顺序传输所选择的数据量所使用的链表。
在一个示例性实施例中,一个或多个DMA引擎406利用一个输入端口504(图5)和一个输出串流端口516(图5)连接到串流开关500。DMA引擎406可以被配置为输入模式或输出模式。DMA引擎406可以被配置为将数据打包并发送到主通信总线132、次级通信总线166上可访问的任何地址位置或一些其他地址位置。DMA引擎406还可以附加地或备选地被配置为对所获取的数据进行解包并且将解包的数据转换成数据串流。
DMA引擎406可以被布置为支持各种打包特征、各种数据格式、多维度(例如,2D、3D等)寻址方案、数据子采样、任意比特宽度数据提取、链表控制和事件监控。从存储器中取回的数据和存储在存储器中的数据可以以任何所选择的比特宽度分别处理和存储,其中在每个数据值(例如,每个像素值)之间和之前/之后具有可配置的间隙。在一些实施例中,DMA引擎也是可配置的或以其他方式可操作的,使得每个线、每个宏块、每个帧或每个其他单元数量的数据可以在存储器中具有单独的偏移量。可以使用DMA引擎406来实现广泛的预获取和块传输,以可接受地优化所提供的总线带宽的延时和利用率。在一些实施例中,实现了链接的命令列表,并且这样的列表可以实现DMA引擎406的处理器独立的重新配置。在这些情况下,每个列表条目可以被编程或以其他方式布置为包含配置上下文,其被执行直到检测到某个可选择的事件,例如,帧的结束、N个帧的结束、接收到的CMD消息等。在这些链表的情况下,每个列表条目中的链接地址可以用于自主获取下一个上下文。
图4A的CAF 400包括设计时可选择的、运行时可配置的多个外部设备接口408。外部设备接口408提供到产生(即,源设备)或消耗(即,宿设备)数据的外部设备的连接。在一些情况下,通过外部设备接口408传递的数据包括流式数据。在一些情况下,可以预先确定通过外部设备接口408传递的流式数据的量。备选地,通过外部设备接口408传递的流式数据的量可以是不确定的,并且在这种情况下,不论何时启用和如此引导特定外部设备,外部设备都可以简单地产生或消耗数据。
在设计设备(例如,CAF 400、SoC 110或移动设备100)时,半导体从业者选择多个外部设备接口408。可以基于CAF 400的确定或预期的使用来选择外部设备接口408的数量、参数和特征。外部设备接口408可以被布置用于耦合(例如,物理耦合、电耦合、通信、控制、电源等中的一个或多个)。外部设备接口408可以被布置用于耦合到图像传感器、数字麦克风、显示监视器或其他源设备和宿设备。外部设备接口408管理或以其他方式处理与其他时钟域的同步。在某些情况下,外部设备接口408可以将内部数据串流转换成标准接口格式,例如,ITU-R BT.656(ITU656),反之亦然。各种类型的外部设备接口408符合并行相机接口协议(例如,ITU656)、串行相机接口协议(例如,CCIR2)、数字输出接口协议(例如,DVI)、多媒体协议、原始数据输入/输出接口协议以及任何其他所需的协议。可选数量(例如,二、四、八、十六)的设备接口408可以被自动地集成在CAF 400框架中。
图4A的CAF 400包括数字可视接口(DVI)外部设备接口408a、第一图像传感器接口和图像信号处理器(ISP)外部设备接口408b、以及第二图像传感器接口和ISP外部设备接口408c。还设想了其他接口,但是为了简化说明,仅示出了三个外部设备接口408。DVI外部设备接口408a被布置用于耦合到特定监视器(例如,基于液晶显示器(LCD)的监视器)的DVI端口。DVI外部设备接口408a可以包括配置逻辑(例如,寄存器、存储器、处理器、状态机等)、像素时钟和同步信号发生器电路、数据打包逻辑、以及单端口或双端口先进先出(FIFO)缓冲器中的一些或全部。像素时钟和同步信号发生器电路可以生成并传递单数据速率模式的时钟信号、双数据速率(DDR)模式的时钟信号。在某些情况下,DVI外部设备接口408a可以支持8/12/24比特RGB/YUV单或双数据速率接口。
第一和第二图像传感器接口和ISP外部设备接口408b、408c可以适合一个或多个视频数据协议,包括ITU-R BT.656-4YUV(YCbCr)4:2:2、RGB565、RGB444和RGB444zp。第一和第二图像传感器接口和ISP外部设备接口408b、408c可以包括配置逻辑(例如,寄存器、存储器、处理器、状态机等)、单端口或双端口FIFO缓冲器特征、数据解包逻辑、数据转换特征、颜色重采样特征以及其他特征中的一些或全部。
多个处理模块410被集成在CAF 400中。为了简单起见,示出了三个处理模块410,但是其他选定数量(例如,二、四、八、十六)的处理模块410也可以在设计时由半导体从业者集成在CAF 400中。可以选择处理模块410来对一个或多个类型的数据执行特定的处理特征。处理模块均可以包括在默认情况下、在启动时或在运行时可编程以引导相关联的处理模块410的操作的配置寄存器的确定的集合。第一处理模块410是被布置为执行某些视频(即,MPEG)处理以及某些图像(即,JPEG)处理的MPEG/JPEG处理模块410a。第二处理模块410是被布置为执行特定的视频编码/解码操作的H264处理模块410b。第三处理模块410是被布置为对某些多媒体数据执行基于颜色的操作的颜色转换器处理模块410n。
在许多情况下,DMA控制器406、外部设备接口408、处理模块410、卷积加速器600以及集成在CAF 400中的其他模块是在设计时由半导体从业者从库中选择的IP模块。半导体从业者可以指定模块的数量、特定模块的特征、总线宽度、功率参数、布局、存储器可用性、总线访问以及许多其他参数。
表2是可以并入CAF 400中的库中的IP模块的非穷尽示例性列表。在许多情况下,随着设计了新模块,以及随着修改了现有模块,新的IP将被添加到库(例如,表2的库)。
表2–IP模块的CAF库
在图4A中,示出了八个卷积加速器600,CA0至CA7。在其他CAF 400实施例中,形成不同数量的卷积加速器。卷积加速器600的数量和每个卷积加速器600中可用的特定特征在某些情况下基于由半导体从业者在设计时选择的参数值。
卷积加速器(CA)600是具有选定数量(例如,一个、两个、四个、八个)的输入和输出串流链接端口的数据处理单元。一个或多个配置寄存器(例如,配置寄存器集合)被布置为控制CA 600的操作。在某些情况下,配置寄存器被包括在CAF控制寄存器402中,并且在这些或其他情况下,某些配置寄存器被形成为CA 600的一部分。
一个或多个卷积加速器模板模块可以被包括在IP模块库中,例如,参考表2所描述的库。在这些情况下,存储在IP模块库中的数据包括相关的构造块,构造块减少构造实现加速器的核心功能的新的加速器所需的工作。可以扩展配置寄存器的预定义集合。形成在或以其他方式位于串流链路端口处的可配置的FIFO可用于吸收数据速率波动,并提供放松处理链中的某些流控制约束所需的一些缓冲余量。
通常,每个CA 600消耗数据,生成数据,或既消耗数据又生成数据。消耗的数据通过第一串流链路500传递,并且被流传输的数据传递通过第二串流链路500。在若干实施例中,CA不具有对由主通信总线132(图3)、次级通信总线166(图3)可访问的存储器地址空间或其他总线地址的直接访问。然而,如果需要对系统总线上传递的数据进行随机存储器访问,则CA 600还可以使用可选的总线端口接口,该总线端口接口可以沿图4A的系统总线接口模块404的线,系统总线接口模块404被用于若干事情,包括允许DMA引擎访问系统总线上的存储器位置。如上所述,一些CA 600实现是库的一部分,库可以在其他CAF 400实施例中使用,以简单地在全局系统定义文件中将CA 600实例化。
在一些情况下,CAF 400在设计时被配置有集中式配置文件。在集中式配置文件中,定义了所选数量和类型的加速器、接口、DMA引擎、互连和其他特征。集中式配置文件被布置为包含用于自动生成可综合的寄存器传输语言(RTL)代码、对应的用于验证的测试台、用于在一个或多个选定的CMOS和FPGA技术上运行逻辑综合的脚本、以及其他特征的相关信息。用于创建CAF 400的IP库可以针对每个加速器或接口包括相关联的RTL代码和配置脚本。还可以提供针对新的加速器和外部接口的参数模板,以简化用新单元对数据库的扩展。在集中式配置文件中定义新的CAF 400系统后,通过单个命令启动生成过程,并且生成用于逻辑综合和验证的所有RTL文件、测试台和实现脚本。
在例如在SoC 110中设计和制造CAF 400之后,CAF 400可以在运行时被配置和重新配置用于任何期望的操作。在一些情况下,CAF被布置用于多媒体处理(例如,流式视频、流式音频)、运动处理或其他类型的数据分析处理。
图4B是被配置用于简单对象检测的一个CAF 400实施例。在图4B的CAF 400实施例中,串流开关500被布置为允许在IP 410、外部流式设备接口408、卷积加速器600以及在CAF 400之外并且经由多个DMA控制器406通信耦合的各种其他部件之间的快速、功率有效的通信。
在图4B的实施例中,所示出的外部设备接口408包括多个图像传感器、至少一个图像串流处理器以及数字可视接口(DVI),但是可以预期其他外部设备接口408。另外,图4B的CAF实施例400图示了多个处理模块410,包括一个或多个颜色处理引擎、参考帧更新模块、背景/阴影去除器模块、多级变形滤波器(例如,4级)、特征检测(例如,FAST)模块以及图像裁剪器和缩放器/子采样器模块。当然可以预期包括但不限于表2中标识的那些模块的其他处理模块。
图4B中示出了六个DMA引擎406,但是在CAF 400中可以形成另一所选的数量。在这种情况下,为了简单起见,在针对简单对象检测使用CAF 400的示例性描述中示出了六个DMA引擎。图4B中还示出了一些数量的卷积加速器(CA)600,但是这些CA600以虚线示出,因为在该示例中它们未被使用。
示出了从接口420。从接口420可以遵循诸如I2C、SPI或USB的串行协议,或者从接口420可以符合一些其他专有或商业可用协议。在一些情况下,从接口420被用于询问、加载或以其他方式访问控制寄存器402。
控制寄存器402用于提供配置CAF 400及其部件以用于期望操作的控制变量。控制寄存器402可以具有默认值。可以在初始化期间、运行时期间或任何其他时间期间加载控制寄存器。
DMA引擎406可以被布置为在诸如图3所示的电路的其他电路之间传递数据。在这些情况下,通过系统总线接口模块404和次级通信总线166传递信息(例如,数据、控制变量等)。在其他情况下,DMA引擎406可以在CAF 400的两个或更多个模块之间在内部传递数据。
在图4B的CAF 400实施例中,例如通过存储在控制寄存器402中的值来配置各个串流链路502(图5)。图4B中经配置的串流链路502c-502m中的一些串流链路被布置为在两个设备之间直接传送数据。图4B中经配置的串流链路502c-502m中的其他串流链路被布置为将数据从一个设备多播到多个设备。在这些多播配置中,多个串流链路500(图5)被配置为针对每个输出设备使用一个串流链路来实现数据的多播复制。然而,为了便于理解,在图4B中,该多个串流链路被简单地示出为单个数据流线。
在图4B的CAF 400实施例中,一个或多个图像传感器被布置为将流式数据传递到串流开关500中。流式图像传感器数据经由串流链路502c多播到包括图像串流处理器的至少三个单独的设备。图像串流处理器可以被布置为提供Bayer传感器颜色滤波或一些其他处理。实施例中的流式图像数据也被复制并传递给参考帧更新模块和背景/阴影去除器模块。三个设备中的每一个对流式原始图像数据执行处理,并且三个设备中的每一个提供不同的经处理的图像数据。
图4B的实施例中的图像串流处理器处理原始图像数据串流并产生颜色滤波数据串流。颜色滤波数据串流经由串流链路502d多播。在一个串流链路502d中,颜色滤波数据串流通过CAF 400中的第一DMA引擎0被传递。在此,颜色滤波数据串流可以被存储在存储器中,在DSP中被处理,或者以其他方式被处理。在另一串流链路502d中,颜色滤波数据串流被传递到图像裁剪器和缩放器/子采样器模块,在此图像数据被进一步处理。
图像裁剪器和缩放器/子采样器模块产生经裁剪和子采样的图像数据串流,其经由单个串流链路502h传递到特征检测模块。特征检测模块可以被布置为遵循特定方法(例如,本领域技术人员已知的加速分割检测特征(FAST)方法)的角落检测模块。然后,被进一步处理的图像数据经由串流链路502e,通过第二DMA引擎1,通过系统总线接口模块404被传递到次级通信总线166,以用于在SoC 110(图3)的另一电路中进一步使用。
经由串流链路502c从图像传感器传递的原始图像数据在参考帧更新模块和背景/阴影去除器模块中被进一步处理。
在参考帧更新模块中,利用经颜色处理的数据(从一个或多个颜色处理模块经由串流链路502j传递)来进一步处理原始图像数据串流。来自参考帧更新模块的经处理的数据经由串流链路502l被反馈到一个或多个颜色处理模块。
同时,来自图像传感器的流式原始图像数据在背景/阴影去除器模块中被处理,背景/阴影去除器模块可以使用在串流链路502j上多播的经颜色处理的数据,以及较早的流式图像数据或从CAF 400外部取回并通过第五DMA引擎4和流链接502k传递的其他数据。来自颜色处理器的经颜色处理的数据也可以使用较早的流式图像数据或从CAF 400外部取回并在串流链路502m上经由第六DMA引擎5传递的一些其他数据来产生。
来自一个或多个颜色处理模块的数据输出在串流链路502g上经由第四DMA引擎从CAF 400多播出去。经颜色处理的数据可以被存储在例如存储器126(图3)中,或者在诸如DSP的SoC 110的另一电路中被处理。来自一个或多个颜色处理模块的数据输出也可以通过视频输出接口经由串流链路502g从CAF 400传递出去。这样的输出可以用于调试,用于标识特别检测到的特征,用于输出经处理的流式视频数据,或者用于其他原因。
返回到背景/阴影去除器模块,该模块可以进一步处理来自图像传感器的原始流式数据、经颜色处理的数据以及从CAF 400外部取回的其他数据,以产生特定的经背景/阴影处理的数据,其经由串流链路502i被传递到变形滤波器模块。可以具有多个级的变形滤波器处理所接收的数据,并且经由串流链路502f输出经变形的数据,经变形的数据传递通过第三DMA引擎2并从CAF 400传递出去。
图4C是串流开关500到次级通信总线166接口架构的实施例。所示的架构提供了涉及DMA引擎406和系统总线接口模块404的操作的进一步细节。N个DMA引擎406中的每一个包括双向传递数据和控制信息的电路,其中“N”是诸如8、16、32等的整数,或表示在CAF 400中形成的DMA引擎的数量的一些其他整数。图4C的DMA引擎406被示出为具有相关联的打包逻辑、解包逻辑和特定缓冲器。可以认识到,打包逻辑、解包逻辑和缓冲器可以与每个DMA引擎物理集成,并且还应当理解,可以以其他方式形成这样的结构。例如,在一些情况下,专用于每个DMA引擎406的缓冲器可以形成在一个或多个共同定位的(commonly located)存储器阵列中。
接口架构的操作可以由特定配置寄存器402来控制。控制寄存器402可以在初始化期间、运行时期间以及在CAF 400的其他操作期间被加载、清除、询问或以其他方式使用。
如图4C所示,每个DMA引擎406可以被耦合到串流开关500。DMA引擎406可以将数据提供到串流开关500中,从而被耦合到串流开关500的输入端口。DMA引擎406可以是单独地或并发地被布置为从串流开关500吸收数据,从而被耦合到串流开关500的输出端口。
DMA引擎406的输入路径中的每一个以及输出路径中的每一个可以具有内联缓冲器。在一些情况下,一个或多个缓冲器被布置为先进先出缓冲器。在一些情况下,一个或多个缓冲器被布置为双端口存储器,并且在其他情况下,以不同的布置访问缓冲器。
一个或多个缓冲器的大小可以在设计时被固定。在其他情况下,例如通过配置一个或多个特定控制寄存器402,在运行时确定一个或多个缓冲器的大小。在一些情况下,将确定的存储量分配为缓冲器空间,并且在运行时分配所确定的量。在这些情况下,可以将各个缓冲器布置为具有不同的大小,并且所分配的缓冲器空间的总量不可以超过被分配为缓冲器空间的确定的存储量。在操作中,缓冲器可以被用于更平滑地操作由特定DMA引擎406通信耦合的电路并避免停止运行。
每个DMA引擎406可以包括相关联的打包逻辑和相关联的解包逻辑。打包和解包逻辑的操作可以由某些控制寄存器402来引导。从串流开关500传递出的数据可以是未经压缩的流式数据。为了更有效地使用SoC 110资源,DMA引擎406可以对从串流开关500传递出的数据进行打包。可以根据固定的打包方案、动态或其他可变的打包方案或其他一些方案来进行打包。
沿着从串流开关500传递出的数据线,从CAF 400外部传递进入串流开关500的数据可以被打包或以其他方式被压缩。通过减少在次级通信总线166上传递的数据的大小,通过减少存储数据所需的存储器的数量,通过使用较少的功率来存储和取回来自存储器的打包数据以及以其他方式,这样的打包更有效地利用SoC 110资源。当从次级通信总线166取回经打包的数据时,解包逻辑在将数据传递到串流开关500的串流链路502之前对数据进行解压缩或以其他方式对数据进行解包。
系统总线接口模块404可以包括将来自多个DMA引擎406的数据协作地传递到次级通信总线166(反之亦然)的切换逻辑。公平的总线仲裁逻辑可以引导系统总线接口模块404的操作。在一些情况下,仲裁逻辑的操作可以由控制寄存器402中的某一个来引导。例如,传递通过某些DMA引擎406的数据可以优先,可以具有相关联的服务质量(QoS)指示符,或者可以以由仲裁逻辑用于确定哪些数据传递通过系统总线接口模块404的其他方式被指定。
图5A是更详细的串流开关实施例500。串流开关500包括用户可选择的、设计时可配置的第一数量的串流链路输入端口504以及用户可选择的、设计时可配置的第二数量的串流链路输出端口516。在一些情况下,存在相同数量的输入端口和输出端口。在其他一些情况下,输入端口比输出端口多,并且在其他另外一些情况下,输出端口比输入端口多。输入端口数量和输出端口数量在设计时被定义。
在运行时,串流开关500根据写入某些CAF控制寄存器402(图4)中的配置数据,将输入串流链路端口通信耦合到输出串流链路端口。在该实施例中,期望一个或多个输入串流链路端口可以被布置为在相同的时钟周期上,将所接收的数据串流并发地转发到一个或多个(多播)输出端口。因此,一个输入串流链路端口可以通信耦合(例如,电连接以用于数据传递)到一个或多个输出串流链路接口,这导致对输入数据串流的物理复制。
在一些CAF 400实施例中,串流链路的导体如表3和表4中所指示进行布置。在一些情况下,一个或多个串流链路的特定配置由某些CAF控制寄存器402中的值来引导。
表3–示例性串流链路的布局
表4–在示例性串流链路上传递的数据类型
表3示出了示例性串流链路实施例的物理布局和定义。如表3中特别指示的,串流链路提供了直接的、单向的接口,以传输数据串流和与数据串流相关联的控制信息。在这样的实施例中,单个控制信号(在某些情况下可以在单个专用或共享数据路径上传播)提供流控制。串流链路的一些导体被用于传递数据(例如,data0、data1、data2);一些其他导体包括数据有效性指示符、第一像素指示符、最后像素指示符、线类型定义以及停止运行信号。停止运行信号用作如本文所述的背压(例如,流控制)机制。在表3的串流链路实施例中,通过串流开关500沿处理链在基于帧的协议中传递图像数据、命令数据、控制信息、消息等。
表4示出了各种线类型定义的示例性实施例。
在图5A的串流开关500的实施例中,详细示出了一个串流链路502的实施例。为了简单地进行图示,在没有细节的情况下,还示出了其他串流链路502a、502b。通常沿串流链路502的线来布置串流链路502a、502b,并且为了本公开清楚起见,所示的串流链路中的任一个可以被标识为串流链路502。
在串流开关500中,每个输出端口516与特定串流链路502相关联。在图5A中,例如,输出端口X与串流链路502相关联。此外,一个或多个输入端口504与每个串流链路相关联。在一些情况下,例如,每个输入端口504与每个串流链路相关联。以这种方式,每个输入端口504可以在同一时间或不同时间将数据传递到任何所有的输出端口516。
串流链路的个体通信路径管道是单向的。即,每个通信路径管道上的信号仅在一个方向上流动。在一些情况下,多个通信路径管道单向地接受从输入端口接收的数据,并将数据传递到一个或多个输出端口。在这些情况下,以及在其他情况下,单个通信路径管道从输出端口单向地接收命令信息(例如,流控制信息),并将命令信息传递到一个或多个输入端口。在一些其他情况下,在两个或更多个通信路径管道上传递从输出端口接收并传递到一个或多个输入端口的命令信息。
在图5A的串流开关500的实施例中,根据半导体从业者的一个或多个设计时的决策,已经在串流开关500中形成了选定数量(例如,四个、八个、十六个等)的输入端口504。四个输入端口504被示出并标识为输入端口A、输入端口B、输入端口C和输入端口D,但也可以形成一些其他数量的输入端口504。第一输入端口A包括确定数量的单向通信路径管道NA,其中确定数量可以是16、32、40、64或一些其他整数。沿着这样的思路,输入端口B、C、D分别包括相同或不同的确定数量的单向通信路径管道NB、NC、ND。在一些情况下,NA=NB=NC=ND。在其他情况下,不同的输入端口可以具有不同数量的单向通信路径管道。
在一些情况下,一个或多个输入端口还可以包括同步机构(未示出)。同步机构可以包括寄存器、小型缓冲器、一个或多个触发器或一些其他同步机构。同步机构可以用于协调数据从源设备或到宿设备的传递,源设备和宿设备根据不同时钟信号(例如,不同频率、不同相位等)操作。
如在图5A的更详细的串流链路502中所示,来自多个输入端口504的单向通信路径管道的集合被传递到数据开关506中。在一些情况下,来自每个输入端口504的单向通信路径管道的集合被传递到数据开关506中。在其他情况下,(一个或多个,但不是全部)输入端口504的单向通信路径管道被传递到特定串流链路502的数据开关506中。数据开关506可以包括多路复用器逻辑、解复用器逻辑或一些其他形式的切换逻辑。
如图5A所示,从多个输入端口504传递到串流链路502中的数据可以并发地存在于数据开关506的输入节点处。选择机构508被布置为确定哪个输入数据传递通过数据开关506。即,基于选择机构508,来自输入端口A、B、C、D中的一个的输入数据通过数据开关506被传递到数据开关506的输出。输出数据将在NA...D单向通信路径管道上传递,其将与所选择的输入端口的单向通信路径管道的数量匹配。
根据串流开关配置逻辑510来引导选择机构508。串流开关配置逻辑510在运行时确定哪个输入端口504将向相关联的输出端口提供数据,并且基于该确定,串流开关配置逻辑510形成被传递到数据开关506的适当的选择信号。串流开关配置逻辑510在运行时实时操作。串流开关510可以获得来自CAF控制寄存器的引导、来自DSP集群122(图3)的DSP的引导、来自应用处理器128的引导、或来自其他一些控制设备的引导。此外,串流开关配置逻辑510还可以获得来自消息/命令逻辑512的引导。
在一些串流开关500的实施例中,例如由接口或加速器通过输入端口504传递的某些特定消息由串流开关500的一个或多个串流链路502中的命令逻辑512识别,并用于对一个或多个串流链路502进行实时重新编程。在这些或在其他实施例中,串流开关500被配置为根据固定模式合并数据串流。例如,在至少一种情况下,串流开关500可以被布置为通过在两个或更多个输入端口504上传递的输入串流之间进行切换来选择输出端口516并传递数据到输出端口516。例如,在每一线、每个帧、每N个事务之后,或者通过一些其他措施,串流开关500可以被配置为将数据从不同的输入端口504传递到所选择的输出端口516。
消息/命令逻辑512被布置为监视在一个或多个输入端口的一个或多个单向通信路径管道上传递的一个或多个比特。消息/命令逻辑512可以例如检测从输入数据源传递的命令。这样的命令可以遵循由表3和表4所指示的某些示例性通信。基于所检测的消息或命令,消息/命令逻辑512被布置为向串流开关配置逻辑510提供方向或特定可操作的信息。
在一个实施例中,例如,第一数据输入源被耦合到输入端口A,并且第二数据输入源被耦合到输入端口B。配置逻辑可以引导数据开关506将来自输入端口A的数据传递到输出端口X。在这种情况下,第一输入源可以将消息嵌入在流传输数据的线中,该数据由消息/命令逻辑512检测。所检测的消息可以引导串流开关配置逻辑510来改变选择机构508,使得来自输入端口B的数据被传递到输出端口X。随后,第二输入源可以将消息嵌入在流传输数据的线中,该数据由消息/命令逻辑512识别,以迫使返回选择机构508来将数据从输入端口A引导到输出端口X。当然也可以考虑其他模式、命令、方向等。以这种方式,使用通过串流链路502传递的命令或消息、经由CAF控制寄存器402(图4)传递的消息、或以另一种方式从另一设备(例如,DSP、应用处理器等)传递的消息,串流开关500可以实时重新编程一个或多个串流链路502。可以根据固定模式、动态模式、学习到的模式或通过某种其他引导来合并数据串流。
从数据开关506传递的数据在某些情况下可以通过一个或多个可选的输出同步逻辑级514传递。输出同步逻辑级514可以被用于存储或以其他方式缓冲从耦合到输入端口504的数据源传递到耦合到输出端口516的数据宿设备的选定量(例如,一个或多个比特、少数或多个字节等)的数据。这样的缓冲、同步和其他这样的操作可以在数据源设备和数据宿设备以不同的速率、不同相位、使用不同的时钟源或以可以彼此异步的其他方式进行操作时实现。
串流开关500包括用于将流控制信息从宿设备传递到源设备的背压停止运行信号机构。从宿设备传递流控制信息,以通知数据串流源设备降低其数据速率。降低数据速率将有助于避免宿设备中的数据溢出。
背压停止运行信号机构的一部分包括被包括在每个输入端口中的背压停止运行信号路径。背压停止运行信号路径被布置作为背压单向通信路径管道。在图5A中,四个背压输入端口机构被示出,BPA、BPB、BPC、BPD;针对所示出的输入端口中的每一个各自有一个背压输入端口机构。在其他实施例中,每个输入端口的背压机构可以包括一个或多个单向通信路径管道。在一些实施例中,每个输入端口的背压机构具有相同数量的单向通信路径管道,其可以是例如单个管道。在这些情况下,例如,当耦合到特定输入端口的数据源设备检测到背压机构上的信号被断言时,特定数据源设备将减慢或停止被传递到相关联的输入端口的数据量。
每个输出端口516包括背压机构的另一部分。示出了针对图5A的三个所示的输出端口X、Y、Z中的每一个的一个输出端口背压机构,BPX、BPY、BPZ。在一些情况下,每个输出端口背压机构包括相同数量的单向通信路径管道(例如,一个)。在其他情况下,至少一个输出端口具有与另一输出端口的另一背压机构不同数量的单向通信路径管道的背压机构。
输出端口背压机构管道在每个串流链路502中被传递到组合背压逻辑518。在图5A中,背压逻辑518接收背压控制信号BPX、BPY、BPZ。组合背压逻辑518还从串流开关配置逻辑510接收控制信息。组合背压逻辑518被布置为将相关的流控制信息通过输入端口504的输入端口背压机构传递回特定的数据源设备。
在串流开关500的背压机构的一个示例性使用中,数据源设备(未示出)被耦合到数据输入A。第一串流开关502被布置为将数据从输入端口A传递到输出端口X。同时,第二串流链路502a被布置成将数据从输入端口A传递到输出端口Y。如果被耦合到输出端口X的第一数据接收设备(未示出)被压倒,则第一输出端口X可以断言在BPX上的流控制信号。被断言的流控制信号被传递回组合背压逻辑518,并且由于串流开关配置逻辑510将数据从输入端口A传送到输出端口X,所以组合背压逻辑518被允许将BPX上的流控制信号传递到输入端口A,这将引导第一数据源减慢或停止其数据流。如果被耦合到输出端口Y的第二数据宿设备(未示出)存在丢失数据的风险,则也可能发生类似的过程。相反,由于被耦合到输入端口A的第一数据源设备(未示出)没有将数据传递到输出端口Z,所以在BPZ上的控制信号上断言的流控制信号将不会向回传递通过输入端口A。
图5B是示出串流开关500实施例的示例性使用的操作。在操作的第一部分中,用户期望使用流式特征数据和某些内核数据执行卷积操作。在这种情况下,在移动设备100(图3)中执行操作,其中SoC 110(图3)被嵌入在移动设备中。SoC 110包括可配置的加速器框架400,在加速器框架400中集成串流开关500。为了执行卷积操作,用户使得所选择的值被加载到多个配置寄存器402(图4)中。
用户确定串流开关500的第一串流链路502n和第二串流链路502o将用于使特征数据和内核数据传递到所选择的卷积加速器600C。第三串流链路将被用于传递来自卷积加速器600C的输出数据。通过使得特定控制寄存器402被加载具有特定值,串流开关500的串流链路在运行时可重新配置并实时可重新配置。
为了开始这一部分操作,用户加载配置寄存器402,以经由串流链路502n将第一串流开关输出端口(1-OUT)可重新配置地耦合到第一串流开关输入端口(1-IN)。然后,配置寄存器402被加载,以经由串流链路502o将第二串流开关输出端口(2-OUT)可重新配置地耦合到第二串流开关输入端口(2-IN),并且寄存器402被加载,以经由串流链路502p,将第三串流开关输出端口(3-OUT)可重新配置地耦合到第三串流开关输入端口(3-IN)。
一旦串流链路502n、502o和502p被配置,特征数据源设备(例如,图像传感器)被耦合到第一输入端口(1-IN),并且内核数据源设备(例如,存储器设备)被耦合到第二输入端口(2-IN)。然后,通过第一串流开关输入端口(1-IN),特征数据被传递到第一串流开关输出端口(1-OUT)并被传递到卷积加速器600C中,并且通过第二串流开关输入端口(2-IN),内核数据被传递到第二串流开关输出端口(2-OUT)并被传递到卷积加速器600C中。
卷积加速器600C使用流式特征数据的至少一部分和流式内核数据的至少一部分来执行卷积操作。通过第三串流开关输入端口(3-IN),然后朝向第三串流开关输出端口(3-OUT)传递卷积加速器输出数据。在一些情况下,卷积加速器输出数据被存储在存储器中。在一些情况下,卷积加速器输出数据被进一步处理。
用户然后期望在另一卷积加速器操作中重新使用卷积加速器输出数据。在一些情况下,通过使得不同的或附加的值被存储在配置寄存器402中,用户重新配置串流开关500。在另一情况下,根据经由串流开关输入端口中的一个传递到串流开关500中的一个或多个控制消息来重新配置串流开关500。因此,嵌入在流式数据或被传递到串流开关500中的其他输入数据中的控制信息可以被解释为控制命令。
在这种情况下,用户经由串流链路502q使得第四串流开关输出端口(4-OUT)与第一串流开关输入端口(1-IN)可重新配置地耦合。以这种方式,在没有任何开销或时间代价的情况下,传递到第一串流开关输入端口(1-IN)中的特征数据将被多播(即,复制)到第一卷积加速器600C和第二卷积加速器600D。用户经由串流链路502r引起第五串流开关输出端口(5-OUT)与第二串流开关输入端口(2-IN)第二可重新配置的耦合,以将内核数据多播到第二卷积加速器600D。用户还经由串流链路502s,引起第六串流开关输出端口(6-OUT)与第三串流开关输入端口(3-IN)可重新配置的耦合,并经由串流链路502t,引起第七串流开关输出端口(7-OUT)与第四串流开关输入端口(4-IN)可重新配置的耦合。通过将第六串流开关输出端口(6-OUT)耦合到第三串流开关输入端口(3-IN),第二卷积加速器600D将从第一卷积加速器600C接收中间卷积输出数据。
一旦如本文所述地加载配置寄存器,则使用流式特征数据的一部分、流式内核数据的一部分和第一卷积加速器输出数据的一部分来执行第二卷积操作。通过第四串流开关输入端口(4-IN),朝向第七串流开关输出端口(7-OUT)(其中可以存储或以其他方式复用来自第二卷积加速器600D的输出数据)传递来自第二卷积加速器600D的输出数据。
图6包括图6A-图6D。
图6A是第一卷积加速器(CA)实施例600A。CA 600A可以被实现为图4的卷积加速器600中的任何一个或多个。
CA 600A包括各自被布置为耦合到串流开关500(图5)的三个输入数据接口和一个输出数据接口。第一CA输入数据接口602被布置用于耦合到第一串流开关输出端口516,第二CA输入数据接口604被布置用于耦合到第二串流开关输出端口516,并且第三CA输入数据接口606被布置用于耦合到第三串流开关输出端口516。CA输出数据接口608被布置用于耦合到所选择的串流开关输入端口504。每个CA输入数据接口602、604、606和输出数据接口608被耦合到的特定串流开关500可以在默认情况下、在启动时或在运行时被确定,并且可以在运行时以编程方式改变特定耦合。
在一个示例性实施例中,第一CA输入数据端口602被布置为将批次数据串流传递到CA 600A中,第二CA输入数据端口604被布置为将内核数据串流传递到CA 600A中,并且第三CA输入数据端口606被布置为将特征数据串流传递到CA 600A中。输出数据端口608被布置为传递来自CA 600A的输出数据串流。
CA 600A包括若干内部存储器缓冲器。在一些实施例中,内部存储器缓冲器可以共享公共存储器空间。在其他实施例中,内部存储器缓冲器中的一些或全部可以彼此分开并不同。内部存储器缓冲器可以被形成为寄存器、触发器、静态或动态随机存取存储器(SRAM或DRAM)或处于其他一些结构配置中。在一些情况下,可以使用多端口架构来形成内部存储器缓冲器,多端口架构允许例如一个设备在存储器中执行数据“存储”操作,而另一设备在存储器中执行数据“读取”操作。
第一CA内部缓冲器610物理地或虚拟地被布置为与第一CA输入数据接口602连线。以这种方式,被流传输到CA 600A中的批次数据可以被自动存储在第一CA内部缓冲器610中,直到数据被传递到CA 600A中的特定数学单元(例如,加法器树622)。第一CA内部缓冲器610可以以在设计时确定的尺寸被固定。备选地,可以使用在启动时或运行时以编程方式确定的可变大小来定义第一CA内部缓冲器610。第一CA内部缓冲器610可以是64字节、128字节、256字节或一些其他大小。
沿第一CA内部缓冲器610的线形成第二CA内部缓冲器612和第三CA内部缓冲器614。即,第二和第三CA内部缓冲器612、614可以各自具有在设计时确定的其自己的固定大小。备选地,第二和第三CA内部缓冲器612、614可以具有在启动时或运行时以编程方式确定的可变大小。第二和第三CA内部缓冲器612、614可以是64字节、128字节、256字节或一些其他大小。第二CA内部缓冲器612物理地或虚拟地被布置为与第二CA输入数据接口604连线,以自动存储流传输的内核数据,直到内核数据被传递到专用于存储内核缓冲器数据的专用第四CA内部缓冲器616。第三CA内部缓冲器614物理地或虚拟地被布置为与加法器树622连线,以自动存储经求和的数据,直到其可以传递通过CA输出接口604。
第四CA内部缓冲器616是专用缓冲器,该专用缓冲器被布置为期望存储内核数据并将所存储的内核数据应用于多个CA乘法累加(MAC)单元620。
第五CA内部缓冲器618是特征线缓冲器,特征线缓冲器被布置为接收通过第三CA输入接口606传递的流传输的特征数据。一旦存储在特征线缓冲器中,特征数据被应用于多个CA MAC单元620。应用于CA MAC单元620的特征和内核缓冲器数据根据本文描述的卷积操作而被数学地组合,并且来自CA MAC单元620的所产生的输出乘积被传递到CA加法器树622。CA加法器树622数学地组合(例如,求和)传入MAC单元数据和通过第一CA输入数据端口传递的批次数据。
在一些情况下,CA 600A还包括可选的CA总线端口接口624。当CA总线端口接口624被包括在内时,CA总线端口接口624可以用于将数据从SoC全局存储器126或其他一些位置传递到CA 600A中,或者从CA 600A传递出数据。在某些情况下,应用处理器128、DSP集群122的DSP或一些其他处理器引导向CA 600A或从CA 600A传递数据、命令或其他信息。在这些情况下,数据可以通过CA总线端口接口624被传递,CA总线端口接口624本身可以被耦合到主通信总线132、次级通信总线166或一些其他通信结构。
在某些情况下,CA 600A还可以包括CA配置逻辑626。CA配置逻辑626可以完全驻留在CA 600A内,部分驻留在CA 600A内,或者远离CA 600A。例如,可以完全或部分地在CAF控制寄存器402、SoC控制器120或者SoC 110的一些其他结构中体现配置逻辑600A。
图6B是另一卷积加速器(CA)实施例600B。CA 600B可以被实现为图4的卷积加速器600中的任何一个或多个。图4的卷积加速器600B沿CA 600A(图6A)的思路被组织在具有不同细节的图示中。在一些情况下,为了简单起见,在图6B的CA 600B中,图6A的CA600A的某些特征被不同地示出或未被示出。在图6A和图6B中示出相同的特征的情况下,使用相同的参考标识符。
图6C是图6B的第二CA 600B实施例的组织参数的集合。图6C中所示的参数呈现了表示CAF 400(图4)的能力的非穷尽性非限制性特征集合,CAF 400具有如本文关于图6所描述的一个或多个卷积加速器。
图6B的CA 600B被用于操作CA 600B的示例性描述方法。为了简化讨论,CA 600A和CA 600B被单独和统称为CA 600。
CA 600被配置为自主地执行诸如AlexNet的卷积神经网络的整个层的卷积。为了实现该配置,CA 600被布置为利用CAF 400中可用的实质并行性。
卷积神经网络中的处理使用了至少部分由SoC全局存储器126提供的巨大数据带宽。尽管快速的片上存储器可用,但是这种存储器的大带宽和占用空间要求使得希望减少对SoC全局存储器126的访问次数以及存储在SoC全局存储器126中的神经网络数据量。减少所存储的数据量和对SoC全局存储器126的访问频率的另一个原因是SoC全局存储器126在多个设备之间共享。例如,在CAF 400正在访问SoC全局存储器126的同时,不期望减慢由SoC 110的应用处理器128正在执行的应用。此外,还不期望使神经网络缺乏数据,以由应用处理器128提供对SoC全局存储器126的优先访问。此外,SoC全局存储器126的严格存储器访问要求不一定有助于被布置为处理各种内核维度和各种特征维度的灵活卷积加速器600。另外,当对SoC全局存储器126的访问减少时,也希望相应地减少功耗。
输入到卷积神经网络的一些数据被称为特征数据。特征数据在许多情况下由两个或更多个通道的二维数据结构组成。在执行图像识别的一些神经网络中,例如,特征数据包括图像帧和相关联的图像帧的像素数据。在这些情况中的一些情况下,使用三个通道的图像帧数据,并且三个通道中的每一个表示红-绿-蓝(RGB)颜色空间的不同颜色。
在一些实施例中,内核是从神经网络的训练得到的。内核可以具有任何两个维度,但在某些情况下,内核数据可以具有3像素×3像素(3×3)至11像素×11像素(11×11)的范围内的维度。在这些情况下,内核深度通常与待处理的特征数据集的通道数相同。
特征数据和内核数据可以使用所选择的数字表示(例如,定点数、浮点数或一些其他约定)。特征数据和内核数据可以使用任何可接受的精度水平。在许多但并非所有嵌入式应用中,不选择浮点数系统,因为使用浮点数系统的计算过于计算昂贵。在某些情况下,使用例如对于内核数据和特征数据具有16比特精度或更低精度的定点数系统提供了在神经网络的硬件复杂度和精度降级之间的合理平衡。在又一些其他情况下,可以使用修改的定点计算来部署浮点数系统。
为了处理卷积层的内核,在第一位置(例如,右上角、左上角或某个其他位置)处的输入特征的每个值(即,每个像素)与内核的每个对应值相乘,并将乘积相加以生成一个输出结果。输出结果立即或稍后被传递到一个或多个后续任务(例如,最大池化和非线性激活)的输入。相对于图6B和图6C,来自第五CA内部缓冲器618(例如,特征线缓冲器)的输入特征值和来自第四CA内部缓冲器616(例如,内核缓冲器)的内核值在CA MAC单元620中被相乘和累加,并且乘积被传递到CA加法器树622的求和逻辑。针对每个像素,在水平方向和垂直方向上重复MAC处理,以生成一个内核的输出。
当内核在水平和垂直方向(例如,图1F、图1G)中遍历特征像素时,内核在水平方向、垂直方向或水平和垂直方向上前进选定量的位移。水平和垂直位移由CA 600实现的神经网络的设计者来选择。位移,也被称为“步幅”,在水平方向、垂直方向或水平和垂直方向上可以处于一个像素和几个像素之间。在某些情况下,还会向输入特征数据添加填充行、填充列或填充行和填充列。CA 600的图6A的配置逻辑626(例如,图6B的内核缓冲器控制逻辑626a)可以通过加载特定的寄存器值来配置,使得实现期望的步幅、填充等。
考虑沿AlexNet的思路的神经网络,在对卷积输出数据执行最大池化和非线性激活操作之后,生成用于下一层的特征输入数据。在一些情况下,来自一个或多个卷积加速器600的特征输出数据通过串流开关500被传递回一个或多个其他卷积加速器600。这种类型的处理链允许数据被复用,从而可以避免至少一些无效的、功耗大的、时间延迟的存储器存储操作。
表5表示CAF 400中可配置的某些内核和特征维度,以实现沿AlexNet的思路的神经网络。
表5–示例性神经网络的内核和特征维度
CAF 400的可配置性允许每个CA 600在“正确”实例处及时接收“正确”数据值,使得并行执行大量的MAC操作。至少部分地,使用CA 600中的本地缓冲器610-618在数据需要被用于新的计算的新数据替换之前,针对可接受数量的操作来缓冲数据,使得该配置变得可能。如表5所示,特征数据和内核数据维度根据处理层、网络类型和其他原因而变化。基于这些以网络为中心的变量,具有在设计时被固定的处理能力的常规处理硬件不能被用于实现神经网络。相比之下,可以利用每个CA 600的灵活的缓冲能力(在某些情况下允许在维度上改变缓冲器)来扩大神经网络中的并行性水平。
在不可以在CA 600中针对所有层提供能够保持整个内核和特征大小的本地缓冲器的情况下,CAF 400还可以利用可配置的卷积加速器600来将特征和内核数据划分为批次,批次可以从一个网络层到下一个网络层不同。例如,一个特征或内核批次可以保持输入特征或内核的二维大小,但是批次可以将通道数除以整数。因此,例如,层3(表5)的特征数据可以除以16,这将为一个内核生成13×13×16像素的16个特征批次和3×3×16的16个内核批次。该数据划分的一个优点是可以在相应CA 600的缓冲器610-618中将重复操作的大的集合分配给具有合理大小的本地存储的批次。类似的方法可以用于批次大小为八(8)的层2a。当在层2a中使用为八(8)的批次大小时,CA 600将对具有27×27×8像素的六(6)个特征批次和具有5×5×8值的内核批次执行卷积操作。
为了完成批次计算,将内核的所有批次的结果相加,以确定整个内核的最终结果。即,对于每个批次计算,中间结果的集合被存储并与内核的下一批次的结果相加。在一些情况下,中间数据量被存储在本地缓冲器存储器(例如,第一CA内部缓冲器610)中。在一些情况下,中间数据通过串流开关500被传递到另一CA 600或另一累加器的输入。在一些其他情况下,中间数据量被确定为太大而无法存储在CAF 400中。在这些情况下,在批次操作的一个集合期间和之后,从CA 600将中间数据流传输到SoC全局存储器126,并且在随后的批次操作集合中,再次获取中间数据。在将中间数据传递回SoC全局存储器126的情况下,可以使用总线端口接口624、DMA控制器406或一些其他数据传输电路系统来传递中间数据。
当DMA控制器406传递特征和内核批次的数据串流时,DMA控制器可以在同一线中开始下一像素数据的传输之前,首先传输该批次中针对一个像素的所有通道值。在线末尾,DMA控制器406可以在下一线的开头重新启动该过程,直到传输整个内核批次。该过程可以被看作是将批次大小为N的X像素×Y像素(X×Y)的特征变换为具有Y个线的特征,并且每个线具有X像素×N像素(X×N),步幅为N且批次大小为1。具有H像素×V像素(H×V)的维度的对应内核可以被平移为具有V个线的内核,其中每个线具有H值×N值(H×N),每个线具有N个像素的步幅。例如,3×3批次大小8可以被平移到步幅为8的24×3的批次。
如上所述平移和处理内核或特征批次提供了有价值的优点。例如,配置CA 600以这种方式平移数据和处理经平移的数据允许集群中的选定数量N的MAC单元620在每个周期产生一个输出值,只要内核的水平维度H除以水平步幅小于或等于所选择的数量N。在沿AlexNet层1的线的神经网络中,例如,其中H=11并且步幅=4,则H/步幅≤3。因此,每个集群三(3)个MAC 620足以处理该内核。在各自具有三(3)个MAC单元的十二个(12)集群的CA 600的实现中,十二(12)个集群配置覆盖由CA 600支持的内核的最大水平维度。在这种情况下,当等式(H/步幅≤3)成立时,在不具有任何停止运行的情况下,三(3)个MAC单元足以处理内核的水平维度,这是表5中层1、3、4、5的情况。
然而,在其他情况下,为了能够处理比例大于三(3)的内核,例如,CA 600可以被配置为将选定数量N的两个或更多个MAC集群620链接在一起,以在每个周期产生一个输出值。利用该配置,将内核的最大垂直维度V除以经链接的MAC集群的选定数量N。例如,在内核维度为5×5的情况下(其中步幅=1),则H/步幅≤3*N,12/N≥V)。因此,可以通过链接两个MAC集群来处理表5中的层2的5×5内核。在CAF 400中,当将同一内核的多个集群分配给相同的处理行时,可以自动应用该特征。
上述内核或特征批次平移和处理的另一个优点与传输中间批次数据所采用的带宽相关联。在这些情况下,针对中间批次和输出数据的带宽可以按照等于输入特征的水平步幅的因子减小。如前所述,水平步幅与被用于细分大内核的第三维度的批次大小相同。因此,批次大小N将中间批次和输出数据带宽除以N。因此,并行计算P个内核将中间批次和输出数据带宽乘以因子P。由于使用大批次尺寸消耗更多的本地缓冲器空间(其可能受限),因此针对该批次大小可以找到一种折中,以将可用缓冲器空间与将中间数据流传输到SoC全局存储器126所消耗的带宽进行平衡。
再次考虑图4、图6A-图6B的卷积加速器600,CA 600具有分别被布置用于耦合到串流开关500的串流链路502的三个CA输入接口602、604、606,以及被布置用于耦合到串流开关500的串流链路502的一个CA输出接口608。第一CA输入接口602被用于传递(例如,接收)同一内核的先前批次计算的中间结果;第二CA输入接口604被用于传递(例如,接收)内核数据;并且第三CA输入接口606被用于传递(例如,接收)特征数据。CA输出接口608被用于(例如,发送)具有批次计算结果传递的数据串流。批次计算结果将被再次获取以进行后续批次计算,或者在最后批次的情况下,批次计算结果将被用作整个内核计算的最终结果。
在一些实施例中,图4、图6A、图6B被布置为使用一个单个时钟域。在其他实施例中,两个或更多个时钟域可以被固定地或可配置地应用到一个或多个卷积加速器600。使用单个时钟域可以简化CA 600的设计。在一些情况下,SoC 110可以使用1GHz的时钟频率来操作。在使用28nm CMOS技术的SoC 110的实施例中,代表本发明人进行的时序分析已经验证了在示例性CAF 400中体现的示例性CA 600中的计算块可合理地实现1GHz的时钟速度。也可以设想更快和更慢的时钟速度。
可以根据一个或多个配置寄存器来引导每个CA 600中执行的处理。配置寄存器可以被体现在CA配置逻辑626、CAF控制寄存器402或与每个CA 600相关联的其他寄存器中。在一些实施例中,配置寄存器可以被主机处理器(例如,应用处理器128、DSP集群122的DSP、传递到串流开关500中并由消息/命令逻辑512处理的命令)或被一些其他电路系统访问和编程。配置寄存器可以定义CA 600的各种处理参数,例如,内核大小、并行处理的内核的数量、CA内部缓冲器610-618的配置(例如,大小、维度等)、输入和输出数据的移位、内核解压缩等参数。表6呈现了卷积加速器600的配置寄存器的示例性集合。
表6示出卷积加速器的配置寄存器
根据存储在配置寄存器中的值(例如,表6),CA 600将管理数据输入、数据输出、数据移位和结果归一化(例如,饱和、舍入等)。CA 600还将应用像素步幅、线步幅,并且CA 600将考虑利用附加的列、行或列和行的填充值。如果例如通过单个DMA控制器406向多个加速器提供数据,则CA 600可以可选地对内核批次进行滤波。CA 600可以可选地启用并执行内核解压缩。
根据特征数据的几何性质、内核大小和可用的MAC单元620,CA 600可以并行地处理多个内核。当卷积处理开始时,CA 600将接受足够量的特征数据线以及在开始处理之前执行卷积处理所需的内核。可以通过并行地运行两个或更多个CA MAC单元620逐列执行卷积处理。
图6D是示出了示例性卷积操作的框图。在框图中,对步幅为1(1)的3像素×3像素(3×3)内核进行卷积。执行以下动作。
在第一周期的线开始时,三个集群(即,三个第一MAC单元)中的每一个的第一CA MAC单元620对第一线的第一输出值执行第一列的计算。
在下一周期,第二列被每个集群的第一CA MAC单元620中的每一个CA MAC单元进行卷积。同时,三个集群(即,三个第二MAC单元)中的每一个的第二CA MAC单元620对第一线的第二输出值执行第一列的计算。
在第三时钟周期中,三个集群的每个第一CA MAC单元620针对第一输出值执行第三列计算,三个集群的每个第二CA MAC单元620针对第二个输出值执行第二列计算,并且三个集群的每个第三CA MAC单元620针对线的第三输出值执行第一列计算。
当在第四时钟周期处理3×3内核时,三个集群的每个第一CA MAC单元620在第四输入值处重新开始第一列计算以用于第四输出值,对于每个第二和第三CA MAC单位620依此类推。
图6D所示的计算顺序执行,使得在每个周期上,一个3×3像素的内核批次被卷积,这提供了从第五CA内部缓冲器618(例如,特征线缓冲器)获取的数据值的重要复用。图6D示出了对于每个计算的输出值如何使用对特征条缓冲器的单次访问来对四个3×3像素内核执行每个周期36个MAC操作。
更详细地考虑图6A、图6B的第五CA内部缓冲器618(例如,特征线缓冲器)。在一些实施例中,特征数据从SoC全局存储器126、通过DMA控制器406、通过串流开关500的串流链路502被传递到示例性CA 600的第三CA输入接口606。特征数据可以被包括作为图像帧,其中特征数据的每个线具有第一标签和最后标签,并且图像帧还在第一线上具有线标签,并且在最后线上具有线标签。
当在示例性CA 600的第三CA输入接口606处接收特征数据时,CA 600的配置逻辑626或其他逻辑检查并验证数据串流格式是正确的。因此,如果数据串流开始于起始帧(SOF)线标签和活动的第一信号,则CA 600确定其正在接收特征数据的新的帧的第一像素。备选地,如果数据串流不包括SOF线标签或活动的第一信号,则数据可以被标记为非法的,可以丢弃该数据或者可以执行其他处理。当检测到有效特征数据时,数据被逐线存储在第五CA内部缓冲器618(例如,特征条缓冲器)中。在现在描述的示例性情况下,第五CA内部缓冲器618特征条缓冲器存储多达12线的具有16比特宽的像素值的输入特征帧。在其他情况下,可以存储不同数量的线、不同的宽度或具有不同特性的特征数据。
第五CA内部缓冲器618特征线缓冲器提供对特征数据值的列的并发访问,在本示例中,该列具有多达12个特征数据值。当第五CA内部缓冲器618特征条缓冲器已满时,由第三CA输入接口606生成停止运行信号,停止运行信号被传播回附接的DMA控制器406。在这种情况下,由DMA控制器传递的数据流406可以被减慢、停止或以其他方式控制,直到停止运行信号被释放。
可以在设计时确定并且在运行时进一步配置第五CA内部缓冲器618特征条缓冲器的最大深度。在示例性CA 600实施例中,第五CA内部缓冲器618特征线缓冲器具有512个条目的上限深度。在某些情况下,这样的深度可以将应用于大内核(例如,大于六像素×6像素(6×6)的内核)的上限特征宽度限制到对应的数量。在该示例中,应用于大内核的上限特征宽度可以被限制到512个像素。在较小的内核(例如,小于或等于六像素×六像素(6×6)的内核)的情况下,可以增加上限特征宽度。在当前的示例中,针对较小内核的上限特征宽度可以加倍至1024个像素,并且对于具有小于或等于三像素×三像素(3×3)的大小的内核的特征,可以达到2048个像素的上限宽度。
物理的第五CA内部缓冲器618特征条缓冲器可以利用双端口存储器来实现。备选地,第五CA内部缓冲器618特征条缓冲器可以通过执行在交替周期中写入和读取的两个单端口存储器切割而利用单端口存储器来实现。以这种方式,单端口存储器可以作为具有并发读取和写入访问的“伪双端口存储器”来操作。第五CA内部缓冲器618特征条缓冲器的一个优点是:其配置允许多个(例如,12个或某个其他数量)特征数据值利用单个存储器访问而被加载,从而降低CA 600的总体功耗。
更详细地考虑图6A、图6B的第四CA内部缓冲器616(例如,内核缓冲器)。在一些实施例中,内核数据从SoC全局存储器126、通过DMA控制器406、通过串流开关500的串流链路502被传递到示例性CA 600的第二CA输入接口604。内核数据可以作为仅具有第一标签和最后标签的原始数据串流被传输。即,内核数据不形成为线数据,所以在传输内核数据时,没有线标签被嵌入到内核数据中。
当在示例性CA 600的第二CA输入接口604处接收内核数据时,CA 600的配置逻辑626或其他逻辑检查并验证数据串流格式(例如,第一/起始标签、最后/结束标签)是正确的。如果数据串流格式不正确(例如,检测到起始或结束标签丢失),则CA 600可以将数据标记为非法,可以丢弃数据,或者可以执行其他处理。备选地,如果数据串流被验证,则数据被转发到第四CA内部缓冲器616内核缓冲器。
在CA 600被配置为处理多个内核的实施例中,可以重复地接收和存储内核数据串流,直到所有内核批次都可用。在至少一个示例性实施例中,第四CA内部缓冲器616内核缓冲器被配置为存储高达576个16比特宽的内核值。在一些情况下,该非限制性示例性的大小可以对应于批次大小为16的四个3像素×3像素(3×3)内核批次。在其他情况下,第四CA内部缓冲器616内核缓冲器被布置为存储批次大小为一(1)的四个11像素×11像素(11×11)的内核、批次大小为4的两个5像素×5像素(5×5)的内核或一些其他配置。
至少一个示例性实施例中的第四CA内部缓冲器616内核缓冲器被划分为12行和48列。还可以设想其他配置。在示例性实施例中,第四CA内部缓冲器616内核缓冲器的每一行被连接到三(3)个CA MAC单元620的一个集群。这样的配置提供三(3)个读取端口来选择同一行上48个内核值的三(3)个寄存器。
在许多但不是全部的实施例中,每个内核寄存器不被连接到每个CA MAC单元620。在这些情况下,认识到,当实现这种全连接时,随着可以被选择的寄存器的数量的增加,复用器复杂度潜在地指数增长(例如,36×1:48可以是可管理的,而36×1:576可能太复杂)。
使用本文所描述的示例性配置,第四CA内部缓冲器616内核缓冲器在一些情况下可以包括复制值(例如,由于两个CA MAC单元620集群的链接,5像素×5像素(5×5)的内核)。然而,可能仍然期望该配置,因为它大大降低了提供36个16比特宽读取端口的第四CA内部缓冲器616内核缓冲器的硬件复杂度。
在一些实施例中,可以利用满足公式H*B<48的批次大小(B)并行处理多个小内核(例如,H像素×V像素(H×V))。在这些实施例中,并行处理的数量可能受内核缓冲器宽度、特征缓冲器宽度或内核缓冲器宽度和特征缓冲器宽度的限制。
在本文所描述的实施例中,在线交织时使用的内核被处理,并且用于预缓冲的内核可以以水平顺序被存储。内核批次的预缓冲可以有助于减少新批次计算启动时的设置时间。
在一些情况下,卷积加速器600将等待,直到所有内核被加载到第四CA内部缓冲器616内核缓冲器中,并且至少V-1个线和H个像素被加载到第五CA内部缓冲器618特征条缓冲器中。这里,“V”是内核的垂直维度。如果两个或更多个卷积加速器600从单个DMA控制器406接收内核数据,则内核加载可能比特征数据加载花费更多的时间。在这些情况下,如本文所述的内核预缓冲可以消除该问题,特别是如果足够的内核缓冲器空间被配置并且可用。
神经网络的内核数据可以占据大部分的片上存储器。增加片上存储器的大小增加了芯片的大小,并且对应地增加了功耗,这是不期望的。由于神经网络高效、实时的使用可能依赖于以非常高的带宽加载的内核数据,所以内核数据的片外存储也是不期望的。为了解决这些缺点,可以压缩内核数据,使得由内核数据解压缩引起的任何性能下降(例如,时间损失、数据丢失)都是可接受的。
一个有效的解压缩方法是对表中被压缩的值进行简单查找,其中被压缩的值被用作索引。在一个示例性实施例中,CA 600的配置逻辑626(例如,内核缓冲器控制626a)管理形成在缓冲器空间中的解压缩查找表或由CA 600可访问的其他存储器。在查找表包括256个16比特条目的情况下,CA 600所接收的8比特值的串流可以被解压缩为对应的16比特内核值。被压缩的内核数据的宽度可以在运行时被配置。当解压缩特征被启用时(这也可以在运行时),以及当被压缩的内核数据到达第二CA输入接口604时,也可以执行解压缩。在启动CA 600之前,将填充查找表的数据可以经由CA总线端口接口624被传递到CA 600。备选地,在一些实施例中,也可以经由第二CA输入接口604或经由某个其他数据传输机构来接收查找表数据。
更详细地考虑图6A、图6B的CA MAC单元620。来自第五CA内部缓冲器618特征条缓冲器的特征数据被转发到CA MAC单元620的集合。在一个示例性实施例中,CA MAC单元620被布置为包括12个MAC集群的堆叠,其中每个MAC集群包含三个(3)MAC单元,并且其中每个MAC单元能够在每周期执行一个16比特MAC操作。当然也考虑其他配置。例如,CA MAC单元620可以包括多于或少于36个的MAC单元,所包括的MAC单元可以或可以不被布置为集群,并且所包括的MAC单元可以操作更宽的数据、更窄的数据或者具有不同的定时。
在CA MAC单元620的MAC集群和第五CA内部缓冲器618特征带缓冲器之间形成高度连接的CA特征缓冲器开关628。在一些实施例中,CA特征缓冲器开关628包括可编程多路复用器的集合。CA特征开关628允许CA MAC 620的各个MAC单元(例如,每个MAC集群)选择第五CA内部缓冲器618特征条缓冲器的特定输出端口(例如,12个输出端口中的一个)。所选择的输出端口将对应于特定的特征线或行。
在并行处理小内核的情况下(例如,本文所讨论的4×3×3的情况),两个或更多个MAC单元(例如,两个或更多个MAC集群)可以选择第五CA内部缓冲器618特征线缓冲器的相同特征行。例如,当考虑示例性实施例时,第一、第二和第三MAC集群将处理第一内核;第四、第五和第六集群将处理第二个内核,等。在处理更大的内核的情况下,可以使用所有MAC单元(例如,所有集群)来计算单一个内核的结果,并且一次只处理一个内核。
一些异常可以适用,并且本文所描述的CAF 400被布置为处理异常。例如,在与AlexNet相似的表5的示例性神经网络中,第一层包括11像素×11像素(11×11)的内核。由于在这种情况下的内核具有11个像素的垂直维度,所以使用示例性CA MAC单元620(例如,具有12个MAC集群)除了一个之外的所有MAC集群来执行计算。然而,在该示例的水平方向上,由于四(4)个像素的步幅,仅需要3个MAC单元。因此,33个MAC单元可以并行执行计算。另一方面,由于在该示例中来自表5的层1的垂直步幅为四(4),在一个输出线的处理之后,并且直到特征数据的另外三个线已被接收并加载到第五CA内部缓冲器618特征条缓冲器中,MAC单元将处于空闲状态。
为了解决不期望的空闲状态,高度可配置的CA 620可以可选地包括附加的线交织模式。附加的线交织模式可以被配置为以线交织的方式将多个内核应用于相同的特征。特征数据的这种线交织使得CA 620能够在相同的特征数据上并行处理四个11×11的内核。
更详细地考虑图6A、图6B的CA加法器树622。在本文所描述的示例性操作中,CA加法器树622构建由CA MAC单元620在每个周期提供的结果的和。CA MAC单元620在水平方向上执行乘法和累加,并且CA加法器树622在垂直方向上生成和。CA加法器树622具有可以基于内核的垂直大小在运行时被配置的宽度。如果并行计算两个或更多个内核,则CA加法器树622操作的可配置宽度可以被划分为子分支。
除了来自CA MAC单元620的结果之外,CA加法器树622还可以对在第一CA输入接口602上接收到的中间批次结果求和。在一些情况下,当并行处理两个或更多个内核并且线未被交织时,来自CA加法器树622的数据作为固定顺序被传递通过CA输出接口608。即,在固定顺序中,第一内核的结果可以被传递通过CA输出接口608,然后第二内核的结果被传递,等。在这种情况下,可以以类似于批次大小用于内核数据和输入特征数据的方式来处理输出数据。例如,如果并行处理四(4)个内核,则输出特征数据将被处理,犹如批次大小等于四(4)。相应地,在这些情况下,通过第一CA输入接口602被传递的中间数据也将保持相同的顺序。
更详细地考虑图6A、图6B的CA输出接口608。在一些情况下,CA输出接口608包括CA配置逻辑626或以其他方式与CA配置逻辑626(例如,输出控制626b)协作,以形成或以其他方式处理原始数据串流。配置逻辑可以在原始数据串流中嵌入某些标签、标记或其他信息(例如,第一标签、最后标签等)。通过CA输出接口608传递的原始数据被传递通过CA加法器树622或以其他方式由CA加法器树622生成。
如本文所述,CA输出接口608被布置用于耦合到串流开关500的串流链路502。在停止运行信号被传递通过串流开关500并由CA输出接口608接收的情况下,停止运行或对应的代表性信号将被传递到CA加法器树622。停止运行信号将导致CA 600减慢或停止其处理,直到停止运行信号被清除。例如,单个寄存器可以暂停或临时禁用CA 600。备选地或附加地,CA MAC单元60的处理、从第五CA内部缓冲器618特征线缓冲器的数据获取、从第四CA内部缓冲器616内核缓冲器的数据获取也可以被暂停或以其他方式挂起,直到停止运行信号被清除。
在运行时,在根据图3-图6的系统中,CAF 400可以被配置有选定数量的定义的、并发虚拟处理链。以这种方式,CAF 400比常规系统提供了明显的优势,因为CAF 400可以复用数据。即,通过定义并发的虚拟处理链,在流式数据可以被“下一个”加速器或接口复用之前,流式数据不需要经过系统总线被重复传输或临时存储在外部存储器中。CAF 400中提供的全功能背压机构管理数据流控制,并且串流多播允许在多个设备处并发呈现相同数据(即,相同数据的多个实例)。在数据被复制到两个或更多个目的地的串流“叉路”的情况下,使用组合背压逻辑518来重新生成背压信号(例如,停止运行信号),组合背压逻辑518将来自耦合到串流链路502的每个启用的目的地设备的背压信号进行组合。
考虑图3的示例性移动设备100的实施例,在特定视频处理应用的启动时,主处理器(例如,应用处理器128、DSP集群140的DSP 142或另一处理器)通过对串流开关500进行编程来配置一个或多个处理链。编程可以通过将特定值存储在CAF控制寄存器402(图4)中的特定CAF控制寄存器中来实现。编程可以在默认情况下、在启动时或在运行时执行。
处理链通常包括:将流式数据传送到串流开关的第一接口;串流开关的第一配置,将流式数据传递到一个或多个加速器;以及串流开关的第二配置,将由一个或多个加速器生成的经处理的数据传递到第二接口。当然可以使用这些动作的各种组合来形成更复杂的处理链。
例如,通过配置串流开关500的输入端口504来形成简单的处理链,以传递来自图像传感器、图像串流处理器或一些其他流式数据源的流式视频数据。串流开关500然后被配置为将流式视频数据传递到第一专用加速器(例如,变形滤波器、JPEG编码器、背景去除器、特征点检测器等)或第一通用加速器(例如,颜色转换器、图像缩放器/裁剪器、卷积加速器等)。然后,串流开关500被配置为将输出数据从第一专用或通用加速器传递到第二接口。第二接口可以是例如另一加速器、DMA引擎或一些其他设备。
考虑更复杂的处理链,CAF 400框架允许具有叉路的链、仅具有一个外部接口的连接串流、具有多个接口的连接串流、具有叉路和跳跃的链以及其他复杂的处理链。在某些情况下,更复杂的处理链将被布置为遵守某些可选的限制。这些可选的限制可以例如与某些外部接口相关联,这些外部接口无法在不丢失数据的情况下控制其带宽。
在一种情况下,连接到相机接口的图像传感器提供固定的平均带宽。如果瓶颈出现在处理链中的下游(例如,后续或稍后)块中,则来自图像传感器的数据将不会被存储或流传输,而是数据将会丢失。管理这种可能的数据丢失问题的一种方式是配置相机传感器,使得提供处理链中的所有后续块在最坏情况下也能够维持的平均带宽。管理可能的数据丢失问题的另一方法是以受控的方式丢弃数据(例如,通过丢弃整个帧并在下一帧开始时重新启动),这可能温和地对应用的功能产生可接受的影响。管理可能的数据丢失问题的另一方法是从在设计时定义并在运行时分配的共享存储器池提供合理的缓冲器空间。也设想了用于管理可能的数据丢失的其他技术。
在一个或多个处理链的配置之后,主机处理器可以被布置为(从链的终点开始,逐渐前进到链的源点)在处理链中的每个块的配置寄存器(例如,CAF控制寄存器402的寄存器)中编程所选择的功能。尚未被配置的串流开关500元件的串流输入端口504可以被布置为在默认情况下向任何连接的输出串流端口516提供停止运行信号。这样的编程可以在整个处理链被配置之前阻止特定处理链的启动。
CAF 400和其中集成的串流开关500的运行时可配置性提供了优于不可如此配置的常规系统的几个优点。例如,使用本文所述的CAF 400架构,新的加速器和接口的设计和集成被大大简化。此外,现有加速器的复用变得更加容易。可以使用新的加速器模块、接口模块和其他模块来扩展本文所述的CAF IP库(例如,表2)。许多通用加速器(例如,颜色转换器、图像裁切器、缩放器等)也可以在运行时被复用,以用于多个应用。CAF 400框架的另一优点是改进的可扩展性。如果半导体从业者需要更多的处理能力,则可以集成多个相同的加速器,其中可以在系统定义文件中添加很少的几行软件定义。本CAF 400架构的另一优点是可以在运行时创建、修改或删除一个或多个处理链。不需要专用旁路、多路复用器或其他逻辑来移除或替换处理链中的单元,从而为算法设计者提供更大的灵活性。CAF 400还有一个优点是可以将数据从串流源设备直接路由到串流宿设备,而无需消耗存储器空间或者系统总线上的带宽。如果期望,在不需要附加的数据获取的情况下,多播特征允许数据串流被轻易地复制,并且可以定义大量并发活动的串流和处理链。本文所描述的CAF架构有利地允许完全主机独立的复杂任务(例如,整个卷积层)的处理,包括可选地如果特定事件发生则生成中断。通过在串流开关500中包括简单的单向串流链路502来实现另一优点。由于单向串流链路502,甚至大型的串流开关500也保持架构上的高效和可扩展性。例如,在一些情况下,具有多于50个输入和输出端口的串流开关500使用仅约4万个门紧凑地形成,这小于一个卷积加速器的门的数量的一半。本文所提到的最后一个优点是,使用CAF 400架构,调试和原型设计被大大简化,原因是每个数据串流都可以在运行时被复制并被路由到处理链的任一级处的调试模块。以这种方式,算法设计者或其他软件从业者可以在运行时有效地跟踪、监视和调试或以其他方式评估系统中的任何处理链。
图7是示出用于训练深度卷积神经网络(DCNN)的数据路径和使用经训练的DCNN配置片上系统(SoC)的高级框图。系统101包括DCNN训练模块106、SoC配置工具108和SoC 110。系统101还包括训练图像数据库102和DCNN配置104。
训练图像数据库102包括用于训练DCNN的多个图像。训练图像数据库102中的图像共享公共特性或图像识别标准,其定义训练DCNN来识别的对象。待识别的对象可以是特定对象、或对象的类或子类。例如,对象可以是狗、特定品种的狗、哺乳动物或广义的动物。应当理解,这些示例不是限制性的,并且也可以识别其他类型的对象。作为示例,如果待识别的对象是动物,则图像数据库102包括不同类型动物的多个图像,例如,狮子、狗、企鹅、鹰、鲸鱼、海豚、袋鼠、兔、松鼠或其他动物。一般来说,训练图像涵盖对象的公共特征越多,DCNN就应当越准确。
DCNN配置104包括多个不同的神经细胞结构、多个不同的神经网络部件以及多种不同类型的深度学习框架,用户可以从其中进行选择以设计DCNN。例如,DCNN配置104可以包括用于任何数量的神经细胞结构(例如,反馈输入细胞、线性输入细胞、噪声输入细胞、隐藏细胞、概率隐藏细胞、尖峰隐藏细胞、线性输出细胞、匹配输入/输出细胞、递归细胞、记忆细胞、不同的记忆细胞、内核细胞、卷积或池化细胞等)的配置信息。
DCNN配置还可以包括用于各种神经网络部件(例如,类型感知器部件、前馈(FF)部件、径向基础网络(RBF)部件、深度前馈(DFF)部件、马尔可夫链(MC)部件、霍普菲尔德网络(HN)部件、玻尔兹曼机(MB)部件、限制BM(RBM)部件、深度信念网络(DBN)部件、递归神经网络(RNN)部件、长/短时记忆(LSTM)部件、门控递归单元(GRU)部件、深度卷积网络(DCN)部件、反卷积网络(DN)部件、深度卷积逆图形网络(DCIGN)部件、自动编码器(AE)部件、变分AE(VAE)部件、去噪AE(DAE)部件、稀疏AE(SAE)部件、生成性对抗网络(GAN)部件、液体状态机(LSM)部件、极限学习机(ELM)部件、回波状态网络(ESN)部件、深度残差网络(DRN)部件、科宁网络(KN)部件、支持向量机(SVM)部件、神经图灵机(NTM)部件等)的配置。DCNN配置104还可以包括配置信息深度学习框架,配置信息深度学习框架包括完全成形的神经网络实现,例如,Caffe、AlexNet、Theano、TensorFlow、GoogleLeNet、VGG19、ResNet或其他深度学习框架。
一旦选择了深度学习框架和图像数据库102,将来自DCNN配置104的DCNN配置信息和来自图像数据库102的训练图像上传或提供给DCNN训练模块106。
DCNN训练模块106利用所提供的训练图像执行或运行深度学习框架来训练DCNN。该训练生成DCNN权重和元数据。这些权重定义经训练的神经网络。
将DCNN权重和元数据提供给SoC配置工具108。SoC配置工具108利用DCNN权重来生成并可接受地优化SoC可配置拓扑。例如,SoC配置工具108测试和验证图像数据集;提供定点分析;执行可接受的最优定点精度分配(逐层);执行权重压缩;并执行权重布局转换。SoC配置工具108执行的其他操作包括对网络拓扑操作执行网络描述;存储器管理和缓冲器放置;DMA描述符链生成;以及对在可配置的加速器框架和DSP集群上的DCNN执行的可接受地最优的映射和调度。SoC配置工具108输出SoC配置文件和DCNN SoC权重。SoC配置文件标识用于在SoC 110上实现DCNN的SoC 110的各种配置(例如,SoC 110上的一个或多个DSP 138的配置和可配置的加速器框架)。
DCNN SoC权重被上传并存储在SoC 110的存储器中。在一些实施例中,DCNN SoC权重可以经由USB、以无线方式或经由其他数据通信链路提供给SoC 110。在各种实施例中,将DCNN SoC权重作为配置文件的一部分提供给SoC 110,该配置文件由SoC 110在SoC 110的启动时加载,该配置文件对SoC 110进行配置。
图8包括图8A-图8B。
图8A-图8B示出了用于设计和配置SoC 110(图3、图7)并用于利用所配置的SoC 110对图像进行分类(图8B)的示例性处理的流程图。图8A的处理200在开始框之后开始。在框204处,接收训练图像数据库。训练数据库包括多个图像,每个图像具有定义DCNN被训练以识别的对象(即,经训练的对象)的至少一个公共特性或图像特征。例如,如果用户上传500个图像,并且每个图像中都有一只狗,那么即使用户没有指定,经训练的对象也是一只狗。
处理200继续到框206,其中接收DCNN配置。如上所述,用户可以选择或定义用于训练DCNN的深度学习框架。
处理200进行到框208,其中基于训练数据库中的图像和DCNN配置来训练DCNN。该DCNN训练是本领域技术人员已知的,并且输出经训练的DCNN权重和其他元数据。
接下来处理200在框210处继续,其中基于经训练的DCNN权重来生成SoC配置文件和SoC DCNN权重。如上所述,该生成处理可以包括对DSP 138或DSP集群122、140以及CAF 400(包括CAF 400中的CA)的利用的配置和自定义。在各种实施例中,该配置标识用于每个DCNN层的不同CAF 400配置和DSP 138利用。CAF 400也是与DSP 138结合来执行DCNN的图像及深度卷积神经网络协同处理系统。
处理200进行到框212,其中SoC配置文件和SoC DCNN权重被上传到SoC 110。SocC 110将SoC DCNN权重存储在诸如SoC全局存储器126的存储器中,并且当SoC配置文件被加载时,SoC 110能够对输入图像数据执行图像识别。
在框212之后,处理200结束或以其他方式返回到调用处理以执行其他动作。
图8B的处理250在开始框之后开始。在框252处,如上面结合图8A所描述的,接收SoC配置文件和SoC DCNN权重。同样,该配置文件定义了在通过DCNN层处理图像期间如何配置CAF 400和DSP 138。
处理250进行到框254,其中基于所接收的配置文件来配置CAF 400和DSP 138。该配置可以包括:初始化一个或多个DSP 138来执行与DCNN相关联的特定操作(例如,最大或平均池化、非线性激活、跨通道响应归一化等)。类似地,如上面更详细描述的,CAF 400被配置为使得CAF 400中的完全连接的开关被配置为将数据移动到适当的宿部件或移动来自适当的源部件的数据,并且一个或多个卷积加速器被初始化来执行各种动作(例如,颜色转换器、参考帧更新、背景/阴影去除器、多状态变形滤波、特征检测、图像裁剪器和缩放器/子采样器等)。
处理250在框256处继续,其中接收图像。应当认识到,可以接收单个静止图像,或者图像可以是视频中的单个图像帧。
处理250进行到框258,其中通过采用经配置的CAF 400和DSP 138来执行其经配置的动作或功能,对所接收的图像执行经训练的DCNN。
处理250进行到框260,其中在DCNN执行期间,CAF 400和/或DSP 138基于配置文件被重新配置。由于DCNN中的每个层可以执行不同的任务或者以不同方式可接受地优化,所以SoC配置文件标识在图像分类期间如何为DCNN的每个层配置CAF 400或DSP 138。
处理250进行到框262,其中输出DCNN结果。在各种实施例中,在这种情况下的结果可以是布尔真或布尔假,指示输入图像是否包括经训练的对象。在其他实施例中,结果可以是图像包括对象的概率的数量或其他标识符。在又一些其他实施例中,结果可以标识多个不同对象的概率。
在框262之后,处理250结束或以其他方式返回到调用处理,以执行其他动作。在各种实施例中,处理250可以循环到框254,以在框256处重新配置SoC 110以用于新的输入图像。该重新配置可被视为重置在新图像上使用的DCNN来识别经训练的对象。
在前面的描述中,阐述了某些具体细节以提供对各种所公开的实施例的透彻理解。然而,相关领域的技术人员将认识到,可以在没有这些具体细节中的一个或多个的情况下,或利用其他方法、部件、材料等来实践实施例。在其他情况下,未详细地示出或描述与电子和计算系统相关联的公知结构(包括客户端和服务器计算系统以及网络),以避免不必要地模糊实施例的描述。
除非上下文另有要求,否则在整个说明书和以下权利要求中,词语“包括”及其派生词(例如,“包含”和“含有”)应以开放的包容性意义来解释,例如,“包括,但不限于”。
在整个说明书中对“一个实施例”或“实施例”及其派生词的参考意味着结合实施例描述的特定特征、结构或特性被包括在至少一个实施例中。因此,贯穿本说明书的各个地方的短语“在一个实施例中”或“在实施例中”的出现不一定都指代相同的实施例。此外,特定特征、结构或特性可以以任何合适的方式组合在一个或多个实施例中。
如本说明书和所附权利要求中所使用的,除非内容和上下文另有明确规定,否则单数形式“一”,“一个”和“所述”包括复数指示物。还应当指出,除非内容和上下文明确地规定了包容性或排他性(视情况而定),否则连接术语“和”和“或”通常在最广泛的意义上被使用以包括“和/或”。另外,“和”以及“或”的组合在本文中被记载为“和/或”时,旨在涵盖包括所有相关联的项或想法的实施例,以及包括少于所有相关联的项或想法的一个或多个其他备选实施例。
本文所提供的公开的标题和摘要仅为了方便起见,并不限制或解释实施例的范围或含义。
可以组合上述各种实施例来提供其他实施例。如果需要使用各种专利、申请和出版物的概念来提供另外的实施例,则可以修改实施例的方面。
可以根据上述详细描述对这些实施例进行这些改变和其他改变。通常,在所附权利要求中,所使用的术语不应被解释为将权利要求限制于说明书和权利要求书中公开的具体实施例,而应被解释为包括这样的权利要求所要求保护的所有可能的实施例以及等同物的全部范围。因此,权利要求不受本公开的限制。
- 还没有人留言评论。精彩留言会获得点赞!