指标决策方法与流程
本发明涉及控制与决策领域,更具体地,涉及一种指标决策方法。
背景技术:
测量和评价是人类认识自然与探索自然的重要手段。在统一的测量指标和评价准则下,对物体的属性(如长度、质量)进行测量、对事物或行为的合理性进行评价,才能得到客观、公正的结果。对事物或行为(被评价对象)的评价往往需要多个指标,从不同维度对其进行“测量”。因此,指标本身的选取对进行状态评估和科学研究具有重要的意义,因此需要对指标的合理性进行“测量”。
在建立指标体系的过程中,往往会有很多指标被设计人提出。合理性“好”的指标,能完全反映被评价对象的特点;合理性“差”的指标不能完全反映被评价对象的特点,即存在较大的误差。对于一个指标的合理性进行测量,本身会引入专家个体的因素,或受到其他专家的干扰,进而使得指标合理性测量存在误差。因此需要依托多个专家的经验,各自独立的对指标的合理性进行测量,最后以定量的方式给出结论,即是否保留该指标。
指标体系设计理论、指标的提出方法、指标的合理性,在很大程度上体现着评估机构和评估人员的总体业务水平。因此对指标的合理性进行测量,是现代评估方法中的一个重要研究内容,也是评估方法进一步发展中不可缺少的分析、研究手段,对科学评估的发展起到了积极的促进作用。
传统的指标决策方法是基于专家经验来进行的,即采用匿名打分方式进行。每个专家独立对待评价指标的合理性进行测量,并给出专家的权威性系数。当所有专家都对该指标的合理性测量完成后,采用计算平均值和标准偏差的方式,形成具有统计意义的专家集体测量结果。
发明人发现,在现有指标决策方法中,没有给出决策结果的置信区间信息。每个专家在对每个指标进行合理性测量以后,测量结果是按照指标的纵向维度分别计算均值、满分频率、以及变异系数,然后在这三个数据中人为判断指标是否合理。这样就把独立的单一指标合理性评价工作拆分成了三种类型的数据,没有将专家独立判断的信息放到整个指标系统的环境下进行决策,判断效率较低且损失了专家信息。
此外,在使用权威系数的时候,没有将同一个专家的打分和权威系数综合考虑得到一个综合测量结果。权威系数仅用于表明专家对本次合理性测量的指标所属领域权威程度是否高(平均值大于0.7时结果显著,结果可信),以及专家的权威性波动情况(所有权威系数的方差)。
此外,虽然每个专家都是独立的对同一个指标进行评价,但是多个专家对同一个指标进行测量以后,对测量结果并没有进行异常值进行剔除,用常规的统计方法将把这种偏见代入到合理性计算当中。尤其是使用变异系数方法去判断专家测量结果的波动性,当平均值接近于0的时候,微小的扰动也会对变异系数产生巨大影响,因此造成指标决策的精确度不足。因此,有必要开发一种效率高、鲁棒性强的指标决策方法。
技术实现要素:
本发明的目的是提出一种指标决策方法,以克服现有指标决策方法精确度不高、效率低的问题。
本发明提出了一种指标决策方法,包括以下步骤:
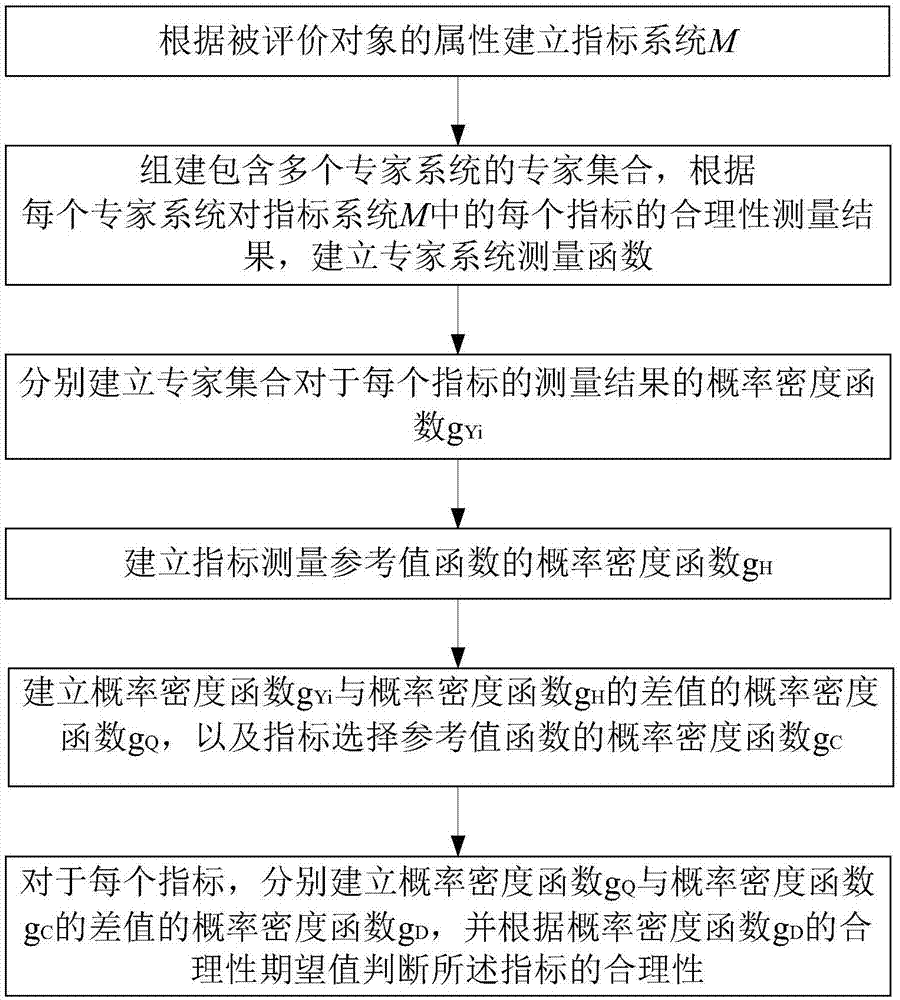
步骤1:根据被评价对象的属性建立指标系统m;
步骤2:组建包含多个专家系统的专家集合,根据每个专家系统对指标系统m中的每个指标的合理性测量结果,建立专家系统测量函数;
步骤3:分别建立专家集合对于每个指标的测量结果的概率密度函数
步骤4:建立指标测量参考值函数的概率密度函数gh;
步骤5:建立概率密度函数
步骤6:对于每个指标,分别建立概率密度函数
优选地,所述被评价对象具有n个属性,这些属性的指标分别记为m1,m2,m3,…,mi,…,mn-1,mn,所述指标系统m为m{m|m1,m2,m3,...,mi,...,mn-1,mn}。
优选地,所述专家系统测量函数为ei,j,如以下公式(1)所示:
ei,j(ei,j,ca,j,cs,j)=λ·ei,j·(ca,j+cs,j)/2,0<λ≤1
ei,j(ei,j,ca,j,cs,j)=ei,j,λ=0(1)
其中,λ为调控因子,ei,j、ca,j、cs,j分别表示专家系统ej对指标系统m中的指标mi进行合理性测量给出的打分结果、测量依据系数、熟悉程度系数,其中,i=1,…,n,j=1,…,p,p为专家系统的数量。
优选地,0≤ca,j≤1,0≤cs,j≤1。
优选地,p≥10。
优选地,所述步骤3包括:
子步骤31:对于每个指标mi,将专家集合中的所有专家系统对于指标mi的测量模型定义为yi;
子步骤32:对于每个指标mi,确定测量模型yi的p个输入量x1,…,xj,…,xp,其分别对应于各专家系统对指标mi的测量结果eλi,1,…,eλi,j,…,eλi,p,其中eλi,j表示专家系统测量函数ei,j的值,分别根据以下公式(2)和(3)计算p个输入量的平均值
其中,
子步骤33:对于每个指标mi,以其对应的平均值
优选地,所述步骤4包括:
子步骤41:对于指标mi,其中i=1,…,n,建立样本向量vyi=(yi,1,yi,2,...,yi,s),其中yi,t(t=1,…,s)表示在子步骤33中对p个输入量x1,…,xj,…,xp进行第t次随机赋值后的测量模型yi的期望值和方差;
子步骤42:对于i=1,…,n,分别基于样本向量vyi计算指标测量参考值函数h的值,如以下公式(4)所示:
hi=h(vyi)=h(yi,1,yi,2,...,yi,s)(4)
其中,h表示对测量模型yi所代表的分布函数取中位数或者取平均值;子步骤43:根据指标测量参考值函数h的值,建立指标测量参考值函数h的概率密度函数为gh;同时建立指标测量参考值函数h的离散模型gh;
子步骤44:将理论计算的期望值和方差与子步骤43中获得的概率密度函数gh的期望值和方差分别进行比较。
优选地,所述步骤5包括:
子步骤51:分别针对每个指标mi,建立测量模型yi与指标测量参考值函数h的差值的函数qi,其中i=1,…,n:
qi=yi-h(5)
子步骤52:分别针对每个指标mi,基于对p个输入量x1,…,xj,…,xp进行每一次随机赋值所计算的测量模型yi所服从的分布的期望值和方差,计算函数qi的值qi,t,如公式(6)所示,其中,t=1,…,s:
qi,t=yi,t-hi(6)
子步骤53:建立所有函数qi的中位数或平均值函数c,其中,i=1,…,n,即:
c=h(q1,q2,...,qi,...,qn)(7)
以及,对于每一次随机赋值,基于函数qi的值qi,t计算中位数或平均值函数c的值,即:
ct=h(q1,t,q2,t,...,qi,t,...,qn,t)(8)
从而获得中位数或平均值函数c的概率密度函数gc,中位数或平均值函数c即指标选择参考值函数。
优选地,所述步骤6包括:
子步骤61:对于每个指标,分别建立函数qi和函数c之间的关系模型di=qi-c,其中i=1,…,n;
子步骤62:对于每个指标,对于t=1,…,s,分别计算关系模型di的值,如以下公式(8)所示:
di,t=qi,t-ct(9)
基于公式(9)的计算结果,对于每个指标,可分别建立关系模型di的概率密度分布函数gdi,通过概率密度分布函数gdi可以计算每个指标的合理性期望值e(gdi)及标准偏差σ(gdi);
子步骤63:针对每个指标,根据其对应的概率密度分布函数gdi的合理性期望值判断所述指标的合理性。
优选地,所述指标决策方法还包括:
步骤7:对指标决策结果进行显著性检验。
优选地,所述步骤7包括:
子步骤71:建立关系模型di的中位数函数o,即:
o=h(d1,d2,...,di,...,dn)(9)
子步骤72:对于每一次随机赋值,基于关系模型di的值di,t计算中位数函数o的值,如以下公式(10)所示:
ot=h(d1,t,d2,t,...,di,t,...,dn,t)(10)
根据中位数函数o的值获得中位数函数o的离散模型go,并将中位数函数o的概率密度函数记为go;
子步骤73:通过卡方测试确定异常分布,包括:
构建检验函数
其中,自由度v=n-1;
根据自由度v和第一显著性水平α,从
本发明另一方面提出一种计算机可读存储介质,其上存储有计算机程序,其中,所述程序被处理器执行时实现以下步骤:
步骤1:根据被评价对象的属性建立指标系统m;
步骤2:组建包含多个专家系统的专家集合,根据每个专家系统对指标系统m中的每个指标的合理性测量结果,建立专家系统测量函数;
步骤3:分别建立专家集合对于每个指标的测量结果的概率密度函数
步骤4:建立指标测量参考值函数的概率密度函数gh;
步骤5:建立概率密度函数
步骤6:对于每个指标,分别建立概率密度函数
优选地,所述被评价对象具有n个属性,这些属性的指标分别记为m1,m2,m3,…,mi,…,mn-1,mn,所述指标系统m为m{m|m1,m2,m3,...,mi,...,mn-1,mn}。
优选地,所述专家系统测量函数为ei,j,如以下公式(1)所示:
ei,j(ei,j,ca,j,cs,j)=λ·ei,j·(ca,j+cs,j)/2,0<λ≤1
ei,j(ei,j,ca,j,cs,j)=ei,j,λ=0(1)
其中,λ为调控因子,ei,j、ca,j、cs,j分别表示专家系统ej对指标系统m中的指标mi进行合理性测量给出的打分结果、测量依据系数、熟悉程度系数,其中,i=1,…,n,j=1,…,p,p为专家系统的数量。
优选地,0≤ca,j≤1,0≤cs,j≤1。
优选地,p≥10。
优选地,所述步骤3包括:
子步骤31:对于每个指标mi,将专家集合中的所有专家系统对于指标mi的测量模型定义为yi;
子步骤32:对于每个指标mi,确定测量模型yi的p个输入量x1,…,xj,…,xp,其分别对应于各专家系统对指标mi的测量结果eλi,1,…,eλi,j,…,eλi,p,其中eλi,j表示专家系统测量函数ei,j的值,分别根据以下公式(2)和(3)计算p个输入量的平均值
其中,
子步骤33:对于每个指标mi,以其对应的平均值
优选地,所述步骤4包括:
子步骤41:对于指标mi,其中i=1,…,n,分别建立样本向量vyi=(yi,1,yi,2,...,yi,s),其中yi,t(t=1,…,s)表示在子步骤33中对p个输入量x1,…,xj,…,xp进行第t次随机赋值后的测量模型yi的期望值和方差;
子步骤42:对于i=1,…,n,分别基于样本向量vyi计算指标测量参考值函数h的值,如以下公式(4)所示:
hi=h(vyi)=h(yi,1,yi,2,...,yi,s)(4)
其中,h表示对测量模型yi所代表的分布函数取中位数或者取平均值;
子步骤43:根据指标测量参考值函数h的值,建立指标测量参考值函数h的概率密度函数为gh;同时建立指标测量参考值函数h的离散模型gh;
子步骤44:将理论计算的期望值和方差与子步骤43中获得的概率密度函数gh的期望值和方差分别进行比较。
优选地,所述步骤5包括:
子步骤51:分别针对每个指标mi,建立测量模型yi与指标测量参考值函数h的差值的函数qi,其中i=1,…,n:
qi=yi-h(5)
子步骤52:分别针对每个指标mi,基于对p个输入量x1,…,xj,…,xp进行每一次随机赋值所计算的测量模型yi所服从的分布的期望值和方差,计算函数qi的值qi,t,如公式(6)所示,其中,t=1,…,s:
qi,t=yi,t-hi(6)
子步骤53:建立所有函数qi的中位数或平均值函数c,其中,i=1,…,n,即:
c=h(q1,q2,...,qi,...,qn)(7)
以及,对于每一次随机赋值,基于函数qi的值qi,t计算中位数或平均值函数c的值,即:
ct=h(q1,t,q2,t,...,qi,t,...,qn,t)(8)
从而获得中位数或平均值函数c的概率密度函数gc,中位数或平均值函数c即指标选择参考值函数。
优选地,所述步骤6包括:
子步骤61:对于每个指标,分别建立函数qi和函数c之间的关系模型di=qi-c,其中i=1,…,n;
子步骤62:对于每个指标,对于t=1,…,s,分别计算关系模型di的值,如以下公式(8)所示:
di,t=qi,t-ct(9)
基于公式(9)的计算结果,对于每个指标,可分别建立关系模型di的概率密度分布函数gdi,通过概率密度分布函数gdi可以计算每个指标的合理性期望值e(gdi)及标准偏差σ(gdi);
子步骤63:针对每个指标,根据概率密度函数gd的合理性期望值判断所述指标的合理性。
优选地,所述指标决策方法还包括:
步骤7:对指标决策结果进行显著性检验。
优选地,所述步骤7包括:
子步骤71:建立关系模型di的中位数函数o,即:
o=h(d1,d2,...,di,...,dn)(9)
子步骤72:对于每一次随机赋值,基于关系模型di的值di,t计算中位数函数o的值,如以下公式(10)所示:
ot=h(d1,t,d2,t,...,di,t,...,dn,t)(10)
根据中位数函数o的值获得中位数函数o的离散模型go,并将中位数函数o的概率密度函数记为go;
子步骤73:通过卡方测试确定异常分布,包括:
构建检验函数
其中,自由度v=n-1;
根据自由度v和第一显著性水平α,从
本发明的有益效果在于通过离散抽样的方式,得到专家系统对指标的合理性测量结果的概率密度分布,提高了指标合理性判定的效率和准确度。
附图说明
通过结合附图对本发明示例性实施例进行更详细的描述,本发明的上述以及其它目的、特征和优势将变得更加明显。
图1示出了根据本发明示例性实施例的指标决策方法的流程图;
图2-1至图2-8分别示出了根据本发明示例性实施例的指标决策方法的对应于指标m1至m8的测量结果的概率密度函数示意图;
图3示出了根据本发明示例性实施例的指标决策方法的指标测量参考值函数的概率密度函数示意图;
图4-1至图4-8分别示出了根据本发明示例性实施例的指标决策方法的对应于指标m1至m8与指标测量参考值函数的差值的概率密度函数示意图;
图5示出了根据本发明示例性实施例的指标决策方法的中位数函数的概率密度函数示意图。
具体实施方式
下面将参照附图更详细地描述本发明。虽然附图中显示了本发明的优选实施例,然而应该理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了使本发明更加透彻和完整,并且能够将本发明的范围完整地传达给本领域的技术人员。
本发明实施例提出一种指标决策方法,图1示出了根据示例性实施例的指标决策方法的流程图,其包括以下步骤:
步骤1:根据被评价对象的属性建立指标系统m。
假设被评价对象具有n个属性,这些属性的指标分别记为m1,m2,m3,…,mi,…,mn-1,mn,根据被评价对象的属性建立指标系统m,即m{m|m1,m2,m3,...,mi,...,mn-1,mn}。
步骤2:组建包含多个专家系统的专家集合,根据每个专家系统对指标系统m中的每个指标的合理性测量结果,建立专家系统测量函数。
具体来说,组建包含p个专家系统的专家集合,p个专家系统分别记为e1,e2,e3,…,ej,…,ep-1,ep。为了保证决策的准确和合理性,一般情况下,p≥10。
每个专家系统分别对指标系统m中的每个指标进行合理性测量,给出打分结果,并给出针对每个指标的测量依据系数ca和熟悉程度系数cs。其值需满足0≤ca≤1,0≤cs≤1的约束。定义ca为0时表示没有判断依据,ca为1时表示根据实践经验进行的判断;cs为0时表示对该指标完全不熟悉,cs为1时表示对该指标所属领域非常熟悉。
一般情况下,一个专家系统对于指标系统m中的各个指标的测量依据和熟悉程度是基本相同的,因此对于一个专家系统而言,其针对每个指标的测量依据系数和熟悉程度系数也相同。具体来说,对于专家系统ej(其中j=1,…,p),其对指标系统m中的指标mi(其中i=1,…,n)进行合理性测量,给出打分结果ei,j,并给出针对指标mi的测量依据系数ca,j和熟悉程度系数cs,j,从而可以获得专家系统测量函数ei,j,如以下公式(1)所示:
ei,j(ei,j,ca,j,cs,j)=λ·ei,j·(ca,j+cs,j)/2,0<λ≤1
ei,j(ei,j,ca,j,cs,j)=ei,j,λ=0(1)
其中,λ为调控因子,用来控制在测量函数中是否加入专家测量系数。专家系统测量函数ei,j的值记为eλi,j,其表示专家系统ej对指标mi的测量结果。
在本步骤中,通过实际的专家系统分别对指标系统m中的每个指标进行合理性测量,建立专家系统测量函数,专家系统测量函数作为后续步骤的模拟基准。
在优选情况下,专家系统测量函数ei,j的任意两个函数值eλi,l与eλi,k(其中1≤l≤p,1≤k≤p,且l≠k)之间的协方差和相关系数为零,即每个专家系统之间不进行信息交换,互相之间没有任何影响。
步骤3:分别建立专家集合对于每个指标的测量结果的概率密度函数
具体地,步骤3包括:
子步骤31:对于每个指标mi,其中i=1,…,n,将专家集合中的所有专家系统对于指标mi的测量模型定义为yi。优选地,测量模型yi的输出量服从正态分布。
子步骤32:对于每个指标mi,确定测量模型yi的p个输入量x1,…,xj,…,xp,其分别对应于各专家系统对指标mi的测量结果eλi,1,…,eλi,j,…,eλi,p,分别根据以下公式(2)和(3)计算p个输入量的平均值
其中,
子步骤33:对于每个指标mi,以其对应的平均值
当s的值充分大时,模拟的平均值与
经过s次随机赋值之后,得到测量模型yi的概率密度函数
优选地,随机赋值的次数s应在100000次以上,以使得模拟的测量模型yi的期望值尽可能地接近
通过上述步骤,对于指标系统m中的每个指标m1,…,mi,…,mn分别建立专家系统对于各指标的测量结果的概率密度函数
步骤4:建立指标测量参考值函数的概率密度函数gh。
具体地,步骤4包括以下子步骤:
子步骤41:对于指标mi(i=1,…,n),根据步骤33的结果,分别建立样本向量vyi=(yi,1,yi,2,...,yi,s),其中yi,t(t=1,…,s)表示在子步骤33中对p个输入量x1,…,xj,…,xp进行第t次随机赋值后的测量模型yi的期望值和方差。样本向量vyi在进行了s次随机赋值以后,每个指标mi的测量模型yi都服从子步骤33中所预期的分布。优选地,yi为均值为
子步骤42:对于i=1,…,n,分别基于样本向量vyi计算指标测量参考值函数h的值,如以下公式(4)所示:
hi=h(vyi)=h(yi,1,yi,2,...,yi,s)(4)
其中,h表示对测量模型yi所代表的概率密度函数取中位数或者取平均值;优选地,h表示取中位数,此时,得到的结果h也是一个概率密度函数,其表示所有指标的测量模型的中位数(或者平均值)的分布。
子步骤43:根据指标测量参考值函数h的值,建立指标测量参考值函数h的离散模型gh,指标测量参考值函数的概率密度函数为gh。
基于子步骤42中计算的指标测量参考值函数h的值,即可建立指标测量参考值函数h的离散模型gh,指标测量参考值函数的概率密度函数记为gh。
概率密度函数gh的期望值表示所有指标测量结果的测量参考值(中位数或平均值),方差表示该测量参考值代表的测量结果的不确定程度。下面,需要确定每个指标与该测量参考值的差值,以及这个差值的不确定程度。
子步骤44:将理论计算的期望值和方差与子步骤43中获得的概率密度函数gh的期望值和方差分别进行比较,以监测其模拟情况。
理论计算的方法为:概率密度函数的期望值为所有指标对应的
步骤5:建立概率密度函数
具体地,步骤5包括以下子步骤:
子步骤51:分别针对每个指标mi,建立测量模型yi与指标测量参考值函数h的差值的函数qi,其中i=1,…,n:
qi=yi-h(5)
子步骤52:分别针对每个指标mi,基于对p个输入量x1,…,xj,…,xp进行每一次随机赋值所计算的测量模型yi所服从的分布的期望值和方差,计算函数qi的值qi,t,如公式(6)所示,其中,t=1,…,s:
qi,t=yi,t-hi(6)
基于公式(6)的计算结果,对于每个指标,可以分别建立其综合测量值与指标测量参考值函数的差值的函数的离散模型gqi,其概率密度函数记为gqi。
子步骤53:建立所有函数qi(其中,i=1,…,n)的中位数或平均值函数c,即:
c=h(q1,q2,...,qi,...,qn)(7)
对于每一次随机赋值,基于函数qi的值qi,t计算中位数或平均值函数c的值,即:
ct=h(q1,t,q2,t,...,qi,t,...,qn,t)(8)
从而可以获得中位数或平均值函数c的概率密度函数gc,中位数或平均值函数c即指标选择参考值函数。
概率密度函数gc的期望值diffref-m为所有e(gq1),...,e(gqi),...,e(gqn)的中位数。期望值反映了专家系统对指标的测量值与指标测量参考值之间的偏离程度。概率密度函数gc的方差反映了偏离程度的波动范围。通过步骤5可以获得每个指标的测量与参考值之间的差异,以及该差异的不确定程度,进而可以得到鲁棒性更好的指标选择参考值。
步骤6:对于每个指标,分别建立其概率密度函数
具体地,步骤6包括以下子步骤:
子步骤61:对于每个指标,分别建立函数qi,,和函数c之间的关系模型di=qi-c,其中i=1,…,n。
子步骤62:对于每个指标,对于t=1,…,s,分别计算关系模型di的值,如以下公式(8)所示:
di,t=qi,t-ct(9)
基于公式(9)的计算结果,对于每个指标,可以分别建立关系模型di的概率密度函数gdi,通过概率密度函数gdi可以计算每个指标的合理性期望值e(gdi)及标准偏差σ(gdi)。
子步骤63:针对每个指标,根据其对应的概率密度函数gdi合理性期望值判断指标的合理性。
对于指标mi,如果其对应的概率密度函数gdi的合理性期望值e(gdi)>0,则表示指标经过专家系统测量满足合理性要求,合理性扩展不确定程度为2σ(gdi),置信概率为95.45%;如果其对应的概率密度函数gdi的合理性期望值e(gdi)≤0,则表示指标经过专家系统测量不满足合理性要求,不合理性扩展不确定程度为2σ(gdi),置信概率为95.45%。不满足合理性要求的指标不能用于评价被评价对象。
步骤7:对指标决策结果进行显著性检验。
具体地,步骤7包括以下子步骤:
子步骤71:建立关系模型di的中位数函数o,即:
o=h(d1,d2,...,di,...,dn)(9)
其中,h表示取中位数。
子步骤72:对于每一次随机赋值,基于关系模型di的值di,t计算中位数函数o的值,如以下公式(10)所示:
ot=h(d1,t,d2,t,...,di,t,...,dn,t)(10)
其中,t=1,…,s;
根据中位数函数o的值可以获得中位数函数o的离散模型go,并将中位数函数o的概率密度函数记为go。
子步骤73:通过卡方测试确定异常分布。具体地,首先构建检验函数
其中,自由度v=n-1;e(gdi)和σ(gdi)分别为指标mi的合理性期望值和标准偏差;e(go)为指标mi的中位数函数o的期望值。
然后,根据自由度v和第一显著性水平α(例如为95%),从
实施例
在示例性实施例中,利用上述的指标决策方法进行指标决策,具体包括以下步骤:
步骤1:根据被评价对象的属性建立指标系统m。
被评价对象具有8个属性,这些属性的指标分别记为m1,m2,m3,…,mi,…,m7,m8,指标系统m可记为m{m|m1,m2,m3,...,mi,...,m7,m8}。
步骤2:组建包含10个专家系统的专家集合,根据每个专家系统对指标系统m中的每个指标的合理性测量的结果,建立专家系统测量函数。
在本实施例中,测量依据系数ca和熟悉程度系数cs均为1,调控因子λ=0。每个专家系统对每个指标进行合理性测量的结果如下表1所示:
表1专家系统对指标的合理性测量结果
步骤3:分别建立专家集合对于每个指标的测量结果的概率密度函数
首先,对于每个指标,根据公式(2)和(3)计算p个输入量的平均值
表2平均值
然后,对每个指标进行10000次随机赋值,从而可以得到每个测量模型的概率密度函数,其服从正态分布。通过多次的随机赋值,使得模拟得到的平均值与
表3平均值和方差结果
通过步骤3,将专家集合对于每个指标的测量结果以概率密度函数的方式表示。
步骤4:建立指标测量参考值函数的概率密度函数gh。
具体地,在步骤3中已经得到了各个指标的测量模型的概率密度函数,在本步骤中,可利用公式(4)直接对概率密度函数取中位数,即可得到指标测量参考值函数的概率密度函数gh,如图3所示。该概率密度函数的期望值
最后,将理论计算结果与模拟的结果进行比较,以监测模拟情况。具体地,计算所有指标对应的
步骤5:建立概率密度函数
具体的,根据子步骤51和子步骤52建立函数qi,获得其概率密度函数的平均值和方差如表4所示,图4-1至图4-8分别示出了对应于指标m1至m8与指标测量参考值函数的差值的概率密度函数示意图:
表4函数qi的概率密度函数的平均值和方差
然后,根据子步骤53建立所有函数qi的中位数函数c,其概率密度函数gc如图5所示。
步骤6:对于每个指标,分别建立概率密度函数
具体地,执行子步骤61和子步骤62,得到关系模型di的值、合理性期望值e(gdi)及方差σ2(gdi),如表5所示,然后根据子步骤63判断每个指标的合理性,在本实施例中,m1、m2、m4合理性期望值大于零,指标合格;m3、m5、m6、m7、m8合理性期望值小于零,指标不合格。
表5关系模型di的平均值和方差
步骤7:对指标决策结果进行显著性检验。具体地,对关系模型di的中位数函数o进行数值模拟,得到o所服从分布的期望值e(go)。进行卡方检验的计算表格如下表6:
表6卡方检验计算表格
其中,自由度v=n-1=7,在临界值表中查得95%的置信度水平时临界值为14.0671,而检验函数值
本发明实施例还提出一种计算机可读存储介质,其上存储有计算机程序,其中,所述程序被处理器执行时实现以下步骤:
步骤1:根据被评价对象的属性建立指标系统m;
步骤2:组建包含多个专家系统的专家集合,根据每个专家系统对指标系统m中的每个指标的合理性测量结果,建立专家系统测量函数;
步骤3:分别建立专家集合对于每个指标的测量结果的概率密度函数
步骤4:建立指标测量参考值函数的概率密度函数gh;
步骤5:建立概率密度函数
步骤6:对于每个指标,分别建立概率密度函数
优选地,所述被评价对象具有n个属性,这些属性的指标分别记为m1,m2,m3,…,mi,…,mn-1,mn,m为m{m|m1,m2,m3,...,mi,...,mn-1,mn}。
优选地,所述专家系统测量函数为ei,j,如以下公式(1)所示:
ei,j(ei,j,ca,j,cs,j)=λ·ei,j·(ca,j+cs,j)/2,0<λ≤1
ei,j(ei,j,ca,j,cs,j)=ei,j,λ=0(1)
其中,λ为调控因子,ei,j、ca,j、cs,j分别表示专家系统ej对指标系统m中的指标mi进行合理性测量给出的打分结果、测量依据系数、熟悉程度系数,其中,i=1,…,n,j=1,…,p,p为专家系统的数量。
优选地,所述步骤3包括:
子步骤31:对于每个指标mi,将专家集合中的所有专家系统对于指标mi的测量模型定义为yi;
子步骤32:对于每个指标mi,确定测量模型yi的p个输入量x1,…,xj,…,xp,其分别对应于各专家系统对指标mi的测量结果eλi,1,…,eλi,j,…,eλi,p,其中eλi,j表示专家系统测量函数ei,j的值,分别根据以下公式(2)和(3)计算p个输入量的平均值
其中,
子步骤33:对于每个指标mi,以其对应的平均值
优选地,所述步骤4包括:
子步骤41:对于指标mi,其中i=1,…,n,建立样本向量vyi=(yi,1,yi,2,...,yi,s),其中yi,t(t=1,…,s)表示在子步骤33中对p个输入量x1,…,xj,…,xp进行第t次随机赋值后的测量模型yi的期望值和方差;
子步骤42:对于i=1,…,n,分别基于样本向量vyi计算指标测量参考值函数h的值,如以下公式(4)所示:
hi=h(vyi)=h(yi,1,yi,2,...,yi,s)(4)
其中,h表示对测量模型yi所代表的分布函数取中位数或者取平均值;子步骤43:根据指标测量参考值函数h的值,建立指标测量参考值函数h的概率密度函数为gh;同时建立指标测量参考值函数h的离散模型gh;
子步骤44:将理论计算的期望值和方差与子步骤43中获得的概率密度函数gh的期望值和方差分别进行比较。
优选地,所述步骤5包括:
子步骤51:分别针对每个指标mi,建立测量模型yi与指标测量参考值函数h的差值的函数qi,其中i=1,…,n:
qi=yi-h(5)
子步骤52:分别针对每个指标mi,基于对p个输入量x1,…,xj,…,xp进行每一次随机赋值所计算的测量模型yi所服从的分布的期望值和方差,计算函数qi的值qi,t,如公式(6)所示,其中,t=1,…,s:
qi,t=yi,t-hi(6)
子步骤53:建立所有函数qi的中位数或平均值函数c,其中,i=1,…,n,即:
c=h(q1,q2,...,qi,...,qn)(7)
以及,对于每一次随机赋值,基于函数qi的值qi,t计算中位数或平均值函数c的值,即:
ct=h(q1,t,q2,t,...,qi,t,...,qn,t)(8)
从而获得中位数或平均值函数c的概率密度函数gc,中位数或平均值函数c即指标选择参考值函数。
优选地,所述步骤6包括:
子步骤61:对于每个指标,分别建立函数qi,,和函数c之间的关系模型di=qi-c,其中i=1,…,n;
子步骤62:对于每个指标,对于t=1,…,s,分别计算关系模型di的值,如以下公式(8)所示:
di,t=qi,t-ct(9)
基于公式(9)的计算结果,对于每个指标,可分别建立关系模型di的概率密度分布函数gdi,通过概率密度分布函数gdi可以计算每个指标的合理性期望值e(gdi)及标准偏差σ(gdi);
子步骤63:针对每个指标,根据概率密度函数gd的合理性期望值判断所述指标的合理性。
优选地,所述指标决策方法还包括:
步骤7:对指标决策结果进行显著性检验。
优选地,所述步骤7包括:
子步骤71:建立关系模型di的中位数函数o,即:
o=h(d1,d2,...,di,...,dn)(9)
子步骤72:对于每一次随机赋值,基于关系模型di的值di,t计算中位数函数o的值,如以下公式(10)所示:
ot=h(d1,t,d2,t,...,di,t,...,dn,t)(10)
根据中位数函数o的值获得中位数函数o的离散模型go,并将中位数函数o的概率密度函数记为go;
子步骤73:通过卡方测试确定异常分布,包括:
构建检验函数
其中,自由度v=n-1;
根据自由度v和第一显著性水平α,从
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!