一种基于联合分布函数的综合干旱指数的制作方法
本发明属于水文水资源领域,涉及一种基于联合分布函数的综合干旱指数。
背景技术:
随着全球气候变暖,旱涝灾害发生频率逐步升高,干旱研究刻不容缓。干旱指数是研究干旱的基础和重要手段,可以用来监测、预防干旱。干旱可以分为气象干旱、水文干旱、农业干旱、社会经济干旱等不同类型,相应有各自不同类型的干旱指数。然而,不同类型干旱的发生与结束时间并不相同,单一变量的干旱指数不能很好的指导决策者做出可靠有效的决策。因此,需要发展一种能综合表征不同类型干旱的综合干旱指数,以期更好的表征干旱,更敏感的捕捉干旱的发生与结束。
现有的采用熵权法赋权和模糊综合法将pdsi、spi和spei3种指数结合在一起,研制出的模糊综合评价指数di在赋权时存在一定主观性,极易造成误差;基于主成分分析法构建的融合降雨、径流及土壤含水量等水文气象要素的综合干旱指数prsm无法反映变量间的非线性影响特征。
技术实现要素:
本发明的目的在于提供一种基于联合分布函数的综合干旱指数,能够灵敏、有效的监测或预测干旱信息。
本发明所采用的技术方案是:一种基于联合分布函数的综合干旱指数,
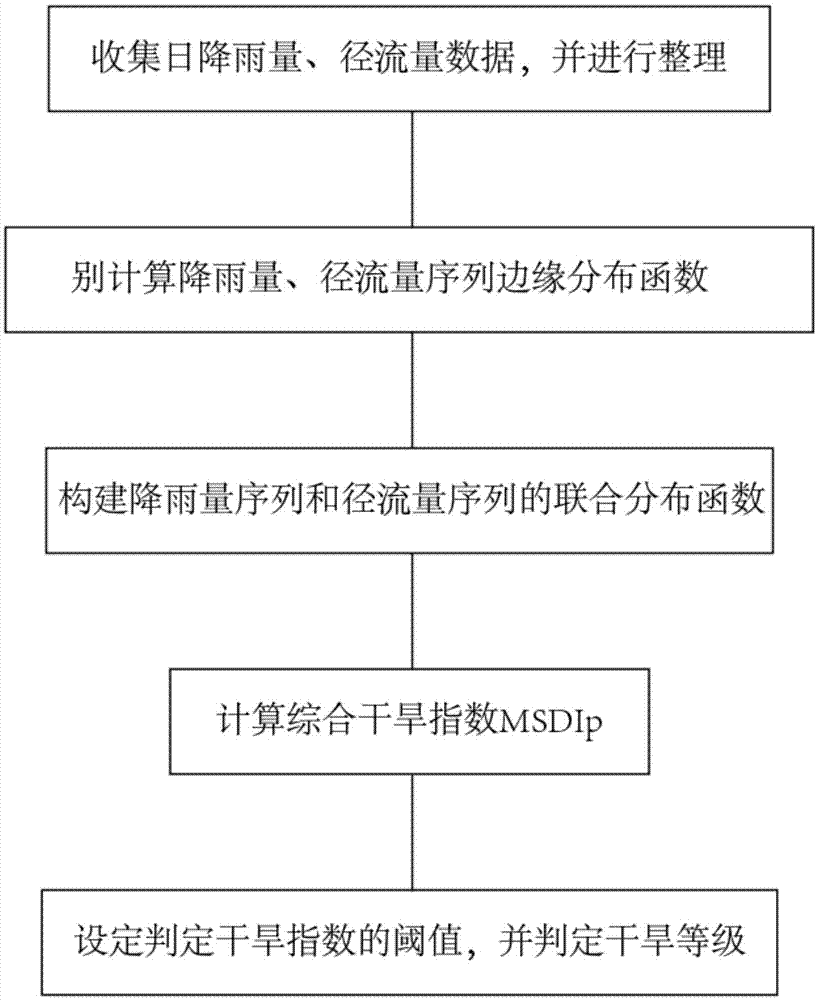
步骤一:收集流域内的日降雨量数据和径流量数据;
步骤二:分别计算降雨量序列边缘分布函数、径流量序列边缘分布函数;
步骤三:构建降雨量序列和径流量序列的联合分布函数;
步骤四:计算综合干旱指数msdip;
步骤五:设定判定干旱指数的阈值,根据步骤四得到的综合干旱指数msdip与干旱指数阈值比较判定是否发生及干旱的等级。
本发明的特点还在于,
步骤一中选取日降雨量大于1.0mm的降雨量数据,将流域内选取的降雨量数据处理成流域面降雨量,在将流域面降雨量序列按各月的日降雨量数据进行加和,得到月总降雨量,转化为月尺度的总降雨量尺度数据,再按时间顺序排列;
步骤一中将各月的径流量数据进行加和,得到月总径流量,转化为月尺度径流量数据,再按时间顺序排列。
步骤一流域面降雨量计算公式为:
式中,fi为第i个气象站所在多边形的面积,f为流域总面积。
步骤二中,设降雨量序列共有n项,按由小到大的顺序排列为x1≦x2…≦xi…≦xn,则序列中小于等于xi的出现次数为i,降雨量序列边缘分布函数计算公式为:
设径流量序列共有m项,按由小到大的顺序排列为y1≦y2…≦yk…≦ym,则序列中小于等于yk的出现次数为k,径流量序列边缘分布函数计算公式为:
式中,降雨量序列、径流量序列长度一致,即n=m。
步骤三中,降雨量序列、径流量序列联合分布函数计算公式为:
h(x,y)=c(f(x),g(y))(4)
其中f为降雨量序列随机变量x边缘分布函数,g为径流量序列随机变量y的边缘分布函数,h为降雨量序列、径流量序列联合分布函数;则对
公式(4)中copula函数c的计算公式为:
生成元为:
其中,u为降雨量序列变量的边缘累积概率即∫f(x),v径流量变量的边缘累积概率即∫g(y);θ为参数。
公式(5)和公式(6)中θ可以由kendall秩相关系数τ求得:
一阶德拜函数d1(θ)表达式为:
其中公式(7)中可求得相关系数τ,结合公式(5)和公式(6)得到copula函数c。
步骤四中,降雨量的边缘分布函数为f(x),径流量的边缘分布函数为g(y),则降雨量、径流量的累积联合概率p可用联合分布p和copula函数c表示为:
p(x≤x,y≤y)=c[f(x),g(y)]=p(9)
将p标准正态化得到σ(p),由联合分布函数可得综合干旱指数(msdip):
msdip=σ-1(p)(10)
式中,σ为标准正态分布。
步骤五中,设判定干旱发生的干旱指数的阈值为-1;当msdip<-1时,则发生干旱;msdip<-1.5时,则干旱较为严重;msdip<-2时,则干旱极为严重。
本发明的有益效果是:本发明的基于联合分布函数的综合干旱指数,选取降雨量、径流量两种变量,分别计算降雨量、径流量的边缘分布函数,采用降雨量序列和径流量序列联合概率分布,构建出综合干旱指数msdip。本发明的一种基于联合分布函数的综合干旱指数,具有可靠性、灵敏性和综合性等优点,能够捕捉干旱开始和结束,更加综合、全面的识别干旱,提前发出预警,为干旱的监测、防治乃至预报提供可靠、有力的支持。
附图说明
图1是本发明一种基于联合分布函数的综合干旱指数的流程图;
图2是本发明一种基于联合分布函数的综合干旱指数泰森多边形法示意图;
图3是本发明一种基于联合分布函数的综合干旱指数的降雨量时间序列折线图;
图4是本发明一种基于联合分布函数的综合干旱指数的径流量时间序列折线图;
图5是本发明一种基于联合分布函数的综合干旱指数的渭河流域月尺度下1960-2010年spi指数、sri指数、msdi指数对比图;
图6是本发明一种基于联合分布函数的综合干旱指数的渭河流域月尺度下1972-1980年spi指数、sri指数、msdi指数对比图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明提供了一种基于联合分布函数的综合干旱指数,如图1所示,步骤一:收集流域内的日降雨量数据和径流量数据;步骤二:分别计算降雨量序列边缘分布函数、径流量序列边缘分布函数;步骤三:构建降雨量序列和径流量序列的联合分布函数;步骤四:计算综合干旱指数msdip;步骤五:设定判定干旱指数的阈值,根据步骤四得到的综合干旱指数msdip与干旱指数阈值比较判定判定是否发生及干旱的等级。
本发明提供了一种基于联合分布函数的综合干旱指数,
步骤一:收集流域内的日降雨量数据(mm)和径流量(m3/s)数据。
首先,从中国气象网搜集所研究流域内各个气象站的一定时段内(如:1960–2010年)的日降雨量数据,选取降雨量大于1.0mm的数据;搜集所研究流域内包括主要干流和支流上的多个水文站的日径流序列。
如图2所示,由于降雨数据来源于多个气象测站,需要按照泰森多边形法处理成流域面雨量。该方法的原理是将流域内及其附近的气象站用直线连接构成若干三角形,而后对各连线做垂直平分线,连接垂线的交点,得到若干个多边形,流域边界处的多边形以流域边界为界。各个多边形内各有一个气象站,以每个多边形内气象站的降雨量代表该多边形面积上的降雨量,最后按照面积加权推求流域面降雨量。
流域面降雨量计算公式为:
式中,fi为第i个气象站所在多边形的面积,f为流域总面积。
其次,径流量数据则直接从流域控制断面所在水文测站中获取。
最后,如图3所示,流域面的降水量序列进行整合。将流域面降雨量序列按各月的日降雨量数据进行加和,得到月总降雨量,转化为月尺度的总降雨量尺度数据,再按时间顺序排列。
如图4所示,控制断面径流量序列进行整合。将各月的径流量数据进行加和,得到月总径流量,转化为月尺度径流量数据,再按时间顺序排列。
步骤二:分别计算降雨量序列边缘分布函数、径流量序列边缘分布函数。采用gringorten公式计算经验频率,并以此作为边缘分布。
设降雨量序列共有n项,按由小到大的顺序排列为x1≦x2…≦xi…≦xn,则序列中小于等于xi的出现次数为i,降雨量序列边缘分布函数计算公式为:
设径流量序列共有m项,按由小到大的顺序排列为y1≦y2…≦yk…≦ym,则序列中小于等于yk的出现次数为k,径流量序列边缘分布函数计算公式为:
式中,降雨量序列、径流量序列长度一致,即n=m。
步骤三:构建降雨量序列和径流量序列的联合分布函数。采用阿基米德copula函数中的frankcopula函数作为边缘分布函数的连接工具。copula函数能够构造不同边缘分布的多个变量的联合分布函数。在众多copula家族中,阿基米德copula应用范围最为广泛。其中,frankcopula函数在干旱研究中有较多应用。
根据sklar定理,步骤三中,降雨量序列、径流量序列联合分布函数计算公式为:
h(x,y)=c(f(x),g(y))(4)
其中f为降雨量序列随机变量x边缘分布函数,g为径流量序列随机变量y的边缘分布函数,h为降雨量序列、径流量序列联合分布函数;则对
frankcopula函数最早由frank于1979年提出,可以用来描述对称相关结构,上下尾相关性变化均不明显。copula函数c的计算公式为:
生成元为:
其中,u为降雨量序列变量的边缘累积概率即∫f(x),v径流量变量的边缘累积概率即∫g(y)。
θ为参数,可以由kendall秩相关系数τ求得:
一阶德拜函数d1(θ)表达式为:
利用matlab软件语句:cor(x,y,method="kendall")即可计算出kendall秩相关系数,继而得出参数θ,最后得到copula函数c。
步骤四:计算综合干旱指数msdip。
降雨量的边缘分布函数为f(x),径流量的边缘分布函数为g(y),则降雨量、径流量的累积联合概率p可用联合分布p和copula函数c表示为:
p(x≤x,y≤y)=c[f(x),g(y)]=p(9)
将p标准正态化化得到σ(p),则由联合分布函数可得综合干旱指数(msdip):
msdip=σ-1(p)(10)
式中,σ为标准正态分布。降雨量x、径流量y这两个序列里,当x、y取不同的值的时候,联合分布概率p。
步骤五:设定判定干旱发生的干旱指数的阈值,根据步骤四得到的综合干旱指数msdip与干旱指数阈值比较判定是否发生及干旱的等级。
参考标准化降雨指数spi的干旱等级划分对综合干旱指数进行了等级划分,结果如下表:
表1msdip干旱等级划分
通过前4个步骤计算出msdip值后,对照表1,可对干旱事件进行判定。考虑到干旱严重程度及所造成影响的强弱程度,推荐以-1作为判定干旱发生的阈值。即,当msdip<-1时,则认为发生了干旱;msdip<-1.5时,则认为干旱较为严重;msdip<-2时,则认为干旱极为严重。为更直观的体现,可将计算得到的msdip序列做成折线图,以纵坐标-1做一条水平线,低于这条水平线的部分则可认为是发生了干旱。
对比例:
分析渭河流域干旱时空演变特征,采用月尺度下的spi(标准化降水指数)、sri(标准化径流指数)和msdip指数。
如图5所示,尺度下的渭河流域全流域1960—2010年的spi指数、sri指数和msdip指数。由图5可知,月尺度下msdip指数的走势、变化规律与spi指数和sri指数有较好的一致性。msdip指数与spi指数、sri指数的pearson相关系数均在0.8以上,呈极强相关,且通过了95%的置信度检验,说明新构造的msdip指数具有较高的可靠性。
如图6所示,为进一步作更直观的比较,截取1972至1982年月尺度下的spi指数、sri指数和msdip指数变化情况。将横坐标放大,可以看出3种指数的一些差异。一般认为,干旱的开始通常是由于降雨的持续缺乏,因此spi指数对于捕捉干旱的开始非常灵敏;而由于复杂的产汇流过程,水文干旱对气象干旱的响应存在一定的延迟,因此sri指数能有效识别干旱的持续时间和结束。如图6中黑色矩形框所示,msdip和spi指数小于-1的时刻(认为是干旱发生的开始)相对sri指数来说要早,这表明msdip指数捕捉干旱开始的能力与spi指数相当。同时,msdip和sri指数大于-1的时刻(认为是干旱发生的结束)相对spi指数来说要迟,这表明msdip指数捕捉干旱结束的能力与sri指数相当。这是因为,spi指数以气象干旱特征为主要参考,而气象干旱发展突然、迅速;sri指数以水文干旱特征为基准,而水文干旱存在相当的延迟且持续时间较长。图中黑色矩形框内显示,msdip指数能够将spi指数和sri指数所捕捉的干旱开始与结束都含括在内。msdip指数能够如spi指数一样很好的捕捉到干旱的开始,也能如sri指数一样很好的捕捉到干旱的持续时间和结束,同时具有二者的优点。此外,由图中第二个矩形框内3种指数变化情况可以看出,只发生了水文干旱而气象干旱未发生的情况下,msdip指数同样捕捉到了干旱的发生。这些结果有力地证明了msdip指数综合了降雨径流两种信息,能够灵敏、有效的捕捉干旱发生的开始、持续时间、结束。
由图5中msdip指数年际变化可知,1972年至1982年左右,干旱发生较为频繁,且干旱等级较高,同样的还有1995年至2007年左右。查阅渭河流域干旱相关文献资料,发现本发明的综合干旱指数msdip指数捕捉到的干旱与有历史记载、文献支持的干旱事件能够相吻合,这说明新构造的msdip指数具有一定的准确性。本发明一种基于多变量的用于捕捉干旱的指数方法,避免了联合分布函数各边缘分布不同的问题、赋权法产生的主观性误差和主成分分析法对非线性关系失真等多种弊端,能够较好的综合表征气象与水文干旱,具有以往干旱指数所没有的优越性。与相比,pdsi、spi和spei3种指数相比可以用来较好的捕捉干旱、描述干旱特征。综合干旱指数msdip能综合表征气象干旱和水文干旱的联合特征,提高综合干旱指数的准确性和适用性,以期为决策者监测、预防干旱提供有力支持。
通过上述方式,本发明的一种基于联合分布函数的综合干旱指数,选取降雨量、径流量两种变量,分别计算降雨量、径流量的边缘分布函数,采用降雨量、径流量联合概率分布,构建出综合干旱指数msdip计算公式。本发明的一种基于多变量的用于捕捉干旱的指数方法,具有可靠性、灵敏性和综合性等优点,能够捕捉干旱开始和结束,更加综合、全面的识别干旱,提前发出预警,为干旱的监测、防治乃至预报提供可靠、有力的支持。
- 还没有人留言评论。精彩留言会获得点赞!