一种基于深度学习的动词短语省略消解方法与流程
本发明属于计算机人工智能技术领域,具体涉及一种基于深度学习的动词短语省略消解方法。
背景技术:
聊天机器人是一种利用自然语言处理技术来模拟人类交流并和人类进行对话的计算机程序。聊天机器人的起源最早可以追溯到1950年图灵在《mind》上发表的文章《computingmachineryandintelligence》,该文提出了经典的“图灵测试”(turingtest),这一测试数十年来一直被视为计算机人工智能的终极目标。在聊天机器人中,多轮对话聊天是一个核心模块。动词短语省略是省略了口头组成部分的照应性结构。在英语中,动词短语省略的实例由两部分组成:触发词和先行短语。触发词,通常是辅助或模态动词,表示动词短语省略现象的存在。先行短语,是被消解元素指代的动词短语(bos和spenader,2011;dalrymple等人,1991)。例如,“thegovernmentincludesmoneyspentonresidentialrenovation;dodgedoesnot”,触发词“does”指代的是先前的短语“includesmoneyspentonresidentialrenovation”。
动词短语省略消解对于对话任务特别重要,例如在非正式的对话中,动词短语省略经常出现。大多数当前的对话系统忽略动词短语省略,并通过从句子的浅层依赖分析中读取信息来派生出一些结构化的语义表示。这种方法不仅会漏掉消岐动词及其参数之间的许多有效联系,而且如果直接应用于辅助触发词,也可能产生无意义的提取。在上面的例子中,一个不完善的方法可能会产生一个无益的语义三元组,如(dodge,agent,do)。
目前已经有一些关于动词短语省略的实证研究(hardt,1997;nielsen,2005;bosandspenader,2011;bos,2012;liuetal.,2016)。但是许多先前的方法仅限于解决动词短语省略的特定子类问题。例如,由do触发的动词短语省略(bos,2012),或者依靠简单的启发式方法来解决动词短语省略消解问题,例如通过选择最近的触发词之前的从句来作为先行短语。(kianetal.2016)开发了一个动词短语省略消解流水线,将任务分成两个步骤。第一步,检测是否存在动词短语省略,并且找出触发词;第二步,先行短语识别,识别出包含先行短语的从句以及确定先行短语的确切边界(边界往往难以界定)。(kianetal.2016)将早期工作中丰富的语言学分析和margin-infused-relaxed-algorithm运用到动词短语省略消解中,并且将动词短语省略消解任务分成了两步:检测是否存在动词短语省略,并找出触发词和识别先行短语,但他们只是使用了简单的机器学习方法,触发词判断和先行短语识别的准确率较低。
技术实现要素:
本发明的目的是为解决现有动词短语省略消解方法中存在的触发词判断和先行短语识别准确率低的问题。
本发明为解决上述技术问题采取的技术方案是:
一种基于深度学习的动词短语省略消解的方法,该方法的具体步骤为:
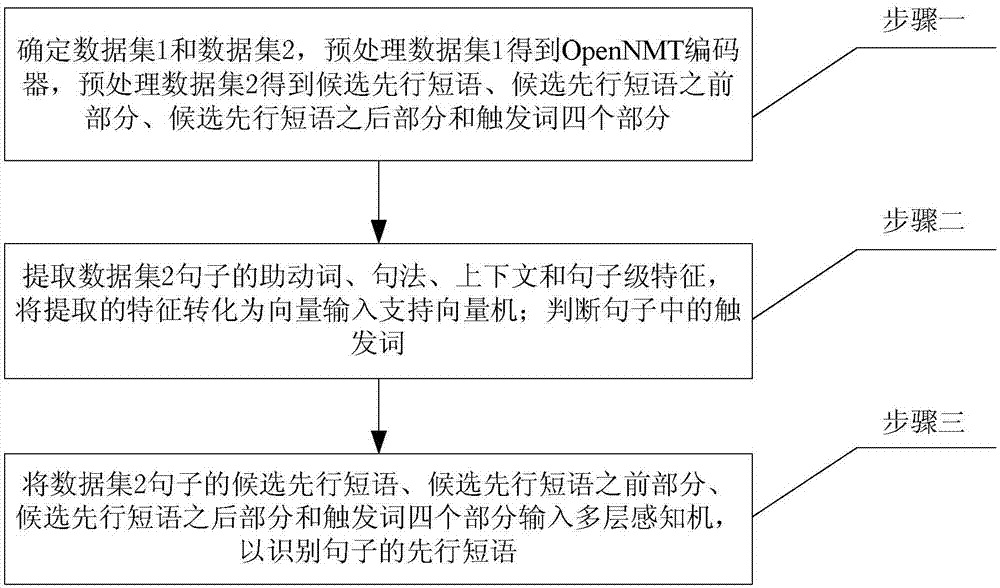
步骤一、确定数据集1和数据集2中包含的句子;
对数据集1中句子进行预处理时,得到opennmt编码器;
对数据集2中句子进行预处理时,将每个句子中的各动词短语和形容词短语依次作为该句的候选先行短语,对应的将该句分成候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词四个部分;
步骤二、提取数据集2句子的助动词特征、句法特征、上下文特征和句子级特征,并将提取特征转化为标明正例和负例的输入向量;支持向量机对所述输入向量分类,根据支持向量机的输出结果判断句子的触发词;
步骤三、将数据集2句子的候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词四个部分输入多层感知机;
多层感知机使用opennmt编码器获取候选先行短语、候选先行短语之前部分和选先行短语之后部分的句子级向量表示,使用字级别表示词向量模型得到触发词的字级别向量表示,以识别动词短语省略现象中的先行短语。
本发明的有益效果是:本发明提供了一种基于深度学习的动词短语省略消解的方法,本发明对确定好的数据集1和数据集2中的句子分别进行预处理过程,在现有方法的基础上,本发明加入了对句子上下文特征和句子级特征的提取,将提取的句子特征转化为向量输入支持向量机,进而根据支持向量机的输出结果确定输入句子的触发词;最后将输入句子的候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词四个部分输入多层感知机来识别动词短语省略现象中的先行短语。本发明提取句子特征时加入了上下文特征和句子级特征,可以使触发词判断的准确率达到90%左右,先行短语识别的准确率达到85%以上。
本发明对存在动词短语省略现象句子的触发词的判断和先行短语的识别的准确率提高起到很好的作用。
附图说明
图1为本发明所述的一种基于深度学习的动词短语省略消解的方法流程图;
图2为本发明所述的将句子分成先行短语、先行短语之前部分、先行短语之后部分和触发词的一个英文示例;
图3为本发明所述的识别先行短语模型的工作示意图;
图4为本发明向量相加方法的示意图;
图5为本发明递归神经网络方法的示意图;
其中,hq是opennmt编码器最后一个时刻的隐层输出;
图6为本发明含有注意力机制的递归神经网络方法的示意图;
其中
具体实施方式
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
具体实施方式一:本实施方式所述的一种基于深度学习的动词短语省略消解的方法,该方法的具体步骤为:
步骤一、确定数据集1(penntreebank2wallstreetjournal)和数据集2(anannotatedcorpusfortheanalysisofvpellipsisbyjohanbosandjenniferspenader)中包含的句子;
对数据集1中句子进行预处理时,得到opennmt编码器;
对数据集2中句子进行预处理时,将每个句子中的各动词短语和形容词短语依次作为该句的候选先行短语,对应的将该句分成候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词四个部分;
步骤二、提取数据集2句子的助动词特征、句法特征、上下文特征和句子级特征,并将提取特征转化为标明正例和负例的输入向量;支持向量机对所述输入向量分类,根据支持向量机的输出结果判断句子的触发词;
步骤三、将数据集2句子的候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词四个部分输入多层感知机;
多层感知机使用opennmt编码器获取候选先行短语、候选先行短语之前部分和选先行短语之后部分的句子级向量表示,使用字级别表示词向量模型得到触发词的字级别向量表示,以识别动词短语省略现象中的先行短语。
本实施方式中的数据集1主要用来得到opennmt编码器和字级别表示词向量模型,然后利用opennmt编码器来获取候选先行短语、候选先行短语之前部分和候选先行短语之后部分的句子级向量表示;利用字级别表示词向量模型得到触发词的字级别向量表示。
在现有技术的基础上,对输入句子特征提取时加入了上下文特征和句子级特征,上下文特征用来判断助词和动词;句子级特征用来判断整句是否含有以下结构;
上下文特征如下:
◇当前词是否是触发词常见词
◇当前词的前面第3个词的词性
◇当前词的前面第2个词的词性
◇当前词的前面第1个词的词性
◇当前词的词性
◇当前词的后面第1个词的词性
◇当前词的后面第2个词的词性
◇当前词的后面第3个词的词性
◇当前词前一个词是否是触发词前一个词常出现的词
◇当前词后一个词是否是触发词后一个词常出现的词
句子级特征如下:
◇,/.so/so/or/nor/but/while[xxx]do/to/did/does◇as[xxx]were/do/does/did
◇than[xxx]do/is/had/has
◇,/.have[xxx],/.
◇[xxx]wasn’t/would/do/might/haveto[xxx],/.
◇从句allthe/theway/that/who/and[xxx]does/will/can
◇thesame[xxx]do
◇doing/do[xxx]thesame/so◇ifitis/does/isn’t
具体实施方式二:本实施方式对实施方式一所述的一种基于深度学习的动词短语省略消解的方法进行进一步的限定,步骤一的数据集2(anannotatedcorpusfortheanalysisofvpellipsisbyjohanbosandjenniferspenader)中的数据由johanbos和jenniferspenader提供先行短语和触发词标注,且数据集2中的句子均存在动词短语省略现象。
本实施方式中的数据集2中的句子均存在动词短语省略现象,以用于训练步骤二的触发词判断模型和步骤三的先行短语识别模型。其中johanbos和jenniferspenader为数据集2出自的英文文献(anannotatedcorpusfortheanalysisofvpellipsisbyjohanbosandjenniferspenader)的作者的名字。
具体实施方式三:本实施方式对实施方式二所述的一种基于深度学习的动词短语省略消解的方法进行进一步的限定,本实施方式中的步骤一对数据集1和数据集2进行预处理的过程为:
利用nltk工具中的word_tokenize对数据集1中句子进行分词处理;利用opennmt-py训练数据集1的分词处理结果,得到opennmt编码器;
所述opennmt编码器有两个输出,其中一个输出为最后一个词对应的隐层状态输出,另一个输出为每个词对应的隐层状态输出;
提取johanbos和jenniferspenader标注后的数据集2,利用bioest对提取的数据集2中每个句子进行标注,并将每个标注句子分成先行短语、先行短语之前部分、先行词短语之后部分和触发词四个部分,将先行短语、先行短语之前部分、先行词短语之后部分和触发词作为对应句子的正例;
利用berkeleyparser对标注后数据集2的句子语法分析处理,得到每个句子对应的语法树,采用nltk工具的tree方法提取每棵语法树的语法结构,抽取每个句子的所有动词短语和形容词短语,以分别作为对应句子的候选先行短语,将对应句子分成候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词四个部分,并将其中与正例不同的情况作为负例。
数据集2中的数据为500句,数据集1中的数据量为49174句,以避免影响实验效果。由于opennmt验证集输入通常不超过5000句,本项技术对所有句子进行了10折交叉验证训练,最终得到了10个opennmt编码器,本发明对opennmt开源代码进行修改,使之能够输出句子的中间表示而不是目标语言。如图2所示,为本发明将句子分成先行短语、先行短语之前部分、先行短语之后部分和触发词四个部分的一个英文示例图。
bioest标注方法如下:将触发词标注为t(trigger),对于先行短语只有一个词的情况,将其标注为s(single);否则用bie来标注先行短语,即开始的第一个词标注为b(begin),最后一个词标注为e(end),中间的词标注为i(in)。除触发词和先行短语之外的词标注为o(other)。
具体实施方式四:本实施方式对实施方式三所述的一种基于深度学习的动词短语省略消解的方法进行进一步的限定,本实施方式中的步骤二判断数据集2中句子的触发词的具体过程为:
将数据集2的每个句子中所有动词和常见触发词依次作为该句的当前词,对应的分别提取该句子的助动词特征、句法特征、上下文特征和句子级特征,以得到对应的31维长度的向量作为x值,数据正例和负例标签作为y值,即若当前词为预处理过程中标注的触发词,则y值为1,否则y值为0;将(x,y)作为输入向量输入支持向量机;
利用python的random库将输入向量(x,y)的集合随机分成5份,其中4份作为训练集数据,1份作为测试集数据;
将svc的核函数设置为kbf,使用svc的fit方法拟合训练集数据,获得训练后的svc模型clf,调用clf的predict方法,得到测试集数据的预测标签y’,调用sklearn的classification_report方法,利用测试数据的真实标签y和预测的标签y’作为参数,通过精确率、召回率和f1值评价模型,经过训练测试确定svc的最佳参数为核函数设置为kbf、c值设置为100、gamma值设置为0.5;
若支持向量机输出的分类结果为1,则表示对应句子的触发词就是当前词;若支持向量机输出的分类结果为0,则当前词不是对应句子的触发词。
本实施方式中svc的c值设置为0.1,1,10,100,1000或10000,gamma值设置为0.8,0.5,0.1,0.01,0.001,将svc的c值和gamma值交叉组合使用;利用指标p(精确率)值、r(召回率)值和f1值评价模型的评估结果。
最终,多轮训练测试确定svc最佳参数为核函数设置为kbf、c值设置为100、gamma值设置为0.5,经过多次训练测试可以保证检测模型的准确性;在该套参数下,本发明在动词短语省略消解的判断触发词上超越了现有方法所取得的实验效果。
具体实施方式五:本实施方式对实施方式四所述的一种基于深度学习的动词短语省略消解的方法进行进一步的限定,本实施方式中的步骤三的具体过程为:
将当前候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词输入多层感知机之前,利用opennmt编码器分别处理当前候选先行短语、候选先行短语之前部分和候选先行短语之后部分,利用向量相加、递归神经网络或含有注意力机制的递归神经网络方法,得出当前候选先行短语、候选先行短语之前部分和候选先行短语之后部分的句子级向量表示;
利用fasttext工具对数据集1进行训练,得到数据集1的字级别表示词向量模型;对输入的每一个词,该模型可以输出对应词的词向量;即对于输入词为触发词的情况,该模型将输出该触发词的字级别向量表示;
将各部分的句子级向量表示和触发词的字级别向量表示联合输入多层感知机;若多层感知机的分类结果为1,则当前候选先行短语是动词短语省略消解中省略的先行短语,若多层感知机的分类结果为0,则依次将步骤一中的每个候选先行短语,以及与其相对应的候选先行短语之前部分、候选先行短语之后部分和触发词四个部分输入多层感知机,直至识别出动词短语省略现象中的先行短语。
获取当前候选先行短语的句子级别向量表示时,利用了数据预处理过程中得到的opennmt编码器,同时通过使用fasttext工具对数据集1进行训练,得到词向量模型,再通过该词向量模型获取触发词的字级别向量表示。如图3所示,为本实施方式识别先行短语模型的工作流程。
识别先行短语过程中,可以将任一组候选先行短语、候选先行短语之前部分、候选先行短语之后部分和触发词联合输入多层感知机,以判断该组的候选先行短语是否是省略的先行短语,如果不是,可以依次将其他候选先行短语输入多层感知机,直至找到该句中省略的先行短语。
具体实施方式六:本实施方式对实施方式五所述的一种基于深度学习的动词短语省略消解的方法进行进一步的限定,所述向量相加方法是将短语中每个词的词向量累加结果作为该短语的向量表示;
递归神经网络方法是将每个词输入,取递归神经网络最后一个词隐层输出作为该短语的向量表示;
含有注意力机制的递归神经网络方法是利用每个输入词隐层状态的输出,并计算对应的权重,用计算得到的权重乘以每个输入词隐层状态输出,最后累加得到的结果作为短语的向量表示;计算过程如下:
其中,si表示第i个输入词和最后一个输入词的相似度,wi为第i个输入词,i=0,1,…,n-1,q是该短语的最后一个输入词,||·||表示二范数;
ai为第i个输入词的权重,exp表示指数函数,sj表示第j个输入词和最后一个输入词的相似度,j=0,1,…,n-1,sq表示最后一个输入词和自身的相似度;
aq是最后一个输入词的权重,
venc表示最后得到的短语向量表示,ci表示opennmt编码器第i个输入词对应的隐层状态输出(context),cq表示opennmt编码器最后一个输入词对应的隐层状态输出(context)。
实施例
测试数据集方面,数据采用penntreebank2wallstreetjournal和anannotatedcorpusfortheanalysisofvpellipsisbyjohanbosandjenniferspenader提供的数据集。
评价标准方面,动词短语省略消解任务中的判断触发词相关实验使用了准确率作为评价指标,如表1所示,为判断触发词的实验结果;可以看出,本发明加入了句子级特征和上下文特征时,触发词判断的准确率达到90%左右。
表1
识别先行短语相关实验使用了准确率作为评价指标,如表2所示,为识别先行短语的实验结果;表2分别给出了本发明的三种向量表示方法对应的识别先行短语准确率,可以看出加入了句子级特征和上下文特征的含有注意力机制的rnn的识别准确率达到85%以上。
表2
整体端到端系统相关实验使用了p、r、f1作为评价指标,如表3所示,为端到端的实验结果。
表3
从表3中可以看出,本发明的向量相加(sumpooling)方法,加入上下文特征和句子级特征的向量相加(sumpooling)方法,递归神经网络(rnn)方法,加入上下文特征和句子级特征的递归神经网络(rnn)方法,含有注意力机制(attention)的递归神经网络(rnn)方法,加入上下文特征和句子级特征的含有注意力机制(attention)的递归神经网络(rnn)方法,p值、r值和f1值均高于现有方法。
术发明可以直接应用于开放域的聊天机器人系统中,是一个聊天机器人的核心模块。本专利技术的应用载体是哈尔滨工业大学社会计算与信息检索研究中心开发的聊天机器人“笨笨”。中控模块将输入以及控制权交给动词短语省略消解模块,该模块根据输入判断是否存在动词短语省略,若存在则预测触发词和先行词或短语,然后该模块将输入、触发词、先行词或短语和控制权交回给中控模块,完成一次动词短语省略消解任务。
从部署方式上来讲,该项技术可以独立作为一个计算节点,部署于阿里云或者美团云等云计算平台上,与其它模块之间的通讯可以通过绑定ip地址和端口号的方式进行。
该技术的具体实现上,因为使用了深度学习相关技术,所以需要使用相应的深度学习框架:本技术的相关实验基于开源框架pytorch实现。如果有需要,可以换做其它框架,比如同样开源的tensorflow,或者企业内部使用的padlepadle等。
- 还没有人留言评论。精彩留言会获得点赞!