多人紧密交互场景下的多视角人体动态三维重建方法与流程
本发明属于计算机视觉和图形学领域,具体讲,涉及人体关键点检测、追踪和人体三维模型重建方法。
背景技术:
在计算机视觉和计算机图形学中,无标记人体运动捕捉已经成为一个热门并且具有挑战性的热点问题,其主要任务是通过跟踪视频中移动对象的运动来恢复动态时间一致的3d形状。最近十年以来单人运动捕捉方法取得了巨大的进步,然而当前的方法需要对相机进行设置或处于一个受控的工作室环境中,并且依赖于良好的图像分割技术。在多人的情况下,由于多人分割和姿态估计比较困难,直接使用现有的单人估计方法不能得到令人满意的结果。尽管一些方法(mustafaa.,kimh.,guillemautj.y.,hiltona.generaldynamicscenereconstructionfrommultipleviewvideo.inproc.ieeeinternationalconferenceoncomputervision(2017),pp.900–908.)可以处理多人的情形,但是捕捉场景都是受限的,并且仅仅只是人与人之间简单的交互即不会产生遮挡问题。然而在现实生活中,人与人之间的紧密交互是非常常见的,例如,拥抱、双人舞蹈和打斗等,同时,这些情形在电影或者动画中是经常存在的。
技术实现要素:
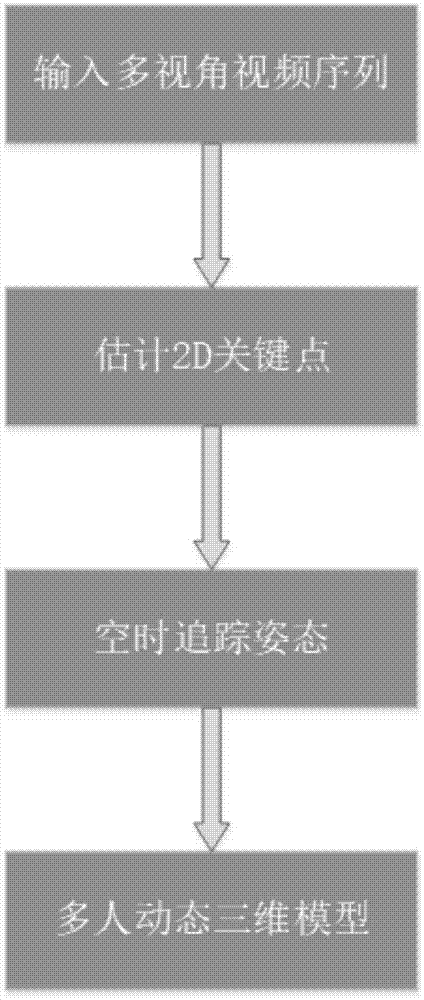
为克服现有技术的不足,本发明提出一种鲁棒的方法实现多人紧密交互下的人体动态三维模型的重建方法,准确地获取紧密交互下多人的人体动态三维模型,本发明采取的技术方案是,多人紧密交互场景下的多视角人体动态三维重建方法,包括以下步骤:
1)采集多人紧密交互场景的多视角视频序列;
2)对于每一张多视角图片,使用人体骨架2d关键点检测方法估计图片中每个人的2d关键点位置和对应的置信度;
3)根据估计得到的每个人每个时刻的2d骨架关键点,进行空时联合的姿态追踪;
4)由步骤3)得到追踪后的2d姿态,通过多人多视角的3d形状和姿态估计方法,拟合多人的三维模型。
步骤3)的空时联合姿态追踪,具体包括以下步骤:
3-1)将步骤2)估计得到的2d人体姿态,先对第一帧时刻的多视角图片进行多人顺序标记,使得多视角图片下的2d人体姿态顺序一致,为了追踪多视角下的同一个人,匹配公式为:
其中b1和b2分别表示为两张图片中两个人的框图boundingbox,
3-2)在同一个视角序列相邻的两帧中,采用时域追踪的方法,具体来说,采用orbmatching方法检测特征点,并对两帧中的两个人计算boundingbox的交并比iou,即:
其中b1和b2分别表示为两帧中两个人的boundingbox,两者的交集表示匹配的特征点,并集表示为特征点的和;
3-3)将估计得到的2d关键点计算相似度,分别将两个关键点看作小boundingbox,大小为人体整体boundingbox的10%,计算公式为:
其中p1和p2分别为两帧中两个人所有关键点boundingbox的和,mi为从p1中的一个关键点的boundingbox中提取到的特征点,ni为从p2中对应关键点boundingbox中匹配的特征点,通过计算其百分比推断两个人的相似度;
3-4)结合公式(2)和(3)来计算相邻两帧中的两个人的相似度,即:
t(p1,p2,b1,b2)=pd(p1,p2)+bo(b1+b2)(4)
3-5)若当前帧中丢失2d关键点,则从前一帧中添加,为了鲁棒的表示添加的2d关键点,设置一个处罚函数为:
其中,ci是由步骤2)计算而得的每个关键点的置信度;
3-6)采用时域追踪以后,在多视角序列的同一时刻中,再联合空域追踪,使得追踪后的2d关键点顺序标记更加准确鲁棒,具体来说,先对每个视角序列下的每一个人,验证其顺序标记的准确性,检验公式为:
其中
3-7)为了矫正不准确的顺序,采用下面的矫正函数:
其中np是要重新追踪的顺序,计算并得到最大相似度的顺序作为新顺序。
步骤4)的多人多视角的3d形状和姿态估计方法,具体包括以下步骤:
4-1)根据步骤3)中追踪得到的2d关键点,进行多视角的模型拟合,能量方程为:
其中ep是先验项,ej是数据项,kv是v视角相机的相机参数,β和θ分别表示为参数化模型的形状参数和姿态参数,先验项定义为:
ep=λθeθ(θ)+λβeβ(β)(9)
其中eθ是姿态先验,eβ是形状先验,λβ和λθ为由数据驱动的参数;ej是多视角数据项,定义如下:
其中ji(β)是三维模型的骨架关节位置,rθ是全局刚性变换经由姿态θ,∏是投影函数,ci是2d关键点的置信度,
其中σ是常量,e是残差项。
本发明的方法的特点及效果:
本发明方法根据多视角视频进行紧密交互下的多人动态三维模型重建,共享多视角下的图片信息,从而得到准确鲁棒的三维模型,具体具有以下特点:
1、操作简单,易于实现;
2、采用空时联合的追踪方法,进行准确的人体2d姿态追踪;
3、根据多视角包含更丰富的信息进行3d形状和姿态估计,减少由错误估计产生的误差。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为本发明方法的流程图;
图2为2d关键点估计结果图;
图3为姿态追踪结果图;
图4为本发明最终重建出的某一时刻的三维模型结果。
具体实施方式
本发明采取的技术方案是基于多视角视频对紧密交互下的多人场景进行人体形状和姿态估计,包括以下步骤:
1)采集多人紧密交互场景的多视角视频序列;
2)对于每一张多视角图片,使用人体骨架2d关键点检测方法估计图片中每个人的2d关键点位置和对应的置信度;
3)根据估计得到的每个人每个时刻的2d骨架关键点,进行空时联合的姿态追踪;
4)由步骤3)得到追踪后的2d姿态,通过多人多视角的3d形状和姿态估计方法,拟合多人的三维模型,2d、3d分别表示二维、三维。
步骤3)的空时联合姿态追踪,具体包括以下步骤:
3-1)将步骤2)估计得到的2d人体姿态,先对第一帧时刻的多视角图片进行多人顺序标记,使得多视角图片下的2d人体姿态顺序一致,为了追踪多视角下的同一个人,匹配公式为:
其中b1和b2分别表示为两张图片中两个人的boundingbox(框图),
3-2)在同一个视角序列相邻的两帧中,采用时域追踪的方法,具体来说,采用orbmatching方法检测特征点,并对两帧中的两个人计算boundingbox的iou(交并比),即:
其中b1和b2分别表示为两帧中两个人的boundingbox,两者的交集表示匹配的特征点,并集表示为特征点的和;
3-3)将估计得到的2d关键点计算相似度,分别将两个关键点看作小boundingbox,大小为人体整体boundingbox的10%,计算公式为:
其中p1和p2分别为两帧中两个人所有关键点boundingbox的和,mi为从p1中的一个关键点的boundingbox中提取到的特征点,ni为从p2中对应关键点boundingbox中匹配的特征点,通过计算其百分比推断两个人的相似度;
3-4)结合公式(2)和(3)来计算相邻两帧中的两个人的相似度,即:
t(p1,p2,b1,b2)=pd(p1,p2)+bo(b1+b2)(4)
3-5)若当前帧中丢失2d关键点,则从前一帧中添加。为了鲁棒的表示添加的2d关键点,设置一个处罚函数为:
其中,ci是由步骤2)计算而得的每个关键点的置信度。
3-6)采用时域追踪以后,在多视角序列的同一时刻中,再联合空域追踪,使得追踪后的2d关键点顺序标记更加准确鲁棒。具体来说,先对每个视角序列下的每一个人,验证其顺序标记的准确性,检验公式为:
其中
3-7)为了矫正不准确的顺序,采用下面的矫正函数:
其中np是要重新追踪的顺序,计算并得到最大相似度的顺序作为新顺序。
步骤4)的多人多视角的3d形状和姿态估计方法,具体包括以下步骤:
4-1)根据步骤3)中追踪得到的2d关键点,进行多视角的模型拟合,能量方程为:
其中ep是先验项,ej是数据项,kv是v视角相机的相机参数,β和θ分别表示为参数化模型的形状参数和姿态参数,先验项定义为:
ep=λθeθ(θ)+λβeβ(β)(9)
其中eθ是姿态先验,eβ是形状先验,λβ和λθ为由数据驱动的参数;ej是多视角数据项,定义如下:
其中ji(β)是三维模型的骨架关节位置,rθ是全局刚性变换经由姿态θ,∏是投影函数,ci是2d关键点的置信度,
其中σ是常量,e是残差项。
下表给出了采用不同视角个数拟合出的三维模型与真实数据的之间的误差结果:
其中平均误差和标准差的单位均为毫米(mm)。
- 还没有人留言评论。精彩留言会获得点赞!