一种基于视觉域局部自适应的计算机视觉深度学习方法与流程
本发明涉及深度学习领域,尤其是涉及了一种基于视觉域局部自适应的计算机视觉深度学习方法。
背景技术
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,并且使电脑处理结果成为更适合人眼观察或传送给仪器检测的图像。在医学领域,可应用计算机视觉技术从显微镜图像、x射线图像、血管造影图像等应用图像中提取用于对患者进行医疗诊断的特征信息,从而能够准确及时地对患者采取相应的救治措施;在工业领域,可应用计算机视觉技术对制造工序进行管理,从而实现对产品的质量控制;在军事领域,应用计算机视觉技术可探测敌方目标的具体位置,以进行精确打击;另外,计算机视觉技术在导航、监控和视觉特效制作等领域都有着广泛的应用。然而,现有的计算机视觉深度学习方法存在处理图像得到的结果不显著,并且不能处理源图像中的局部微小的特征信息等问题。
本发明中提出的一种基于视觉域局部自适应的计算机视觉深度学习方法,先将源图像和目标图像输入到一个神经卷积网络中,这个网络在图像网上进行了预训练;然后,用单元相乘将目标与域信息融合,以获取不同域的共有区域的卷积映射;接下来,执行一个最大池化层,紧接着对两个连接层进行规范化调整;最后,在softmax层中根据源数据对目标进行分类。本方法采用了局部自适应架构,具有强大的空间存储,能够使计算机视觉实验结果更加显著,并且能够处理源图像中的局部微小的特征信息。
技术实现要素:
针对现有的计算机视觉深度学习方法存在处理图像得到的结果不显著,并且不能处理源图像中的局部微小的特征信息等问题,本发明的目的在于提供一种基于视觉域局部自适应的计算机视觉深度学习方法,先将源图像和目标图像输入到一个神经卷积网络中,这个网络在图像网上进行了预训练;然后,用单元相乘将目标与域信息融合,以获取不同域的共有区域的卷积映射;接下来,执行一个最大池化层,紧接着对两个连接层进行规范化调整;最后,在softmax层中根据源数据对目标进行分类。
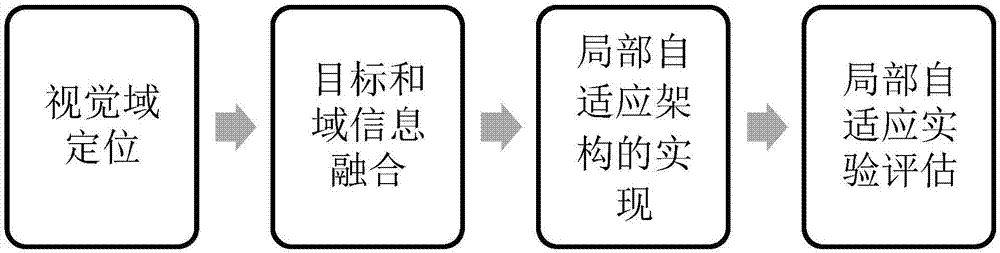
为解决上述问题,本发明提供一种基于视觉域局部自适应的计算机视觉深度学习方法,其主要内容包括:
(一)视觉域定位;
(二)目标和域信息融合;
(三)局部自适应架构的实现;
(四)局部自适应实验评估。
其中,所述的视觉域局部自适应,主要是通过建立一个基于目标域的模型,对源域中的已标记数据进行训练,在训练过程中令目标域中的未标记样本作为辅助信息,以达到在源域和目标域分布概率不同的情况下进行学习的目的。
其中,所述的视觉域定位,将源图像和目标图像输入到一个神经卷积网络中,这个网络在图像网上进行了预训练,并且在一个单独的s形单元上进行微调以进行二元分类;采用yc=f(x)表示最后一个卷积层的softmax函数的得分;最后一个卷积层会生成n=1,…,n个特征映射(
权重值
这个集合可视作一个粗略的热图;为了使热图可视化,可通过双线性内插算法对热图进行升级,并且可用热图来鉴别视觉域(c=1时为特殊域,c=2时为普通域);所得到的热图即为域映射。
其中,所述的目标和域信息融合,首先网络在预训练过程中会生成一个深度卷积网络特征映射c和同等尺寸的滤波器w(在最后一个卷积层);然后,用单元相乘m=c⊙w将目标与域信息融合,以获取不同域的共有区域的卷积映射。
进一步地,所述的滤波器,可用以下公式表示:
其中,n=1,…,n;此公式包含了该滤波器对于特定分类过程所做贡献的信息;其中,relu函数(线性整流函数)经过了严格筛选,可将图像滤波器的灰度区像素减少到零。
其中,所述的局部自适应架构的实现,主要采用torch7(一个深度学习架构)进行;在域定位实现后,执行一个最大池化层,这个池化层是torch7的一个扩展;紧接着对两个连接层进行规范化调整;最后在softmax层中根据源数据对目标进行分类。
进一步地,所述的torch7,是一个多功能的数字计算框架和机器学习库,其目标是提供一个灵活的环境来设计和训练机器学习;由于使用了简单快捷的脚本语言,运行起来非常简单且高效;在局部自适应架构中,torch7可以实现单元相乘和串联过程,并且可用来生成滤波器集成层。
其中,所述的局部自适应实验评估,主要包括实验设置和实验分析。
进一步地,所述的实验设置,采用转换数据集进行实验,转换数据集包括了150个目标,这些目标被平均分配到15个类别之中;每个目标都会发生变化,这是由于每个目标的获取都经历了一个独立的视觉转换过程;实验主要进行了两个方面的测试:转换和尺寸缩扩;对于转换测试,以照相机为圆心从左到右对目标进行旋转拍摄,总共拍摄150张照片,取前50张作为源图像,取后50张作为目标图像,然后基于转换数据集进行域适应;对于尺寸缩扩测试,将目标置于远离照相机的位置,然后逐步向照相机靠近进行拍摄,总共拍摄150张照片,取前50张作为源图像,取后50张作为目标图像,然后基于转换数据集进行域适应。
进一步地,所述的实验分析,主要通过分析在转换和尺寸缩扩的自适应过程中域差的降低程度,来评估局部适应架构的性能。
附图说明
图1是本发明一种基于视觉域局部自适应的计算机视觉深度学习方法的系统流程图。
图2是本发明一种基于视觉域局部自适应的计算机视觉深度学习方法的视觉域定位网络图。
图3是本发明一种基于视觉域局部自适应的计算机视觉深度学习方法的实验方法图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于视觉域局部自适应的计算机视觉深度学习方法的系统流程图。主要包括:视觉域定位、目标和域信息融合、局部自适应架构的实现和局部自适应实验评估。
视觉域局部自适应,主要是通过建立一个基于目标域的模型,对源域中的已标记数据进行训练,在训练过程中令目标域中的未标记样本作为辅助信息,以达到在源域和目标域分布概率不同的情况下进行学习的目的。
目标和域信息融合,首先网络在预训练过程中会生成一个深度卷积网络特征映射c和同等尺寸的滤波器w(在最后一个卷积层);然后,用单元相乘m=c⊙w将目标与域信息融合,以获取不同域的共有区域的卷积映射。
其中,滤波器,可用以下公式表示:
其中,n=1,…,n;此公式包含了该滤波器对于特定分类过程所做贡献的信息;其中,relu函数(线性整流函数)经过了严格筛选,可将图像滤波器的灰度区像素减少到零。
局部自适应架构的实现,主要采用torch7(一个深度学习架构)进行;在域定位实现后,执行一个最大池化层,这个池化层是torch7的一个扩展;紧接着对两个连接层进行规范化调整;最后在softmax层中根据源数据对目标进行分类。
其中,torch7,是一个多功能的数字计算框架和机器学习库,其目标是提供一个灵活的环境来设计和训练机器学习;由于使用了简单快捷的脚本语言,运行起来非常简单且高效;在局部自适应架构中,torch7可以实现单元相乘和串联过程,并且可用来生成滤波器集成层。
局部自适应实验评估,主要包括实验方法和实验分析。
其中,实验分析,其特征在于,主要通过分析在转换和尺寸缩扩的自适应过程中域差的降低程度,来评估局部适应架构的性能。
图2是一种基于视觉域局部自适应的计算机视觉深度学习方法的视觉域定位网络图。视觉域定位,将源图像和目标图像输入到一个神经卷积网络中,这个网络在图像网上进行了预训练,并且在一个单独的s形单元上进行微调以进行二元分类;采用yc=f(x)表示最后一个卷积层的softmax函数的得分;最后一个卷积层会生成n=1,…,n个特征映射(
权重值
这个集合可视作一个粗略的热图;为了使热图可视化,可通过双线性内插算法对热图进行升级,并且可用热图来鉴别视觉域(c=1时为特殊域,c=2时为普通域);所得到的热图即为域映射。
图3是一种基于视觉域局部自适应的计算机视觉深度学习方法的实验方法图。实验方法,其特征在于,采用转换数据集进行实验,转换数据集包括了150个目标,这些目标被平均分配到15个类别之中;每个目标都会发生变化,这是由于每个目标的获取都经历了一个独立的视觉转换过程;实验主要进行了两个方面的测试:转换和尺寸缩扩;对于转换测试,以照相机为圆心从左到右对目标进行旋转拍摄,总共拍摄150张照片,取前50张作为源图像,取后50张作为目标图像,然后基于转换数据集进行域适应;对于尺寸缩扩测试,将目标置于远离照相机的位置,然后逐步向照相机靠近进行拍摄,总共拍摄150张照片,取前50张作为源图像,取后50张作为目标图像,然后基于转换数据集进行域适应。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!