一种物联网数据预处理方法及系统与流程
本发明涉及物联网数据处理领域,特别涉及一种物联网数据预处理方法及系统。
背景技术:
目前,物联网系统广泛的应用在现代产品生产系统中,国内的产品生产类企业需要重点提升产品的自动化、数字化、网络化和智能化水平。目前的产品生产中,往往有上百个工艺参数需要逐步进行优化,生产过程出现了“数据丰富而知识贫乏”的现象逐步获得有效解决,但随之而来的则是企业的集成信息系统尤其是生产制造系统每天获取的数据随着应用精度的提高呈几何级递增,因此在如何分发、存储、管理和共享这些海量物联网数据已成为亟待解决的问题。
因此,需要在hadoop框架的基础上,提出一种物联网数据预处理方法。
技术实现要素:
有鉴于此,本发明的目的是在hadoop框架的基础上,提出一种物联网数据预处理方法及系统。
本发明的基于hadoop的物联网大数据处理方法,包括以下步骤:
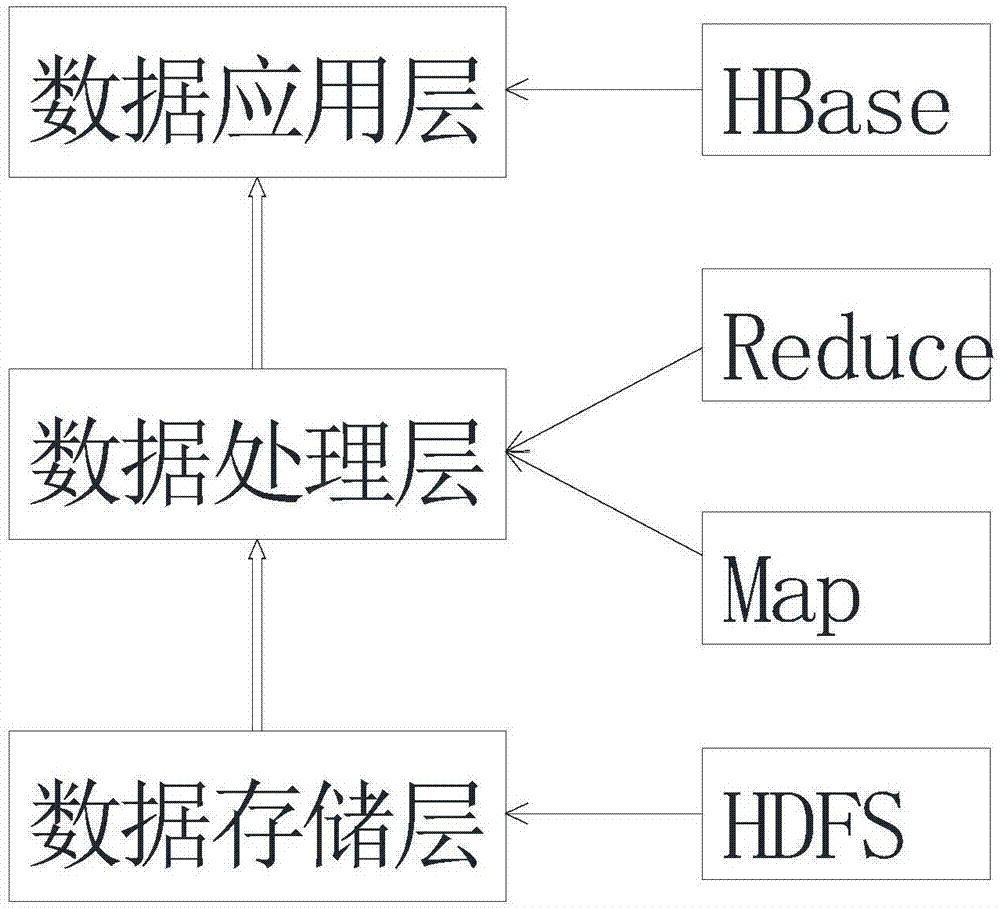
s1.根据产品生产过程产生的数据及数据的使用需求,采用源数据层进行数据的获取存储,采用数据处理层进行数据的并行加载存储,采用数据存储层实现为数据应用展现所需数据的存储。s2.通过使用hdfs存储海量源数据,通过mapreduce处理海量源数据,用hbase分布式数据库存储处理后生产数据;s3.通过三个层面的数据流转从而设计实现产品生产海量生产数据的存储系统。
进一步,在所述步骤s2中,hdfsclient通过调用filesystem对象的open()来读取文件,distributedfilesystem通过使用rpc来调用namenode,以确定文件开头部分的块位置;
进一步,在所述步骤s2中,对于每一个块,namenode返回具有该块副本的数据节点;distributedfilesystem返回一个fsdatainputstream对象给client读取数据;fsdatainputstream转而包装一个dfsinputstream对象。client对这个输入流调用read();存储着文件开头部分的块的数据节点地址的dfsinputstream随即与这些块最近的数据节点相连接。
进一步,通过在数据流中反复调用read(),数据会从不同的数据节点返回客户端;到达块的末端时,dfsinputstream会close()与数据节点间的联系,然后为下一个块找到最佳的数据节点;client从流中读取datablock是按照dfsinputstream与不同的数据节点的新连接顺序读取的,一旦client读取完成,就对filesystem输入流调用close(),在整个过程中,client只需要读取一个连续的流即可获得整体的需要分析的数据集,依次过程,client对hdfs写入数据到各个datanode。
本发明的一种物联网数据预处理系统,包括海量产品生产数据的存储整体架构,所述构架包括:源数据层,其功能是数据的获取存储,数据处理层,其用于实现数据的并行加载存储,数据存储层,其用于实现为数据应用展现所需数据的存储。
本发明的有益效果:本发明的基于hadoop的物联网大数据处理方法及系统,根据产品生产过程的不同特点通过hadoop实现了海量生产数据的存储。通过hdfs实现了数据的一次写入,多次读取;通过mapreduce实现了充分的并行性,将作业有效分布到数据上;通过hbase实现了随着表空间增长的自动分区、区域自动平衡、访问数据在毫秒范围内的应用。
附图说明
下面结合附图和实施例对本发明作进一步描述。
图1为本发明的存储系统的连接示意图;
图2为本发明的hdfs读写数据体系的连接示意图。
具体实施方式
图1为本发明的存储系统的连接示意图;如图所示:本实施例的物联网数据预处理方法,包括以下步骤:s1.根据产品生产过程产生的数据及数据的使用需求,采用源数据层进行数据的获取存储,采用数据处理层进行数据的并行加载存储,采用数据存储层实现为数据应用展现所需数据的存储。s2.通过使用hdfs存储海量源数据,通过mapreduce处理海量源数据,用hbase分布式数据库存储处理后生产数据;s3.通过三个层面的数据流转从而设计实现产品生产海量生产数据的存储系统。本实施例的基于hadoop的物联网大数据处理方法及系统,根据产品生产过程的不同特点通过hadoop实现了海量生产数据的存储。通过hdfs实现了数据的一次写入,多次读取;通过mapreduce实现了充分的并行性,将作业有效分布到数据上;通过hbase实现了随着表空间增长的自动分区、区域自动平衡、访问数据在毫秒范围内的应用。
本实施例中,在所述步骤s2中,hdfsclient通过调用filesystem对象的open()来读取文件,distributedfilesystem通过使用rpc来调用namenode,以确定文件开头部分的块位置;
本实施例中,在所述步骤s2中,对于每一个块,namenode返回具有该块副本的数据节点;distributedfilesystem返回一个fsdatainputstream对象给client读取数据;fsdatainputstream转而包装一个dfsinputstream对象。client对这个输入流调用read();存储着文件开头部分的块的数据节点地址的dfsinputstream随即与这些块最近的数据节点相连接;
本实施例中,通过在数据流中反复调用read(),数据会从不同的数据节点返回客户端;到达块的末端时,dfsinputstream会close()与数据节点间的联系,然后为下一个块找到最佳的数据节点;client从流中读取datablock是按照dfsinputstream与不同的数据节点的新连接顺序读取的,一旦client读取完成,就对filesystem输入流调用close(),在整个过程中,client只需要读取一个连续的流即可获得整体的需要分析的数据集,依次过程,client对hdfs写入数据到各个datanode;
本实施例的一种物联网数据预处理系统,包括海量产品生产数据的存储整体架构,所述构架包括:源数据层,其功能是数据的获取存储,数据处理层,其用于实现数据的并行加载存储,数据存储层,其用于实现为数据应用展现所需数据的存储。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
技术特征:
技术总结
本发明公开了一种物联网数据预处理方法,包括以下步骤:S1.根据产品生产过程产生的数据及数据的使用需求,采用源数据层进行数据的获取存储,采用数据处理层进行数据的并行加载存储,采用数据存储层实现为数据应用展现所需数据的存储;S2.通过使用HDFS存储海量源数据,通过MapReduce处理海量源数据,用HBase分布式数据库存储处理后生产数据;S3.通过三个层面的数据流转从而设计实现产品生产海量生产数据的存储系统;本发明根据产品生产过程的不同特点通过Hadoop实现了海量生产数据的存储。通过HDFS实现了数据的一次写入,多次读取;通过MapReduce实现了充分的并行性,将作业有效分布到数据上。
技术研发人员:陈虹宇
受保护的技术使用者:重庆工商职业学院
技术研发日:2018.07.27
技术公布日:2018.12.21
- 还没有人留言评论。精彩留言会获得点赞!