一种基于评价对象阵营的立场分析模型构建方法与流程
本发明涉及一种基于评价对象阵营的立场分析模型构建方法。
背景技术:
在分析海量评论信息的立场(褒义、贬义、中立等)时,人工判断立场的方法需要耗费大量的人力且效率低。此外,评论信息中涉及的对象很多,评论信息中同样的表达方式,针对不同的对象,立场也不同。因此,当前基于对象进行情感褒贬分析的方法无法直接运用在立场分析。
技术实现要素:
为了克服现有技术的上述缺点,本发明提供了一种基于评价对象阵营的立场分析模型构建方法,针对网络社交媒体的评论信息,构建对象阵营词典,利用本发明的对象阵营判断模型以及立场分析模型的协作,可以达到快速准确分析评论信息立场的目的。
本发明解决其技术问题所采用的技术方案是:一种基于评价对象阵营的立场分析模型构建方法,包括如下步骤:
步骤一、构建对象阵营词典;
步骤二、构建对象阵营判断语料;
步骤三、构建对象阵营判断模型;
步骤四、构建立场分析语料;
步骤五、构建立场分析模型。
与现有技术相比,本发明的积极效果是:
通过本发明方法构建的立场分析模型对目标对象的分析速度快,远远高于人工判定;其次是准确率高,模型准确率可达到72.54%,且能分析一些少数立场,同时,训练语料构建工作量小,只需要制作一个小规模的语料库,就可以对模型进行训练。
综上,本发明的立场分析模型在分析目标对象立场时,不仅节约了人力成本,降低了工作量,且提高了对目标对象立场分析的效率及准确率。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
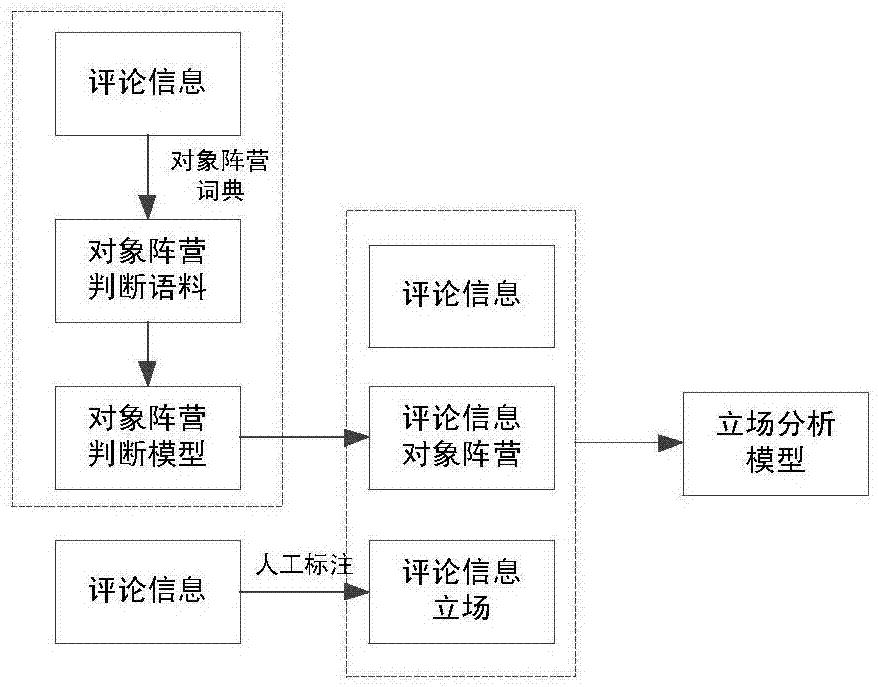
图1为本发明的原理框图。
具体实施方式
一种基于评价对象阵营的立场分析模型构建方法,如图1所示,针对网络社交媒体的评论信息,构建对象阵营词典。采用词典-评论信息匹配的方法,抽取出明显具有对象阵营特征的句子,作为对象阵营判断的学习语料,构建对象阵营判断模型,完成评论信息对象阵营的判断。人工标注评论信息的立场,并将其与对象阵营、评论信息共同作为立场分析模型的输入,通过训练得到立场分析模型。
本发明的具体内容包括:
(一)对象阵营判断模型构建
1、对象阵营词典构建
为了方便对象阵营判断语料的构建,首先通过人工分析方法构建对象阵营词典,用于匹配评论中的对象信息。该词典内容为一个对象跟随一个类别标签,对象阵营包含两大阵营,分别记为0、1。
2、对象阵营判断语料构建
将对象的评论信息与词典进行匹配,选出明显具有对象阵营特征的评论信息,分别归到0、1阵营中,共同构成对象阵营判断语料。
同时,在不打乱语料对象阵营对应关系的基础上进行语料随机乱序,并将语料信息按照8:1:1的比例分为训练集、验证集、测试集。
3、对象阵营判断模型构建
对象阵营判断模型是一个经典的双向长短记忆神经网络(blstm)。
对象阵营判断模型的大体结构可以描述如下:
a.输入层:将长度为n的句子t中的每个词wt={wt1,wt2,...,wtn,}的词向量st={st1,st2,...,stn,}输入。
st=embedding(wt)
b.双向神经网络:通过双向的长短记忆神经网络得到每个词的抽象表示ht={ht1,ht2,...,htn,}(隐层输出,维度为50)。
ht=bsltm(st)
c.输出层:将每个句子最后一个词的隐层输出htn作为最终的句子表示,经过linear层转化为2维并通过softmax函数得到一个2维概率分布pt,分别代表评价对象阵营为0和1。
pt=softmax(w×htn+bias)
其中,w为句子的权重,bias为偏置。
(二)立场分析模型构建
1、立场分析语料构建
对目标对象评论信息的立场进行人工标注,结合评论信息对象阵营判断的结果,从评论信息的对象阵营、立场、评论信息内容三方面,完成立场分析语料构建。同样,在不打乱语料对应关系的基础上进行语料随机乱序,并将语料信息按照8:1:1的比例分为训练集、验证集、测试集。
2、立场分析模型构建
结合评论信息对象阵营判断的结果,将评论信息的对象阵营、立场、评论信息内容三个要素共同作为立场分析模型的输入,基于blstm的分类神经网络,构建立场分析模型。
模型结构描述如下:
a.输入层:将长度为n的句子t的每个词wt={wt1,wt2,...,wtn,}的词向量st={st1,st2,...,stn,}与该句子对象阵营的向量表示vt进行连接,并作为立场分析模型的输入,记为it。
其中,对象阵营vt的向量表示方法为one-hot形式:对象阵营标签为0,向量类别表示为[1,0,0];对象阵营标签为1,向量类别表示为[0,1,0];对象阵营标签为2,向量类别表示为[0,0,1]。
it=concatenate(st,vt)
b.双向神经网络:通过双向长短记忆神经网络得到每个词的抽象表示ht={ht1,ht2,...,htn,}(隐层输出,维度为50)。
ht=bsltm(it)
c.注意力层(attentionlayer):在每个词的隐层输出ht上再连接一次该句子对象阵营vt的向量表示,作为注意力层的输入kt,在注意力层对该向量进行线性非线性变换,使之变成句子长度n维的概率分布at,并认为概率大的位置对于最后的立场判断更加重要。将该概率分布(概率分布拓展到与隐层输出的维度相同)与句子中每个词的隐层输出按位相乘,并求和,即加权求和,作为句子的一个表示rt。
注意力层采用linear+tanh+linear变换。其中注意力层的输入kt计算方法如下:
kt=concatenate(ht,vt)
概率分布at:
at=attention(kt)
句子的一个表示rt:
rt=sum(at×ht)
d.输出层:将注意力层加权求和得到的句子表示rt与句子最后一个词的隐层输出htn进行按位加法,结果作为最终的句子表示ht*,
ht*=rt+htn
将ht*经过linear函数变换为3维向量,并经过softmax函数得到一个3维概率分布pt。
pt=softmax(w×ht*+bias)。
技术特征:
技术总结
本发明公开了一种基于评价对象阵营的立场分析模型构建方法,包括如下步骤:步骤一、构建对象阵营词典;步骤二、构建对象阵营判断语料;步骤三、构建对象阵营判断模型;步骤四、构建立场分析语料;步骤五、构建立场分析模型。与现有技术相比,本发明的积极效果是:通过本发明方法构建的立场分析模型对目标对象的分析速度快,远远高于人工判定;其次是准确率高,模型准确率可达到72.54%,且能分析一些少数立场,同时,训练语料构建工作量小,只需要制作一个小规模的语料库,就可以对模型进行训练。综上,本发明的立场分析模型在分析目标对象立场时,不仅节约了人力成本,降低了工作量,且提高了对目标对象立场分析的效率及准确率。
技术研发人员:曾曦;阳红;谢瑞云;夏明赟;赵姝颖;常明芳
受保护的技术使用者:中国电子科技集团公司第三十研究所
技术研发日:2018.08.17
技术公布日:2019.02.19
- 还没有人留言评论。精彩留言会获得点赞!