可编程人工智能加速器指令集的构建方法与流程
本发明涉及人工智能(ai)应用领域,特别是涉及一种可编程人工智能加速器指令集的构建方法。
背景技术:
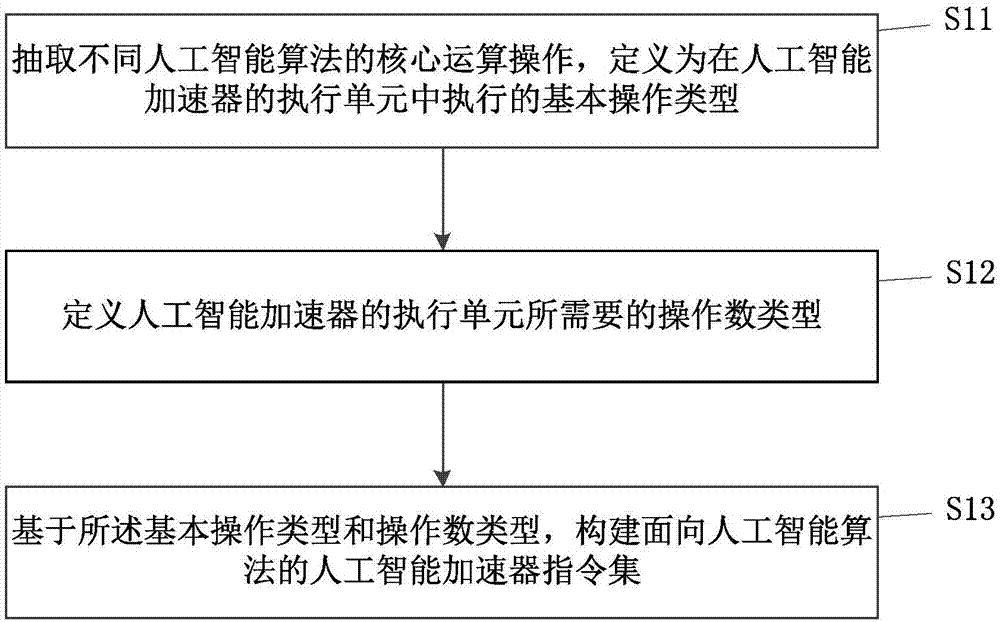
:随着大数据、人工智能技术的快速发展,传统的中央处理器cpu的运算处理能力已经无法满足人工智能运算的处理需求,业内处理器厂商开始研发专用的人工智能加速器用于人工智能算法加速。现有的人工智能加速器大多使用asic专用集成电路设计方法进行设计,根据这种方法设计的人工智能加速器通常用于特定的人工智能算法加速。然而,随着人工智能技术在各领域的普遍应用,作为人工智能技术基础的机器学习算法、尤其是深度学习算法也是多种多样。为了使得一种人工智能加速器能够支持多种人工智能算法的运算加速,现有的一种方案是从功能的角度提取人工智能算法的通用逻辑,通过硬件控制,使得多种人工智能算法可以在相同的硬件逻辑上运行,从而达到一款asic人工智能加速器可以实现对多种人工智能算法进行加速的目的。例如,可以将人工智能算法抽象为矩阵乘法(matrixmultiply)、激活(activation)和规范化/池化(normalize/pool)三种基本功能操作,结合硬件控制达到用一种人工智能加速器实现多种人工智能算法的目的。但是,这种方法是从功能的角度对常用的人工智能算法进行抽象,而不同的人工智能算法对硬件的利用率不同,这种抽象方法必然会导致一部分硬件对一些人工智能算法是冗余的,而对其它人工智能算法却是不足的。随着人工智能算法的不断研究,各种算法也在不断发展演进,当新的人工智能算法出现时,原有的人工智能加速器硬件已经无法高效适配新的算法加速,从而导致硬件的算力浪费和成本上升。技术实现要素:为了解决上述问题,本发明提出一种可编程人工智能加速器指令集构建方法,包括:步骤s11,抽取不同人工智能算法的核心运算操作,定义为在人工智能加速器执行单元中执行的基本操作类型;步骤s12,定义人工智能加速器的执行单元所需要的操作数类型;步骤s13,基于所述基本操作类型和操作数类型,构建面向人工智能算法的人工智能加速器指令集。在一些实施方式中,所述基本操作类型包括加法操作、减法操作、乘法操作、乘累加操作、最大值操作、最小值操作、移位操作。在一些实施方式中,所述基本操作类型包括逻辑操作。在一些实施方式中,所述逻辑操作包括逻辑与、逻辑或、逻辑异或操作。在一些实施方式中,所述基本操作类型包括进循环操作和出循环操作。在一些实施方式中,所述基本操作类型包括加法树操作。在一些实施方式中,所述操作数类型包括从所述执行单元的第一操作数输入端口获得的操作数。在一些实施方式中,所述操作数类型包括从所述执行单元的第二操作数输入端口获得的操作数。在一些实施方式中,所述操作数类型包括从所述执行单元的第一内部寄存器获得的操作数。在一些实施方式中,所述操作数类型包括从所述执行单元的第二内部寄存器获得的操作数。在一些实施方式中,所述指令集中的指令格式包括指令名称、操作数类型、hint标记、目标寄存器和多个操作数。本发明实施例通过抽象人工智能算法所需要的核心运算操作,构建面向人工智能算法的专用指令集,通过细粒度的适配,实现了一款人工智能加速器能够高效适配多种人工智能算法,从而有效利用了硬件算力,节约了硬件成本。附图说明图1是根据本发明一实施例的可编程人工智能加速器指令集的构建方法的流程示意图;图2是根据本发明一实施例的eu执行单元的结构示意图;图3是根据本发明一实施例的可编程人工智能加速器执行单元的结构示意图;图4是根据本发明另一实施例的可编程人工智能加速器执行单元的结构示意图;图5是根据本发明一实施例的基于可编程人工智能加速器的人工智能加速方法的流程示意图;图6是根据本发明另一实施例的基于可编程人工智能加速器的人工智能加速方法的流程示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。图1是根据本发明一实施例的可编程人工智能加速器指令集的构建方法的流程示意图。本发明实施例的可编程人工智能加速器指令集的构建方法包括以下步骤:步骤s11,抽取不同人工智能算法的核心运算操作,定义为在人工智能加速器执行单元中执行的基本操作类型。人工智能算法需要在人工智能加速器的eu执行单元中执行各种运算操作,从而完成算法的执行。本发明实施例通过对不同的人工智能算法进行分析和抽象,将各算法中的核心运算操作抽取出来,定义为人工智能加速器执行单元中执行的基本操作类型,具体包括:1)加法操作op_add加法操作op_add用于实现两个操作数的加法运算。以两个操作数opa和opb为例,假设运算结果用result表示,那么该加法操作op_add就相当于以下算式:result=opa+opb;2)减法操作op_sub减法操作op_sub用于实现两个操作数的减法运算。以两个操作数opa和opb为例,假设运算结果用result表示,那么该减法操作op_sub就相当于以下算式:result=opa-opb;3)乘法操作op_mul乘法操作op_mul用于实现两个操作数的乘法运算。以两个操作数opa和opb为例,假设运算结果用result表示,那么该乘法操作op_mul就相当于以下算式:result=opa*opb;4)乘累加操作op_mac乘累加操作op_mac用于实现两个操作数的乘积与另一操作数的累加运算。以操作数opa、opb和opd为例,假设运算结果用result表示,那么该乘累加操作op_mac就相当于下面两个操作组合完成:result=op_mul(opa,opb);opd=op_add(result,opd);5)最大值操作op_max最大值操作op_max用于求两个操作数中的最大值max。以操作数opa和opb为例,假设运算结果用result表示,那么该最大值操作op_max就相当于下面算式组合完成:result=op_sub(opa,opb);max=result>0?opa:opb;6)最小值操作op_min最小值操作op_min用于求两个操作数中的最小值min。以操作数opa和opb为例,假设运算结果用result表示,那么该最小值操作op_min就相当于下面算式组合完成:result=op_sub(opa,opb);min=result<0?opa:opb;7)逻辑与操作op_and逻辑与操作op_and用于实现两个操作数的逻辑与操作。以两个操作数opa和opb为例,假设运算结果用result表示,那么该逻辑与操作op_and就相当于以下算式:result=opa&opb;8)逻辑或操作op_or逻辑或操作op_or用于实现两个操作数的逻辑或操作。以两个操作数opa和opb为例,假设运算结果用result表示,那么该逻辑或操作op_or就相当于以下算式:result=opa|opb;9)逻辑异或操作op_xor逻辑异或操作op_xor用于实现两个操作数的逻辑异或操作。以两个操作数opa和opb为例,假设运算结果用result表示,那么该逻辑异或操作op_xor就相当于以下算式:result=opa^xor;10)移位操作op_shift移位操作op_shift用于实现操作数的左移和右移运算。以操作数opa为例,假设运算结果用result表示,那么该移位操作op_shift就相当于以下两个算式:result=opa<<m;result=opa>>m;其中,m表示对操作数opa进行左移和右移的位数。11)出循环操作op_cbz出循环操作op_cbz用于标识eu执行单元退出一个循环loop。12)进循环操作op_loop进循环操作op_loop用于标识eu执行单元进入一个循环loop。13)加法树操作op_addtree加法树操作op_addtree用于实现若干个数相加运算。以若干个操作数opa0,opa1,…,opan为例,用算式表示如下:result=opa0+opa1+opa2+…+opan。步骤s12,定义人工智能加速器的执行单元所需要的操作数类型。如图2所示,通常人工智能加速器中的一个eu执行单元包括两个或者若干个输入操作数(图中仅示出操作数opa和opb),一个或者若干个输出结果(图中仅示出一个运算结果result),内部由若干个寄存器(图中仅示出src寄存器和dest寄存器),用来保存操作数和执行结果。如下表1所示,本发明实施例定义了4种eu操作数类型:表1eu执行单元的操作数类型操作数类型功能描述eu_opa标识从eu接口的opa端口获得操作数eu_opb标识从eu接口的opb端口获得操作数eu_src标识从eu内部src寄存器获得操作数eu_dest标识从eu内部dest寄存器获得操作数步骤s13,基于所述基本操作类型和操作数类型,构建面向人工智能算法的人工智能加速器指令集。本发明实施例根据步骤s11中定义的人工智能加速器执行单元中执行的基本操作类型以及步骤s12中定义的操作数类型构建人工智能加速器指令集,如下表2所示:表2人工智能加速器指令集以表2中指令eu_add和eu_addd为例说明指令集命名的含义:指令eu_add是一条op_add操作类型的指令,hint标记值为2′b00,操作数opa和opb分别来自操作数类型eu_opa和eu_opb,执行结果保存在eu_dest中。同理,指令eu_addd也是一条op_add操作类型的指令,hint标记值为2′b11,操作数opa和opb分别来自操作数类型eu_opa和eu_dest,执行结果保存在eu_dest中。根据上述指令集定义,以下举例说明如何基于上述指令集实现人工智能算法的核心运算。1)卷积运算卷积运算可以实现为以下指令步骤:a)eu_loopb)eu_macc)eu_cbzd)eu_addd上述指令步骤表示首先进入循环;然后执行乘累加运算;随后判断循环是否结束,如是则继续向下执行,如否则回到eu_loop继续执行;当循环结束后,对运算结果加偏移量。2)最大池化(maxpooling)最大池化运算可以实现为以下指令步骤:a)eu_loopb)eu_maxdc)eu_cbz上述指令步骤表示首先进入循环;然后执行求最大值运算;随后判断循环是否结束,如是则继续向下执行,如否则回到eu_loop继续执行。3)矩阵乘法(matrixmultiply)a)eu_loopb)eu_macc)eu_cbz上述指令步骤表示首先进入循环;然后执行乘累加运算;随后判断循环是否结束,如是则继续向下执行,如否则回到eu_loop继续执行。本发明实施例通过抽象人工智能算法所需要的核心运算操作,构建面向人工智能算法的专用指令集,通过细粒度的适配,实现了一款人工智能加速器能够高效适配多种人工智能算法,从而有效利用了硬件算力,节约了硬件成本。图3是根据本发明一实施例的可编程人工智能加速器执行单元的结构示意图。如图3所示,本发明实施例的可编程人工智能加速器执行单元包括以下功能模块:取指模块11,用于获取人工智能加速程序指令,并控制程序执行的流程;译码模块12,用于根据获取的指令的类型进行译码操作,生成程序执行需要的控制信息;执行模块13,用于根据译码生成的控制信息执行相应的运算操作,并输出执行结果。如图4所示,所述取指模块11包括取指控制模块110、表索引生成模块111、指令表112和配置寄存器113。取指控制模块110用于根据配置寄存器113的配置,开始运行基于人工智能加速指令集编写的人工智能加速程序,控制人工智能加速程序指令的获取;表索引生成模块111根据配置寄存器113的配置和执行的程序地址,生成指令表索引,并按照指令表索引从指令表112中获取需要执行的一组指令。取指控制模块110还用于将获取的需要执行的一组指令发送给译码模块12。译码模块12包括分别对应不同指令类型的多个译码单元,例如进出循环操作指令(loop/cbz)译码单元、加法树操作指令(addtree)译码单元,加法操作指令(add)译码单元,乘法操作指令(mul)译码单元,移位操作指令(shift)译码单元和逻辑运算操作指令(包含and、or、xor等logic逻辑操作)译码单元等。各指令类型的译码单元进行译码操作后获得的控制信息通过命令总线分别传输给执行模块13中相应的eu执行单元执行相应的操作。执行模块13包括多个具体的eu执行单元以及加法树操作执行单元,eu执行单元从译码模块接收译码后的控制信息,对输入的操作数opa和opb进行相应的指令操作运算,并输出运算结果。加法树操作执行单元用于对各eu执行单元的运算结果进行相加操作,输出相加后的运算结果。如图4所示,该可编程人工智能加速器运行一条指令,需要三个主要步骤:首先由取指模块11的取指控制模块110开始,取指控制模块110根据配置寄存器113的内容,控制表索引生成模块111生成指令在指令表112中的索引,并从指令表112中将指令取出。然后取指模块11将取出的指令送往译码模块12,译码模块12根据指令类型在相应的译码单元(loop/cbz,addtreee,add等)将指令信息解析出来,并通过命令总线送到执行模块13。执行模块13根据命令总线上的信息,在eu执行单元上同时执行命令总线上指明的操作。若该指令需要加法树操作执行单元(addtree)执行,则将eu执行单元的执行结果送往addtree执行单元,否则eu执行单元的执行结果就是该指令的执行结果。本发明实施例提出可编程人工智能加速器执行单元的基本结构和工作流程,能够保证高效执行面向人工智能算法的专用指令集,通过细粒度的适配,使得一款人工智能加速器能够高效适配多种人工智能算法。图5是根据本发明一实施例的基于可编程人工智能加速器的人工智能加速方法的流程示意图。如图5所示,本发明实施例的基于可编程人工智能加速器执行单元的人工智能加速方法包括以下步骤:步骤s21,获取人工智能加速程序指令,并控制程序执行的流程,所述人工智能加速程序基于人工智能加速器指令集编写;步骤s22,根据获取的指令的类型进行译码操作,生成程序执行需要的控制信息;步骤s23,根据译码生成的控制信息执行相应的运算操作,并输出执行结果。图6是根据本发明另一实施例的基于可编程人工智能加速器的人工智能加速方法的流程示意图。如图6所示,在图5所示实施例基础上,上述步骤s21包括以下步骤:步骤s211,开始运行基于人工智能加速器指令集编写的人工智能加速程序,控制人工智能加速程序指令的获取;步骤s212,根据配置寄存器的配置和执行的程序地址,生成指令表索引;步骤s213,根据生成的指令表索引从指令表获取需要执行的一组指令。上述步骤s22包括以下步骤:步骤s221,基于与获取的指令的类型对应的译码单元对指令进行译码操作,分别生成程序执行所需要的控制信息;步骤s222,通过命令总线将生成的程序执行所需要的控制信息传输给相应的执行单元。上述步骤s23包括以下步骤:步骤s231,将执行运算操作所需的操作数据输入相应的执行单元进行运算,输出运算结果;步骤s232,对各执行单元的运算结果进行加法树操作,输出相加后的运算结果。本发明实施例提出的基于可编程人工智能加速器的人工智能加速方法,通过可编程人工智能加速器执行单元执行人工智能加速器指令集编写的人工智能加速程序,通过细粒度的适配,使得一款人工智能加速器能够高效适配多种人工智能算法,从而有效利用了硬件算力,节约了硬件成本。以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1